Direktes Ingestieren von Daten aus Google Cloud Storage in Elastic mit Google Dataflow


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Wir freuen uns, heute die Einführung der Unterstützung für das direkte Ingestieren von Daten aus Google Cloud Storage (GCS) in den Elastic Stack mit Google Dataflow bekannt geben zu können. Entwickler, Site-Reliability-Engineers (SREs) und Security-Analysten können so mit ein paar wenigen Klicks in der Google Cloud Console Daten aus GCS in den Elastic Stack ingestieren.
Viele Entwickler, SREs und Security-Analysts nutzen für das Speichern von Log- und Ereignisdaten aus Anwendungen und Infrastruktur in Google Cloud GCS, während für das Troubleshooting, das Monitoring oder das Aufspüren von Verhaltensanomalien bei diesen Anwendungen und dieser Infrastruktur der Elastic Stack zum Einsatz kommt. Um das Nutzungserlebnis bei beiden Lösungen aufzuwerten, haben Google und Elastic zusammen eine nutzungsfreundliche, integrierte Möglichkeit entwickelt, Log- und Ereignisdaten aus GCS in den Elastic Stack zu ingestieren. Das ermöglicht einfachere Daten-Pipeline-Architekturen, eine Reduzierung des operativen Overheads und ein schnelleres Troubleshooting – all dies mit ein paar wenigen Klicks in der Google Cloud Console und ganz ohne die Notwendigkeit, einen eigenen Datenprozessor zu erstellen.
In diesem Blogpost beschäftigen wir uns damit, wie Sie mit Google Dataflow ganz ohne Agent Daten aus GCS in den Elastic Stack ingestieren können.
Einfacheres und schnelleres Ingestieren von Daten aus GCS
Google Cloud Storage (GCS) ist eine Objektspeicherlösung, die häufig mit Amazon S3 oder Azure Blob Storage verglichen wird. Sie wird gern für das Sichern und Archivieren von Daten, für die Datenanalyse ohne Streaming oder auch für das Hosten einfacher Webseiten und Anwendungen zu einem günstigen Preis verwendet. Entwickler, SREs oder Security-Analysten können GCS nutzen, um auf der Plattform Log- und Ereignisdaten für ihre Anwendungen oder ihre Infrastruktur zu sichern oder zu archivieren. Denkbar ist auch, dass ein Google Cloud-Nutzer eine Daten-Pipeline hat, bei der nicht alle Daten in den Elastic Stack ingestiert werden, sondern bei der einige Daten für die spätere Analyse in GCS gespeichert werden.
Wenn für die Analyse eine externe Analytics-Lösung wie Elastic verwendet werden soll, müssen Sie entscheiden, wie die Log- und Ereignisdaten ihren Weg in diese externe Lösung finden. Am besten wäre es, wenn die Daten mit einigen wenigen Klicks in der Google Cloud Console direkt aus GCS in den Elastic Stack ingestiert werden könnten. Dank eines neuen Dropdown-Menüs in Google Dataflow, einem verbreiteten serverlosen Datenprozessor auf der Basis von Apache Beam, ist genau dies jetzt möglich. Dataflow befördert Log- und Ereignisdaten aus GCS direkt in den Elastic Stack. Derzeit wird das Dateiformat CSV unterstützt, aber wir werden demnächst auch die Verwendung von JSON möglich machen.
Ganz allgemein läuft die Dateningestion wie unten dargestellt ab. Die Integration funktioniert bei allen Nutzern unabhängig von der verwendeten Umgebung, also gleich ob in Elastic Stack auf Elastic Cloud, in Elastic Cloud im Google Cloud Marketplace oder in selbstverwalteten Umgebungen.
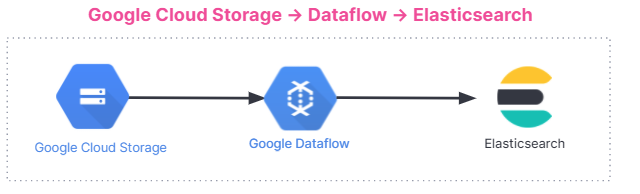
Erste Schritte
Am besten lässt sich die GCS-Ingestionsfunktion anhand eines Beispiels erklären. Im folgenden Beispiel analysieren wir Erdbebendaten, die vom United States Geological Survey (USGS) bereitgestellt werden. Der USGS unterhält einen öffentlich zugänglichen Satz von Daten, der Echtzeitinformationen über Erdbeben sowie statistische Daten zur seismischen Aktivität enthält. Wir verwenden die in Form einer CSV-Datei bereitgestellten USGS-Daten zu Erdbeben ab einer Stärke von 2,5 aus dem letzten Monat. Im Folgenden werden nur die ersten fünf Zeilen präsentiert, damit Sie eine Vorstellung davon erhalten, wie diese Daten aussehen:

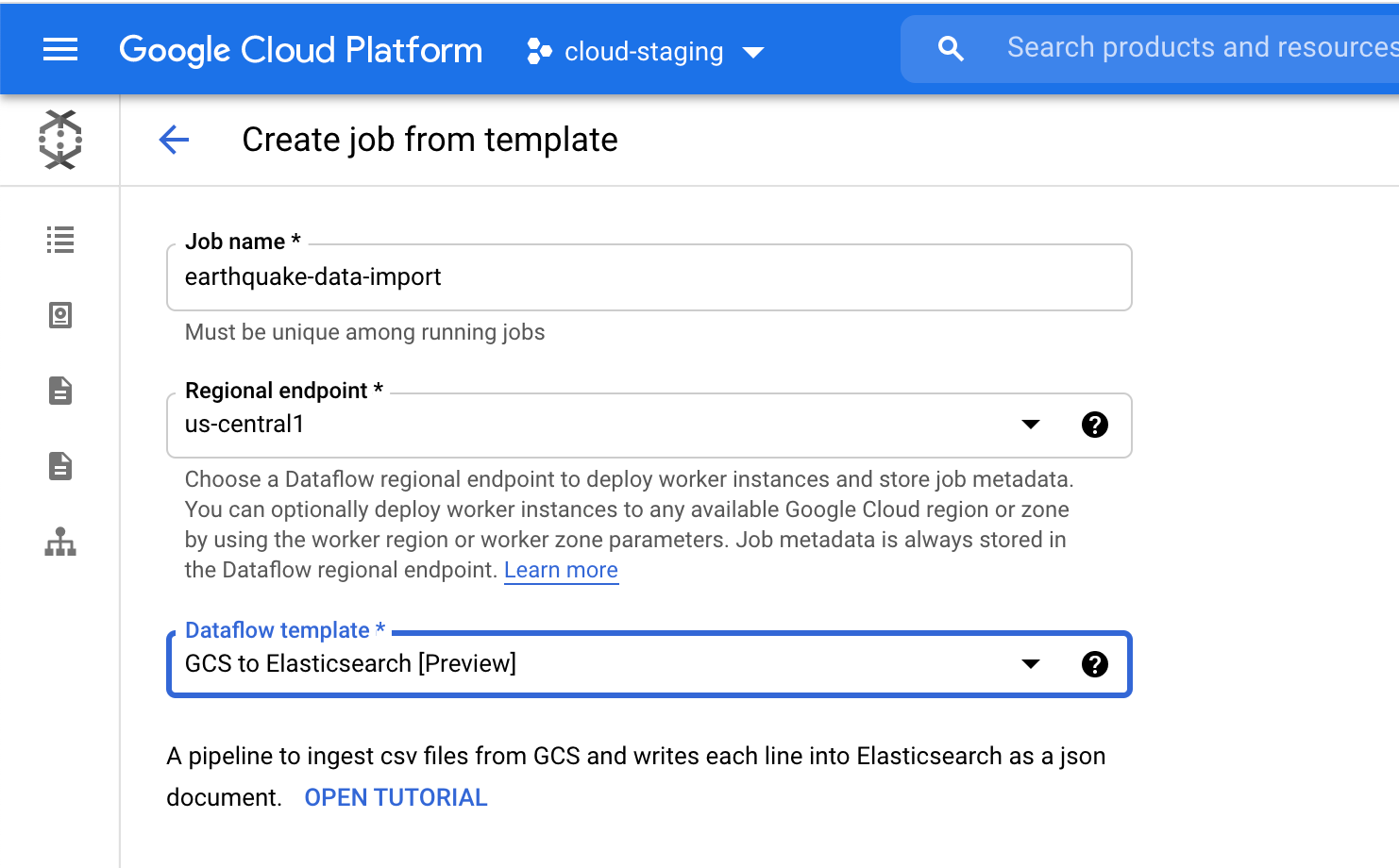
Wir wählen in der Google Cloud Console auf der Seite „Dataflow“ die Vorlage GCS to Elasticsearch aus. Die Vorlage erstellt das Schema für das JSON-Dokument und nutzt dabei eine der folgenden Optionen:
- Javascript UDF (sofern bereitgestellt)
- JSON-Schema (sofern bereitgestellt)
- CSV-Kopfzeilen* (Standardeinstellung)
Wenn eine UDF oder ein JSON-Schema bereitgestellt wird, wird dieser Option der Vorrang vor den CSV-Kopfzeilen gegeben.
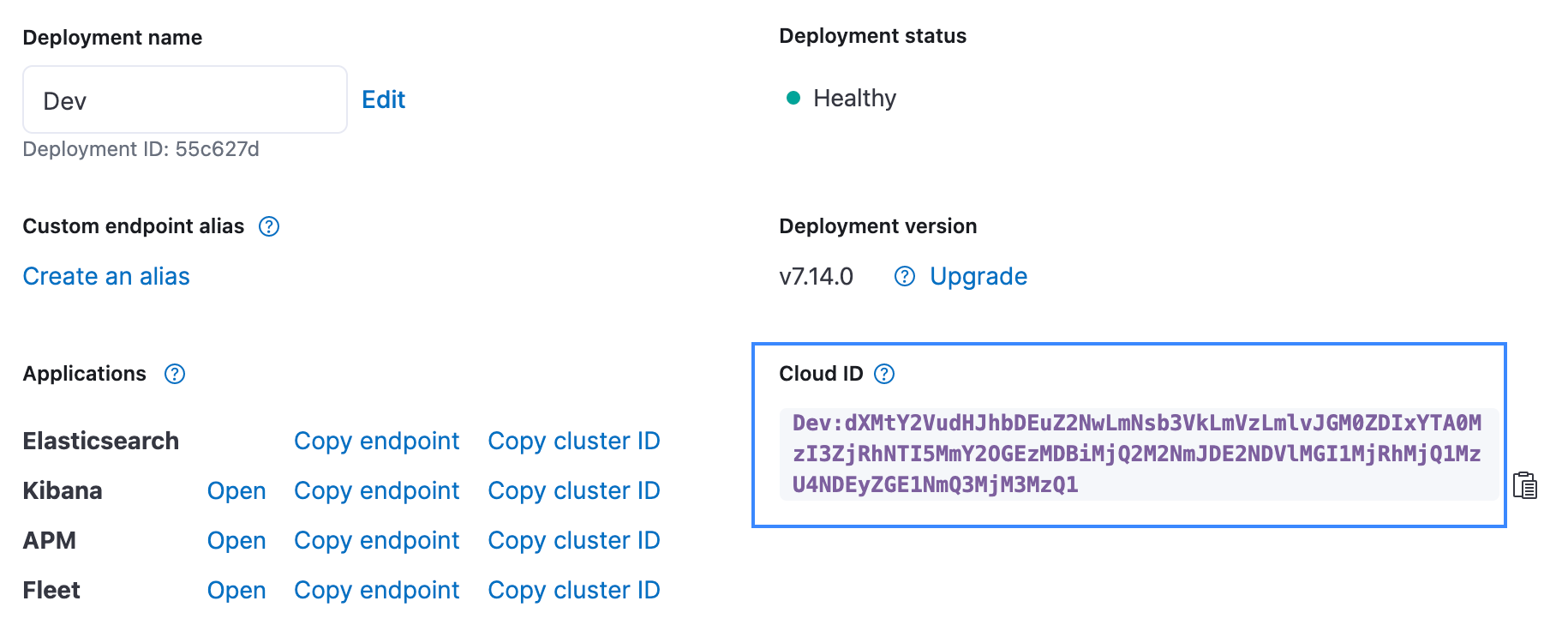
Wir wählen im Feld Elasticsearch Index den Namen des Index aus, in den unsere Daten geladen werden. In unserem Beispiel ist das der Index quakes.
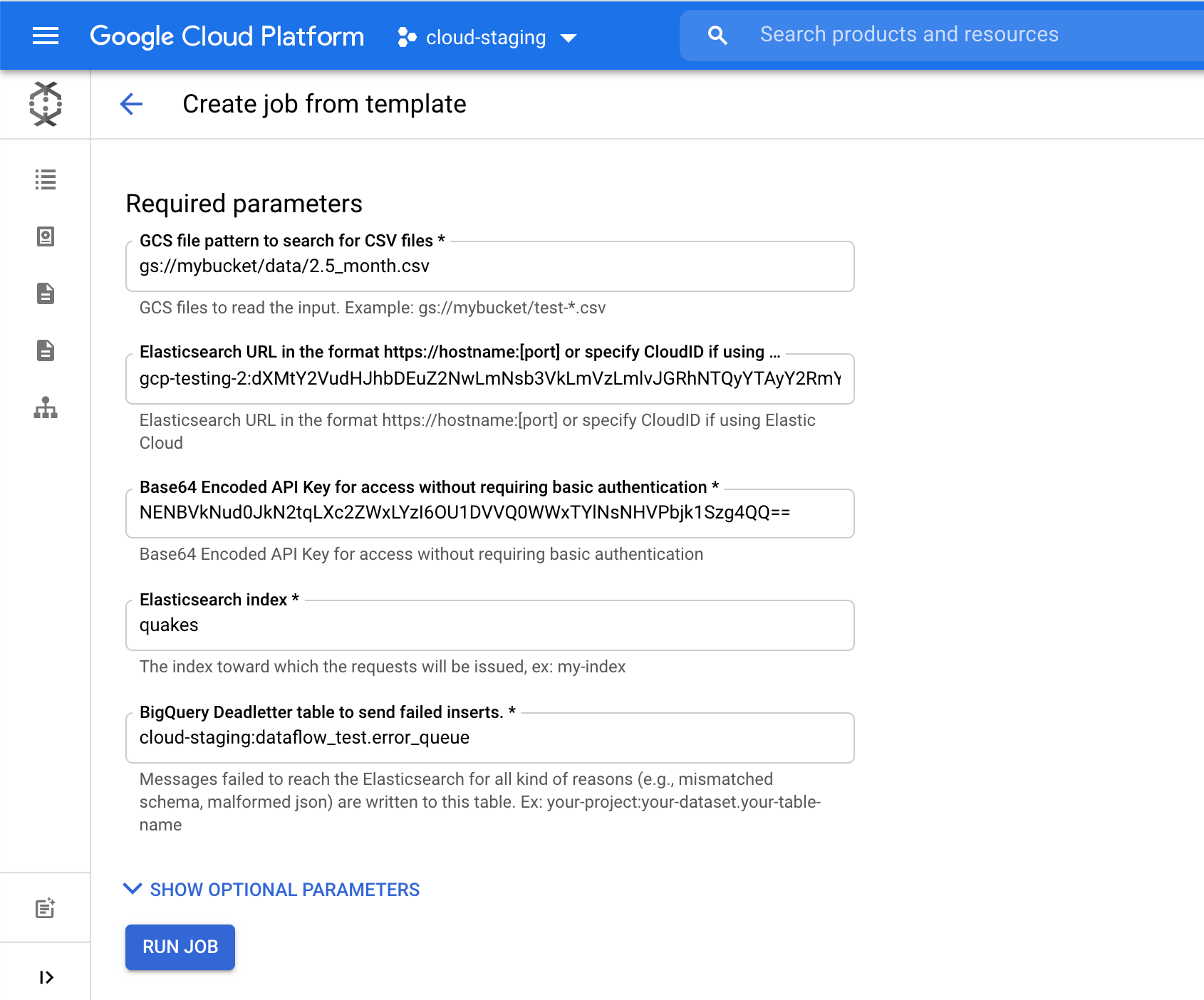
Wir klicken auf Job ausführen, um das Ingestieren dieser Erdbebendaten aus GCS in Elasticsearch zu starten. Das alles geht, ohne dass wir dazu die Google Cloud Console verlassen müssen.
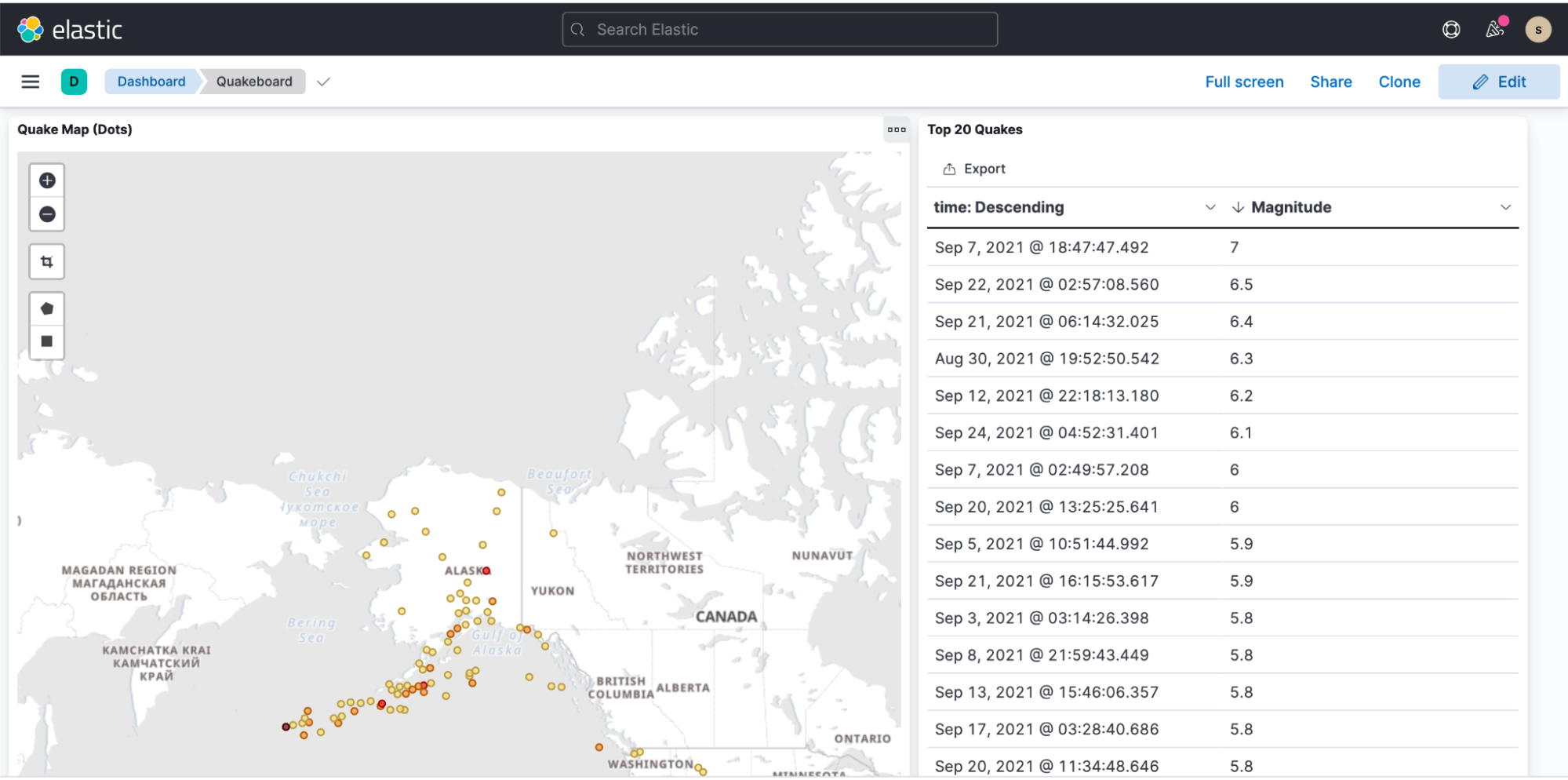
Anschließend können wir zu Kibana wechseln, ein Indexmuster erstellen und mit dem Visualisieren der Daten beginnen. Das alles lässt sich innerhalb weniger Minuten erledigen.
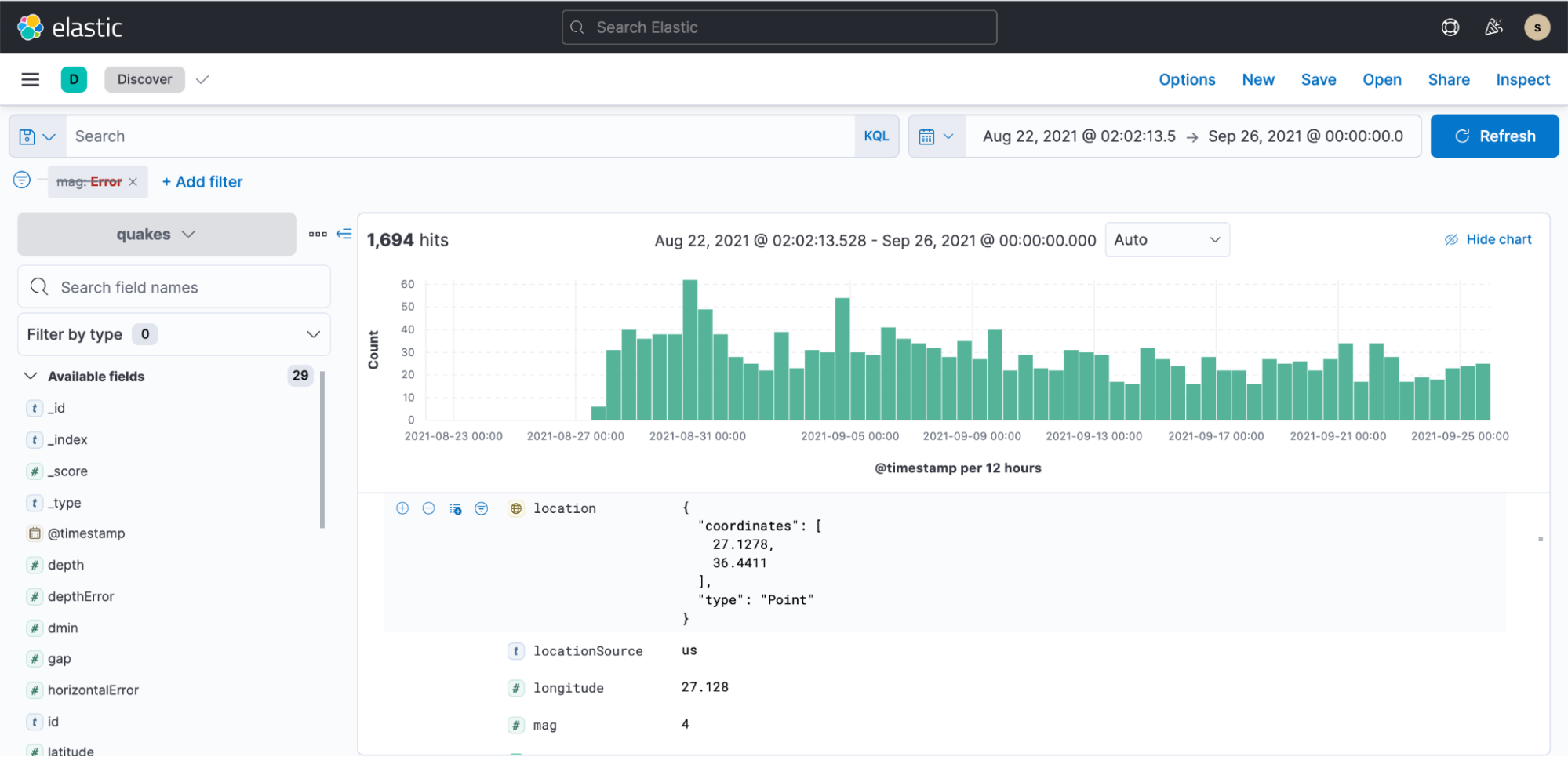
Beispiel-Dashboard mit Erdbebendaten:
Fazit
Elastic erleichtert es Kunden immer mehr, selbst zu bestimmen, wo Jobs ausgeführt werden und was dabei genutzt wird. Diese optimierte Google Cloud-Integration ist das jüngste Beispiel dafür. Elastic Cloud macht den Elastic Stack noch wertvoller, denn Kunden können so schneller mehr erledigen – ideal, um das Potenzial unserer Plattform bestmöglich auszuschöpfen. Wenn Sie Elastic auf Google Cloud selbst erleben möchten, besuchen Sie den Google Cloud Marketplace oder elastic.co.Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken