Erste Schritte mit Vega-Visualisierungen in Kibana
Die deklarative Vega-Grammatik ist eine leistungsstarke Methode zum Visualisieren Ihrer Daten. Mit diesem in Kibana 6.2 eingeführten Feature können Sie aussagekräftige Vega- und Vega-Lite-Visualisierungen mit Ihren Elasticsearch-Daten erstellen. Ich werde Ihnen die Vega-Sprache mit einigen einfachen Beispielen demonstrieren.
Öffnen Sie zunächst den Vega-Editor, ein praktisches Tool, mit dem Sie die reine Vega-Sprache ausprobieren können (ohne Elasticsearch-Anpassungen). Wenn Sie den folgenden Code kopieren, sollte im rechten Bereich der Text „Hello Vega!“ angezeigt werden.

{
"$schema": "https://vega.github.io/schema/vega/v3.json",
"width": 100, "height": 30,
"background": "#eef2e8",
"padding": 5,
"marks": [
{
"type": "text",
"encode": {
"update": {
"text": { "value": "Hello Vega!" },
"align": { "value": "center"},
"baseline": { "value": "middle"},
"stroke": { "value": "#A32299" },
"angle": { "value": 15 },
"x": { "signal": "width/2" },
"y": { "signal": "height/2" }
}
}
}
]
}
Der Block marks (Markierungen) enthält ein Array von Zeichenobjekten wie Text, Linien und Rechtecke. Jedes mark-Element enthält zahlreiche Parameter im encoding set (Codierungssatz). Jeder Parameter enthält entweder einen konstanten Wert oder das Ergebnis einer Berechnung (Signal) in der „update“-Phase. Für die Textmarkierung geben wir die Zeichenfolge ein, positionieren den Text relativ zu den angegebenen Koordinaten, drehen ihn und legen die Textfarbe fest. Die X- und Y-Koordinaten beziehen sich auf die Breite und Höhe des Diagramms, und der Text wird in der Mitte positioniert. Sie haben noch viele weitere Parameter für Textmarkierungen zur Auswahl. Dort finden Sie außerdem eine interaktive Demo für Textmarkierungen, in der Sie verschiedene Parameterwerte ausprobieren können.
„$schema“ ist lediglich eine ID der erforderlichen Version der Vega-Engine, und „Background“ (Hintergrund) legt fest, dass das Diagramm nicht transparent ist. Die Parameter „width“ (Breite) und „height“ (Höhe) definieren die ursprüngliche Canvas-Größe. Die tatsächliche Größe des Diagramms kann sich unter Umständen auf Basis des Inhalts und der Optionen für automatische Größenänderungen ändern. Kibana verwendet „fit“ (Anpassen) anstelle von „pad“ (Auffüllen als Standardwert für die automatische Größenänderung, daher sind „height“ und „width“ optional. Der Parameter „padding“ (Auffüllung) fügt einen Freiraum um das Diagramm herum zusätzlich zur Breite und Höhe hinzu.
Datengesteuertes Diagramm
Im nächsten Schritt zeichnen wir ein datengesteuertes Diagramm mit der Rechteck-Markierung. Im Datenbereich können wir mehrere Datenquellen hinzufügen, entweder hartcodiert oder als URL. In Kibana können Sie außerdem Elasticsearch-Abfragen direkt eingeben. Unsere Datentabelle „vals“ hat vier Zeilen und die zwei Spalten „category“ (Kategorie) und „count“ (Anzahl). Wir verwenden „category“, um den Balken auf der X-Ache zu positionieren, und „count“ für die Höhe des Balkens. Beachten Sie, dass sich der Null-Wert für die Y-Koordinate am oberen Rand befindet und die Achse nach unten wächst.
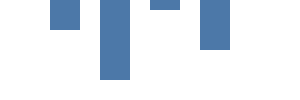
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 300, "height": 100,
"data": [ {
"name": "vals",
"values": [
{"category": 50, "count": 30},
{"category": 100, "count": 80},
{"category": 150, "count": 10},
{"category": 200, "count": 50}
]
} ],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"field": "category"},
"width": {"value": 30},
"y": {"field": "count"},
"y2": {"value": 0}
}
}
} ]
}
Die „rect“-Markierung definiert „vals“ als Datenquelle. Die Markierung wird für jeden Wert in den Quelldaten (Tabellenzeile oder Datenwert) einmal gezeichnet. Im Gegensatz zum vorherigen Diagramm sind die X- und Y-Parameter nicht hartcodiert, sondern stammen aus den Feldern des Datenwerts.
