Einführung in die moderne Verarbeitung natürlicher Sprache mit PyTorch in Elasticsearch


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Zu den neuen Funktionen von Version 8.0 gehört die Möglichkeit, mit PyTorch erstellte Machine-Learning-Modelle in Elasticsearch hochzuladen, um im Elastic Stack moderne Funktionen zur Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) anbieten zu können. So können Elasticsearch-Nutzer:innen eines der beliebtesten Formate für das Erstellen von NLP-Modellen integrieren und diese Modelle als Teil einer NLP-Datenpipeline mit unserem Inferenzprozessor in Elasticsearch einbinden. Die Kombination aus neuen ANN-Search-APIs und dem Einsatz von PyTorch-Modellen eröffnet ganz neue Möglichkeiten für die Arbeit mit Elastic Enterprise Search.
Was ist NLP?
„NLP“ steht für „Natural Language Processing“, also die Verarbeitung natürlicher Sprache, und bezieht sich auf die Art und Weise, wie wir Software einsetzen können, um „natürliche Sprache“, also alles das, was wir Menschen ganz normal sprechen oder schreiben, zu verarbeiten und zu verstehen. Google hat 2018 unter der Bezeichnung „Bidirectional Encoder Representations from Transformers“ – kurz „BERT“ genannt – ein neues Verfahren für das NLP-Vortraining auf Open-Source-Basis bereitgestellt. BERT arbeitet mit dem sogenannten „Transfer Learning“-Verfahren, das heißt, für das Training, das vollautomatisch und ohne jede menschliche Einmischung stattfindet, werden Datensätze in für das Internet typischen Größen (z. B. Wikipedia und digitale Bücher in ihrer Gesamtheit) herangezogen.
Durch Transfer Learning kann ein BERT-Modell so vortrainiert werden, dass es normale, nicht fach- oder jargonspezifische Sprache (General Purpose Language, GPL) versteht. Ein nur einmal vortrainiertes Modell kann immer wieder von Neuem verwendet und für spezifischere Aufgaben feinabgestimmt werden. Ziel dabei ist, dass das Modell versteht, wie Sprache verwendet wird.
Zur Unterstützung von BERT-ähnlichen Modellen – also von Modellen, die denselben Tokenizer wie BERT nutzen – wird Elasticsearch dank der neuen Unterstützung für PyTorch-Modelle nach und nach die Mehrzahl der gängigsten NLP-Aufgaben unterstützen. PyTorch ist eine der beliebtesten modernen Machine-Learning-Bibliotheken mit einer großen aktiven Nutzer-Community. Sie unterstützt tiefe neuronale Netze, darunter die Transformer-Architektur, die auch BERT verwendet.
Im Folgenden haben wir für Sie ein paar Beispiele für NLP-Aufgaben zusammengestellt:
- Sentimentanalyse: Binäre Klassifizierung zur Unterscheidung von positiven und negativen Aussagen
- Erkennung benannter Entitäten (Named Entity Recognition, NER): Strukturierung von unstrukturiertem Text, um z. B. Details wie Name, Ort oder Organisation zu extrahieren
- Textklassifizierung: Die Zero-Shot-Klassifizierung ermöglicht es, Text auf der Grundlage zuvor ausgewählter Klassen zu klassifizieren, ohne dass dem ein Vortraining vorausging.
- Texteinbettungen: Kommt bei der Suche nach dem nächsten Nachbarn anhand des „k-Nearest-Neighbor“-Algorithmus (kNN) zum Einsatz

NLP in Elasticsearch
Mit der Integration von NLP-Modellen in die Elastic-Plattform wollten wir das Hochladen und Verwalten von Modellen einfacher und intuitiver gestalten. Mit dem Eland-Client zum Hochladen von PyTorch-Modellen und der Kibana-Benutzeroberfläche zur Verwaltung von ML-Modellen auf einem Elasticsearch-Cluster können Nutzer:innen verschiedene Modelle ausprobieren und sich ansehen, wie die Modelle bei ihren Daten funktionieren. Außerdem wollten wir für Skalierbarkeit über mehrere verfügbare Knoten in einem Cluster hinweg sowie für einen guten Inferenz-Durchsatz sorgen.
Zu diesem Zweck brauchten wir eine Machine-Learning-Bibliothek, die Inferenz ermöglichte. Damit PyTorch in Elasticsearch unterstützt werden kann, musste die native Bibliothek libtorch genutzt werden, die ihrerseits PyTorch unterstützt. Außerdem werden nur PyTorch-Modelle unterstützt, die als TorchScript-Darstellung exportiert oder gespeichert wurden. Dies ist die von libtorch benötigte Modelldarstellungsform und wenn sie verwendet wird, benötigt Elasticsearch keinen Python-Interpreter.
