Wir stellen vor: das Elastic Common Schema (ECS)
In diesem Blog-Post stellen wir Ihnen das Elastic Common Schema (ECS) vor – eine neue Spezifikation für die konsistente und individuell anpassbare Strukturierung Ihrer Daten in Elasticsearch, die die Analyse von Daten aus unterschiedlichen Quellen möglich macht. ECS hilft dabei, die Anwendungsbreite von Analytics-Inhalten, wie Dashboards und Machine-Learning-Jobs, zu erweitern, Suchen enger einzugrenzen und sich die Namen von Feldern einfacher zu merken.
Was bringt ein gemeinsames Schema?
Gleich, ob Sie Methoden zur interaktiven Analyse (mittels Suchen, Drill-downs und Pivot-Analysen, Visualisierungen und so weiter) oder zur automatischen Analyse (wie Alerting oder Machine-Learning-gestützte Anomalieerkennung) anwenden – Sie brauchen eine Möglichkeit, Ihre Daten auf eine gemeinsame Basis zu stellen, damit Sie sie untersuchen können. Sobald Sie aber Daten aus verschiedenen Quellen haben, stoßen Sie auf das Problem unterschiedlicher Formatierungen. Dafür gibt es verschiedene Gründe:
- Unterschiede bei den Datentypen (z. B. Log-Einträge, Metriken, APM, Datenströme, Kontextdaten)
- heterogene Umgebungen mit anbieterspezifischen Standards
- ähnliche Datenquellen, die sich aber dennoch unterscheiden (z. B. mehrere Quellen für Endpunktdaten, wie Auditbeat, Cylance und Tanium)
Stellen Sie sich vor, Sie müssten in Daten aus verschiedenen Quellen einen konkreten Nutzer finden. Allein für die Suche nach diesem einen Feld wäre es nötig, zumindest die folgenden Feldnamen in Betracht zu ziehen: user, username, nginx.access.user_name und login. Drill-downs und Pivot-Analysen anhand dieser Daten wären noch schwieriger zu bewerkstelligen. Stellen Sie sich jetzt vor, Sie müssten Analytics-Inhalte, wie Visualisierungen, Alerts oder Machine-Learning-Jobs, entwickeln – jede neue Datenquelle würde zusätzliche Komplexität oder Doppelungen mit sich bringen.
Was hat es mit dem ECS auf sich?
Das Elastic Common Schema (ECS) ist eine Open-Source-Spezifikation, die einen gemeinsamen Satz von Dokumentfeldern für Daten definiert, die in Elasticsearch ingestiert werden. Das Schema unterstützt die einheitliche Datenmodellierung und ermöglicht so die zentrale Analyse von Daten aus unterschiedlichen Quellen mit interaktiven und automatisierten Methoden.
Es bietet sowohl die Vorhersehbarkeit einer zweckgebundenen Taxonomie als auch die Vielseitigkeit einer inklusiven Spezifikation, die sich an individuelle Anwendungsfälle anpasst. Die Taxonomie des ECS verteilt Datenelemente über Felder, die sich in die folgenden drei Kategorien einteilen lassen:
| Kategorie | Beschreibung | Empfehlung |
| Kernfelder (ECS) | Vollständig definierte Gruppe von Feldnamen unter einem definierten Satz von ECS-Objekten auf oberster Ebene | Diese Felder sind den meisten Anwendungsfällen gemeinsam, sodass an dieser Stelle angesetzt werden sollte. |
| Erweiterte Felder (ECS) | Teilweise definierte Gruppe von Feldnamen unter demselben Satz von ECS-Objekten auf oberster Ebene | Erweiterte Felder können auf enger gefasste Anwendungsfälle zutreffen oder, je nach Anwendungsfall, stärker interpretierbar sein. |
| Nutzerdefinierte Felder | Nicht definierte Gruppe von Feldern ohne gemeinsamen Namen unter einem vom Nutzer bereitgestellten Satz von Nicht-ECS-Objekten auf oberster Ebene, die nicht mit ECS-Feldern oder -Objekten in Konflikt geraten dürfen | Hier können Sie Felder hinzufügen, für die es im ECS keine Feldentsprechung gibt. Sie können hier auch eine Kopie der originalen Ereignisfelder aufbewahren, z. B., wenn Sie Ihre Daten in das ECS überführen. |
Was hat es mit dem Elastic Common Schema (ECS) auf sich?