Skalieren
Skalierung ist eines der wichtigsten, jedoch auch eines der komplexeren Konzepte in Vega. In den bisherigen Beispielen waren die Pixelkoordinaten auf dem Bildschirm in den Daten hartcodiert. Dies erleichtert uns zwar die Verarbeitung, aber in der Praxis liegen Daten fast nie in dieser Form vor. Stattdessen haben die Quelldaten eigene Einheiten (z. B. die Anzahl der Ereignisse), und das Diagramm ist dafür verantwortlich, die Ausgangswerte auf die gewünschte Diagrammgröße in Pixeln zu skalieren.
In diesem Beispiel verwenden wir eine lineare Skalierung, also eine mathematische Funktion, bei der ein Wert aus der Domäne aus den Quelldaten (in diesem Diagramm die „count“-Werte 1000..8000 inklusive „count=0“) in den gewünschten Bereich konvertiert wird (die Grafik in unserem Fall hat die Höhe 0..99). Wir fügen "scale": "yscale" zu den Parametern „y“ und „y2“ hinzu, um den „count“-Wert mit dem Skalierer „yscale“ zu Bildschirmkoordinaten zu konvertieren (0 wird zu 99, und 8000, der größte Wert in den Quelldaten, wird zu 0). Der Parameter „height“ ist hier ein Sonderfall, da der Wert umgekehrt wird, um 0 am unteren Ende des Diagramms anzuzeigen.
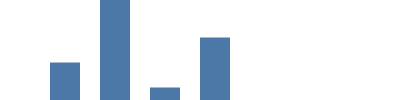
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 100,
"data": [ {
"name": "vals",
"values": [
{"category": 50, "count": 3000},
{"category": 100, "count": 8000},
{"category": 150, "count": 1000},
{"category": 200, "count": 5000}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"field": "category"},
"width": {"value": 30},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value": 0}
}
}
} ]
}
Bandskalierung
In diesem Tutorial verwenden wir eine weitere der mehr als 15 Vega-Skalierungsarten: die Bandskalierung. Diese Skalierung ist hilfreich, wenn Sie eine Reihe von Werten (z. B. Kategorien) haben, die Sie als Bänder darstellen möchten, wobei jedes Band denselben Anteil der Gesamtbreite des Diagramms ausfüllt. In diesem Fall teilt die Bandskalierung jeder der vier einzigartigen Kategorien dieselbe proportionale Breite zu (etwa 400/4, abzüglich 5 % Freiraum zwischen den Balken und an den Rändern). Das Band {"scale": "xscale", "band": 1} erhält 100 % der Breite des Bands für den „width“-Parameter der Markierung.
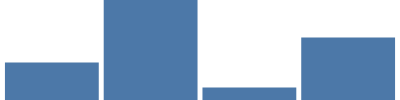
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 100,
"data": [ {
"name": "vals",
"values": [
{"category": "Oranges", "count": 3000},
{"category": "Pears", "count": 8000},
{"category": "Apples", "count": 1000},
{"category": "Peaches", "count": 5000}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
},
{
"name": "xscale",
"type": "band",
"domain": {"data": "vals", "field": "category"},
"range": "width",
"padding": 0.05
}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"scale": "xscale", "field": "category"},
"width": {"scale": "xscale", "band": 1},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value": 0}
}
}
} ]
}
Achsen
Kein Diagramm ist vollständig ohne Achsenbeschriftungen. Die Achsendefinition verwendet unsere zuvor definierten Skalierungen, und wir können ganz einfach über den Namen auf die Skalierung verweisen und die Seite angeben, auf der wir die Beschriftung platzieren möchten. Fügen Sie diesen Code als oberstes Element zum vorherigen Codebeispiel hinzu.
