Die Luft, die wir atmen: Analyse von Luftqualitätsdaten mit Elasticsearch in der Elastic Cloud (Teil 1)
Der Elastic Stack hat vielfach gezeigt, dass er hervorragend geeignet ist, Daten zu erfassen und zu indexieren und anhand dieser Daten dann wertvolle Erkenntnisse bereitzustellen. Die integrierte Verwaltung von Informationen ist nicht nur möglich, sondern kann, wie Sie in dieser Serie von Blogposts sehen werden, vielfältig sinnvoll eingesetzt werden. Wir zeigen Ihnen, wie aus rohen Daten Schlussfolgerungen gezogen werden können, die jeder Bewohner einer modernen Großstadt zur Verbesserung seines täglichen Lebens nutzen kann.
Das Bevölkerungswachstum in vielen Großstädten dieser Erde bringt eine Reihe von Problemen mit sich. Eines der größten davon – mit unmittelbaren Auswirkungen auf die Gesundheit der Bewohner – ist die Luftverschmutzung. Um die Bürger warnen und bei Bedarf Notfallmaßnahmen ergreifen zu können, betreiben viele Stadtverwaltungen Anlagen zur Messung der Luftqualität, die an verschiedenen Orten der Stadt die Konzentration von Schadstoffen in der Luft messen.
Da die Messung der Luftqualität eine öffentliche Aufgabe ist, sind die gemessenen Werte nicht selten öffentlich zugänglich und können von jedermann genutzt werden. Das ist auch in Madrid, mit mehr als drei Millionen Einwohnern eine der größten Städte Europas, der Fall.
Wir zeigen Ihnen, wie einfach es ist, mithilfe von Elasticsearch aus diesen für sich genommen nicht sehr aussagekräftigen Messungen von Stoffkonzentrationen Rückschlüsse auf die Gewohnheiten der Bewohner Madrids zu ziehen.
Aus CSV-Dateien werden Elasticsearch-Dokumente
Als Erstes gilt es, einen Blick auf die Datenquelle zu werfen. Die Madrider Stadtverwaltung betreibt ein offenes Datenportal, auf dem stündlich Messdaten zur Luftqualität bereitgestellt werden (in spanischer Sprache).
Wir finden dort einen HTTP-Endpunkt, der eine CSV-Datei bereitstellt, die einmal pro Stunde aktualisiert wird und die Messdaten des aktuellen Tages bis zur letzten Stunde enthält.
Jede Zeile in der Datei steht für ein (Standort, Stoff)-Schlüsselpaar und enthält die stündlichen Messdaten für einen ganzen Tag. Die Werte für die einzelnen Stunden werden jeweils in einer eigenen Spalte festgehalten.
| ... | MESSSTELLE | STOFF | ... | MONAT | TAG | 00:00 Messwert | 00:00 Gültig? | ... | 23:00 Messwert | 23:00 Gültig? |
| Zahl (Code) | Code (Code) | Zahl | Zahl | Zahl | „V“ oder „F“ (Wahr/Falsch) | Zahl | „V“ oder „F“ (Wahr/Falsch) |
Felder wie MESSSTELLE und STOFF werden als numerische Werte für die geografische Lage beziehungsweise die Stoffzusammensetzung angegeben. Die entsprechenden Verknüpfungen werden über Tabellen auf der Datenquellen-Website bereitgestellt.
Dagegen werden die stündlichen Messdaten (i-te stündliche Messung) und Flags zur Angabe der Gültigkeit (i-te stündliche Messung gültig?) als Rohwerte präsentiert. Die Einheiten sind ebenfalls mit einer Tabelle auf der Datenquellen-Website verknüpft und das Gültigkeits-Flag kann die Werte „V“ für „Verdadero“ (wahr) und „F“ für „Falso“ (falsch) haben.
Die Stoffprobenergebnisse werden als Messwerte in Raum und Zeit dargestellt. Moment mal, das heißt doch … Richtig: Zeitreihen räumlicher Ereignisse! Die Zeilen stellen also nicht einzelne Ereignisse dar. Im Gegenteil: Pro Zeile werden bis zu 24 Ereignisse für ein und denselben Standort und ein und dieselbe chemische Verbindung erfasst.
Wenn wir jedes Ereignis als ein JSON-Dokument verschlüsseln würden, sähe das Ergebnis beispielsweise wie folgt aus:
{
"timestamp": 1532815200000,
"location": {
"lat": 40.4230897,
"lon": -3.7160478
},
"measurement": {
"value": 7,
"chemical": "SO2",
"unit": "μg/m^3"
}
}
Wir könnten bei Bedarf diese Daten mit den Grenzwerten der Weltgesundheitsorganisation (WHO) anreichern. Dazu müssen wir lediglich im Messdaten-Subdokument ein zusätzliches Ziel hinzufügen. Das Aufbrechen der einzelnen CSV-Zeilen in separate JSON-Dokumente hilft, die Daten einfacher zu verstehen, und es vereinfacht auch das Ingestieren in Elasticsearch.
{
"timestamp": 1532815200000,
"location": {
"lat": 40.4230897,
"lon": -3.7160478
},
"measurement": {
"value": 7,
"chemical": "SO2",
"unit": "μg/m^3",
"who_limit": 20
}
}
Die Gruppe aller Dokumente, die dieser Struktur entsprechen, kann anhand eines weiteren JSON-Dokuments beschrieben werden. Dabei handelt es sich um ein Mapping in Elasticsearch, mit dessen Hilfe wir beschreiben können, wie Dokumente in einem bestimmten Index gespeichert werden.
{
"air_measurements": {
"properties": {
"timestamp": {
"type": "date"
},
"location": {
"type": "geo_point"
},
"measurement": {
"properties": {
"value": {
"type": "double"
},
"who_limit": {
"type": "double"
},
"chemical": {
"type": "keyword"
},
"unit": {
"type": "keyword"
}
}
}
}
}
}
Sekundenschnelles Bereitstellen eines Clusters in Elastic Cloud
Sie könnten jetzt entweder lokal ein Elasticsearch-Cluster einrichten oder aber Ihren 14-tägigen Testzeitraum starten, um kostenlos den Elasticsearch Service in der Elastic Cloud zu nutzen. Wie Sie mit ein paar Klicks einen neuen Cluster einrichten, zeigen wir Ihnen hier. Ich verwende für diese Demonstration Elastic Cloud.
Nachdem Sie sich bei Elastic Cloud angemeldet haben, müssen Sie einen neuen Cluster bereitstellen. Bei der Überlegung, wie groß der Cluster für diesen Anwendungsfall sein soll, ist zu berücksichtigen, dass eine JSON-Datei mit den Messereignisdaten eines Monats ungefähr 34 MB Platz belegt (vor dem Indexieren), das heißt, wir können den kleinsten verfügbaren Cluster verwenden (1 GB RAM/24 GB Festplattenspeicherplatz). Dieser kleine Cluster dürfte für den Anfang genug sein, zumal das Skalieren in Elastic Cloud wirklich einfach ist, sodass wir die Cluster-Größe bei Bedarf jederzeit anpassen können. Dasselbe gilt auch für die Zahl der Verfügbarkeitszonen oder andere Änderungen in unserem Cluster.
Auf diese Weise haben wir in null Komma nichts einen Elasticsearch-Cluster zum Empfangen und Indexieren unserer Sammlung von Messereignissen gezaubert.
Extrahieren, Transformieren und Laden
Das Umwandeln der originalen CSV-Datei in viele einzelne JSON-Dokumente wird niemand gern manuell machen (Sisyphus lässt grüßen) – diese Aufgabe schreit geradezu nach Automatisierung.
Lassen Sie uns also zunächst ein Automatisierungsskript entwerfen, mit dem die CSV-Tabelle in einzelne JSON-Dokumente aufgeteilt wird. Die Programmiersprache Scala eignet sich dazu ganz hervorragend:
- Sie ermöglicht es, sich auf den Datenfluss zu konzentrieren, statt den Programmfluss im Blick haben zu müssen, was das Transformieren von Sammlungen von Dokumenten vereinfacht.
- Scala verfügt über eine Vielzahl von Bibliotheken zur JSON-Bearbeitung.
- Mit Ammonite wird das Schreiben von Datenbearbeitungsskripten fast schon zum Kinderspiel.
Der folgende Ausschnitt aus dem Skript extractor.sc fasst die Transformationslogik zusammen:
// Datei aus dem offenen Datenportal der Madrider Stadtverwaltung abrufen
lazy val sourceLines = scala.io.Source.fromURL(uri).getLines().toList
sourceLines.headOption foreach { head =>
/* Die erste Zeile der CSV-Datei enthält die Spaltenüberschriften.
Es ist kein Problem, ein Mapping zwischen Überschrift und Position
zu berechnen, damit der Rest des Codes lesbarer wird. */
lazy val label2pos = head.split(";").zipWithIndex.toMap
// For each line, we'll produce several events, that's easilt via flatMap
lazy val entries = sourceLines.tail flatMap { rawEntry =>
val positionalEntry = rawEntry.split(";").toVector
val entry = label2pos.mapValues(positionalEntry)
/* Die ersten 8 Positionen werden genutzt, um die Informationen zu
extrahieren, die für alle 24 Stundenmesswerte gelten. */
val stationId = entry("ESTACION").toInt
val ChemicalEntry(chemical, unit, limit) = chemsTable(entry("MAGNITUD").toInt)
// Die Messwerte sind in den letzten 24 Spalten enthalten
positionalEntry.drop(8).toList.grouped(2).zipWithIndex collect {
case (List(value, "V"), hour) =>
val timestamp = new DateTime(
entry("ANO").toInt,
entry("MES").toInt,
entry("DIA").toInt,
hour, 0, 0
)
// Und das ist das Ergebnis: Das generierte Ereignis als Fallklasse.
Entry(
timestamp,
location = locations(stationId),
measurement = Measurement(value.toDouble, chemical, unit, limit)
)
}
}
- Wir rufen den aktuellen stündlichen Bericht mit den Messdaten ab, die bis vor maximal einer Stunde erfasst wurden.
- Für jede Zeile:
- Wir extrahieren die Felder, die für alle aus der Zeile generierten Ereignisse gelten: Messstellenkennung (stationId) und Stoff, der gemessen wurde.
- Wir extrahieren die Daten für die heute gemessenen Messwerte (bis zu 24). Wir filtern diejenigen aus, die nicht als gültige Messwerte markiert sind.
- Für jeden dieser Messwerte generieren wir aus Rohdatum und Messwertspaltennummer einen Messwertzeitstempel. Wir kombinieren die für alle Ereignisse in der Zeile geltenden Felder, den Zeitstempel und den erfassten Wert zu einem gemeinsamen Ereignisobjekt (Entry).
Das Skript fährt mit der Serialisierung von Entry-Objekten als JSON-Dokumente und der Ausgabe dieser Dokumente als Folge unabhängiger JSONs fort.
Extractor.sc kann mit Argumenten angewiesen werden, die umzuwandelnden Daten aus anderen Quellen, z. B. lokalen Dateien, abzurufen oder die für das gemeinsame Hochladen von Dateien für einen ganzen Tag durch die Elasticsearch-Bulk-API erforderlichen Aktionen hinzuzufügen.
extractor --uri String (default http://www.mambiente.munimadrid.es/opendata/horario.csv) --bulkIndex --bulkType
Hochladen von Daten in Elasticsearch
Wir haben jetzt ein Skript, das die Umwandlung von CSV-Dateien in Listen von Dokumenten bewerkstelligt. Wie können wir diese Dokumente indexieren? Ganz einfach: Wir müssen nur ein paar Aufrufe für unser Cluster erstellen.
Indexerstellung
Die erste Aufgabe besteht darin, den Index zu erstellen. Wir haben ja bereits ein JSON-Dokument für unsere Dokument-Mappings, das wir in unsere Indexdefinition einbinden können: ./payloads/index_creation.json
{
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"air_measurements" : {
"properties" : {
"timestamp": { "type": "date" },
"location" : { "type" : "geo_point" },
"measurement": {
"properties": {
"value": { "type": "double" },
"who_limit": { "type": "double" },
"chemical": { "type": "keyword" },
"unit": { "type": "keyword" }
}
}
}
}
}
}
Dieses senden wir an den Indexerstellungsendpunkt unseres Clusters:
curl -u "$ESUSER:$ESPASS" -X PUT -H 'Content-type: application/json' \
"$ESHOST/airquality" \
-d "@./payloads/index_creation.json"
Das Ergebnis ist ein Index der Luftqualität.
Bulk-Upload
Am schnellsten lassen sich all diese Daten mit der Bulk-API in Elasticsearch laden: Verbindung herstellen, Dokumentenpaket hochladen und Vorgang abschließen – fertig! Wenn wir jedes Dokument einzeln hochladen würden, müssten wir für jede einzelne Messung in jeder Zeile der CSV-Datei eine TCP-Verbindung herstellen, das Dokument senden, auf eine Bestätigung warten und dann die Verbindung wieder schließen. Das ist viel zu ineffizient.
Die Bulk-API-Dokumentation schreibt vor, dass für jedes Dokument eine NDJSON-Datei mit zwei Zeilen pro Dokument hochgeladen werden muss.
- Die eine Zeile muss die in Elasticsearch auszuführende Aktion enthalten
- und die zweite das Dokument, das von der Aktion betroffen ist. Die Aktion, die uns hier interessiert, ist index (Indexieren).
extractor.sc verfügt daher über zwei zusätzliche Optionen, mit denen die Indexieren-Aktion und ihr Auftreten direkt vor jedem Dokument gesteuert werden können:
- bulkIndex INDEX – Mit dieser Option stellt das Extrahierungsskript jedem Dokument eine In INDEX indexieren-Aktion voran.
- bulkType TYPE – Wenn diese Option nach bulkIndex übergeben wird, wird die Indexieren-Aktion mit dem Typ abgeschlossen, mit dem das Dokument übereinstimmen soll.
/* Die Sammlung von Ereignissen wird dann serialisiert und gemäß Standardausgabe ausgegeben.
Wir können sie so als NDJSON-Datei verwenden.
*/
val asJsonStrings = entries flatMap { (entry: Entry) =>
Some(bulkIndex).filter(_.nonEmpty).toList.map { index =>
val entryId = {
import entry._
val id = s"${timestamp}_${location}_${measurement.chemical}"
java.util.Base64.getEncoder.encodeToString(id.getBytes)
}
/* Optional können wir für eine schnellere Datenübertragung
auch Bulk-Aktionen serialisieren. */
BulkIndexAction(
BulkIndexActionInfo(
_index = index,
_id = entryId,
_type = Some(bulkType).filter(_.nonEmpty)
)
).asJson.noSpaces
} :+ entry.asJson.noSpaces
}
asJsonStrings.foreach(println)
Dies erlaubt es uns, unsere riesige NDJSON-Datei mit allen Einträgen des Tages zu generieren:
time ./extractor.sc --bulkIndex airquality --bulkType air_measurements > today_bulk.ndjson
Das Generieren hat 1,46 Sekunden gedauert und wir haben jetzt eine Datei, die wir wie folgt an die Bulk-API senden können:
time curl -u $ESUSER:$ESPASS -X POST -H 'Content-type: application/x-ndjson' \
$ESHOST/_bulk \
--data-binary "@today_bulk.ndjson" | jq '.'
Das Hochladen hat 0,98 Sekunden in Anspruch genommen.
Insgesamt haben wir für diese Methode 2,44 Sekunden (1,46 Sekunden ab Datenabruf und -transformation plus 0,98 Sekunden ab der Bulk-Upload-Anforderung) benötigt. Das ist 182 Mal schneller, als wenn wir jedes Dokument einzeln hochgeladen hätten. Ja, Sie haben richtig gelesen: 2,44 Sekunden statt 7 Minuten und 26 Sekunden!
Eine wichtige Lehre ist also: Für Prozesse, die das Indexieren großer Dokumentenmengen beinhalten, sind Bulk-Uploads das Mittel der Wahl.
Von rohen Daten zu hilfreichen Erkenntnissen
Herzlichen Glückwunsch! Wir haben es jetzt geschafft, die Messwerte zur Luftqualität in Elasticsearch zu indexieren. Damit sind wir zum Beispiel in der Lage, ganz einfach die Dateien zu durchsuchen und abzurufen, ohne sie erst herunterladen, extrahieren und manuell durchsuchen zu müssen.
Stellen Sie sich einfach einmal vor, Sie haben eine Weile vor Velázquez’ Meisterwerk „Las Meninas“ verbracht und stehen jetzt vor der Wahl, ob Sie als Nächstes
- die Sonne Madrids genießen oder
- doch lieber noch etwas Zeit im Prado verbringen sollten.
Sie könnten Elasticsearch mit der folgenden Anfrage fragen, was für Ihre Gesundheit besser wäre: Wie lautete der letzte NO2-Messwert an der nächstgelegenen Messstation innerhalb eines Radius von 1 km?: ./es/payloads/search_geo_query.json
{
"size": "1",
"sort": [
{
"timestamp": {
"order": "desc"
}
},
{
"_geo_distance": {
"location": {
"lat": 40.4142923,
"lon": -3.6912903
},
"order": "asc",
"unit": "km",
"distance_type": "plane"
}
}
],
"query": {
"bool": {
"must": {
"match": {
"measurement.chemical": "NO2"
}
},
"filter": {
"geo_distance": {
"distance": "1km",
"location": {
"lat": 40.4142923,
"lon": -3.6912903
}
}
}
}
}
}
curl -H "Content-type: application/json" -X GET -u $ESUSER:$ESPASS $ESHOST/airquality/_search -d "@./es/payloads/search_geo_query.json"
Wenn die Antwort
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4248,
"max_score": null,
"hits": [
{
"_index": "airquality",
"_type": "air_measurements",
"_id": "okzC5mQBiAHT98-ka_Yh",
"_score": null,
"_source": {
"timestamp": 1532872800000,
"location": {
"lat": 40.4148374,
"lon": -3.6867532
},
"measurement": {
"value": 5,
"chemical": "NO2",
"unit": "μg/m^3",
"who_limit": 200
}
},
"sort": [
1532872800000,
0.3888672868035024
]
}
]
}
}
lautet, wüssten Sie, dass die Messstelle El Retiro zuletzt einen NO2-Gehalt von 5 μg/m³ gemeldet hat. Angesichts des WHO-Grenzwertes von 200 μg/m³ ist das alles andere als ein schlechter Wert – Zeit für Tapas!
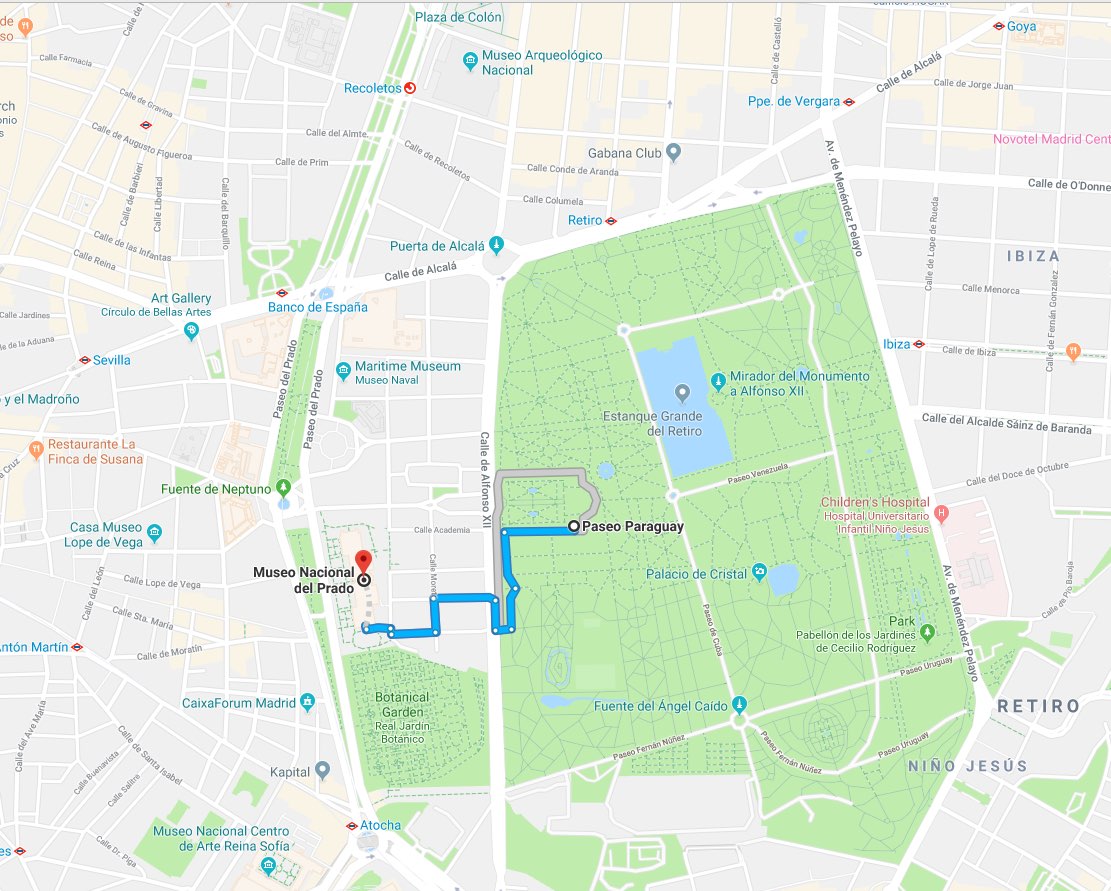
Nun muss ich zugeben, dass ich noch nie gesehen habe, dass jemand im Museum den Laptop zückt und beginnt, cURL-Befehle zu schreiben. Fakt ist allerdings, dass diese Anfragen in praktisch allen Programmiersprachen so einfach zu programmieren sind, dass sich Frontend-Anwendungen innerhalb weniger Tage bereitstellen lassen. Schließlich haben wir mit unserem Informationsindex bereits ein ausgewachsenes Analytics-Backend parat.
Mit Kibana Unsichtbares sichtbar machen
Und wie wäre es, wenn wir gar keine eigene Anwendung schreiben müssten? Wenn wir einfach nur den vorhandenen Cluster nehmen und mit der Erkundung der Daten anfangen könnten, indem wir uns durch aufschlussreiche Informationen durchklicken? Kibana macht’s möglich. Wir können unter cloud.elastic.co zu unserer Cluster-Verwaltung gehen und dort auf den Link zu unserem Kibana-Deployment klicken:
Mit Kibana können wir umfassende Visualisierungen und Dashboards erstellen, deren Daten auf den in Elasticsearch indexierten Dokumenten beruhen.
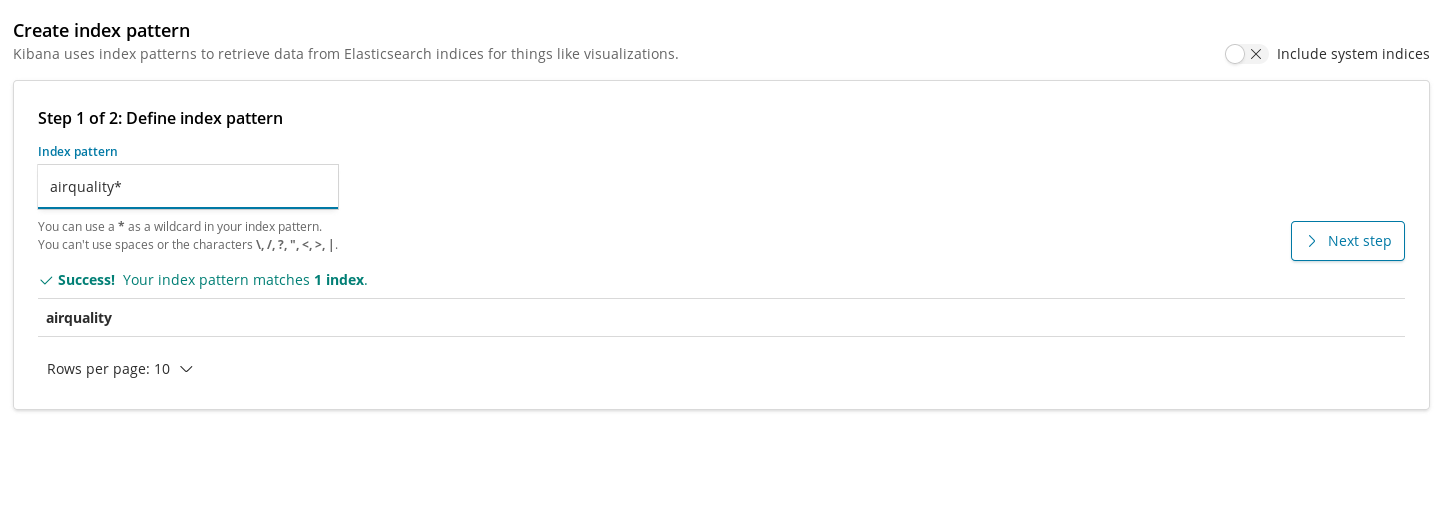
Zum Registrieren von Indizes in Kibana können wir Indexmuster verwenden. Diese können dann zum Abrufen von Daten für Visualisierungen genutzt werden. Bevor wir also mit dem Erstellen von Diagrammen für unseren Index der Luftqualität beginnen, müssen wir ihn registrieren.
Anschließend können wir unsere erste Visualisierung hinzufügen. Beginnen wir mit etwas Einfachem und stellen die Entwicklung der durchschnittlichen Konzentration eines Stoffes im Stadtgebiet im Laufe der Zeit dar. Nehmen wir als Beispiel NO2:
Als Erstes müssen wir ein Liniendiagramm erstellen, bei dem die Y-Achse die aggregierten Durchschnittswerte für das Feld measurement.value in den auf der X-Achse dargestellten Stundeneinheiten zeigt. Für die Auswahl des Zielstoffes können wir die Abfrageleiste von Kibana verwenden, mit der wir nach NO2-Messwerten filtern können. Und wenn wir die Funktion Autocomplete aktivieren, können wir uns Schritt für Schritt durch die Definition der Suchanfrage leiten lassen.
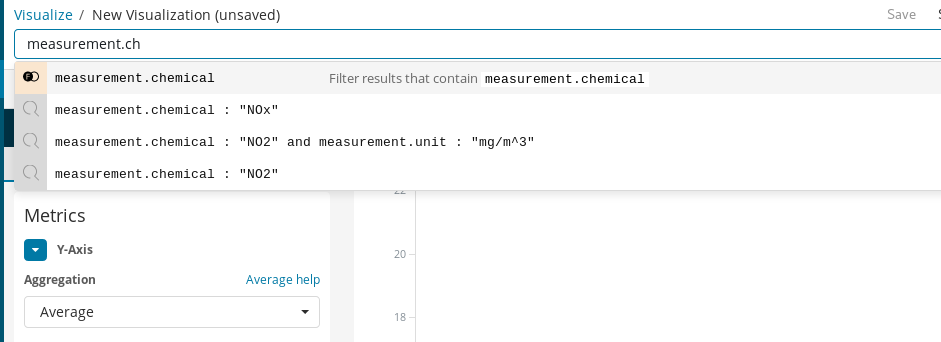
Mit Time Range wählen wir schließlich noch den Zeitbereich der zu visualisierenden Daten aus.
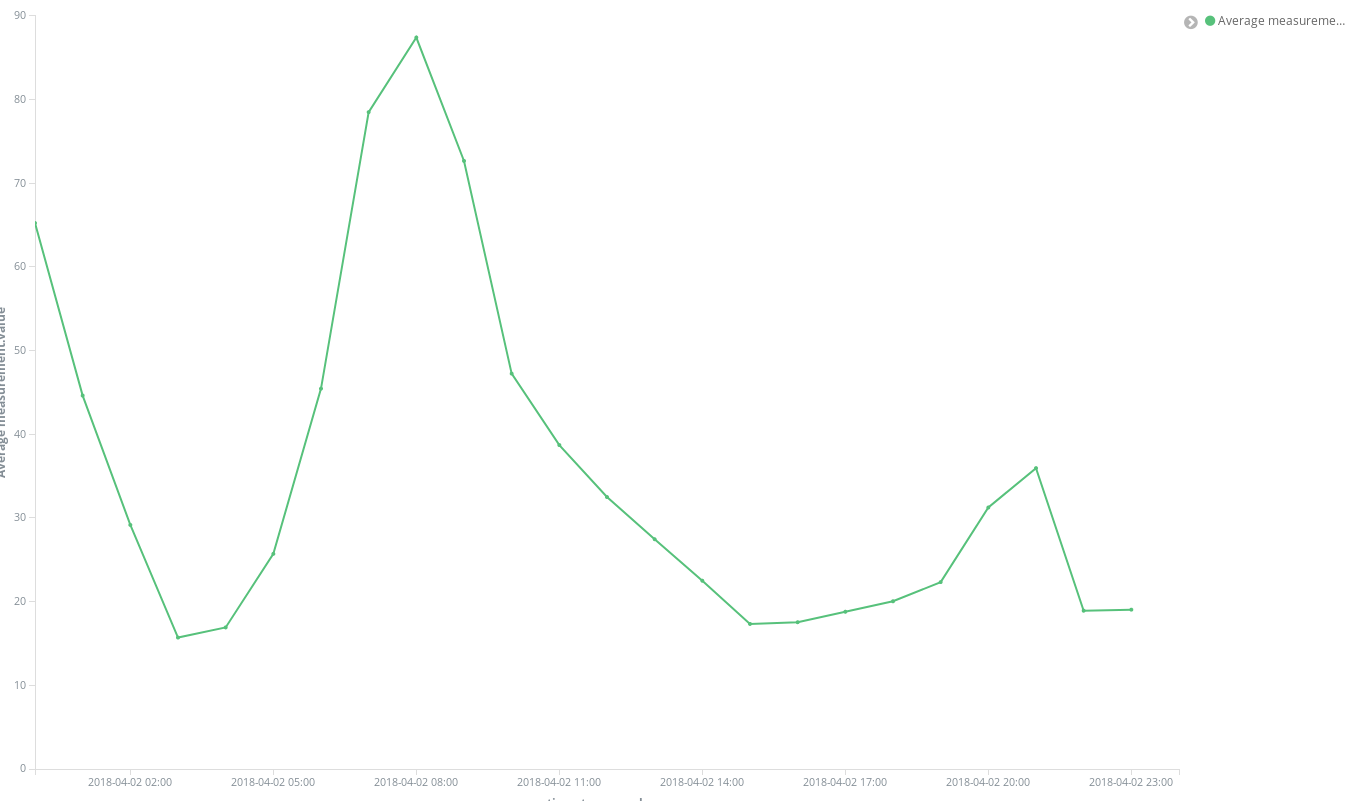
Mit einigen wenigen Klicks erhalten wir sofort ein Ergebnis:
Zu den hilfreichen Diagrammarten, die wir für diese Daten verwenden können, gehören die Koordinatenkarten. Da für jeden Messwert die Koordinaten der Messstelle bereitgestellt werden, können wir darstellen, wo die Luftverschmutzung besonders hoch ist. Damit wechseln wir von der Ermittlung der Durchschnittswerte für räumliche Einträge in Zeitunterteilungen zur Ermittlung der Durchschnittswerte von Zeiteinträgen in räumlichen Positionen. Eingeteilt wird also jetzt nach Geohash-Aggregationen nach Ort – dem Feld, das den Messpunkt enthält.
