Migration zum Elastic Common Schema (ECS) in Beats-Umgebungen
Im Februar 2019 haben wir das Elastic Common Schema (ECS) mit einem entsprechenden Blogeintrag und einem Webinar präsentiert. Eine kurze Zusammenfassung: ECS definiert einen gemeinsamen Satz von Feldern und Datentypen, um Suche, Visualisierung und Analyse für verschiedenste Datenquellen zu vereinheitlichen. Dies ist ein riesiger Vorteile für heterogene Umgebungen mit verschiedenen Herstellerstandards und zahlreichen Datenquellen, die einander zwar ähneln, aber nicht gleich sind.
Außerdem haben wir darüber gesprochen, dass die Implementierung von ECS ihre Tücken hat. Um ECS-kompatible Ereignisse zu generieren, müssen viele der von Ereignisquellen bereitgestellten Felder beim Ingestieren der Daten kopiert oder umbenannt werden.
Zum Abschluss unserer ECS-Einführung haben wir angemerkt, dass Benutzer, die schon einmal eine Elasticsearch-Indexvorlage konfiguriert und ein paar Transformationsfunktionen mit Logstash- oder Elasticsearch-Ingest-Knoten geschrieben haben, ungefähr wissen, was sie erwartet. Der Arbeitsaufwand für die Migration Ihrer Umgebung nach ECS hängt davon ab, wie Sie die Dateningestions-Pipelines für Ihren Elastic Stack modelliert haben. An einem Ende des Spektrums können Sie mit Beats und Beats-Modulen eine kuratierte Migration zu ECS durchführen. Beats 7-Ereignisse liegen bereits im ECS-Format vor, und Sie müssen lediglich eine Verbindung zwischen vorhandenen Analyseinhalten und neuen ECS-Daten herstellen. Am anderen Ende des Spektrums haben wir verschiedenste Arten von spezialisierten Pipelines, die von den Benutzern entwickelt wurden.
Im Juni haben wir ein Webinar gehostet, in dem wir über die Migration zu ECS gesprochen haben. Dieser Blogeintrag baut auf der Diskussion in diesem Webinar auf und behandelt die Migration zu ECS in Beats-Umgebungen noch ausführlicher. Die Migration von benutzerdefinierten Dateningestions-Pipelines nach ECS wird in einem zukünftigen Blogeintrag besprochen.
Übersicht über die in diesem Blogeintrag behandelten Themen:
- Migration zu ECS mit Elastic Stack 7
- Grundlegende Übersicht über die Migration zu ECS
- Übersicht über die Migration einer Beats-Umgebung zu ECS
- Erstellen Sie Ihre eigene Migrationsstrategie
- Beispielmigration
- Fazit
- Referenzen
Migration zu ECS mit Elastic Stack 7
Als uns klar wurde, dass wir die Namen der von Beats verwendeten Ereignisfelder nicht ändern können, ohne Probleme bei unseren Benutzern zu verursachen, haben wir in der neuesten Hauptversion (Elastic Stack Version 7) ECS-Feldnamen eingeführt.
Dieser Beitrag beginnt mit einer Übersicht über die Migration zu ECS mit Beats im Kontext eines Upgrades von Elastic Stack 6.8 auf 7.2. Anschließend besprechen wir ein Migrationsbeispiel anhand einer Beats-Ereignisquelle Schritt für Schritt.
Achten Sie darauf, dass dieser Blogeintrag nur einen Teil der Migration zu Version 7 behandelt. Gemäß unserer Richtlinien für Stack-Upgrades sollte das Upgrade von Beats nach Elasticsearch und Kibana durchgeführt werden. Das Migrationsbeispiel in diesem Blogeintrag befasst sich daher nur mit dem Beats-Upgrades und geht davon aus, dass Sie Elasticsearch und Kibana bereits auf Version 7 aktualisiert haben. Auf diese Weise können wir uns auf die Details beim Beats-Upgrade vom alten Schema zu ECS konzentrieren.
Beachten Sie bei der Planung Ihrer Elastic Stack 7-Migration unbedingt die erwähnten Richtlinien, sehen Sie sich den Kibana Upgrade-Assistenten an und lesen Sie natürlich die Upgradehinweise und wichtigen Änderungen für sämtliche Teile des Stacks, die Sie einsetzen.
Hinweis: Falls Sie Beats einsetzen möchten und keine Daten aus Beats 6 haben, müssen Sie sich keine Gedanken über die Migration machen. In diesem Fall können Sie einfach Beats Version 7.0 oder höher einsetzen, die bereits für ECS-formatierte Ereignisse vorkonfiguriert ist.
Grundlegende Übersicht über die Migration zu ECS
Die Migration zu ECS umfasst die folgenden Schritte:
- Übersetzen Ihrer Datenquellen nach ECS
- Auflösen von Unterschieden und Konflikten zwischen dem alten Ereignisformat und den ECS-Ereignissen
- Anpassen von Analyseinhalten, Pipelines und Anwendungen für die Verwendung von ECS-Ereignissen
- Herstellen einer Kompatibilität zwischen alten und ECS-Ereignissen, um den Wechsel zu erleichtern
- Entfernen von Feld-Aliasen, nachdem alle Quellen zu ECS migriert wurden
In diesem Blogeintrag behandeln wir all diese Schritte speziell im Kontext der Migration einer Beats-Umgebung nach ECS.
Im Anschluss an die folgende Übersicht werden wir das Upgrade eines Filebeat-Moduls von 6.8 auf 7.2 Schritt für Schritt besprechen. Sie können diese Beispielmigration mühelos auf Ihrem Computer begleiten, die einzelnen Schritte der Migration ausführen und nebenher verschiedene Dinge ausprobieren.
Übersicht über die Migration einer Beats-Umgebung zu ECS
Die Schritte der oben beschriebenen Migration können auf verschiedene Arten absolviert werden. Wir werden uns die Schritte im Kontext der Migration Ihrer Beats-Ereignisse nach ECS genauer ansehen.
Übersetzen von Datenquellen nach ECS
Beats wird mit zahlreichen kuratierten Ereignisquellen ausgeliefert. Ab Beats 7.0 liegen sämtliche Ereignisquellen bereits im konvertierten ECS-Format vor. Die Beats-Prozessoren, die Metadaten zu Ihren Ereignissen hinzufügen (z. B. add_host_metadata) wurden ebenfalls zu ECS konvertiert.
Beachten Sie dabei jedoch, dass Beats manchmal einfach nur als Transport für Ihre Ereignisse dient. Beispiele hierfür sind die von Winlogbeat und Journalbeat gesammelten Ereignisse, sowie sämtliche Filebeat-Eingaben, mit denen Sie benutzerdefinierte Protokolle und Ereignisse verarbeiten (mit Ausnahme der eigentlichen Filebeat-Module). Sie müssen sämtliche benutzerdefinierten Ereignisquellen, die Sie momentan verarbeiten und analysieren, zu Ihrem eigenen ECS zuordnen.
Beheben von Unterschieden und Konflikten im Schema
Diese Migration zu ECS hat das Ziel, die Feldnamen in vielen verschiedenen Datenquellen zu standardisieren. Dies bedeutet, dass zahlreiche Felder umbenannt werden.
Namensänderungen und Feld-Aliase
Sie haben verschiedene Möglichkeiten, um die alten und neuen ECS-Ereignisse beim Wechsel zwischen den zwei Formaten zu verarbeiten. Die beiden wichtigsten Optionen:
- Verwenden von Elasticsearch-Feld-Aliasen, damit der die neuen Indizes die alten Feldnamen erkennen
- Duplizieren von Daten innerhalb des Ereignisses (sowohl alte Felder als auch ECS-Felder werden ausgefüllt)
- Kein Eingreifen: alte Inhalte funktionieren nur mit alten Daten, neue Inhalte nur mit neuen Daten
Elasticsearch-Feld-Aliase sind die einfachste und kostengünstigste Methode. Daher haben wir diesen Migrationspfad für das Beats-Upgrade ausgewählt.
Feld-Aliase haben jedoch einige Einschränkungen und sind keine perfekte Lösung. Lassen Sie uns ihre Vor- und Nachteile genauer betrachten.
Feld-Aliase sind zusätzliche Felder in der Elasticsearch--Zuordnung für neue Indizes. Außerdem können Indizes mit Feld-Aliasen auf Abfragen antworten, in denen die alten Feldnamen verwendet werden. Betrachten Sie das folgende vereinfachte Beispiel, in dem nur ein Feld angezeigt wird:
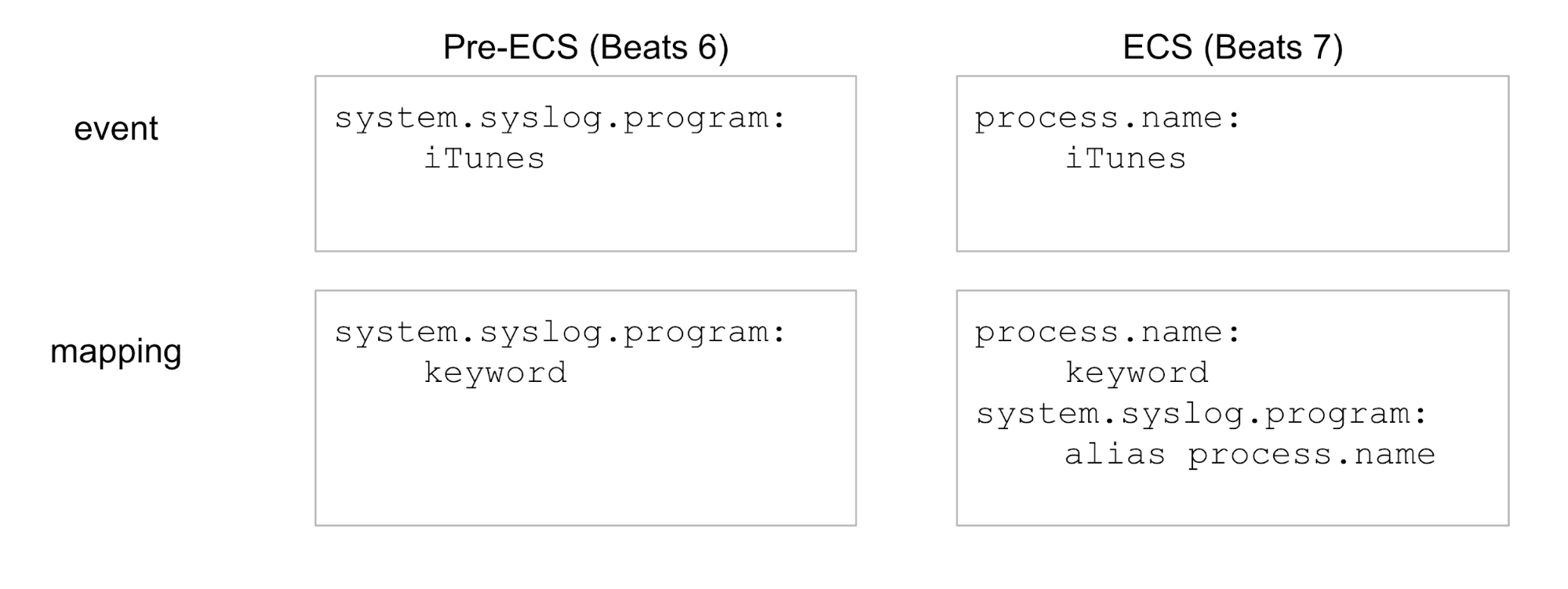
Feld-Aliase unterstützen Sie bei den folgenden Aufgaben:
- Aggregationen und Visualisierungen über das Alias-Feld
- Filter- und Suchvorgänge über das Alias-Feld
- Autovervollständigung für das Alias-Feld
Für Feld-Aliase gelten die folgenden Einschränkungen:
- Feld-Aliase sind eine Funktion der Elasticsearch-Zuordnungen (der Suchindex). Daher nehmen sie keine Änderungen an der Dokumentquelle oder den Feldnamen vor. Das Dokument enthält entweder die alten oder die neuen Feldnamen. In den folgenden Anwendungsfällen sind Aliase nicht hilfreich, da direkt im Dokument auf die Felder zugegriffen wird:
- Spalten in gespeicherten Suchen
- Zusätzliche Verarbeitungsschritte in Ihrer Dateningestions-Pipeline
- Alle Anwendungen, die Ihre Beats-Ereignisse verarbeiten (z. B. über die Elasticsearch-API)
- Da Feld-Aliase auch Feldeinträge sind, können wir keinen Alias erstellen, wenn bereits ein neues ECS-Feld mit demselben Namen existiert.
- Feld-Aliase funktionieren nur mit Leaf-Feldern und unterstützen keine komplexen Felder wie etwa
object-Felder, die weitere verschachtelte Felder enthalten können.
Diese Feld-Aliase werden in Ihren Beats 7-Indizes standardmäßig nicht erstellt. Sie müssen sie aktivieren, indem Sie migration.6_to_7.enabled: true in den einzelnen YAML-Konfigurationsdateien für Beats festlegen, bevor Sie das Beats-Setup ausführen. Diese Option und die entsprechenden Aliase sind für die Lebensdauer von Elastic Stack 7.x verfügbar und werden in 8.0 entfernt.
Konflikte
Bei der Migration zu ECS können Feldkonflikte auftreten, je nachdem, welche Quellen Sie verwenden.
Einige dieser Konflikte werden dabei nur für die Felder erkannt, die Sie tatsächlich verwenden. Dies bedeutet, dass Änderungen oder Konflikte in Quellen, die Sie nicht verwenden, keine Auswirkungen haben. Es bedeutet jedoch auch, dass Sie bei der Planung Ihrer Migration Beispielereignisse aus all Ihren Datenquellen in beiden Formaten (Beats 6 und 7) in Ihre Testumgebung ingestieren sollten, um alle Konflikte zu erkennen, die behoben werden müssen.
Dabei können zwei Arten von Konflikten auftreten:
- Der Datentyp eines Felds wird zu einem passenderen Typ geändert
- Ein vor ECS verwendeter Feldname ist in ECS definiert, jedoch mit einer anderen Bedeutung. In diesem Fall sprechen wir von inkompatiblen Feldern.
Diese beiden Konflikttypen haben unterschiedliche Auswirkungen. Grundsätzlich gilt: Wenn sich der Datentyp eines Felds oder die Verschachtelung eines inkompatiblen Felds ändert (Beispiel: ein keyword-Feld wird zu einem object-Feld), dann können Sie das Feld nicht mehr gleichzeitig über alte und neue ECS-Quellen gleichzeitig abfragen.
Wenn Ihre Indizes in Beats 6 und 7 einige Daten enthalten, können Sie Ihre Kibana-Indexmuster aktualisieren, um diese Konflikte anzuzeigen. Wenn nach der Aktualisierung der Indexmuster keine Konfliktwarnung angezeigt wird, bedeutet dies, dass keine weiteren Konflikte vorhanden sind. Wenn eine Warnung angezeigt wird, können Sie die Anzeige mit der Datentypauswahl auf die Konflikte beschränken:

Sie können diese Konflikte beheben, indem Sie die alten Daten neu indizieren, um sie mit dem neuen Schema kompatibel zu machen. Die durch Typänderungen verursachten Konflikte sind relativ einfach zu beheben. Überschreiben Sie Ihre Beats 6-Indexmuster so, dass diese einen passenderen Datentyp verwenden, indizieren Sie die Daten in einem neuen Index (um die geänderte Zuordnung zu übernehmen) und löschen Sie den alten Index.
Im Fall von inkompatiblen Feldern müssen Sie entscheiden, ob Sie die Felder löschen oder umbenennen möchten. Wenn Sie das Feld umbenennen, müssen Sie es zunächst in Ihrem Indexmuster definieren.
Anpassen Ihrer Umgebung für die Verarbeitung von ECS-Ereignissen
Angesichts der zahlreichen Änderungen an Feldnamen wurden die mit Beats ausgelieferten Inhalte der Beispielanalyse (z. B. Dashboards) ebenfalls an die neuen Namen angepasst. Die neuen Inhalte funktionieren nur mit ECS-Daten, die von Beats 7.0 oder einer neueren Version produziert wurden. Daher überschreibt das Beats-Setup Ihre vorhandenen Beats 6-Inhalte nicht, sondern erstellt stattdessen eine zweite Kopie aller Kibana-Visualisierungen. Die neuen Kibana-Visualisierungen haben denselben Namen, jeweils mit „ECS“ am Ende.
Die Beats 6-Beispielinhalte und Ihre benutzerdefinierten Inhalte, die dieses alte Schema verwenden, funktionieren dank der Feld-Aliase weiterhin zum Großteil mit Daten aus Beats 6 und 7. Wie bereits besprochen sind Feld-Aliase jedoch nur eine unvollständige und vorübergehende Hilfe bei der Migration zu ECS. Daher sollten Sie bei Ihrer Migration auch Ihre individuellen Dashboards aktualisieren oder duplizieren, um die neuen Feldnamen zu nutzen.
Sehen Sie sich dazu die folgende Tabelle an:
|
Vor ECS (Beats 6, Ihre individuellen Dashboards) |
ECS (Beats 7) |
| [Filebeat System] Syslog dashboard | [Filebeat System] Syslog dashboard ECS |
|
|
Sie müssen also nicht nur Ihre Analyseinhalte in Kibana überprüfen und anpassen, sondern auch alle benutzerdefinierten Teile Ihrer Ereignispipeline und Ihre Anwendungen, die über die Elasticsearch-API auf Beats-Ereignisse zugreifen.
Herstellen einer Kompatibilität zwischen alten und ECS-Ereignissen
Wir haben bereits besprochen, wie wir Datentypkonflikte und inkompatible Felder mit einer erneuten Indizierung beheben können. Die erneute Indizierung dieser zwei Arten von Änderungen ist zwar optional, lässt sich jedoch relativ einfach implementieren und lohnt sich daher in den meisten Fällen. In einfachen Anwendungsfällen können Konflikte manchmal auch ignoriert werden. Potenzielle Feldkonflikte haben jedoch Auswirkungen ab dem Moment, an dem Sie Beats 7-Daten ingestieren, bis zum Moment, an dem Beats 6 vollständig aus Ihrem Cluster verschwunden ist.
Erneute Indizierung
Wenn Feld-Aliase für Ihre Situation nicht ausreichen, können Sie auch vergangene Daten neu indizieren, um die ESC-Feldnamen in Ihre Beats 6-Daten zu übernehmen. Damit stellen Sie sicher, dass alle neuen Analyseinhalte, die von ESC-Feldern abhängen (neue Beats 7-Inhalte und Ihre aktualisierten benutzerdefinierten Inhalte), sowohl Ihre alten Daten als auch die Beats 7-Daten abfragen können.
Bearbeiten von Ereignissen bei der Dateningestion
Wenn Sie eine lange Rolloutphase für die Beats 7-Agenten erwarten, macht es unter Umständen Sinn, nicht nur vergangene Indizes zu indizieren. Sie können eingehende Beats 6-Ereignisse bei der Dateningestion auch bearbeiten.
Sie haben verschiedene Methoden zur Auswahl, mit denen Sie Dokumente neu indizieren und bearbeiten können, etwa um Felder zu kopieren, zu löschen oder umzubenennen. Die einfachste Methode sind Elasticsearch Ingest-Pipelines. Vorteile dieser Methode:
- Einfache Testmöglichkeiten mit der _simulate-API
- Sie können vergangene Indizes neu indizieren
- Sie können eingehende Beats 6-Ereignisse weiterhin bearbeiten
Um eingehende Ereignisse zu bearbeiten, reicht es in oft aus, die „pipeline“-Einstellung Ihrer Elasticsearch-Ausgabe so zu konfigurieren, dass die Daten an Ihre Pipeline gesendet werden. Dies gilt für Logstash und Beats.
Beachten Sie, dass Filebeat-Module bereits Ingest-Pipelines für ihre Datenanalyse verwenden. Diese Module können ebenfalls bearbeitet werden. Dabei müssen Sie jedoch die Filebeat 6-Pipelines überschreiben und ein Callout zu Ihrer Anpassungs-Pipeline hinzufügen.
Feld-Aliase entfernen
Wenn Sie die Feld-Aliase nicht mehr benötigen, können Sie sie entfernen. Wie bereits erwähnt verbraucht diese Methode weniger Ressourcen, als wenn Sie sämtliche Daten duplizieren. Die Aliase verbrauchen jedoch weiterhin Arbeitsspeicher in Ihrem Cluster, eine kritische Ressource. Außerdem werden sie unnötigerweise in der Kibana-Autovervollständigung angezeigt.
Um Ihre alten Feld-Aliase zu entfernen, löschen Sie die Einstellung migration.6_to_7.enabled aus Ihrer Beats-Konfiguration (z. B. filebeat.yml) bzw. legen Sie sie auf „false“ fest, führen Sie die „Setup“-Operation erneut aus und überschreiben Sie die Vorlage.
Nachdem Sie Ihre Vorlagen überschrieben haben und diese keine Aliase mehr enthalten, müssen Sie trotzdem auf den Rollover Ihrer Indizes warten, bevor die Aliase auch aus Ihren Indexmappings verschwinden. Nach dem Rollover der Indizes müssen Sie abwarten, bis Ihre Beats 7-Daten mit den Aliasen altersbedingt aus Ihrem Cluster entfernt werden, bevor diese komplett verschwunden sind.
Erstellen Sie Ihre eigene Migrationsstrategie
Wir haben verschiedene Methoden in Beats besprochen, die Sie bei der Migration Ihrer Beats-Daten zu ECS unterstützen. Außerdem haben wir zusätzliche Schritte besprochen, mit denen Sie Ihre Migration einfacher gestalten können.
Wir empfehlen, den benötigten Aufwand für Ihre einzelnen Datenquellen unabhängig abzuschätzen. Möglicherweise können Sie Ihre weniger kritischen Datenquellen mit weniger Aufwand migrieren.
Hier sind einige Kriterien für die Beurteilung der einzelnen Datenquellen:
- Wie lange ist der Aufbewahrungszeitraum, und wird dieser extern vorgegeben? Besteht die Option, Daten bei dieser Migration vorzeitig zu löschen?
- Benötigen Sie Kontinuität in Ihren Daten? Oder können Sie einen Cutover durchführen? Mit diesen Fragen können Sie entscheiden, ob Sie Ihre Daten wie oben beschrieben rückmigrieren müssen.
- Wie lange wird Ihr Beats 7-Rollout dauern? Müssen Sie die weiterhin eingehenden Beats 6-Ereignisse bearbeiten?
Wenn Sie viele Felder rückmigrieren müssen, sollten Sie sich dev-tools/ecs-migration.yml im Beats-Repository ansehen. Diese Daten enthält sämtliche Feldänderungen für die Migration von Beats 6 nach 7.
Beispielmigration
Im Rest dieses Blogeintrags zeigen wir Ihnen, wie Sie zu ECS migrieren, indem Sie Beat von 6.8 auf 7.2 aktualisieren. Außerdem besprechen wir Vorteile und Einschränkungen von Aliasen, Konfliktauflösung, erneute Indizierung frischer Daten als Übergangslösung, und das Bearbeiten der weiterhin eingehenden Beats 6-Ereignisse. In diesem Beispiel verwenden wir das Syslog-Modul von Filebeat.
Wie bereits erwähnt werden wir in diesem Beispiel nicht den gesamten Elastic Stack aktualisieren. Wir gehen davon aus, dass Elasticsearch und Kibana bereits auf Version 7 aktualisiert wurden und können uns daher darauf konzentrieren, das Datenschema für ECS zu aktualisieren.
Falls Sie das Beispiel begleiten möchten, verwenden Sie die aktuellste Version von Elasticsearch 7 und Kibana 7. Sie können entweder ein kostenloses Elastic Cloud-Testkonto verwenden oder die Software lokal ausführen, indem Sie die Installationsanweisungen für Elasticsearch und Kibana ausführen.
Ausführen von Beats 6.8
In dieser Demo verwenden wir Filebeat 6.8 und 7.2 gleichzeitig auf demselben Computer. Daher ist es wichtig, dass wir beide Versionen mit einer Archivinstallation installieren (mit der .zip- oder .tar.gz-Datei). Archivinstallationen sind auf ihr eigenes Verzeichnis beschränkt und vereinfachen den Prozess.
Starten Sie Elasticsearch und Kibana 7 und installieren Sie Filebeat 6.8. Unter Windows können Sie stattdessen auch Winlogbeat installieren.
Auf den meisten Systemen verwendet Syslog die lokale Zeit für seine Zeitstempel, ohne eine Zeitzone anzugeben. Wir werden Filebeat so konfigurieren, dass die Zeitzone über den Prozessor add_locale zu den Ereignissen hinzugefügt wird. Anschließend werden wir die Pipeline des Systemmoduls so konfigurieren, dass der Zeitstempel korrekt interpretiert wird. Damit stellen wir sicher, dass wir unsere ECS-Migration später validieren können, wenn wir uns die kürzlich eingetroffenen Ereignisse anschauen.
Suchen Sie in „filebeat.yml“ nach dem Abschnitt „processors“ und fügen Sie den Prozessor add_locale hinzu. Fügen Sie die folgende Modulkonfiguration unter dem Abschnitt „processors“ hinzu:
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
- add_locale: ~
filebeat.modules:
- module: system
syslog:
var.convert_timezone: true
Falls Sie Elasticsearch und Kibana lokal ausführen, sollte diese Konfiguration ausreichen. Wenn Sie Elastic Cloud verwenden, müssen Sie außerdem Ihre Cloud-Anmeldeinformationen zu „filebeat.yml“ hinzufügen. Sie finden diese Daten in Elastic Cloud bei der Erstellung Ihres Clusters:
cloud.id: 'my-cluster-name:a-very-long-string....' cloud.auth: 'username:password'
Anschließend werden wir Filebeat 6.8 für die Erfassung von Systemprotokollen einrichten:
./filebeat setup -e ./filebeat -e
Im Dashboard [Filebeat System] Syslog dashboard können wir überprüfen, ob das System Daten empfängt. Im Dashboard sollten die neuesten Syslog-Ereignisse aus dem System angezeigt werden, auf dem Sie Filebeat installiert haben.
Dieses Dashboard ist interessant, da es Visualisierungen und eine gespeicherte Suche enthält. Dies ist hilfreich, um später die Vorteile und Einschränkungen von Aliasen zu demonstrieren.
Ausführen von Beats 7 (ECS)
Leider eignen sich nicht alle Umgebungen für einen sofortigen Cutover zwischen verschiedenen Beats-Versionen. Höchstwahrscheinlich empfangen Sie für einige Zeit parallel Ereignisse aus Filebeat 6 und 7. In diesem Beispiel gehen wir von genau dieser Situation aus.
Dazu können wir einfach Filebeat 7.2 parallel zu 6.8 auf demselben System ausführen. Wir extrahieren Filebeat 7.2 in ein anderes Verzeichnis und wenden dieselben Konfigurationsänderungen an wie in 6.8.
Warten Sie jedoch noch mit dem Setup! Für Beats 7 müssen wir zusätzlich die Migrationseinstellung aktivieren, um Feld-Aliase zu erstellen. Entfernen Sie den Kommentar in dieser Zeile am Ende von „filebeat.yml“:
migration.6_to_7.enabled: true
Unsere Konfigurationsdatei für 7.2 enthält jetzt dieses zusätzliche Migrationsattribut, den Prozessor add_locale, die Konfiguration für das Systemmodul und, falls erforderlich, unsere Cloud-Anmeldeinformationen.
Wir starten Filebeat 7.2 aus einem anderen Terminal:
./filebeat setup -e ./filebeat -e
Konflikte
Bevor wir uns den Dashboards zuwenden, öffnen wir zunächst die Kibana-Indexverwaltung, um zu überprüfen, ob der neue Index erstellt wurde und wir Daten empfangen. Dort sollte in etwa Folgendes angezeigt werden:
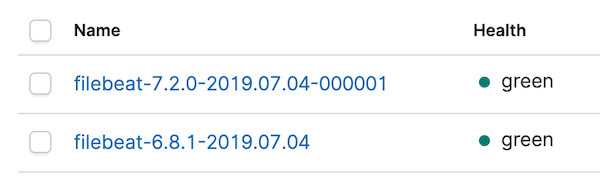
Außerdem öffnen wir die Indexmuster und aktualisieren das Indexmuster „filebeat-*“. Nachdem wir unser Indexmuster für Daten aus 6.8 und 7.2 aktualisiert haben, werden einige Konflikte angezeigt. Wir können uns auf die Konflikte konzentrieren, indem wir die Datentypauswahl rechts von All field types zu conflict ändern:
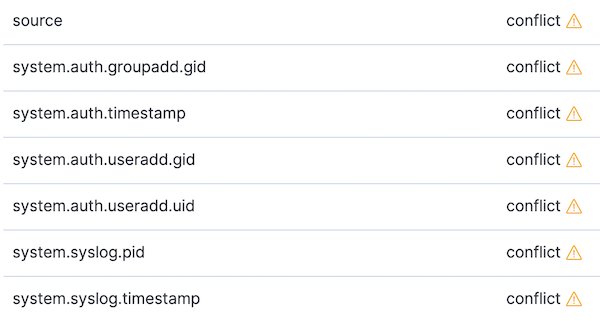
Wir werden uns zwei der oben gezeigten Konflikte näher ansehen und Ansätze für ihre Behebung besprechen.
Zunächst betrachten wir einen syslog-spezifischen Konflikt: system.syslog.pid. Wenn wir die Indexverwaltung öffnen und nach der Zuordnung für 6.8 suchen, sehen wir, dass das Feld als keyword indiziert ist. Im Indexmapping für 7.2 sehen wir, dass system.syslog.pid ein Alias für process.pid ist. Diese Konfiguration ist in Ordnung und ist nicht die Ursache des Konflikts. Wenn wir jedoch dem Alias folgen, sehen wir, dass process.pid jetzt den Datentyp long hat. Der Wechsel von keyword zu long hat unseren Datentypkonflikt verursacht.
Als nächstes sehen wir uns einen Konflikt an, der durch ein inkompatibles Feld verursacht wird. Dieser Konflikt tritt in allen Filebeat-Migrationen auf: das Feld source. In Filebeat 6 ist source ein keyword-Feld, das normalerweise einen Dateipfad (oder manchmal auch eine Syslog-Quelladresse) enthält. In ECS und daher auch in den Filebeat 7-Feldzuordnungen ist source ein Objekt mit verschachtelten Feldern, die die Quelle eines Netzwerkereignisses beschreiben (source.ip, source.port usw.). Da in Beats 7 weiterhin ein Feld mit dem Namen source existiert, können wir dort kein Alias-Feld erstellen.
Wir haben zwei Felder identifiziert, die wir für unsere Migration verwenden können. Wir kommen gleich wieder auf diese Felder zurück.
Aliase
Lassen Sie das Beats 6-Dashboard [Filebeat System] Syslog dashboard geöffnet. Da wir das „filebeat-*“-Indexmuster geändert haben, nachdem wir diese Seite geöffnet haben, sollten wir sie mit Command-R bzw. F5 aktualisieren.
Öffnen Sie das neue Dashboard [Filebeat System] Syslog dashboard ECS.
In der gespeicherten Suche am unteren Rand des 6.8-Dashboards sehen wir, dass die Daten lückenhaft sind. Manche Ereignisse haben Werte für system.syslog.program und system.syslog.message, manche jedoch nicht. Wenn wir die Ereignissen mit leeren Werten öffnen, sehen wir, dass es sich um dieselben Syslog-Ereignisse handelt, die von 7.2 empfangen wurden, jedoch mit anderen Feldnamen. Im gleichen Zeitraum in der Registerkarte mit dem ECS-Dashboard sehen wir dasselbe Verhalten, nur umgekehrt. Die ECS-Felder process.name und message werden für 7.2-Ereignisse ausgefüllt, jedoch nicht für 6.8-Ereignisse.
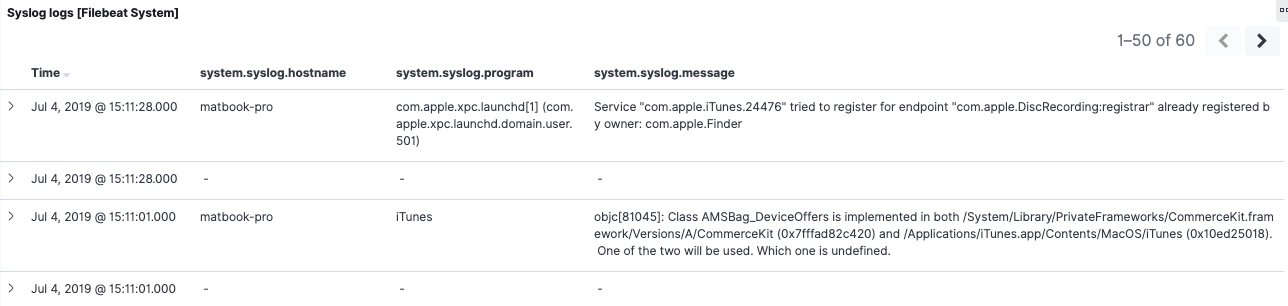
Dies ist ein konkretes Beispiel, in dem Feld-Aliase nicht hilfreich sind. Die gespeicherte Suche verwendet nur den Inhalt des Dokuments, und nicht das Indexmapping. Wie bereits in der Übersicht erwähnt, können Sie Ihre Daten neu indizieren, um sie rückzumigrieren (und die eingehenden Ereignisse zu bearbeiten), falls Sie Kontinuität benötigen. Dazu kommen wir gleich.
Zunächst sehen wir uns an, in welchen Fällen Feld-Aliase hilfreich sind. Sehen Sie sich die Donut-Visualisierung im 6.8-Dashboard an und fahren Sie mit der Maus über den äußeren Ring, um die Werte für system.syslog.program anzuzeigen:
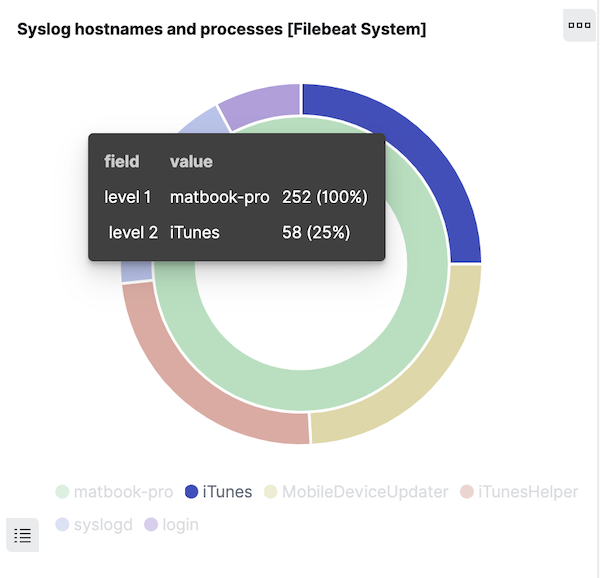
Klicken Sie auf einen Ringabschnitt, um die Anzeige nach den Nachrichten von einem Programm zu filtern. Wir wählen nur den Filter nach dem Programmnamen aus:
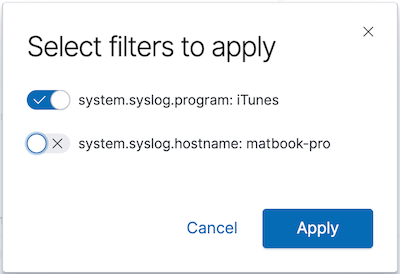
Wir haben soeben einen Filter über ein Feld angewendet, das in 7.2 nicht mehr vorhanden ist: system.syslog.program. Dennoch werden weiterhin beide Nachrichtensätze in der gespeicherten Suche angezeigt:
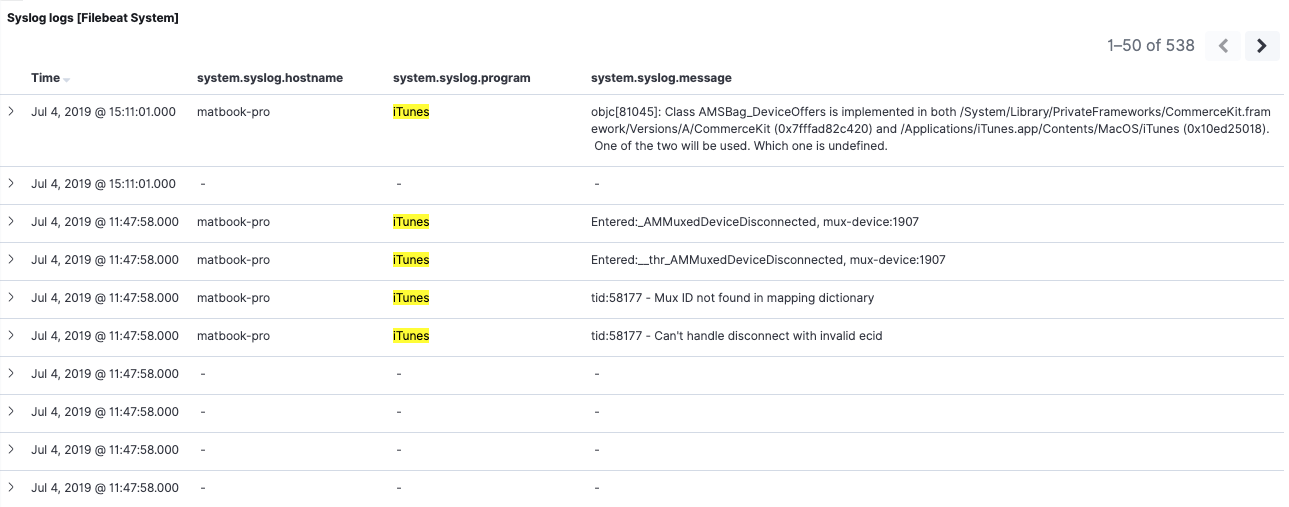
Wenn wir die 7.2-Elemente inspizieren, sehen wir, dass der Filter auf diese Elemente ebenfalls erfolgreich angewendet wurde. Damit haben wir bestätigt, dass unser Filter über system.syslog.program dank des system.syslog.program-Alas auch für unsere 7.2-Daten funktioniert.
Die Visualisierung basiert auf einer Elasticsearch-Aggregation und zeigt ebenfalls die korrekten Ergebnisse für 6.8 und 7.2 für das migrierte Feld system.syslog.program an.
Zurück im 7.2-Dashboard ohne aktive Filter sehen wir, dass Daten für 6.8 und 7.2 angezeigt werden. Wenn wir jedoch denselben Filter wie in 6.8 anwenden, sehen wir ein anderes Verhalten. Der Filter process.name:iTunes liefert jetzt nur noch 7.2-Ergebnisse zurück. Dies liegt daran, dass die Indizes in 6.8 weder ein Feld noch einen Aliase mit dem Namen process.name enthalten.
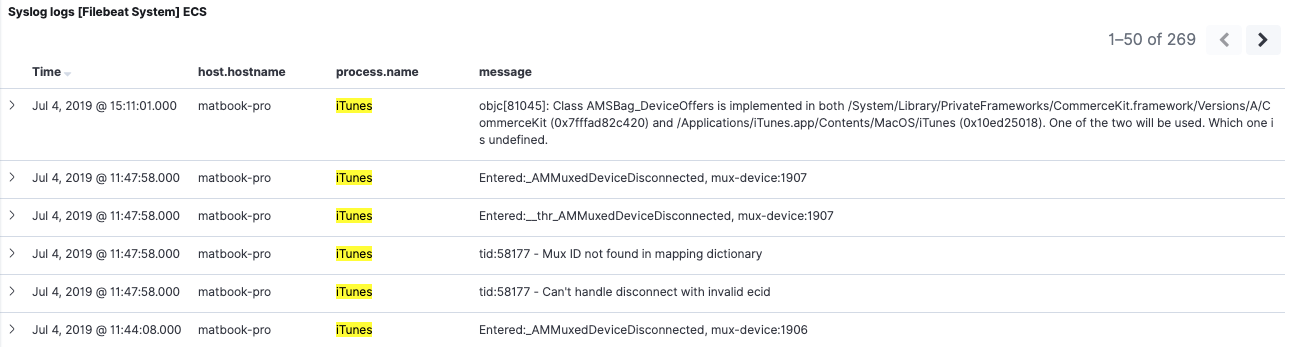
Erneute Indizierung für eine reibungslose Migration
Wir haben besprochen, dass wir mit der erneuten Indizierung drei verschiedene Aspekte der Migration behandeln können: Beheben von Datenkonflikten, Auflösen von inkompatiblen Feldern und Rückmigrieren von ECS-Feldern zur Erhaltung der Kontinuität. Wir werden diese drei Aspekte je an einem Beispiel betrachten.
Wir werden unsere Beats 6-Daten wie folgt bearbeiten:
- Datentypkonflikt: Ändern des Datentyps für system.syslog.pid von keyword zu long
- Inkompatibles Feld: Löschen des Filebeat-Felds source, nachdem wir seinen Inhalt nach log.file.path kopiert haben. Auf diese Weise eliminieren wir den Konflikt mit dem ECS-Feld „source“. Beats 6.6 und höhere Versionen füllen log.file.path bereits mit demselben Wert aus. Dies gilt jedoch nicht für ältere Versionen von Beats 6, daher kopieren wir den Wert mit einer Bedingung.
- Rückmigrieren des ECS-Felds process.name mit dem Wert von system.syslog.process.
Wir werden diese Änderungen wie folgt implementieren:
- Wir werden die Indexvorlage in Filebeat 6.8 für die Verwendung der neuen Datentypen konfigurieren und Felddefinitionen hinzufügen und entfernen.
- Wir werden eine neue Ingest-Pipeline erstellen, die 6.8-Ereignisse bearbeitet, indem sie Felder entfernt oder kopiert.
- Wir werden die Pipeline mit der „_simulate“-API testen.
- Wir werden die Pipeline verwenden, um Daten aus der Vergangenheit neu zu indizieren.
- Außerdem fügen wir einen Aufruf an diese neue Pipeline an das Ende der Ingest-Pipeline in Filebeat 6.8 hinzu, um die empfangenen Ereignisse zu bearbeiten.
Änderungen an Indexvorlagen
Änderungen an Datentypen müssen in der Indexvorlage vorgenommen werden und treten beim Rollover des Index in Kraft. Der Rollover erfolgt standardmäßig am nächsten Tag. Wenn Sie Index Lifecycle Management (ILM) in 6.8 verwenden, können Sie einen Rollover mit der rollover API erzwingen.
Rufen Sie die aktuelle Indexvorlage mit den Kibana Dev-Tools-ab:
GET _template/filebeat-6.8.1
Indexvorlagen können nicht geändert werden, sondern müssen komplett überschrieben werden (Dokumentation). Bereiten Sie einen PUT API-Aufruf mit der gesamten Indexvorlage vor und nehmen Sie dabei einige Änderungen vor:
- Entfernen Sie die Definition für source (alle Zeilen unten, die mit
-beginnen). - Fügen Sie eine Felddefinition für program.name hinzu.
- Ändern Sie den Typ des Felds system.syslog.pid zu long.
PUT _template/filebeat-6.8.1
{
"order" : 1,
"index_patterns" : [
"filebeat-6.8.1-*"
]
...
"mappings": {
"properties" : {
- "source" : {
- "ignore_above" : 1024,
- "type" : "keyword"
- },
"program" : {
"properties" : {
"name": {
"type": "keyword",
"ignore_above": 1024
}
}
},
"system" : {
"properties" : {
"syslog": {
"properties" : {
"pid" : {
"type" : "long"
}
...
}
Bereiten Sie den Hauptteil des API-Aufrufs vor und führen Sie ihn anschließend aus, um die Indexvorlage zu überschreiben. Falls Sie viele ECS-Felder rückmigrieren werden, sollten Sie sich die ECS Elasticsearch-Vorlagen im ECS git-Repository anschauen.
Erneute Indizierung
Im nächsten Schritt schreiben wir eine neue Ingest-Pipeline, um unsere Beats 6.8-Ereignisse zu bearbeiten. In unserem Beispiel kopieren wir system.syslog.program nach process.name, source nach log.file.path (falls nicht bereits ausgefüllt), und entfernen das Feld source:
PUT _ingest/pipeline/filebeat-system-6-to-7
{ "description": "Pipeline to modify Filebeat 6 system module documents to better match ECS",
"processors": [
{ "set": {
"field": "process.name",
"value": "{{system.syslog.program}}",
"if": "ctx.system?.syslog?.program != null"
}},
{ "set": {
"field": "log.file.path",
"value": "{{source}}",
"if": "ctx.containsKey('source') && ctx.log?.file?.path == null"
}},
{ "remove": {
"field": "source"
}}
],
"on_failure": [
{ "set": {
"field": "error.message",
"value": "{{ _ingest.on_failure_message }}"
}}
]
}
Lesen Sie mehr über Ingest-Pipelines und die Painless-Sprache (verwendet in den if-Klauseln).
Wir können diese Pipeline mit der _simulate-API und vollständig ausgefüllten Ereignissen testen, aber der folgende minimalistische Test eignet sich besser für einen Blogeintrag. Beachten Sie, dass log.file.path in einem der Ereignisse bereits ausgefüllt ist (Beats 6.6 und höher), in einem anderen Ereignis jedoch nicht (6.5 und niedriger):
POST _ingest/pipeline/filebeat-system-6-to-7/_simulate
{ "docs":
[ { "_source": {
"log": { "file": { "path": "/var/log/system.log" } },
"source": "/var/log/system.log",
"system": {
"syslog": {
"program": "syslogd"
}}}},
{ "_source": {
"source": "/var/log/system.log",
"system": {
"syslog": {
"program": "syslogd"
}}}}
]
}
Die Antwort des API-Aufrufs enthält die zwei geänderten Ereignisse. Wir sehen, dass unsere Pipeline funktioniert hat, da das Feld source verschwunden ist und beide Ereignisse den Wert dieses Felds in log.file.path enthalten.
Anschließend können wir unsere erneute Indizierung für Indizes ausführen, die keine Schreibvorgänge mehr empfangen (z. B. die Indizes von gestern und davor). Dazu verwenden wir ebenfalls die Ingest-Pipeline für alle Filebeat-Indizes, die wir migrieren. Lesen Sie unbedingt die _reindex-Dokumentation, um sich damit vertraut zu machen, wie Sie im Hintergrund indizieren, Ihre erneute Indizierung drosseln usw. Das folgende Beispiel für eine erneute Indizierung ist völlig ausreichend für unsere geringe Menge an Ereignissen:
POST _reindex
{ "source": { "index": "filebeat-6.8.1-2019.07.04" },
"dest": {
"index": "filebeat-6.8.1-2019.07.04-migrated",
"pipeline": "filebeat-system-6-to-7"
}}
Wenn Sie dem Artikel gefolgt sind und nur den heutigen Index haben, können Sie den API-Aufruf trotzdem ausführen und sich die Zuordnung des migrierten Index ansehen. Löschen Sie den heutigen Index anschließend jedoch nicht, da er immer wieder neu erstellt wird, weil Filebeat 6.8 immer noch Daten sendet.
Andernfalls können wir die alten Indizes löschen, sobald wir die inaktiven Indizes neu indiziert und uns vergewissert haben, dass die neuen Indizes alle gewünschten Korrekturen enthalten.
Bearbeiten eingehender Ereignisse
Beats kann oft so konfiguriert werden, dass die Daten direkt an eine Ingest-Pipeline in der Elasticsearch-Ausgabe gesendet werden (dasselbe gilt für die Elasticsearch-Ausgabe von Logstash). Da wir für diese Demo ein Filebeat-Modul verwenden, das bereits Ingest-Pipelines verwendet, müssen wir stattdessen die Pipeline des Moduls anpassen.
Die beim Setup von Filebeat 6.8 instalilerte Ingest-Pipeline hat den Namen filebeat-6.8.1-system-syslog-pipeline. Es reicht also aus, wenn wir einen Callout zu unserer eigenen Pipeline am Ende der Syslog-Pipeline von Filebeat hinzufügen.
Wir rufen die Pipeline ab, die wir anpassen möchten:
GET _ingest/pipeline/filebeat-6.8.1-system-syslog-pipeline
Anschließend bereiten wir den API-Aufruf vor, mit dem wir die Pipeline überschreiben, indem wir die komplette Pipeline unter dem PUT API-Aufruf angeben. Wir fügen einen „pipeline“-Prozessor am Ende hinzu, um unsere neue Pipeline aufzurufen:
PUT _ingest/pipeline/filebeat-6.8.1-system-syslog-pipeline
{ "description" : "Pipeline for parsing Syslog messages.",
"processors" :
[
{ "grok" : { ... }
...
{ "pipeline": { "name": "filebeat-system-6-to-7" } }
],
"on_failure" : [
{ ... }
]
}
Nachdem wir diesen API-Aufruf ausgeführt haben, werden alle eingehenden Ereignisse vor der Indizierung an ECS angepasst.
Zuletzt können wir _update_by_query verwenden, um Dokumente von vor der Änderung der Pipeline im Live-Index zu bearbeiten. Wir suchen nach Dokumenten, die immer noch das source-Feld enthalten, da diese Dokumente noch aktualisiert werden müssen:
GET filebeat-6.8.1-*/_search
{ "query": { "exists": { "field": "source" }}}
Anschließend indizieren wir nur diese Dokumente neu:
POST filebeat-6.8.1-*/_update_by_query?pipeline=filebeat-system-6-to-7
{ "query": { "exists": { "field": "source" }}}
Überprüfen von Konflikten
Nachdem wir alle Indizes mit Konflikten gelöscht haben, sind nur noch die neu indizierten Indizes übrig. Wir aktualisieren das Indexmuster, um uns zu vergewissern, dass keine Konflikte mehr vorhanden sind. Zurück im Filebeat 7-Dashboard sehen wir, dass unsere Daten aus 6.8 jetzt brauchbarer sind, da wir das Feld process.name rückmigriert haben:
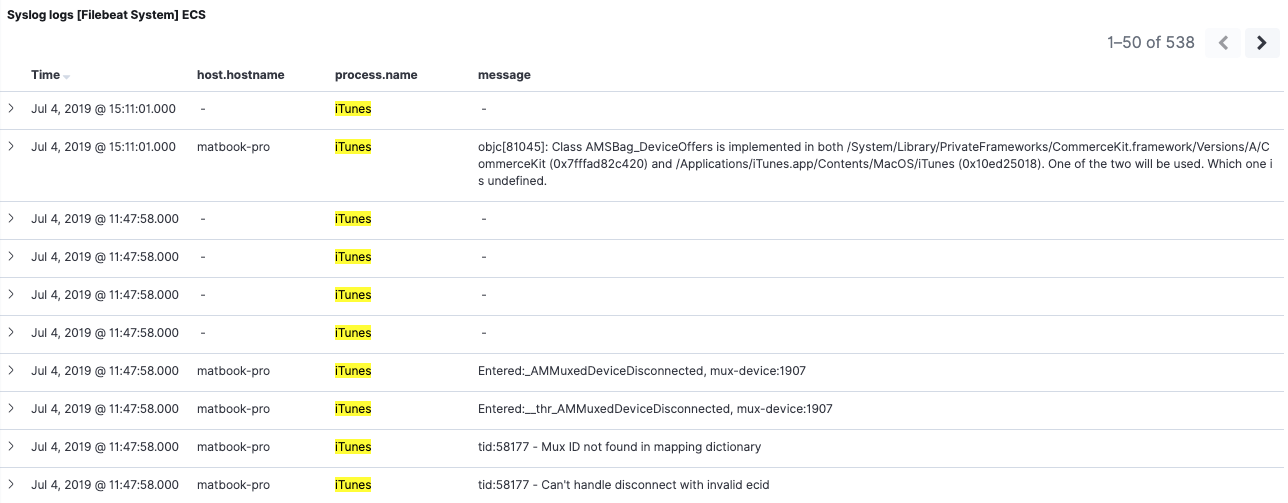
In unserem Beispiel haben wir nur ein Feld rückmigriert. Sie können selbstverständlich beliebig viele Felder rückmigrieren.
Bereinigung nach der Migration
Bei Ihrer Migration bearbeiten Sie höchstwahrscheinlich Ihre individuellen Dashboards und Anwendungen, die Beats-Ereignisse über die API verarbeiten, um sie an die neuen ECS-Feldnamen anzupassen.
Nachdem Sie die Migration zu Beats 7 komplett abgeschlossen haben und keine Feld-Aliase mehr verwenden, können Sie sie entfernen, um wie oben erwähnt Arbeitsspeicher freizugeben. Um die Aliase zu entfernen, löschen wir das Attribut migration.6_to_7.enabled aus „filebeat.yml“ und überschreiben anschließend die Filebeat 7.2-Vorlage mit:
./filebeat setup --template -e -E 'setup.template.overwrite=true'
Genau wie bei den vorherigen Änderungen an der Filebeat 6.8-Vorlage tritt die neue Vorlage ohne Aliase beim nächsten Rollover des Filebeat 7.2-Index in Kraft.
Fazit
In diesem Artikel haben wir die Schritte für die Migration Ihrer Daten zu ECS in einer Beats-Umgebung behandelt. Wir haben die Vorteile und Einschränkungen der Upgradeprozedur besprochen. Die Einschränkungen können umgangen werden, indem Sie Daten aus der Vergangenheit neu indizieren und sogar aktuelle eingehende Beats 6-Daten bei der Ingestion bearbeiten.
Im Anschluss an die Migrationsübersicht haben wir das Systemmodul von Filebeat Schritt für Schritt von 6.8 auf 7.2 aktualisiert. Wir haben die Unterschiede zwischen Ereignissen aus Filebeat 6.8 und 7.2 besprochen und uns die Schritte angesehen, mit denen Sie Daten aus der Vergangenheit neu indizieren und neu eingehende Daten bearbeiten können.
Ein neues Schema hat zwangsläufig umfassende Auswirkungen auf vorhandene Installationen, aber in diesem Fall sind wir davon überzeugt, dass sich der Aufwand lohnt. Unsere Gründe dafür finden Sie in den Artikeln Wir stellen vor: das Elastic Common Schema (ECS) und Why Observability loves the Elastic Common Schema (Warum Observability und das Elastic Common Schema perfekt zueinander passen, nur auf Englisch).
Falls Ihre Umgebung andere Pipelines als Beats für die Dateningestion verwendet, schauen Sie regelmäßig vorbei. Wir haben einen weiteren Blogeintrag geplant, in dem wir die Migration einer benutzerdefinierten Ingestions-Pipeline nach ECS beschreiben werden.
Falls Sie Fragen zu ECS haben oder Hilfe bei Ihrem Beats-Upgrade brauchen, besuchen Sie unsere Diskussionsforen und markieren Sie Ihre Frage mit dem Tag elastic-common-schema. Weitere Informationen zu ECS finden Sie in unserer Dokumentation, und auf GitHub können Sie zu ECS beitragen.
Referenzen
Dokumentation
- Upgrade Assistant
- Upgrading the Elastic Stack (Elastic Stack aktualisieren)
- Breaking changes in 7.0 (Wichtige Änderungen in 7.0)
- Reindex (Neu indizieren)
- Ingest pipeline (Ingest-Pipeline)
- Ingest pipeline’s simulate API (Simulate-API für die Ingest-Pipeline)
- Painless language (Painless-Sprache)
- Mappings (Zuordnungen) und index templates (Indexvorlagen)
- Datei mit einer Dokumentation aller Feldänderungen: ecs-migration.yml
- Beispiele für ECS Elasticsearch-Indexvorlagen
Blogs und Videos
- Introducing ECS (Einführung in ECS, Blog)
- Introducing ECS (Einführung in ECS, Webinar)
- ECS: How to migrate your data (ECS: Migration Ihrer Daten, Webinar)
- Why observability loves the Elastic Common Schema (Warum Observability und das Elastic Common Schema perfekt zueinander passen, Blog)
- Upgrading the Elastic Stack with the 7.x Upgrade Assistant (Elastic Stack mit 7.x Upgrade Assistant aktualisieren, Blog)
Allgemein
- Stellen Sie Fragen zu ECS in unseren Diskussionsforen und markieren Sie Ihre Frage mit dem Tag „elastic-common-schema“.
- Offizielle ECS-Dokumentation
- ECS Github-Repository