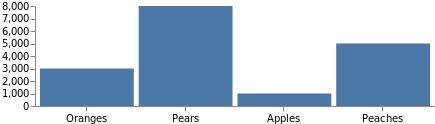
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
Die Gesamtgröße des Diagramms wurde automatisch angepasst, um die Achsen unterzubringen. Sie können "autosize": "fit" am Anfang der Spezifikation hinzufügen, um zu erzwingen, dass das Diagramm seine ursprüngliche Größe behält.
Datentransformationen und Bedingungen
Daten müssen vor der grafischen Darstellung oft aufbereitet werden. Vega bietet zu diesem Zweck zahlreiche Transformationen an. Wir werden die am häufigsten verwendete Formel-Transformation verwenden, um ein Zufallszahlenfeld „count“ dynamisch zu unseren Quelldatenwerten hinzuzufügen. Außerdem werden wir in diesem Diagramm die Füllfarbe des Balkens wie folgt anpassen: rot für Werte kleiner als 333, gelb für Werte kleiner als 666 und grün für Werte größer als 666. Dasselbe hätten wir auch mit einer Skalierung erreichen können, indem wir die Domäne der Quelldaten zu den Farbsätzen oder zu einem Farbschema zuordnen.
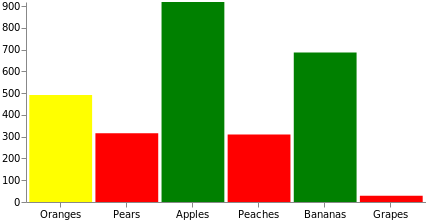
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 200,
"data": [ {
"name": "vals",
"values": [
{"category": "Oranges"},
{"category": "Pears"},
{"category": "Apples"},
{"category": "Peaches"},
{"category": "Bananas"},
{"category": "Grapes"}
],
"transform": [
{"type": "formula", "as": "count", "expr": "random()*1000"}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
},
{
"name": "xscale",
"type": "band",
"domain": {"data": "vals", "field": "category"},
"range": "width",
"padding": 0.05
}
],
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"scale": "xscale", "field": "category"},
"width": {"scale": "xscale", "band": 1},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value": 0},
"fill": [
{"test": "datum.count < 333", "value": "red"},
{"test": "datum.count < 666", "value": "yellow"},
{"value": "green"}
]
}
}
} ]
}
Dynamische Daten mit Elasticsearch und Kibana
Nachdem Sie die Grundlagen kennen, können Sie jetzt ein zeitbasiertes Liniendiagramm mit zufällig generierten Elasticsearch-Daten erstellen. Dieser Vorgang ähnelt der Erstellung eines neuen Vega-Diagramms in Kibana, nur dass wir hier die Vega-Sprache anstatt des Kibana-Standards Vega-Lite (eine vereinfachte und übergeordnete Version von Vega) verwenden.
In diesem Beispiel verwenden wir hartcodierte Daten mit „values“ anstelle von tatsächlichen Abfragen mit „url“. Auf diese Weise können wir unsere Tests weiterhin im Vega-Editor ausführen, der keine Kibana-Elasticsearch-Abfragen unterstützt. Wenn Sie „values“ wie unten gezeigt durch den „url“-Abschnitt ersetzen, wird die Grafik in Kibana vollständig dynamisch angezeigt.
Unsere Abfrage zählt die Dokumente pro Zeitintervall und verwendet den Zeitbereich und die Kontextfilter, die ein Dashboard-Benutzer ausgewählt hat. Weitere Informationen finden Sie unter Elasticsearch-Abfragen in Kibana.
"url": {
"%context%": true,
"%timefield%": "@timestamp",
"index": "_all",
"body": {
"aggs": {
"time_buckets": {
"date_histogram": {
"field": "@timestamp",
"interval": {"%autointerval%": true},
"extended_bounds": {
"min": {"%timefilter%": "min"},
"max": {"%timefilter%": "max"}
},
"min_doc_count": 0
}
}
},
"size": 0
}
Wenn wir den Code ausführen, erhalten wir das folgende Ergebnis (einige irrelevante Felder wurden zur Vereinfachung ausgelassen):
"aggregations": {
"time_buckets": {
"buckets": [
{"key": 1528061400000, "doc_count": 1},
{"key": 1528063200000, "doc_count": 45},
{"key": 1528065000000, "doc_count": 49},
{"key": 1528066800000, "doc_count": 17},
...
Wie Sie sehen, sind unsere gewünschten Daten im Array „aggregations.timebuckets.buckets“ enthalten. Mit der Anweisung "format": {"property": "aggregations.timebuckets.buckets"} in der Datendefinition können Sie Vega anweisen, nur das Array zu berücksichtigen.
Unsere X-Achse basiert nicht mehr auf Kategorien, sondern ist eine Zeitachse (das Feld „key“ (Schlüssel) liegt als UNIX-Zeit vor und kann von Vega direkt verwendet werden). Wir ändern also den Typ von „xscale“ zu „time“ (Zeit) und passen alle Felder an, um „key“ und „doc_count“ (Dokumentanzahl) zu verwenden. Außerdem müssen wir den Markierungstyp zu „line“ (Zeile) ändern und die Parameterkanäle „X“ und „Y“ einbinden. Und schon haben wir ein Liniendiagramm. Möglicherweise möchten Sie die Beschriftungen der X-Achse mit den Parametern „format“ (Formatierung), „labelAngle“ (Beschriftungswinkel) und „tickCount“ (Taktanzahl) anpassen.
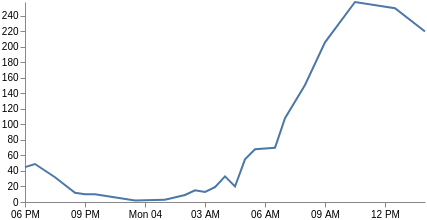
{
"$schema": "https://vega.github.io/schema/vega/v3.json",
"width": 400, "height": 200,
"data": [
{
"name": "vals",
"values": {
"aggregations": {
"time_buckets": {
"buckets": [
{"key": 1528063200000, "doc_count": 45},
{"key": 1528065000000, "doc_count": 49},
{"key": 1528068600000, "doc_count": 32},
{"key": 1528072200000, "doc_count": 12},
{"key": 1528074000000, "doc_count": 10},
{"key": 1528075800000, "doc_count": 10},
{"key": 1528083000000, "doc_count": 2},
{"key": 1528088400000, "doc_count": 3},
{"key": 1528092000000, "doc_count": 9},
{"key": 1528093800000, "doc_count": 15},
{"key": 1528095600000, "doc_count": 13},
{"key": 1528097400000, "doc_count": 19},
{"key": 1528099200000, "doc_count": 33},
{"key": 1528101000000, "doc_count": 20},
{"key": 1528102800000, "doc_count": 55},
{"key": 1528104600000, "doc_count": 68},
{"key": 1528108200000, "doc_count": 70},
{"key": 1528110000000, "doc_count": 108},
{"key": 1528113600000, "doc_count": 151},
{"key": 1528117200000, "doc_count": 206},
{"key": 1528122600000, "doc_count": 258},
{"key": 1528129800000, "doc_count": 250},
{"key": 1528135200000, "doc_count": 220}
]
}
}
},
"format": {"property": "aggregations.time_buckets.buckets"}
}
],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "doc_count"},
"range": "height"
},
{
"name": "xscale",
"type": "time",
"domain": {"data": "vals", "field": "key"},
"range": "width"
}
],
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
"marks": [
{
"type": "line",
"from": {"data": "vals"},
"encode": {
"update": {
"x": {"scale": "xscale", "field": "key"},
"y": {"scale": "yscale", "field": "doc_count"}
}
}
}
]
}
Halten Sie Ausschau in unserem Blog nach weiteren Beiträgen zu Vega. Ich habe vor, einen weiteren Beitrag zur Verarbeitung von Elasticsearch-Ergebnissen zu verfassen, insbesondere zu Aggregationen und verschachtelten Daten.
Nützliche Links
- Kibana Vega-Dokumentation
- Vega-Dokumentation
- Vega-Beispiele
- Vega-Lite-Dokumentation
- Vega-Lite-Beispiele