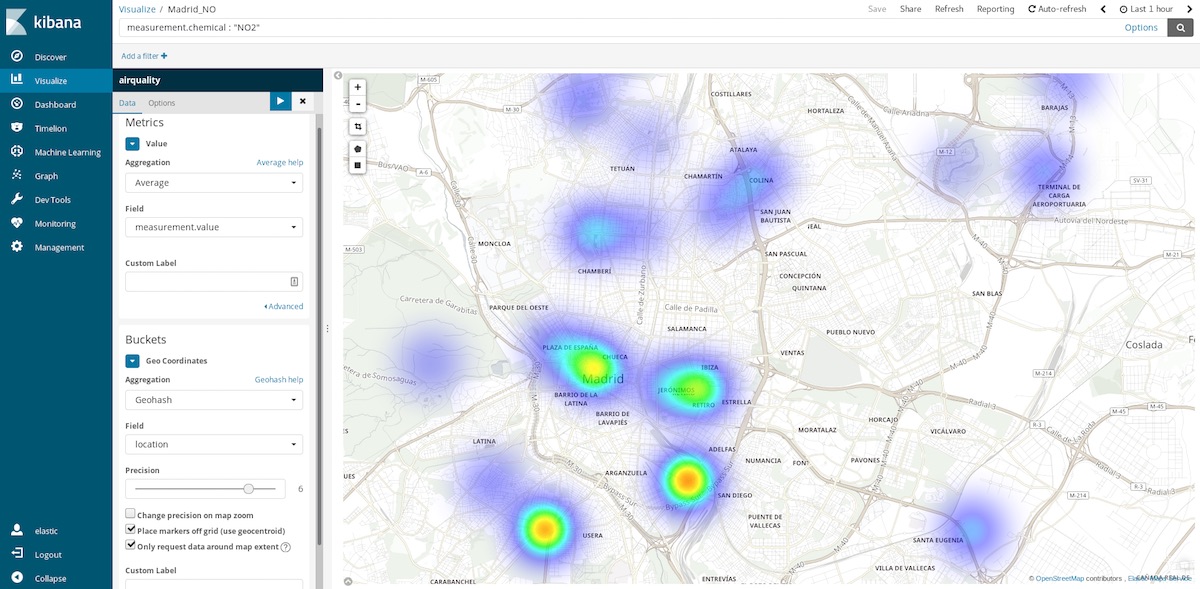
Wenn wir den Zeitbereich letzte Stunde wählen, können wir herausfinden, wo die Luft gerade am saubersten ist. Jährliche Zeitbereiche geben Auskunft darüber, in welchen Gegenden die Luft im Durchschnitt am saubersten ist. Diese Informationen lassen sich zum Beispiel nutzen, wenn es darum geht, wo man aus gesundheitlichen Gründen besser kein Wohneigentum erwerben sollte.
Geskriptete Felder
Da unsere Dokumente für einige Stoffe auch die WHO-Richtwerte enthalten, kann visualisiert werden, wie ungesund die Luft ist. Dies kann zum Beispiel mithilfe einer Tachometerdiagramm-Visualisierung dargestellt werden, die zeigt, wie sich der gemessene Wert zum WHO-Grenzwert verhält. Allerdings wurde diese Aufteilung beim Laden der Daten nicht durchgeführt. Das ist aber kein Problem, weil es dank der Skripting-Sprache Painless möglich ist, auf der Basis der indexierten Felder neue Felder zu generieren. Painless ist leicht verständlich, und wer schon einmal Java genutzt hat, findet sich schnell darin zurecht. (Seit Kibana 6.4 kann man sich auch eine Vorschau der Ergebnisse des Painless-Skripts anzeigen lassen.)
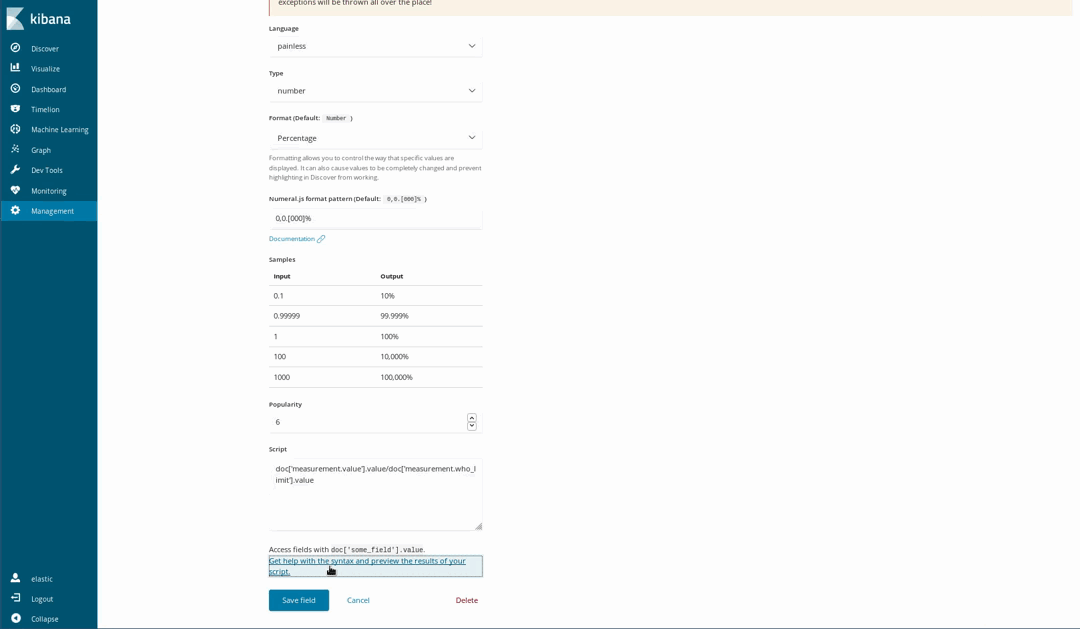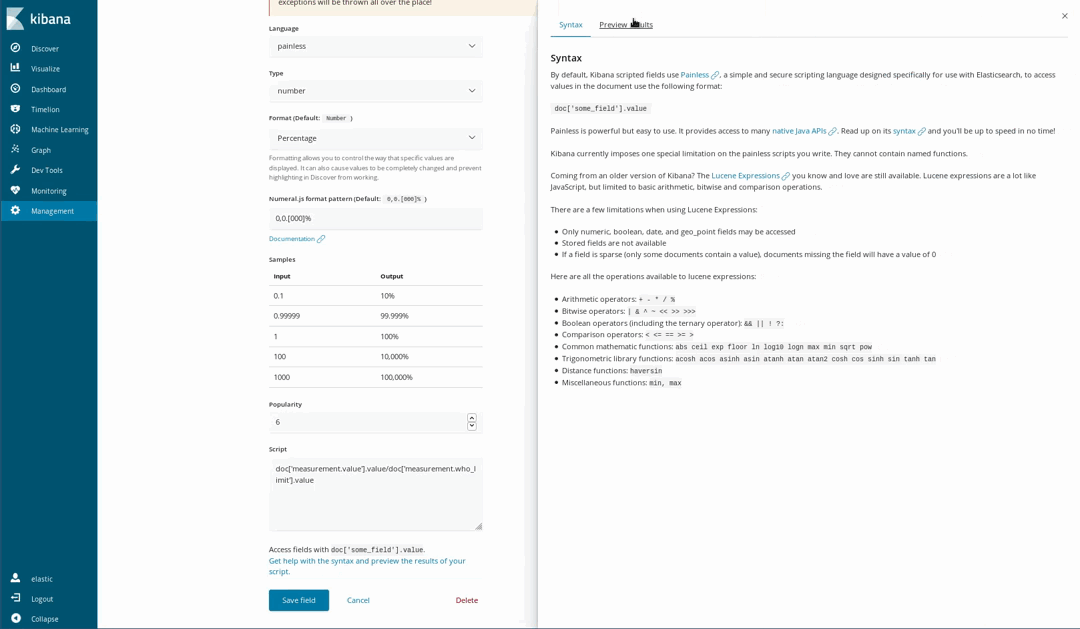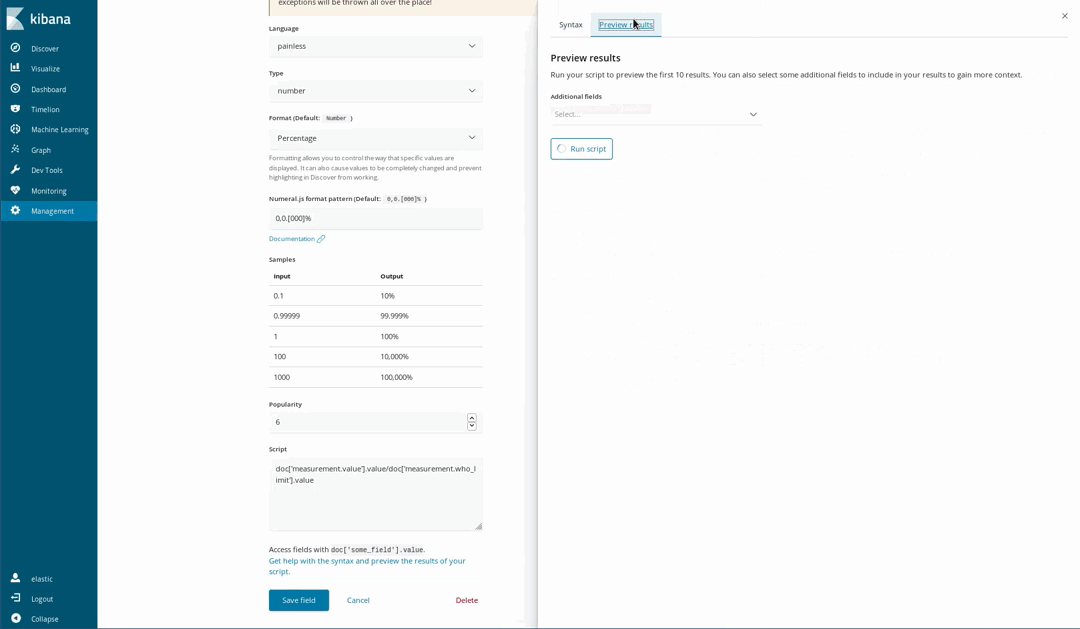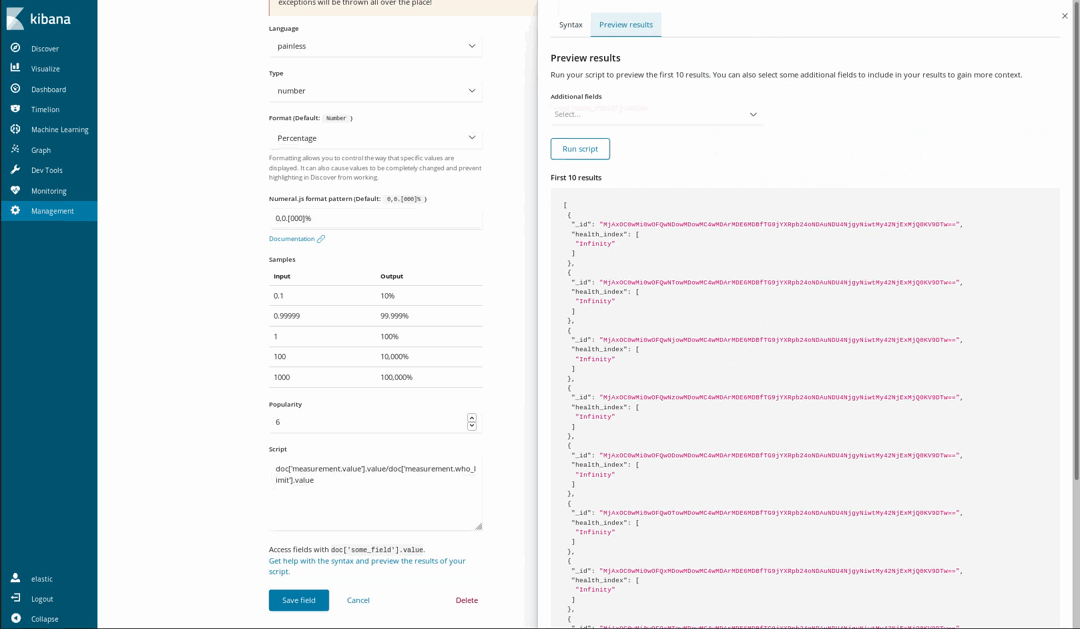
Anschließend verwenden wir die Felder in unseren Visualisierungen, als wären sie normale indexierte Felder:
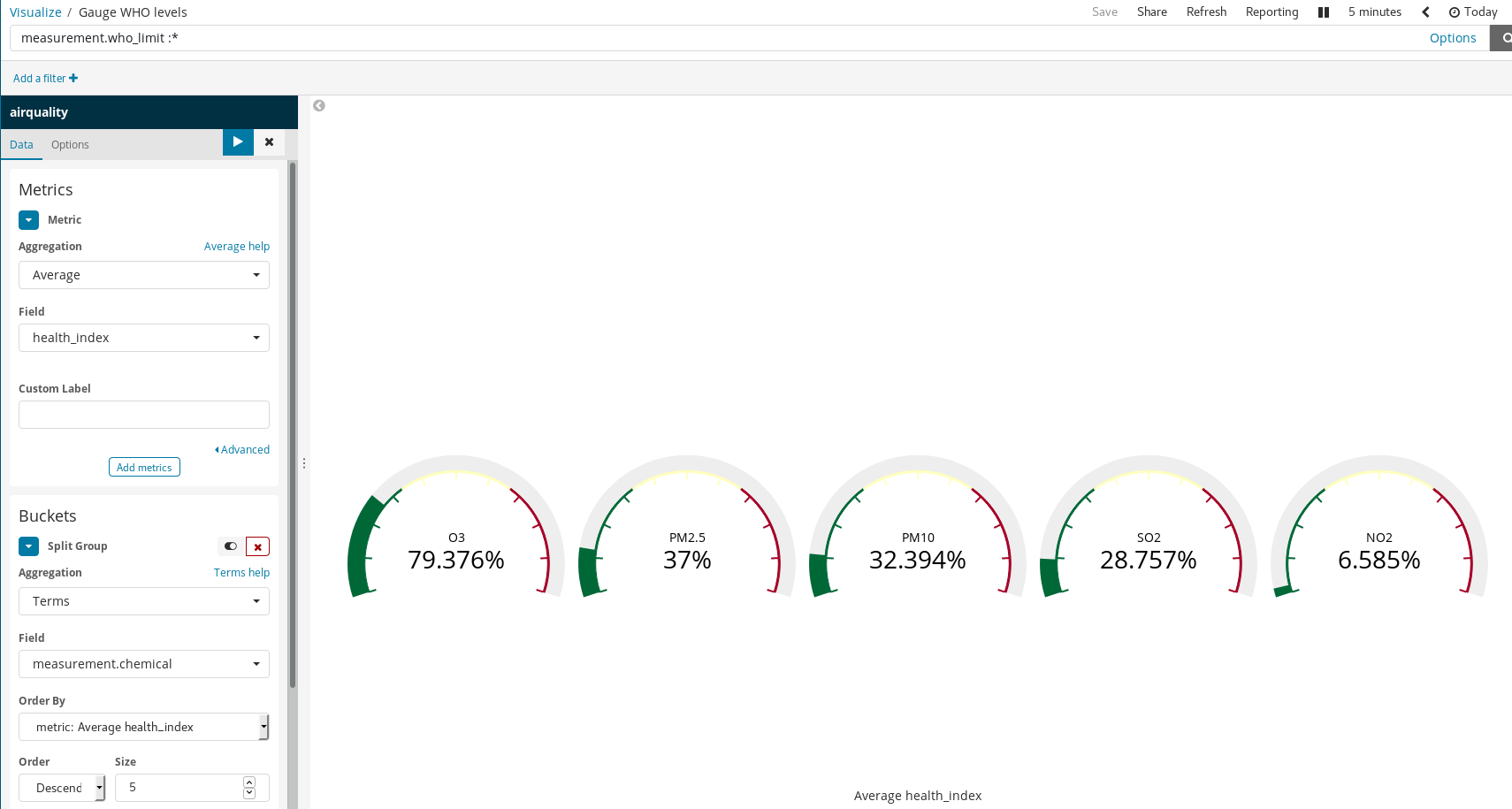
Beachten Sie, wie Kibana es schafft, mit einfachen Regeln aussagekräftige Visualisierungen zu erstellen. Im Beispiel oben haben wir
- Dokumente gefiltert und nur diejenigen ausgewählt, für die es WHO-Grenzwerte gibt, und
- auf
measurement.chemicaldie Funktionen „Split Groups“ und „Term Aggregation“ angewendet.
Das Ergebnis ist ein Tachometerdiagramm für jeden Stoff, für den es bekannte WHO-Grenzwerte gibt.
Darstellung der Luftverschmutzung in Madrid
Kibana-Visualisierungen können für die Erstellung von Dashboards genutzt werden, die Visualisierungen aggregieren und damit wertvolle Instrumente für das Interpretieren und Verstehen des Zustands eines Systems in Echtzeit darstellen. In unserem Beispiel ist das System die Zusammensetzung der Atmosphäre und deren Wechselwirkung mit den Aktivitäten der Menschen.
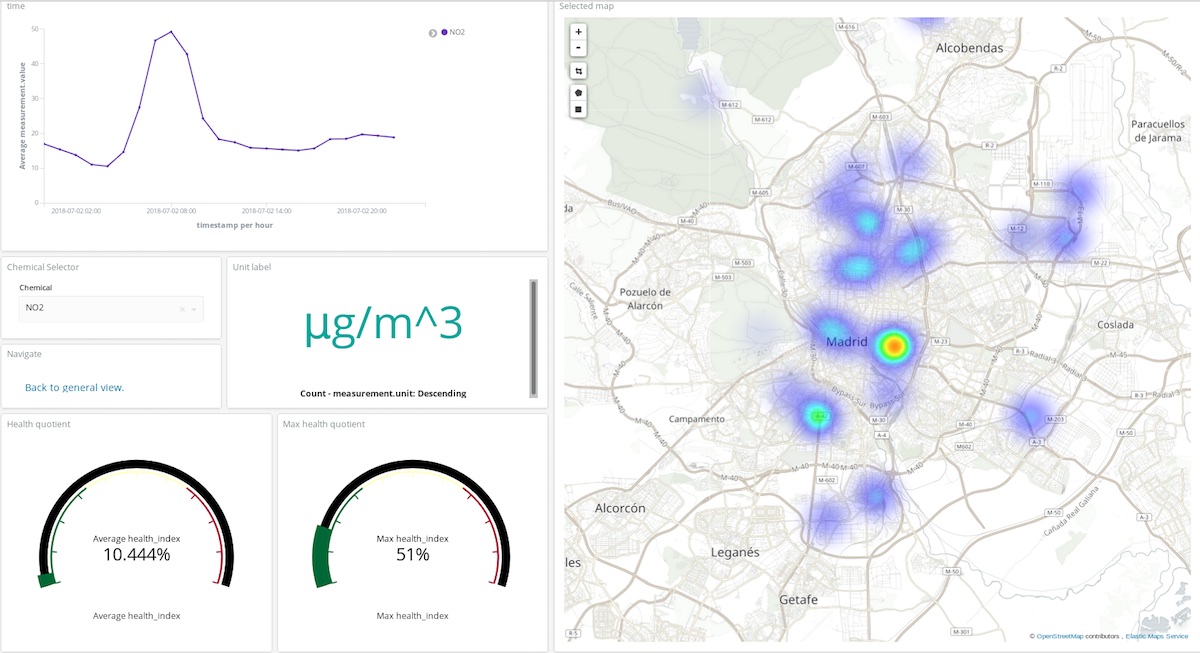
Im Dashboard oben kann der Benutzer einen Stoff und einen Zeitraum auswählen, um sich einen guten Überblick darüber zu verschaffen, wo und in welcher Menge dieser Stoff die Atmosphäre verschmutzt. Sehen Sie sich das Ganze doch einmal an! (Benutzername: test, Passwort: madrid_air).
Man kann sich auch ein allgemeines Bild von der Luftqualität in Madrid machen (gleicher Benutzername, gleiches Passwort).
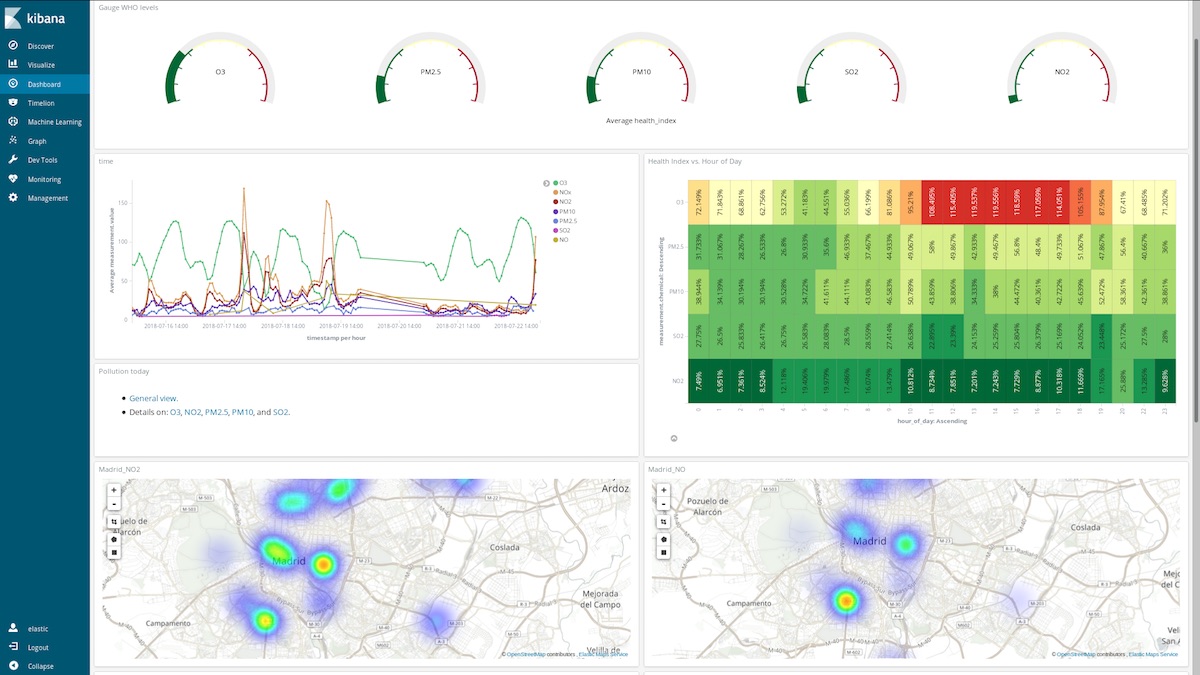
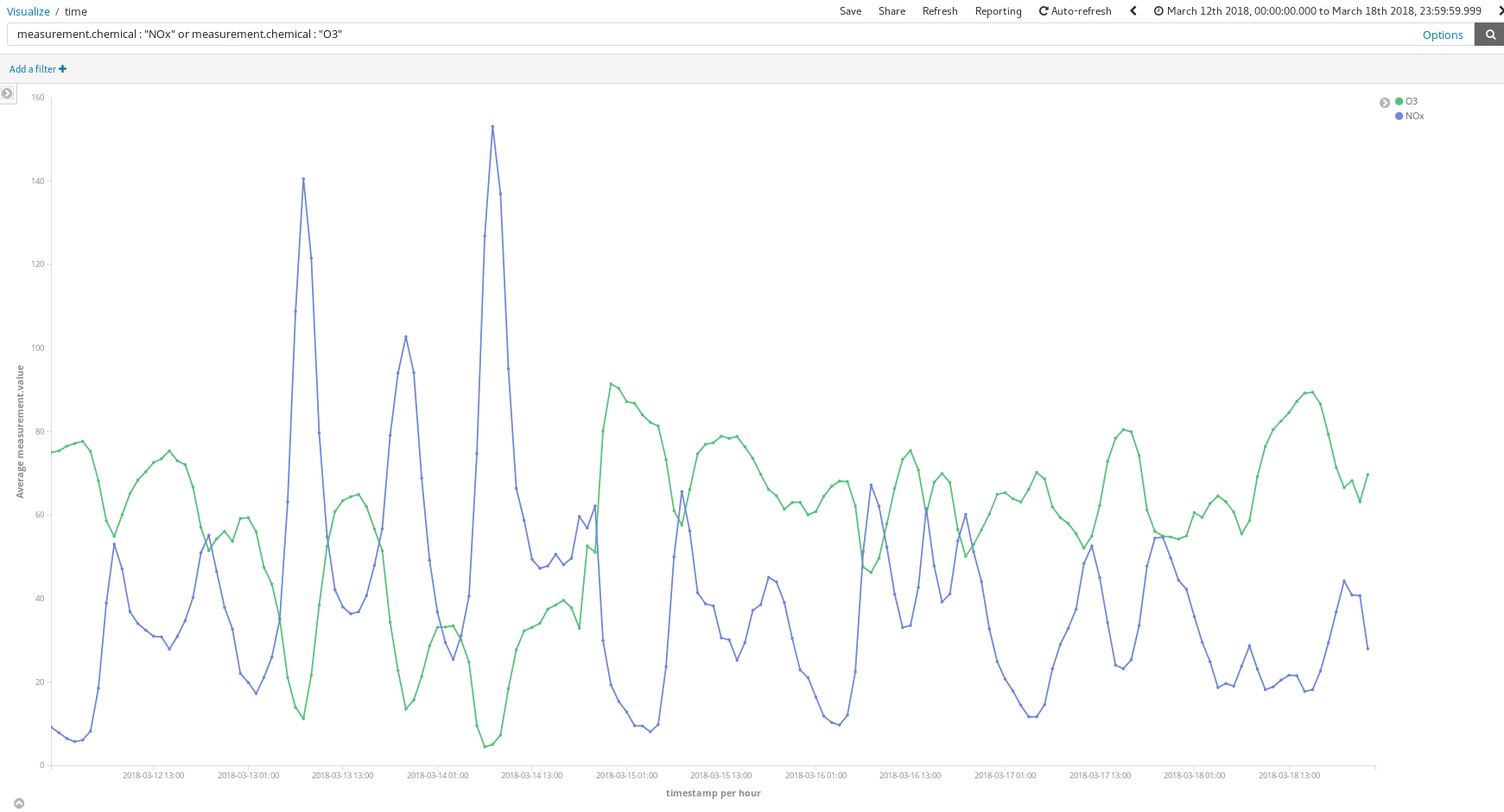
Was bringen mir diese Dashboards? Schauen wir uns doch einmal eine beliebige Woche im März an (12. März bis 18. März):
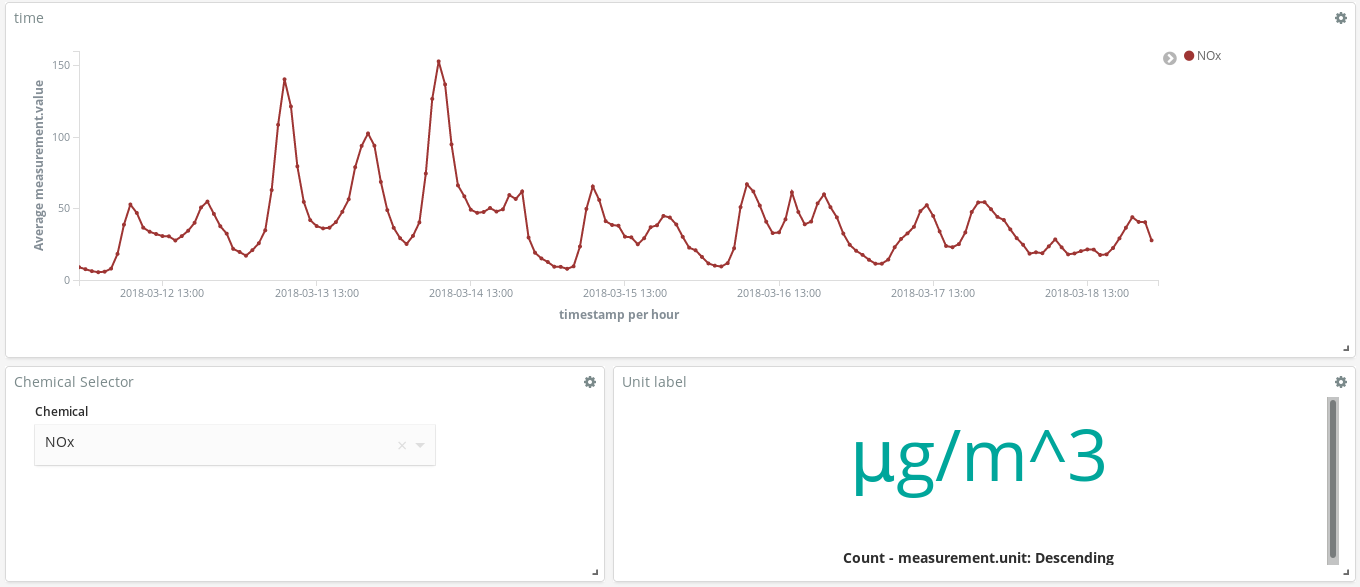
Sagen diese Spitzenwerte bei NOx (eine Verbindung, die durch Dieselabgase in die Luft gelangt) etwas über die Gewohnheiten der Madrilenen aus? Aber ja doch – die Spitzenwerte treten zweimal pro Tag auf …
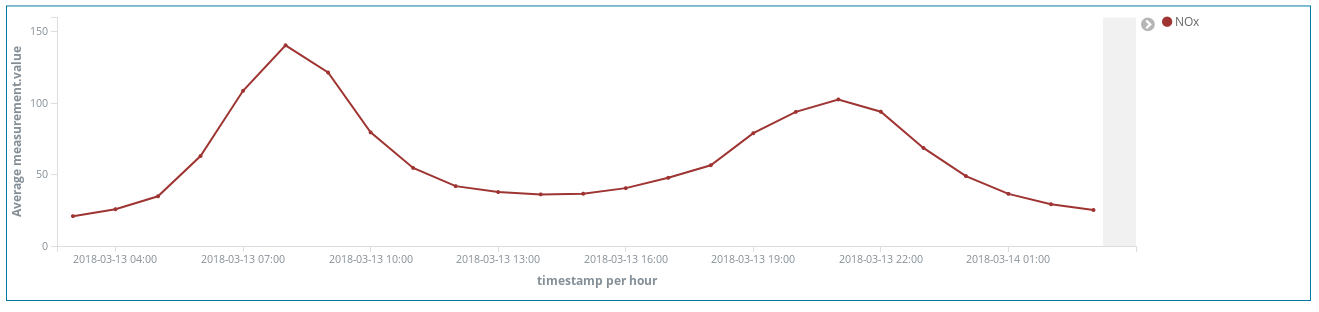
Der erste gegen 8 Uhr und der zweite gegen 21 Uhr. Wir sehen hier einen Anstieg bei der Nutzung von Dieselautos im morgendlichen Berufsverkehr. Tagsüber stehen die Autos im Wesentlichen irgendwo herum, sodass die Luftbelastung erst wieder ansteigt, wenn der Feierabendverkehr einsetzt.
Außerdem ist ein bemerkenswerter Zusammenhang zwischen hohen O3-Werten und niedrigen NOx-Werten feststellbar. O3 ist ein Nebenprodukt der Reaktion von NOx mit organischen Verbindungen bei Sonnenlicht, sodass eine Korrelation zwischen NOx und O3 zu erwarten ist.
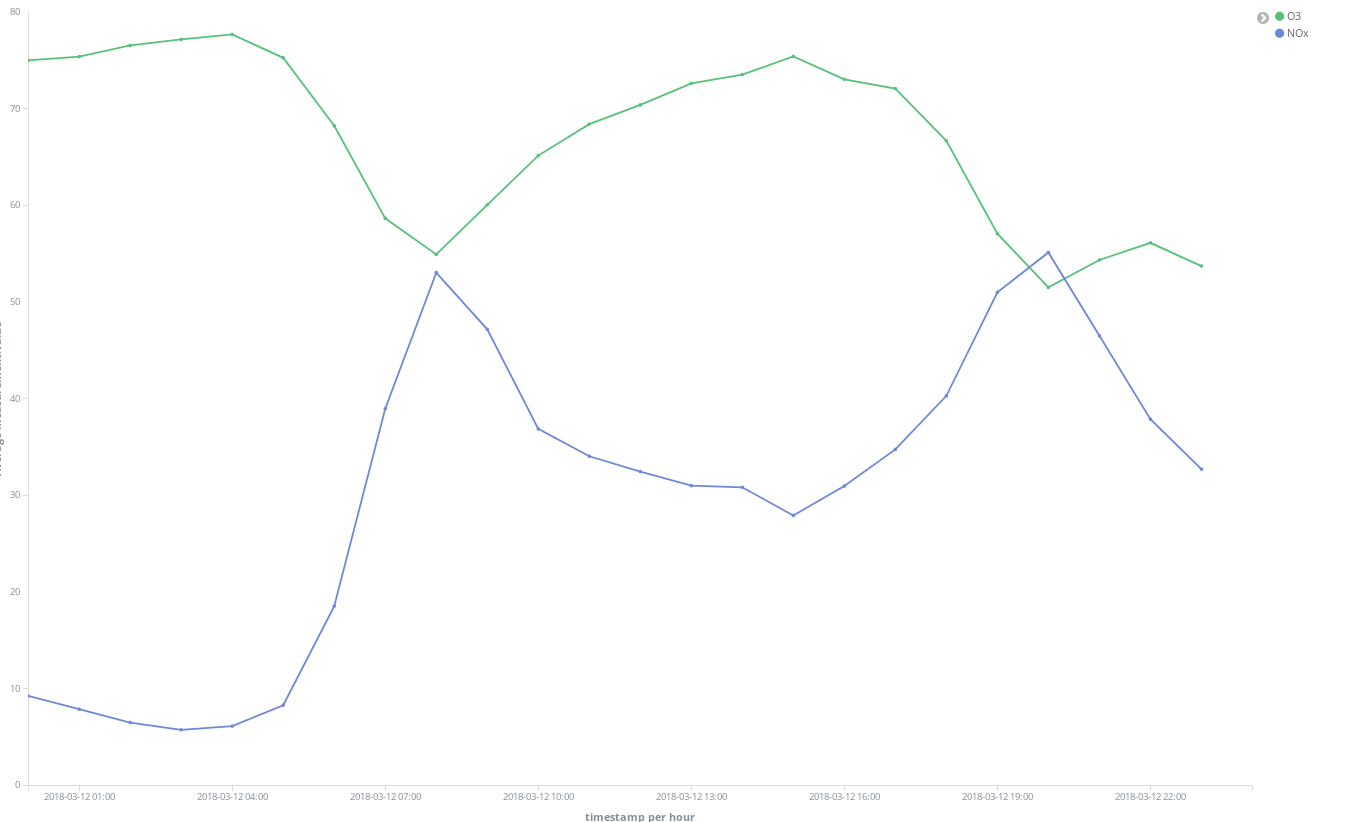
Darüber hinaus lässt sich feststellen, dass sich die allgemeine Situation an den Wochenenden entspannt:
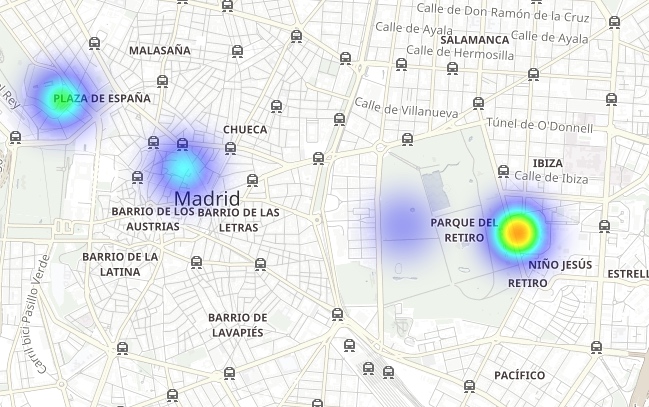
Die folgende Visualisierung zeigt, dass der Park El Retiro (eine große Grünfläche im Herzen der Stadt) von einigen besonders NO2-belasteten Gebieten umgeben ist, während der Park selbst durch die dichte Vegetation und den fehlenden Verkehr relativ verschont bleibt:
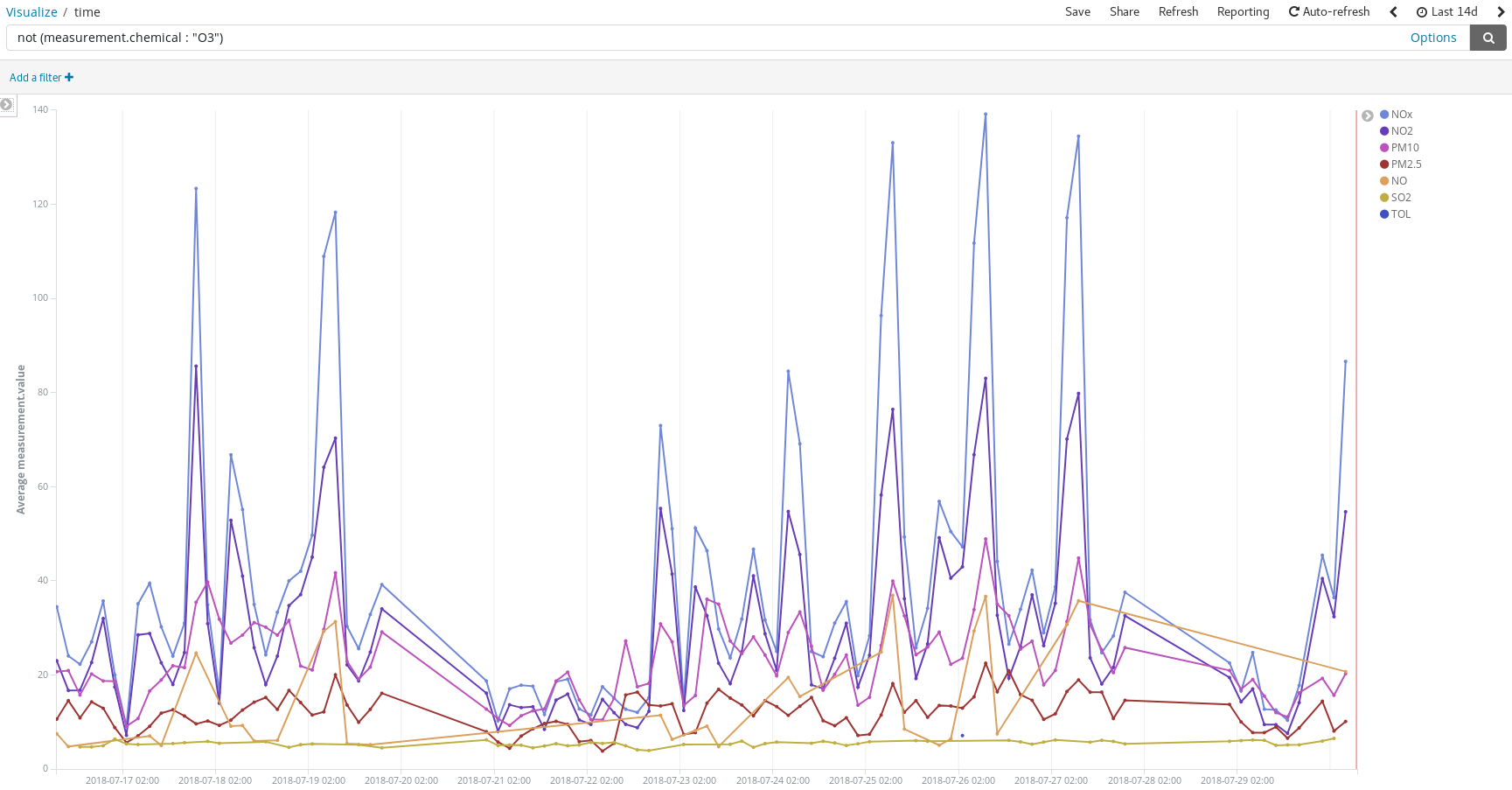
Wir können auch nach Verschmutzungsspitzen an den Tagen Ausschau halten, an denen sich die Leute mit ihren Autos auf den Weg in den Sommerurlaub machen:
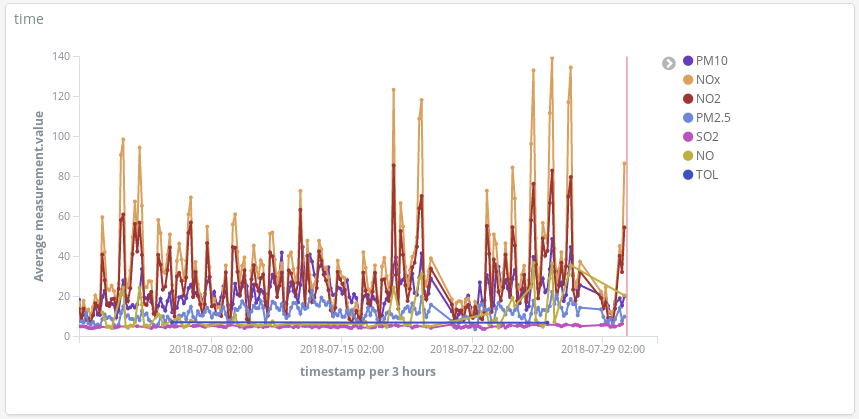
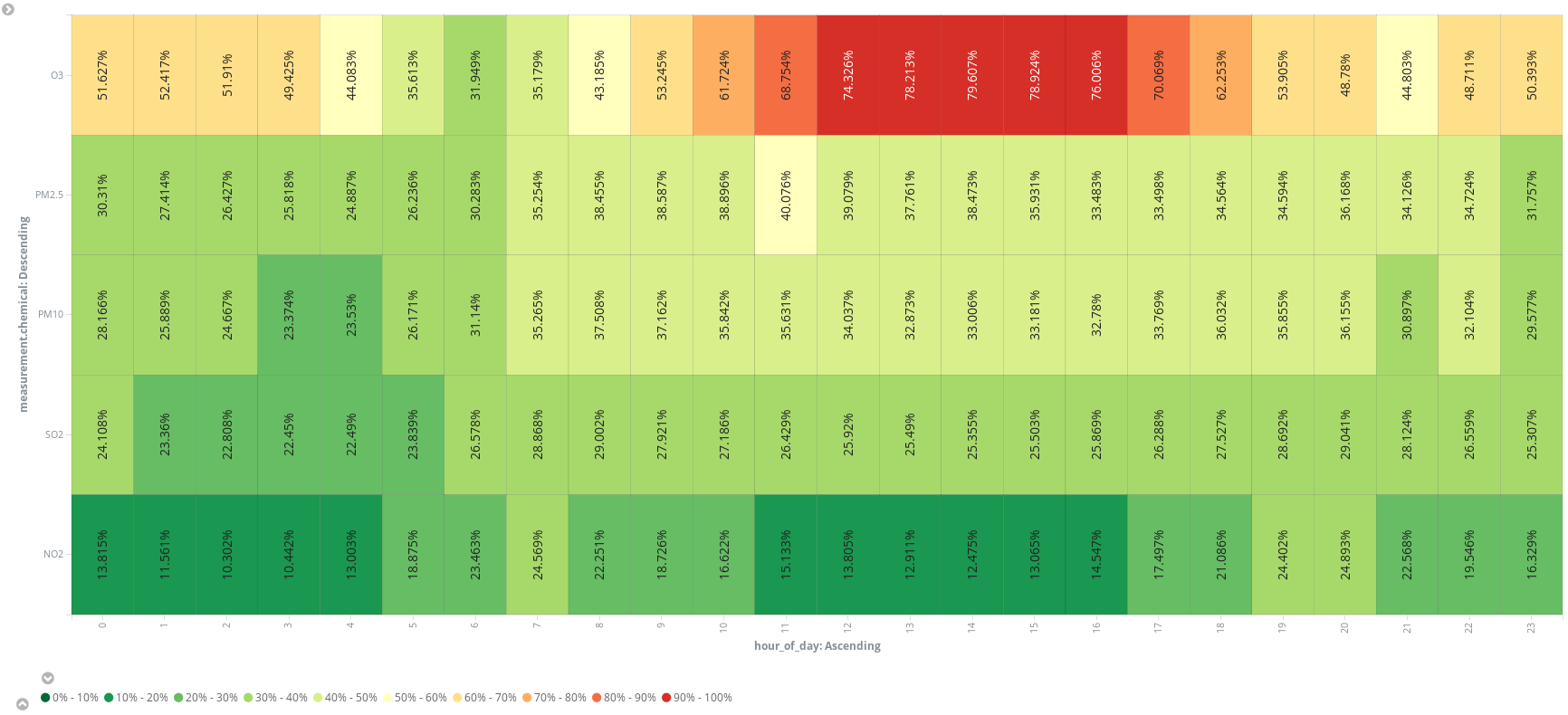
Oder ein zusätzliches geskriptetes Feld (hour_of_day) hinzufügen, um die Daten nach Stunden innerhalb eines Tages aufzuteilen und die Durchschnittswerte nach Stoff geordnet in einer Heatmap darzustellen. So wie es aussieht, sollte man seine Joggingrunde am besten um 6 Uhr morgens drehen:
Schaut man sich dies alles an, kommt man nicht umhin festzustellen, dass da mehr in der Luft liegt als nur Stickstoff, Sauerstoff, Kohlendioxid, Argon und Wasser. Ergo: Es ist nicht die reine Luft, die wir einatmen, wenn wir uns zum Promenieren auf die Gran Via in Madrid begeben! Aber das Gleiche gilt sicherlich auch für Flaneure in Manhattan. Wie wär’s, wenn Sie das einmal selbst prüfen? Den Weg dahin kennen Sie ja jetzt. Alles, was Sie jetzt noch brauchen, ist eine frei verfügbare Datenquelle …
Fazit
Wenn es unsere Aufgabe gewesen wäre, den Datenanalysten in unserer Firma Tools zur Analyse der Luftverschmutzung in Madrid bereitzustellen, hätten wir lediglich das Indexmuster Luftqualität in Kibana registrieren und eine E-Mail mit dem Zugangslink versenden müssen – unsere Arbeit wäre erledigt gewesen und die Datenanalysten hätten etwas zum Herumspielen gehabt. Der Elastic Stack bietet einen vollständigen Analytics-Stack, der in Minutenschnelle und sehr intuitiv Antworten bereitstellt, wobei lediglich Code für die geskripteten Felder geschrieben werden muss (sofern erforderlich).
Die Elastic Cloud macht es möglich, dass wir als Data Engineers lediglich ein paar Klicks ausführen und den ETL(Extract Transform Load)-Dienst schreiben müssen. Aber ist es überhaupt nötig, einen ETL zu schreiben, um Daten abzurufen und sie in Elasticsearch zu importieren? Der nächste Blogpost zeigt Ihnen, dass der Elastic Stack auch das übernehmen kann.