Durch die Integration mit einem der gängigsten Formate für das Erstellen von NLP-Modellen in PyTorch-Modellen kann Elasticsearch eine Plattform bereitstellen, die mit einer Vielzahl von NLP-Aufgaben und ‑Anwendungsfällen funktioniert. Für das Training von NLP-Modellen gibt es eine Reihe hervorragender Bibliotheken, sodass wir dafür erst einmal kein eigenes Tool bereitstellen müssen. Es spielt keine Rolle, ob Sie Ihre Modelle mit Bibliotheken wie PyTorch NLP, Hugging Face Transformers oder fairseq von Facebook trainieren: Sie können Ihre Modelle in Elasticsearch importieren und sie inferenzieren. Das Inferenzieren in Elasticsearch wird zunächst nur zum Zeitpunkt des Ingestierens erfolgen, es ist aber möglich, dass dieser Prozess zukünftig auch zum Zeitpunkt der Abfrage stattfindet.
Bislang mussten zum Integrieren von NLP-Modellen API-Aufrufe und Plugins sowie andere Optionen zum Streamen von Daten zu und aus Elasticsearch genutzt werden. Durch die neue Möglichkeit, NLP-Modelle als Teil Ihrer Elasticsearch-Datenpipeline zu integrieren, ergeben sich die folgenden Vorteile:
- Sie können eine bessere Infrastruktur um Ihre NLP-Modelle herum erstellen.
- Sie können das Inferenzieren Ihres NLP-Modells skalieren.
- Die Sicherheit und der Schutz Ihrer Daten bleiben gewahrt.
NLP-Modelle können zentral in Kibana verwaltet werden, was eine Verteilung von Abfragen auf die verschiedenen Machine-Learning-Knoten möglich macht, um für Lastausgleich zu sorgen.
Inferenzaufrufe mit den PyTorch-Modellen als Ziel können über den Cluster verteilt werden und erlauben das spätere Skalieren, wenn die Last es erfordert. Die Performance lässt sich verbessern, indem Daten nicht immer wieder verschoben werden und indem Cloud-VMs für CPU-basiertes Inferenzieren optimiert werden. Durch das Integrieren von NLP-Modellen in Elasticsearch können wir Daten in einem zentralisierten, gesicherten Netzwerk halten und so für Datenschutz und Compliance sorgen. Die Einbindung von NLP-Modellen in Elasticsearch verbessert sowohl die gemeinsame Infrastruktur als auch die Abfragegeschwindigkeit und den Datenschutz.
Workflow zur Implementierung eines PyTorch-NLP-Modells
Das Implementieren eines NLP-Modells mit PyTorch ist recht einfach. Der erste Schritt besteht darin, dass wir unsere Modelle in Elasticsearch hochladen müssen. Dazu können wir beispielsweise die REST-APIs verwenden, die von jedem Elasticsearch-Client aus genutzt werden können, aber wir wollten diesen Prozess noch einfacher gestalten. In unserem Eland-Client, unserer Python Data Science-Bibliothek für den Elastic Stack, werden wir einige sehr einfache Methoden und Skripte bereitstellen, mit denen Sie Modelle von der lokalen Festplatte hochladen oder Modelle aus dem Hugging Face-Modellhub herunterladen können (was eine der beliebtesten Möglichkeiten für das Teilen trainierter Modelle ist). In beiden Fällen wird es Tools geben, die helfen, PyTorch-Modelle in ihre TorchScript-Darstellungen zu konvertieren und schließlich Modelle in einen Cluster hochzuladen.
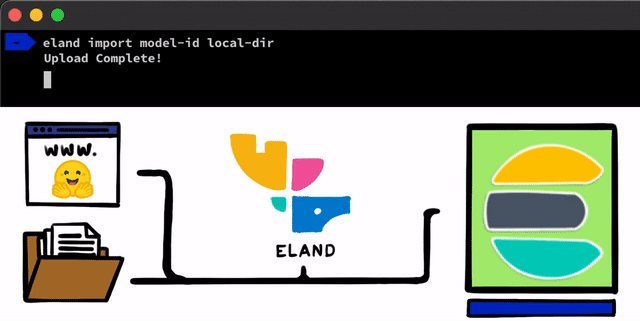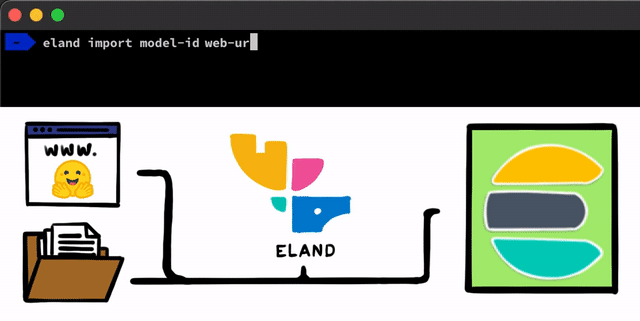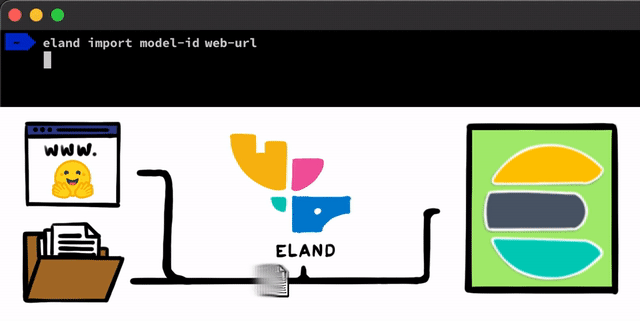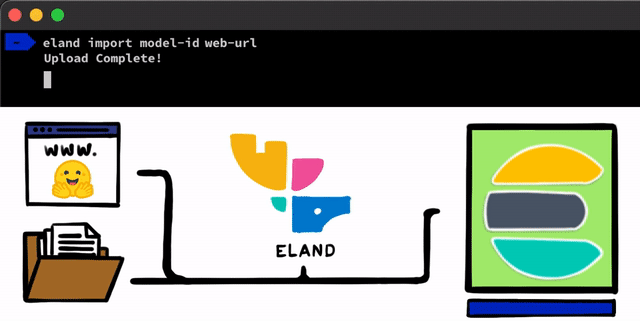
Nachdem Sie die PyTorch-Modelle in den Cluster hochgeladen haben, können Sie sie konkreten Machine-Learning-Knoten zuweisen. Bei diesem Prozess werden die Modelle in den Speicher geladen und die nativen libtorch-Prozesse werden gestartet, um die Modelle für das Inferenzieren vorzubereiten.
Wenn die Modellzuweisung abgeschlossen ist, kann es mit dem Inferenzieren losgehen. Beim Ingestieren wird es einen Prozessor für das Inferenzieren geben, und Sie können jede Art von Ingestions-Verarbeitungspipeline einrichten, um Dokumente vor oder nach dem Inferenzieren zu verarbeiten. Bei einer Sentimentanalyseaufgabe beispielsweise, bei der wir Text aus einem Dokumentfeld als Eingabe verwenden, erhalten wir entweder das positive oder das negative Klassenlabel, das für diese Eingabe vorhergesagt wurde. Diese Vorhersage wird dann in ein Ausgabefeld im Dokument eingefügt. Das daraus resultierende neue Dokument kann entweder durch andere Ingestionsprozessoren weiter verarbeitet oder so wie es ist indexiert werden.
Was kommt als Nächstes
Wir werden Ihnen in zukünftigen Blogposts und Webinaren weitere Beispiele für spezifische Modelle und NLP-Aufgaben präsentieren. Wenn Sie ein Modell haben, das Sie in Elasticsearch ausprobieren möchten, beginnen Sie doch am besten gleich damit und berichten Sie in unserem ML-Diskussionsforum oder im Community-Slack von Ihren Erfahrungen. Wenn Sie NLP-Modelle für Produktionszwecke hochladen und den Inferenzprozessor nutzen möchten, benötigen Sie eine „Platinum“- oder „Enterprise“-Lizenz für Elasticsearch. Sie können das Ganze aber kostenlos ausprobieren. Oder Sie erstellen einen neuen Elastic Cloud-Cluster und verwenden dann unseren Eland-Client, um das Modell in Ihren neuen Cluster hochzuladen. Wenn Sie sofort loslegen möchten, können Sie Elastic Cloud 14 Tage lang kostenlos ausprobieren.
Und noch etwas: Wenn Sie gern mehr über NLP-Modelle und ihre Integration in Elasticsearch erfahren möchten, nehmen Sie an unserem Webinar Einführung in NLP-Modelle und Vektorsuche teil.
Weitere interessante Links:
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken