向量数据库应该为您做什么?




Elasticsearch:不仅仅是向量,深受开发人员喜爱
没有任何漏洞或妥协——一切都能协同运作,因为它就是这样构建的。
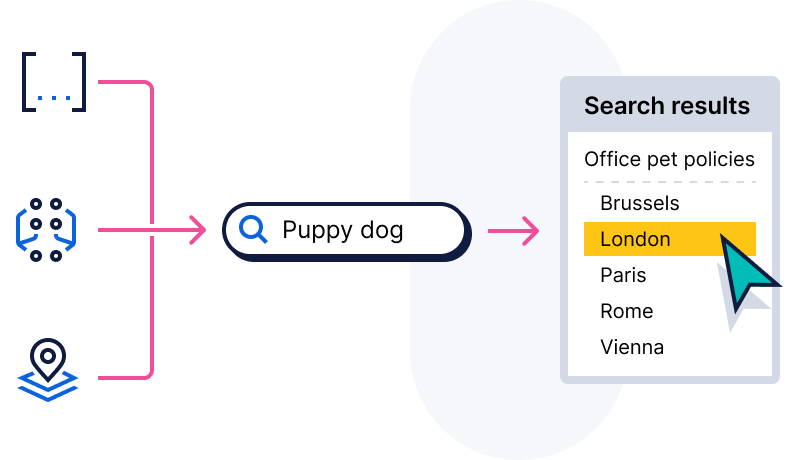

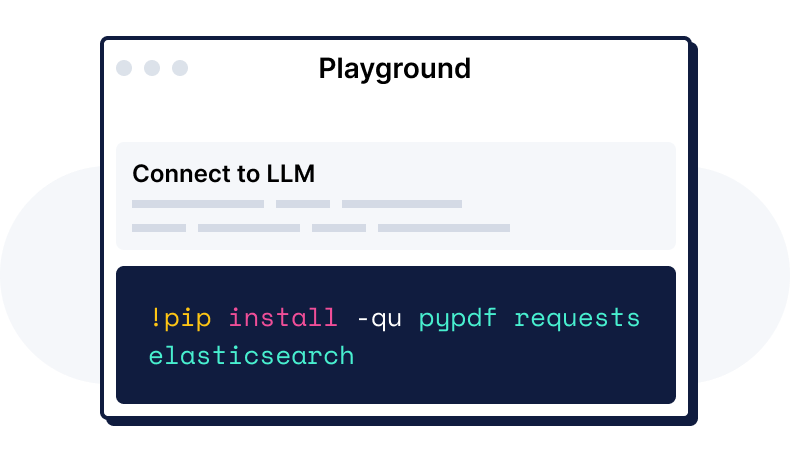
只需一次调用
索引、搜索、筛选、应用基于角色的访问控制(RBAC)——针对文本、嵌入、地理、时间序列或元数据。
通过将数据转换为密集向量,捕获数据的含义、上下文和关联。创建嵌入博文
POST _inference/my-e5-endpoint { "input": "How many adult mallard ducks fit in an american football field?" }
POST _inference/my-e5-endpoint
{
"input": "How many adult mallard ducks fit in an american football field?"
}
同类最佳?内置
从 Elasticsearch 内置的 Jina AI 模型开始。或者,通过 AI 生态系统中的原生集成,接入您已在使用的模型。







高品质社区
从提示到产品,这些组织都信任 Elastic 来构建下一代搜索
客户聚焦

Reed 是英国最大的招聘机构,它利用 Elasticsearch 中的向量嵌入将求职者和雇主联系起来。
客户聚焦

Stack Overflow 将人类专家的智慧与生成式 AI 相结合,加快了从开发人员知识库中检索可靠信息的速度。
客户聚焦

Adobe 可以扩展、管理多种用例,并将机器学习功能与 Elastic 结合使用。
向量数据库超集
根据您想要打造的向量搜索体验来选择向量数据库。
其他向量数据库
Elasticsearch
灵活的文档模型
部分支持
全面支持(免费)
安全存储(文档和字段级安全性)
部分支持
全面支持(付费)
处理结构化和非结构化数据
部分支持
全面支持(免费)
采集工具(客户端、网络爬虫*、连接器*、*推理管道*)
部分支持
全面支持(*付费)
实时文档和元数据更新
部分支持
全面支持(免费)
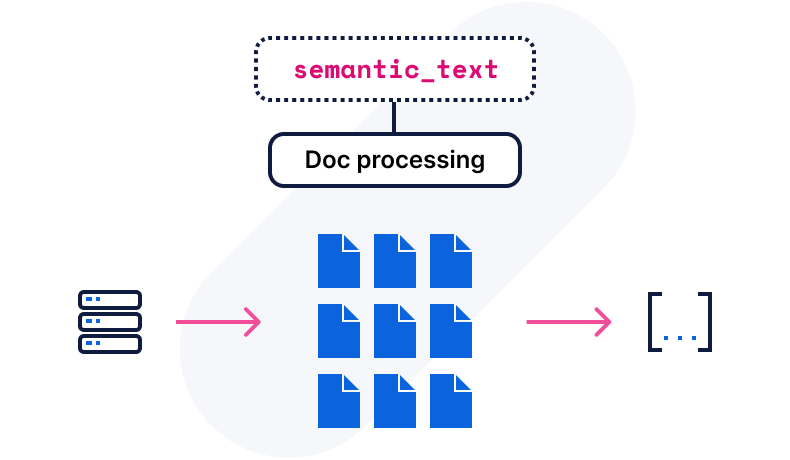
用于优化向量存储的语义文本
部分支持
全面支持(免费)
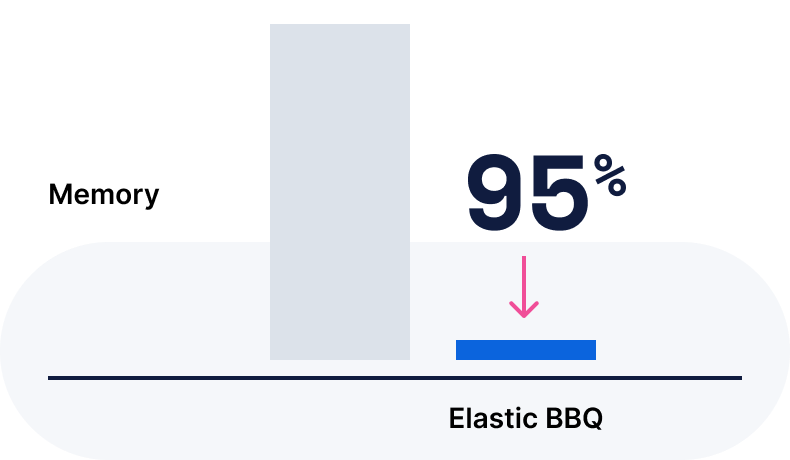
存储嵌入(默认为 int8,可选 float、int4、bit 和 BBQ)
部分支持
全面支持(免费)
生成嵌入
部分支持
全面支持(付费)
搜索嵌入(向量搜索)
全面支持
全面支持(免费)
全文本搜索(BM25)
部分支持
全面支持(免费)
原生混合搜索(BM25 + 向量搜索)
部分支持
全面支持(免费)
筛选、分面搜索、聚合
部分支持
全面支持(免费)
搜索自动完成
部分支持
全面支持(免费)
针对多种数据类型(文本、向量、地理位置等)进行优化
部分支持
全面支持(免费)
跨集群搜索
部分支持
全面支持(免费)
本地部署和隔离式部署
不支持
全面支持(免费)
支持多种嵌入模型类型
部分支持
全面支持(付费)
内置的语义搜索模型
不支持
全面支持(付费)
内置重排序模型和学习如何排序
不支持
全面支持(付费)
管道查询 (ES|QL)
不支持
全面支持(免费)
可观测性工具 (Kibana)
不支持
全面支持(免费)
AI 助手
不支持
全面支持(付费)
Search UI 组件
不支持
全面支持(免费)
常见问题
什么是向量数据库?它是如何运作的?
什么是向量数据库?它是如何运作的?
向量数据库将信息存储为向量,即数据对象的数值表示,也称为向量嵌入。它利用向量嵌入,在海量结构化、非结构化和半结构化数据(如图像、文本、视频和音频)中实现多模态搜索。向量数据库专为管理向量嵌入而构建,因此可提供完整的数据管理解决方案。
什么是向量嵌入?
什么是向量嵌入?
向量嵌入使用机器学习模型将文本转化为数字,让您可以执行向量搜索。通过将数据转换为向量,嵌入可以更容易地比较、搜索和分析空间中项目之间的相似性。
向量数据库有哪些优势?
向量数据库有哪些优势?
向量数据库通过实现本地部署、隔离和主权云环境之间的无缝数据迁移,并为向量嵌入提供存储,从而提供大规模搜索的效率。向量数据库擅长相似性搜索,可以让您轻松找到相关项目,这对于推荐系统、图像搜索和内容发现至关重要。借助语义搜索功能,它们不只停留在关键词的简单匹配上,而是能够根据词语的意义和上下文环境来提供搜索结果。通过存储向量嵌入,它们可以支持人工智能和机器学习应用程序,从而更容易部署 NLP 和推荐模型。对于在受监管或分类环境中的组织(政府、国防和金融服务),Elasticsearch 支持完全本地部署和隔离部署,无需外部连接。
Elasticsearch 是向量数据库吗?
Elasticsearch 是向量数据库吗?
是的,Elasticsearch 是世界上部署最广泛的开源向量数据库,为您提供大规模、高效地创建、存储和搜索向量嵌入的有效方法。借助 Elastic 的企业级向量数据库,即使数据快速变化,您也可以实现快速查询时间和最佳性能。它可根据扩展进行构建,在简化开发流程的同时提供相关的个性化搜索结果。
为什么选择 Elastic 作为您的向量数据库?
为什么选择 Elastic 作为您的向量数据库?
我能否将 Elasticsearch 作为本地部署或隔离向量数据库运行?
我能否将 Elasticsearch 作为本地部署或隔离向量数据库运行?
是的。Elasticsearch 完全可以本地部署在裸机、私有云或没有外部连接的完全隔离网络中。政府机构、国防承包商和受监管企业使用 ECE 来扩展本地部署的 Elasticsearch 集群,包括在保密和断开连接的环境中。Elastic Cloud 上的所有向量搜索、混合搜索和 RAG 功能在本地部署中同样可用。