Beispiel 1: Parsing-Analyse
Wir wenden das ECS als Erstes auf den folgenden Apache-Log-Eintrag an:
10.42.42.42 - - [07/Dec/2018:11:05:07 +0100] "GET /blog HTTP/1.1" 200 2571 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36"
Bei der Zuordnung dieser Nachricht zum ECS werden die Felder des Log-Eintrags wie folgt organisiert:
| Feldname | Wert | Anmerkungen |
| @timestamp | 2018-12-07T11:05:07.000Z
| |
| ecs.version | 1.0.0
| |
| event.dataset | apache.access
| |
| event.original | 10.42.42.42 - - [07/Dec ...
| Vollständiger, unveränderter Log-Eintrag für Audit-Zwecke |
| http.request.method | get
| |
| http.response.body.bytes | 2571
| |
| http.response.status_code | 200
| |
| http.version | 1.1
| |
| host.hostname | webserver-blog-prod
| |
| message | "GET /blog HTTP/1.1" 200 2571
| Textdarstellung der wesentlichen Informationen aus dem Ereignis für die Kurzdarstellung in einem Log-Viewer |
| service.name | Company blog
| Von Ihnen festgelegter Name für diesen Dienst |
| service.type | apache
| |
| source.geo.* | Felder für Geolocation-Zwecke | |
| source.ip | 10.42.42.42
| |
| url.original | /blog
| |
| user.name | -
| |
| user_agent.* | Felder zur Beschreibung des Nutzer-Agents |
Wie oben dargestellt, bleibt der original Log-Eintrag im ECS-Feld event.original erhalten, um für Audit-Anwendungsfälle zur Verfügung zu stehen. Bitte beachten Sie auch, dass für eine bessere Übersichtlichkeit in diesem Beispiel Einzelheiten zum Monitoring-Agent (unter agent.*), einige Einzelheiten zum Host (unter host.*) und ein paar weitere Felder weggelassen wurden. Eine ausführlichere Darstellung finden Sie in diesem Beispielereignis in JSON.
Beispiel 2: Suche
In diesem Beispiel geht es um die Untersuchung der Aktivitäten einer konkreten IP-Adresse in einem kompletten Web-Stack: Palo Alto Networks-Firewall, HAProxy (nach Verarbeitung durch Logstash), Apache (unter Verwendung des Beats-Moduls), Elastic APM und zu guter Letzt das Suricata-IDS (individuell angepasst, unter Verwendung des Suricata-eigenen JSON-Format EVE).
Ohne ECS hätte die Suchanfrage für diese IP-Adresse z. B. wie folgt ausgesehen:
src:10.42.42.42 OR client_ip:10.42.42.42 OR apache2.access.remote_ip:10.42.42.42 OR context.user.ip:10.42.42.42 OR src_ip:10.42.42.42
Aber nach Zuordnung aller Quellen zu ECS reicht die folgende einfache Suchanfrage:
source.ip:10.42.42.42
Beispiel 3: Visualisierung:
Die Leistungsfähigkeit des ECS wird noch deutlicher ersichtlich, wenn man sich anschaut, wie es auf einheitlich normalisierte Daten aus mehreren unterschiedlichen Datenquellen angewendet werden kann. Nehmen wir an, Sie nutzen zum Web-Stack-Monitoring verschiedene Netzwerkdatenquellen: eine Palo Alto-Next-Generation-Firewall am Perimeter und das Suricata IDS, das Ereignisse und Alerts generiert. Wie lassen sich nun die Felder source.ip und network.direction so aus den Nachrichten extrahieren, dass eine zentralisierte Visualisierung in Kibana und anbieterübergreifende Drill-downs und Pivot-Analysen vorgenommen werden können? Natürlich mit dem ECS – das ECS macht es wesentlich einfacher als bisher, zentralisierte Monitoring-Aufgaben zu erledigen.
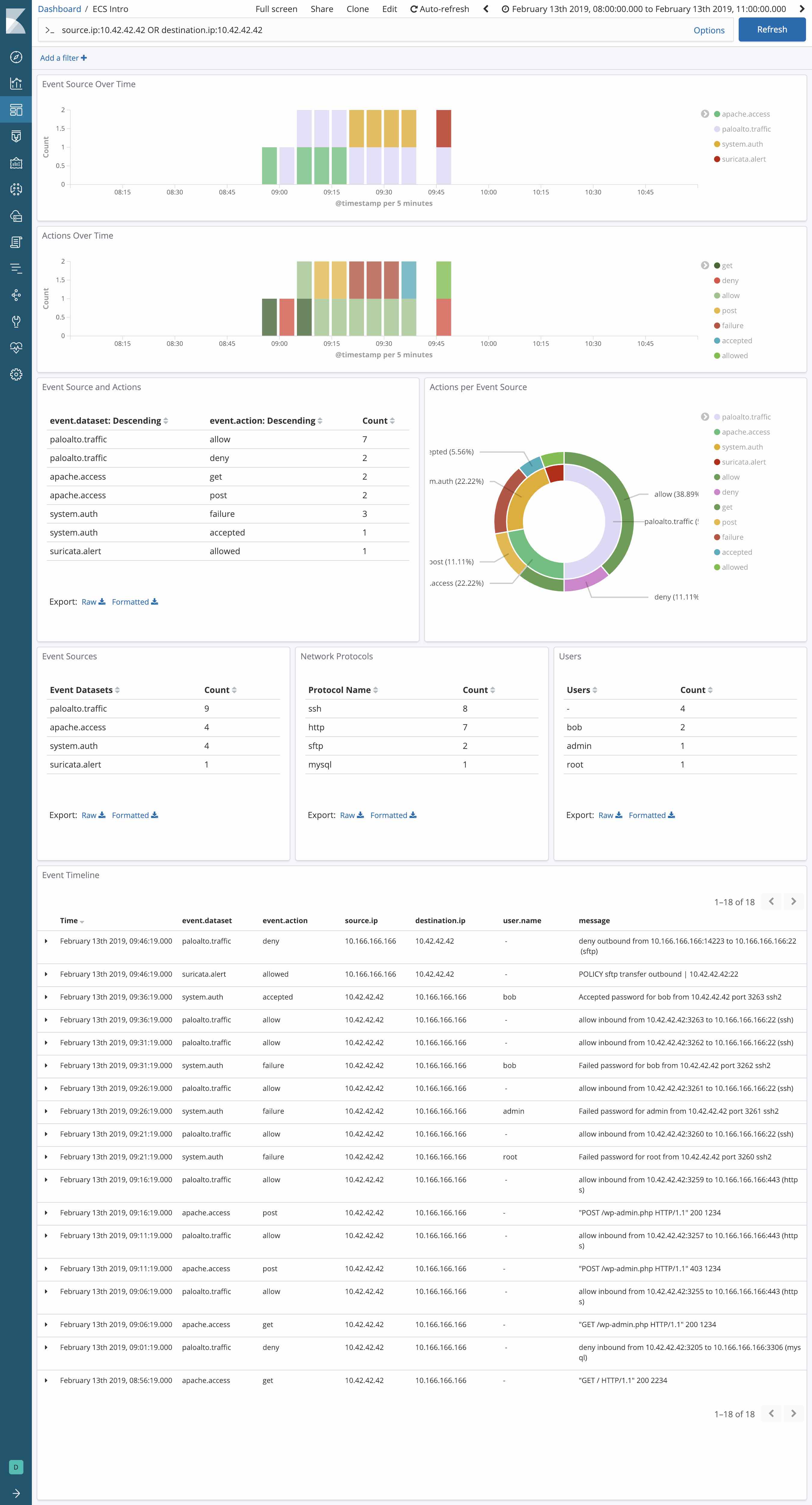
Vorteile des ECS
Wenn Sie das ECS implementieren, bringen Sie alle im Elastic Stack verfügbaren Analysemodi – Suche, Drill-down- und Pivot-Analysen, Datenvisualisierung, Machine-Learning gestützte Anomalieerkennung und Alerting – in einer Lösung zusammen. In Deployments mit kompletter ECS-Implementierung können Nutzer für ihre Suchen sowohl unstrukturierte als auch strukturierte Abfrageparameter verwenden. Das ECS hilft Ihnen auch beim automatischen Korrelieren von Daten aus unterschiedlichen Datenquellen, wobei es keine Rolle spielt, ob es sich einfach nur um verschiedene Geräte desselben Anbieters oder komplett unterschiedliche Datenquellentypen handelt.
Außerdem trägt das ECS dazu bei, die Entwicklung von Analytics-Inhalten zu beschleunigen. Statt für jede neu hinzukommende Datenquelle neue Suchen und Dashboards erstellen zu müssen, können Sie ganz einfach weiter die bestehenden Suchen und Dashboards verwenden. In Umgebungen, in denen das ECS im Einsatz ist, lassen sich wesentlich einfacher Analytics-Inhalte von anderen Parteien, die ebenfalls das ECS nutzen, direkt übernehmen, ob nun von Elastic, einem Partner oder einem Open-Source-Projekt.
Die Tatsache, dass der Nutzer sich nur einen Satz von Feldnamen merken muss, statt verschiedener Sätze für jede Datenquelle, erleichtert die Durchführung interaktiver Analysen. Auch das Herleiten von Feldnamen ist mit dem ECS einfacher, denn die Spezifikation folgt, von einigen wenigen Ausnahmen abgesehen, einer einfachen und standardisierten Benennungskonvention.
Sie sind noch nicht ganz bereit, auf das ECS umzusteigen? Kein Problem – das ECS ist da, wenn Sie es brauchen, aber Sie müssen es nicht nutzen.
Wie steht es um die Verfügbarkeit des Elastic Common Schema?
Das ECS steht zur Einsichtnahme in einem öffentlichen GitHub-Repo bereit. Die Spezifikation befindet sich derzeit in Beta2 und wird in Kürze allgemein verfügbar gemacht werden. Ihre Veröffentlichung erfolgt unter der Apache 2.0-Open-Source-Lizenz, sodass das ECS durch die Elastic-Community universell eingesetzt werden kann.
Klingt doch alles recht „automagisch“, oder? Nun, das ECS ist ein Schema, und das Implementieren von Schemas ist nicht ohne Tücken. Aber wenn Sie schon einmal eine Elasticsearch-Indexvorlage konfiguriert und ein paar Transformationsfunktionen mit Logstash- oder Elasticsearch-Ingest-Knoten geschrieben haben, wissen Sie ungefähr, was sie erwartet. Künftige Versionen der Elastic Beats-Module werden standardmäßig ECS-formatierte Ereignisse ausgeben und so diesen Teil des Umstiegs einfacher gestalten. Das neue Systemmodul für Auditbeat macht den Anfang, weitere werden folgen.
Wenn Sie mehr über das ECS erfahren möchten, sehen Sie sich unser Webinar zu Elastic Common Schema (ECS) an. Wir werden uns in diesem Blog demnächst mit dem Mapping Ihrer Daten zum ECS (einschließlich dem Mapping von Daten, die im Schema nicht definiert sind) sowie mit Strategien zur Migration zum ECS beschäftigen.