利用 Elasticsearch 和 Elastic APM 监测应用
什么是应用程序性能监测 (APM)?
我发现,将 APM 与“可观察性”的其他方面(日志和基础架构指标)放在一起讨论会很有帮助。日志、APM 和基础架构指标构成了 可观察性三要素:
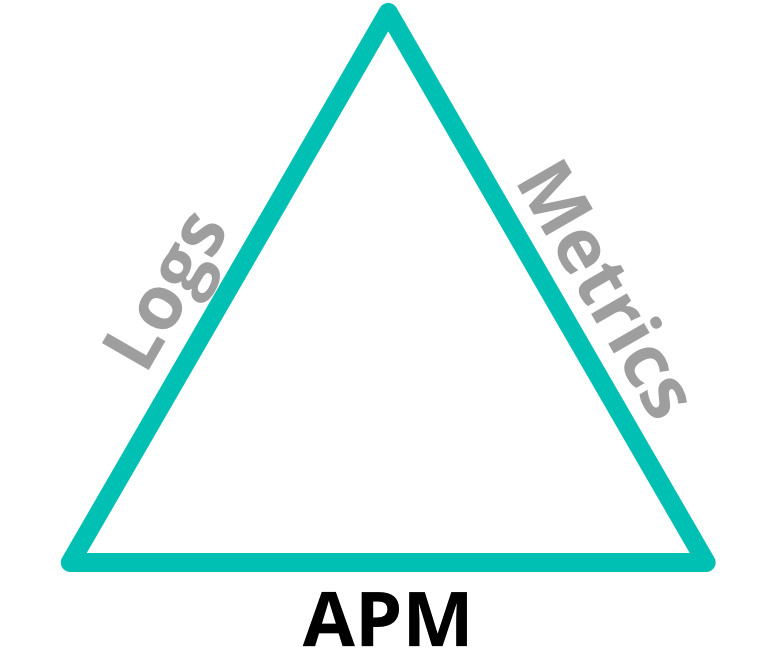
这些领域有重叠 — 刚好足以帮助它们相互关联。日志可能表明发生了错误,但也许没有指明原因。这些指标值可能显示服务上的 CPU 使用率激增,但并没有表明是什么原因导致了这种情况。因此,当我们协同使用它们时,我们可以解决一系列更广泛的问题。
日志
首先,让我们深入研究一些定义。日志和指标之间有着真正微妙的区别。一般来说,日志是当某些事情发生时发出的事件 — 接收并响应请求,打开文件,在代码中遇到 printf。
例如,一种常见的日志格式来自 Apache HTTP 服务器项目(假的,长度有裁剪) :
264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "GET /ESProductDetailView HTTP/1.1" 200 6291 264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "POST /intro.m4v HTTP/1.1" 404 7352 264.242.88.10 - - [22/Jan/2018:16:38:53 -0800] "POST /checkout/addresses/ HTTP/1.1" 500 5253
日志仍然倾向于在组件级别,而不是从整体上看应用程序。日志通常适合人类阅读,这是日志的一个优点。在上面的例子中,我们看到了一个 IP 地址、一个显然没有设置的字段、一个日期、用户正在访问的页面(加上方法)以及几个数字。根据经验,我知道这些数字是响应代码(200 表示良好,404 不如 200, 但比 500 好),以及返回的数据量。
日志很方便,因为它们通常在运行相应应用程序或服务的主机/机器/容器实例上可用,而且正如我们上面看到的,它们在一定程度上适合人类阅读。日志的缺点与它们的本质有关:如果您不编码,它就不会打印出来。您必须明确进行特定操作来获取日志,比如 Ruby 中的 puts 或 Java 中的 system.out.println。即使您这样做,也务必要注意格式问题。上面的 Apache 日志看起来像一种奇怪的日期格式。以“ 01/02/2019”为例。对我来说(在美国),那是 2019 年 1 月 2 日,但是对很多阅读这篇文章的人来说,我打赌会认为是 2 月 1 日。当您设置日志语句格式时,请考虑类似的事情。
指标
另一方面,指标往往是周期性的总结或计数 — 在过去 10 秒内,平均 CPU 为 12%,应用程序使用的内存量为 27MB,或者主磁盘的剩余容量为 71% (至少我的是这样,我刚刚检查过)。
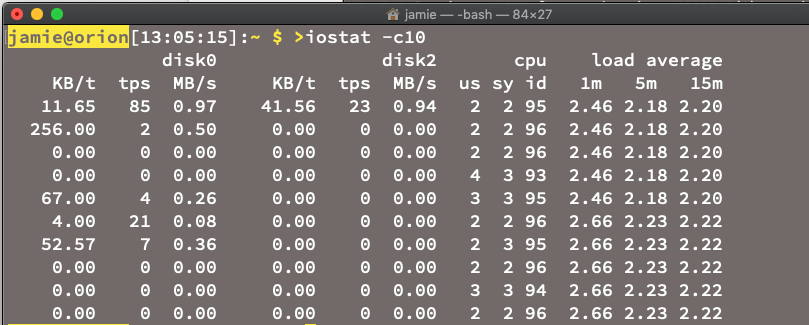
以上是在 Mac 上运行的 iostat 的截图。这里面有很多指标。当想要显示趋势和历史时,指标是很有用的,当试图创建简单、可预测、可靠的规则来捕捉事件和异常时,指标也非常有用。指标的一个问题是,它们倾向于监测基础架构层,获取有关组件实例级别的数据,比如主机、容器和网络,而不是自定义应用程序级别。因为指标标准往往在一段时间内被抽样,所以短暂的异常值会有被“取平均值”的风险。
APM
应用程序性能监测弥合了指标和日志之间的差距。虽然日志和指标往往更具交叉性,涉及基础架构和组件,但 APM 侧重于应用程序,允许 IT 和开发人员监测其堆栈的应用层,包括最终用户体验。
将 APM 添加到您的监测中可以让您:
- 了解您的服务的时间花在什么上,以及它崩溃的原因。
- 了解服务如何相互交互并可视化瓶颈
- 主动发现并修复性能瓶颈和错误
- 希望,在太多客户受到影响之前
- 提高开发团队的生产力
- 在浏览器中跟踪终端用户体验
需要注意的一点是 APM 会“说”代码(稍后我们会看到更多)。
让我们来看一下 APM 与我们从日志中得到的结果的对比。我们有一个日志条目:
264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "GET /ESProductDetailView HTTP/1.1" 200 6291
最初看这个条目时,一切似乎都很好。我们成功地做出了响应 (200),并发回了 6291 字节 — 它没有显示出花费了 16.6 秒,正如这张 APM 截图所示:
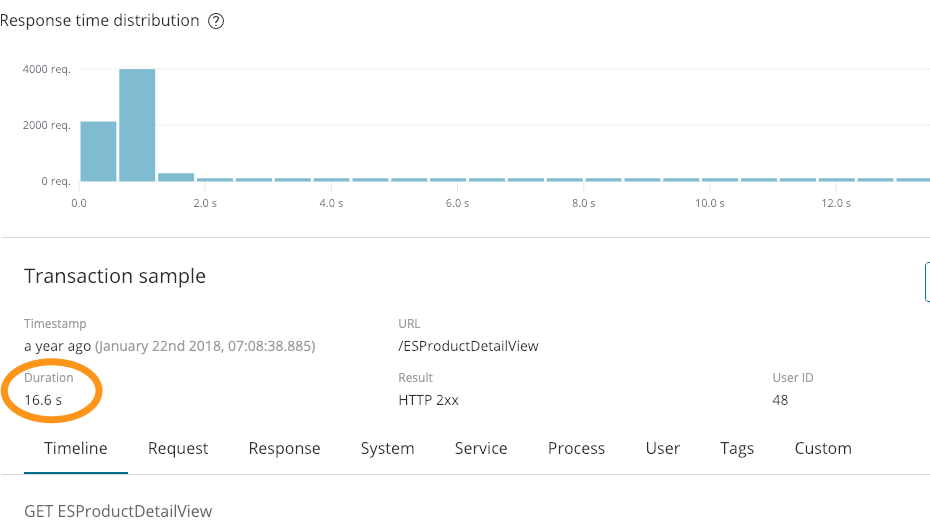
额外的上下文信息非常丰富。我们在上述日志中也有错误:
264.242.88.10 - - [22/Jan/2018:07:08:53 -0800] "POST /checkout/addresses/ HTTP/1.1" 500 5253
APM 还为我们捕获错误:
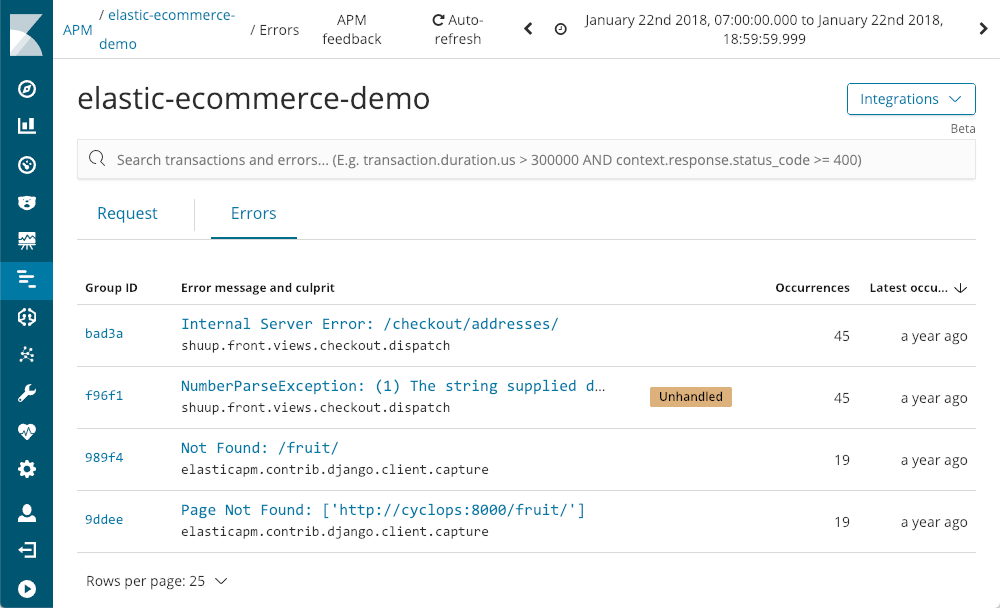
向我们展示了它们上次发生的时间、发生的频率以及它们是否由应用程序处理。当我们深入研究异常时,以 NumberParseException 为例,我们会看到窗口中错误发生次数的分布情况:
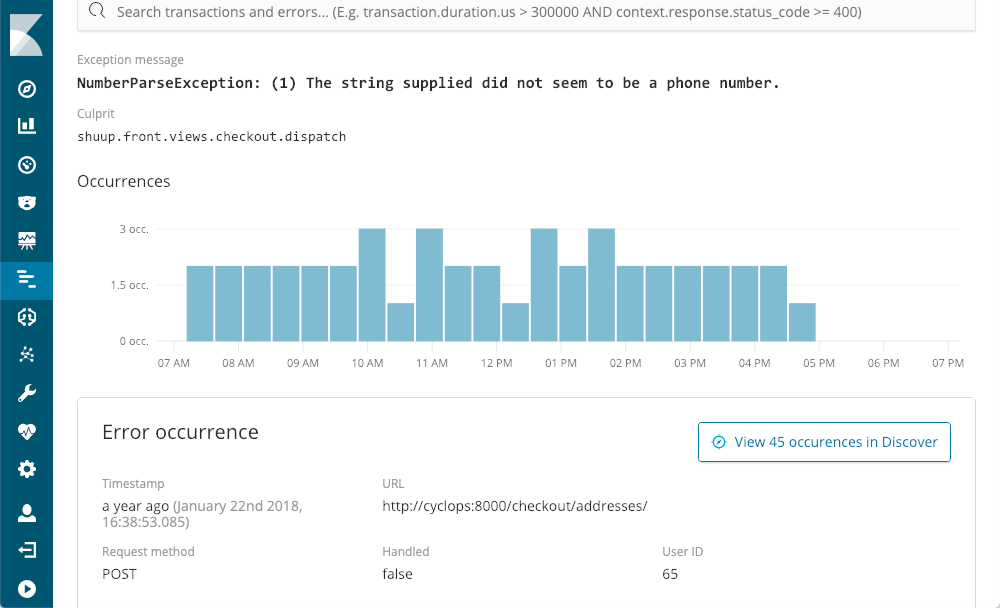
我们可以立即看到,这种情况在每个时间段都发生过几次,但几乎是一整天。我们可能会在其中一个日志文件中找到相应的堆栈跟踪,但很可能它没有使用 APM 时可用的上下文和元数据:
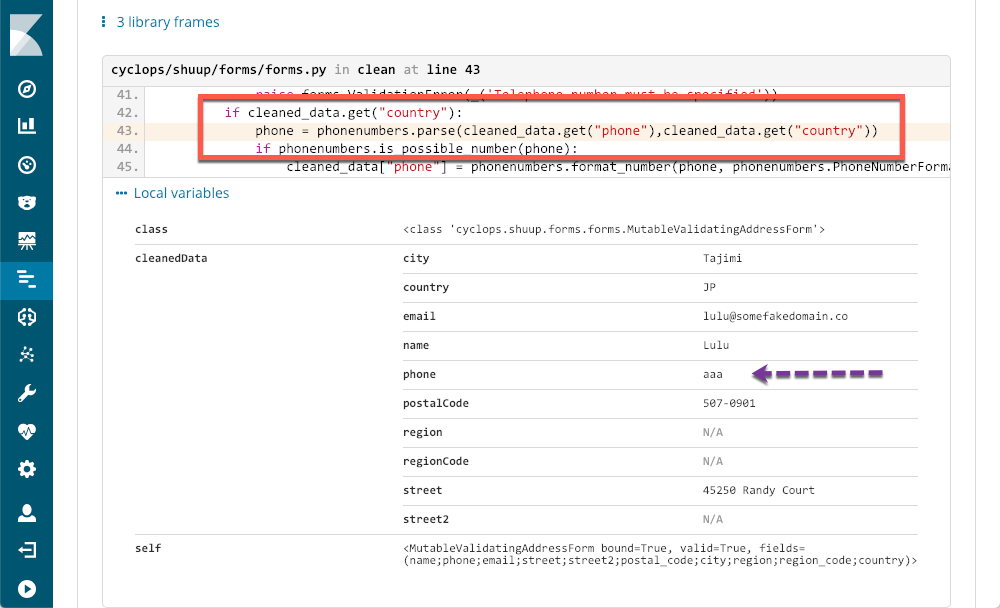
红色矩形显示了导致异常的代码行,APM 提供的元数据准确地显示了问题所在。即使像我这样的非 python 程序员也能准确地看到问题所在,并且有足够的信息打开一个标签。
APM 功能教程(带截图)
我可以整天告诉您 Elastic APM (在 Twitter 上找到我,我会证明这一点),但我猜您更愿意看看它能做什么。我们一起来看看吧。
打开 APM
当我们进入 Kibana 的 APM 应用程序时,我们会看到我们安装了 Elastic APM 的所有服务:
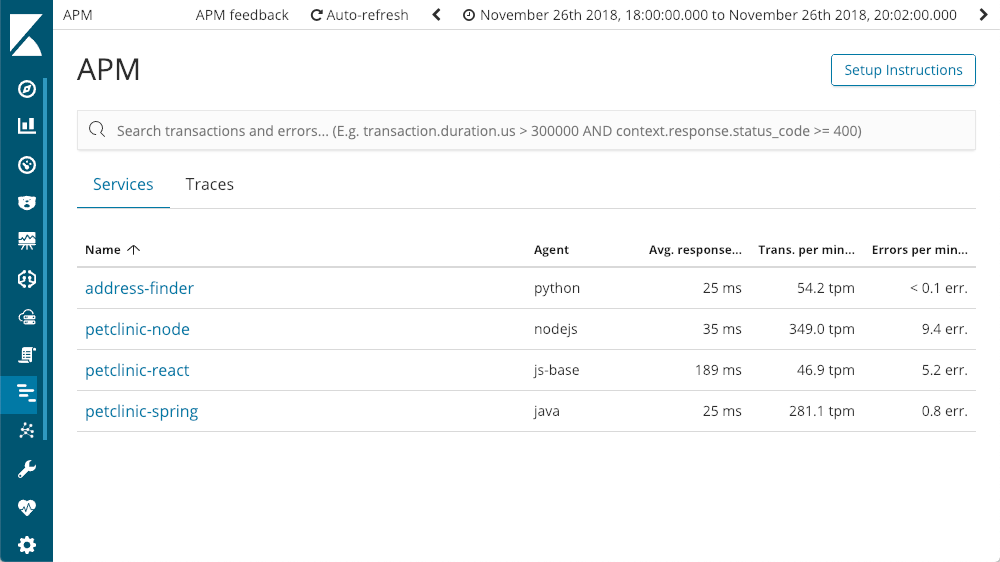
深入研究服务
我们可以深入到个人服务 — 让我们试试“petclinic-spring” 服务。每项服务都将具有类似的布局:
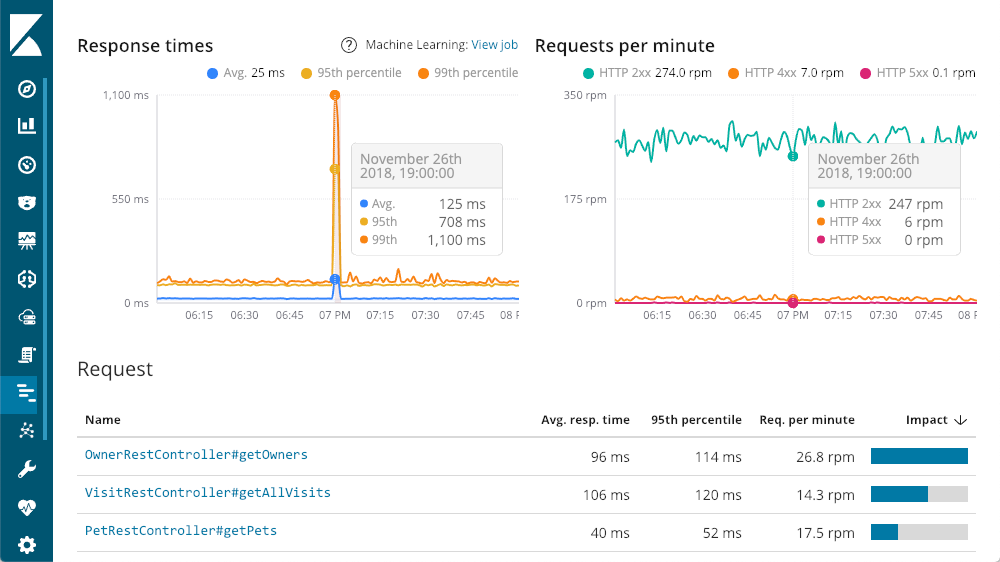
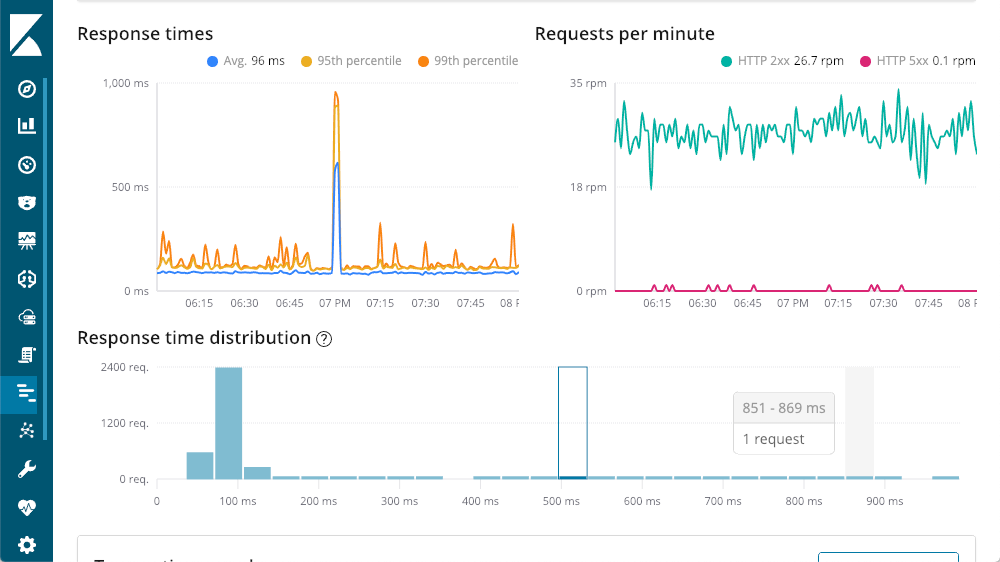
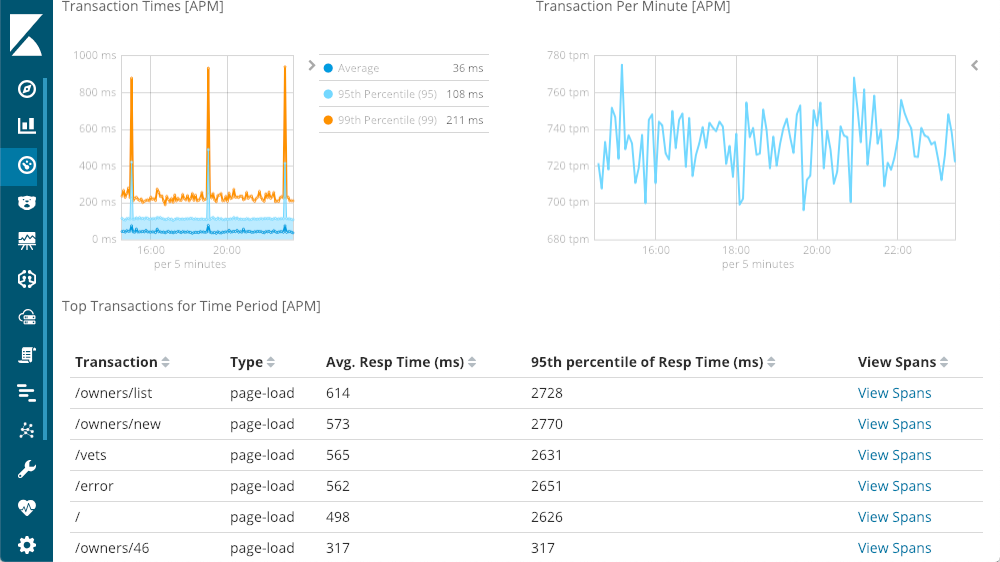
左上角给出了响应时间 — 平均值、95% 和 99%,以显示我的异常值在哪里。我们还可以显示或隐藏各种线条元素,以便更好地了解异常值对整个图表的影响。右上角有我的响应代码 — 这些代码被分解成每分钟的请求数(RPM),而不是时间。正如您在图表中看到的,当您将鼠标移到任何一个图表上时,您会得到一个弹出窗口,显示当时的摘要。在我们开始研究之前,我们就已经有了第一个见解 — 延迟的巨大增长没有任何 500 响应(服务器错误)。
深入了解处理响应时间
继续我们的处理总结之旅,我们到了底部,请求细目。在我们的应用程序中,每个请求基本上都是不同的端点(尽管您可以使用 各种代理 API来扩充默认值)。我可以按列标题排序,但是我个人喜欢 “impact” 列 — 它考虑了给定请求的延迟和受欢迎程度。在这种情况下,我们的 “getOwners” 似乎造成了巨大麻烦,但它的平均延迟仍然相当可观,为 96 毫秒。深入到该处理的细节,我们看到了与前面相同的布局:
Waterfall 操作
但是即使是最慢的请求也不到一秒钟。向下滚动,我们可以看到处理中操作的瀑布视图:
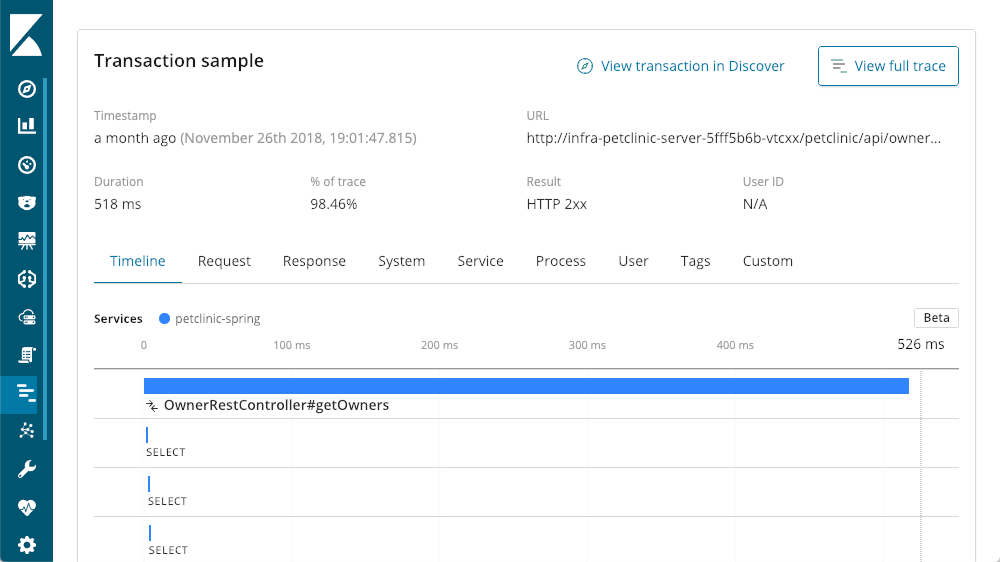
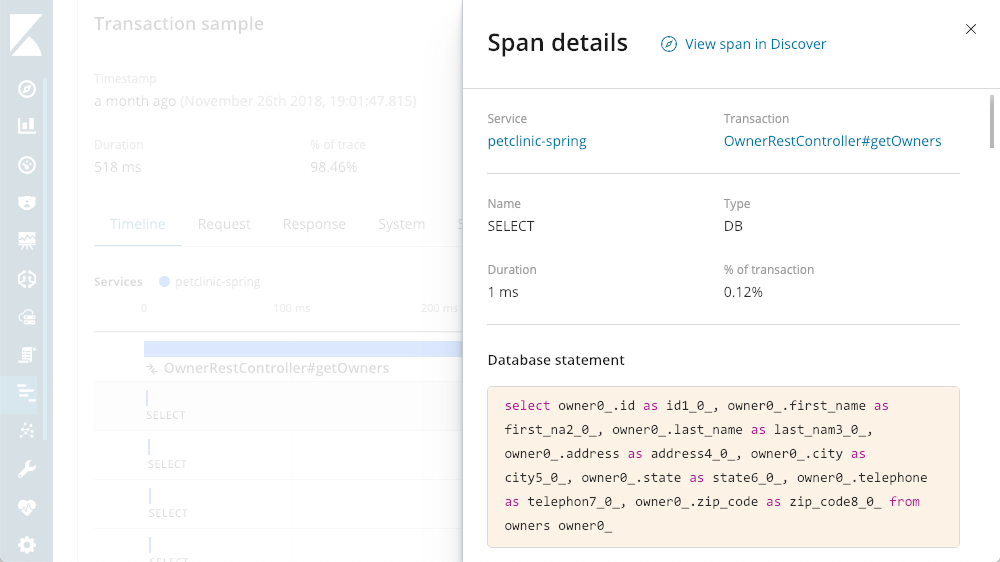
查询详细信息查看器
肯定有很多 SELECT 语句正在进行。使用 APM,我能够看到正在执行的实际查询:
分布式跟踪
我们正在处理这个应用程序堆栈中的多层微服务体系架构。由于我们所有的层都安装了 Elastic APM,我们可以点击“查看完整跟踪”按钮来查看该调用中涉及的所有内容,显示参与处理的所有组件的 分布式跟踪:
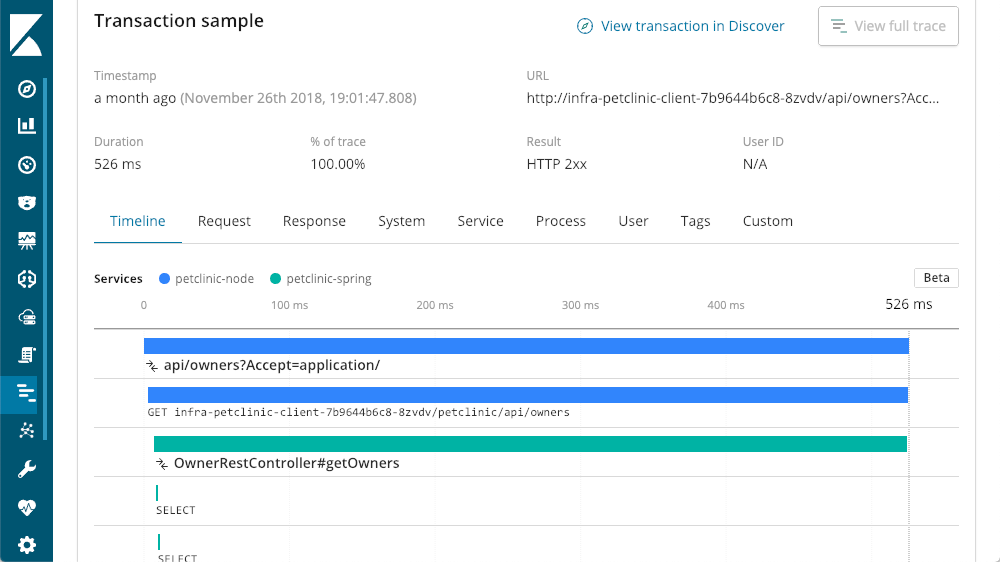
痕迹层
在这种情况下,我们从 Spring 层开始的层是其他层调用的服务。我们现在可以看到“宠物诊所节点”被称为“宠物诊所 spring” 层。这只是两层,但是我们可以看到更多,在这个例子中,我们有一个从浏览器(反应)层开始的请求:
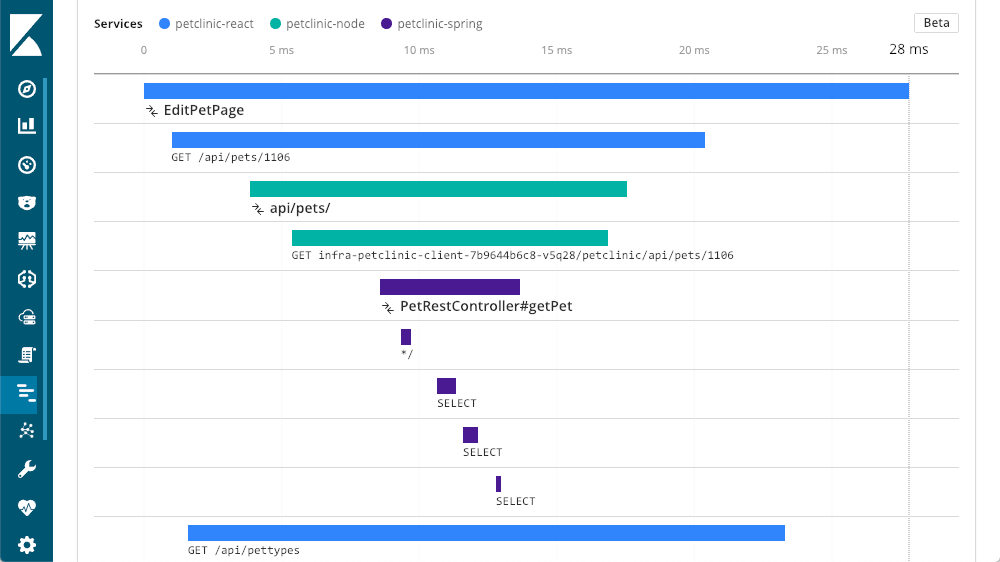
真实用户监测
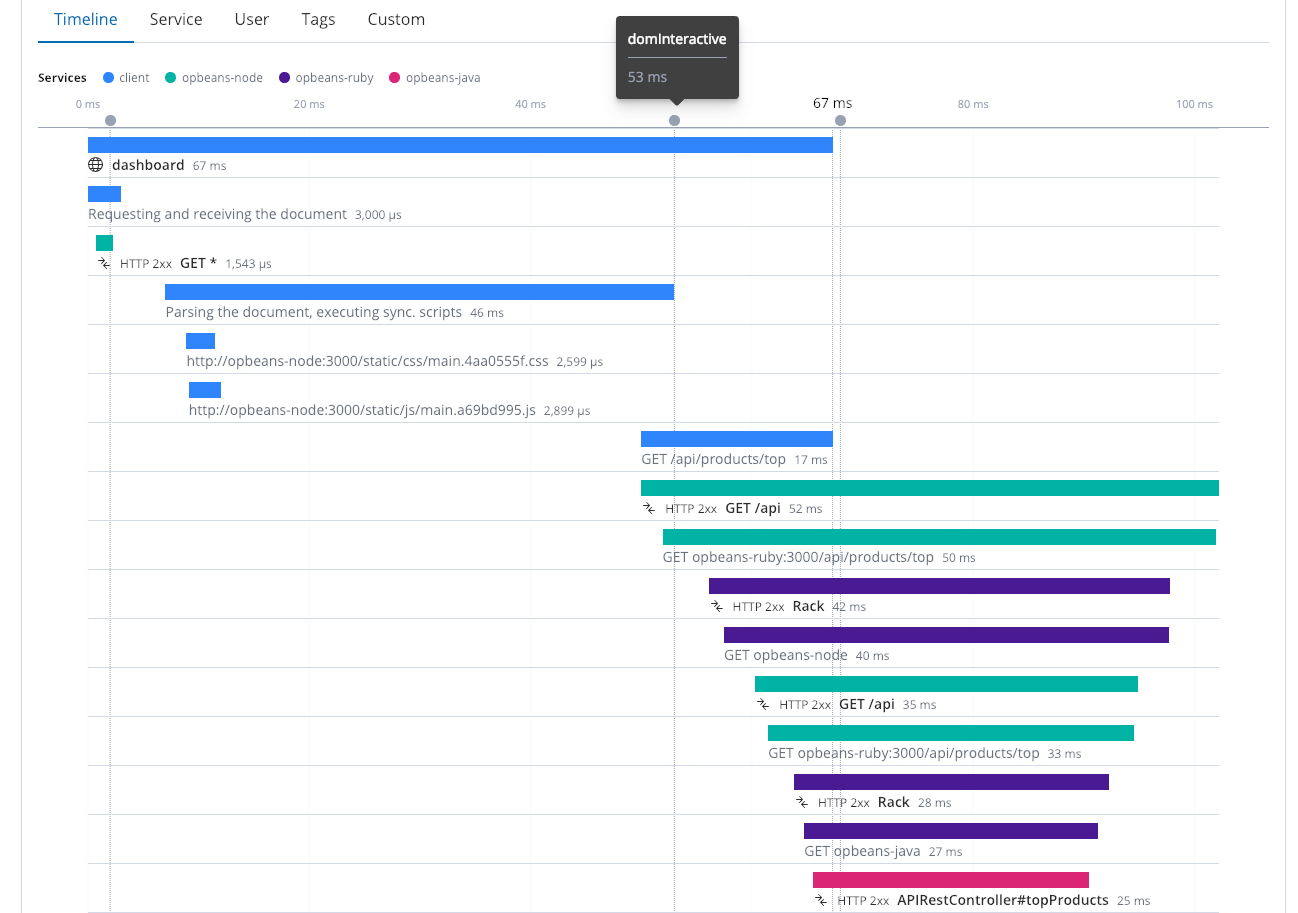
为了从分布式跟踪中获得最大价值,尽可能多地检测您的组件和服务非常重要,包括利用 真实用户监测 (或 RUM)。仅仅因为您有快速的服务响应时间并不意味着事情在浏览器中很快就能完成 — 衡量最终用户在浏览器中的体验是很重要的。这个分布式跟踪显示了四种不同的服务,一同工作。其中包含了网络浏览器(客户端)以及几项服务。在 53 毫秒时,dom 是交互式的,在 67 毫秒时,我们看到 dom 是完整的。
不仅仅是一个漂亮的界面
Elastic APM 不仅仅是面向应用程序开发人员的全包 APM 用户界面,支持它的数据也不仅仅是为该用户界面服务。事实上,Elastic APM 数据最好的地方之一就是它只是另一个索引。信息就在那里,还有您的日志、指标、甚至您的业务数据,让您看到服务器减速如何影响您的收入,或者利用 APM 数据来帮助您计划下一轮代码增强(提示:看看影响最大的请求)。
APM 附带默认的可视化和仪表板,允许我们将它们与日志、指标甚至我们的业务数据中的可视化进行混合和匹配。
开始使用 Elastic APM
Elastic APM 可以与 Logstash 和 Beats 一起运行,具有类似的部署拓扑:
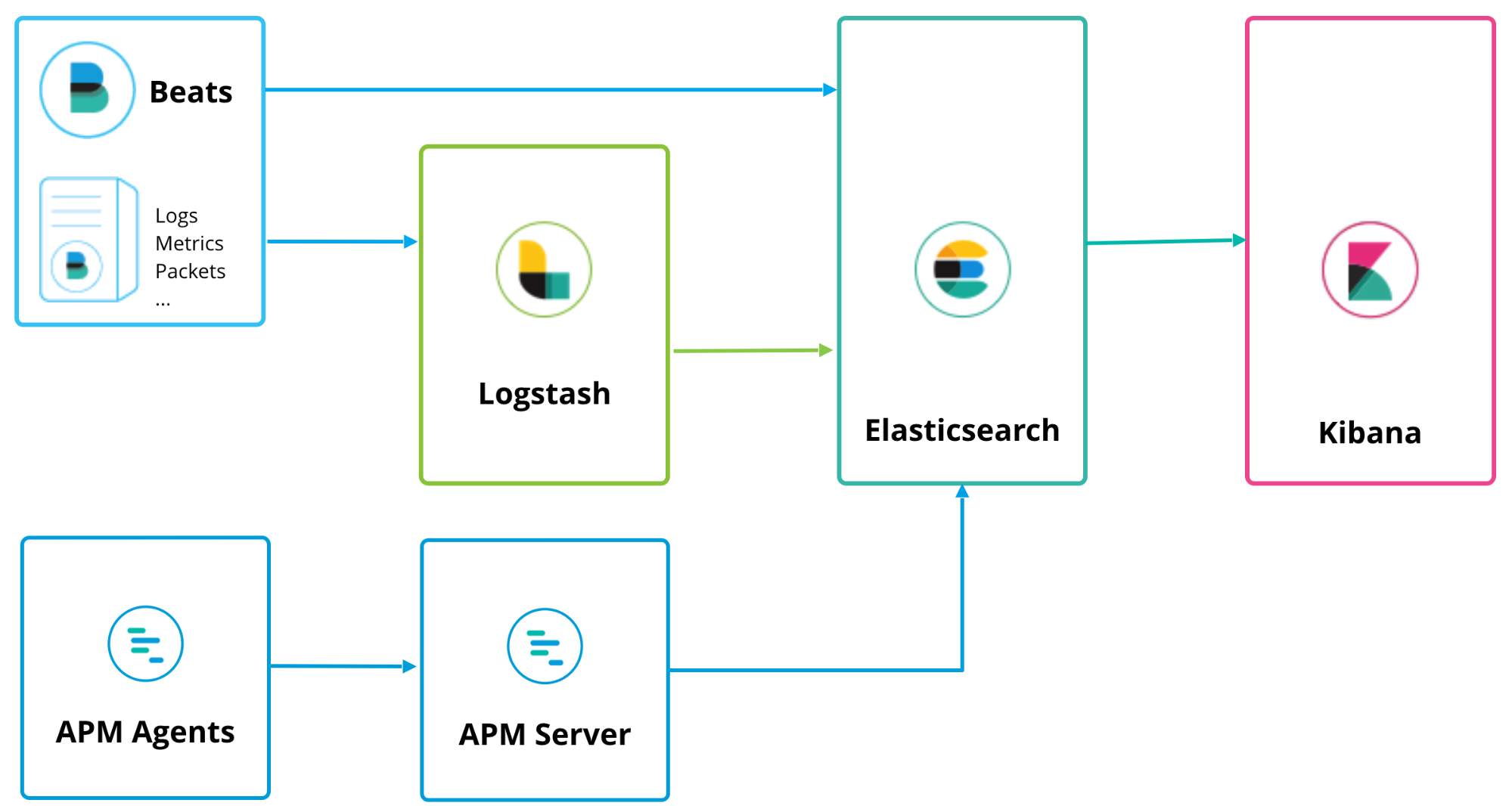
APM 服务器充当数据处理器,将 APM 数据从 APM 代理 转发到 Elasticsearch。安装非常简单,可以在文档的 “安装和运行” 页面上找到,或者您可以简单地点击 Kibana 中的 “K” 标志,进入 Kibana 主屏幕,在那里您会看到一个选项“添加 APM”:
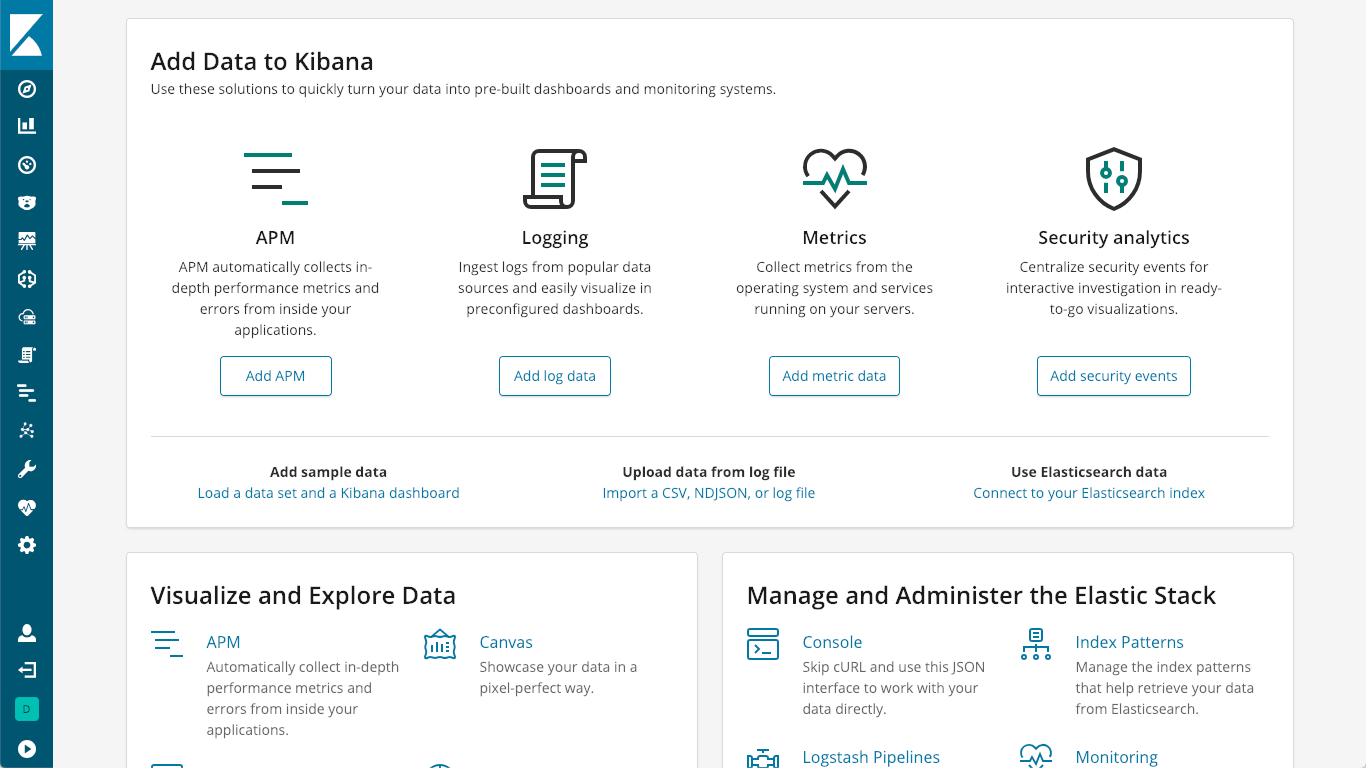
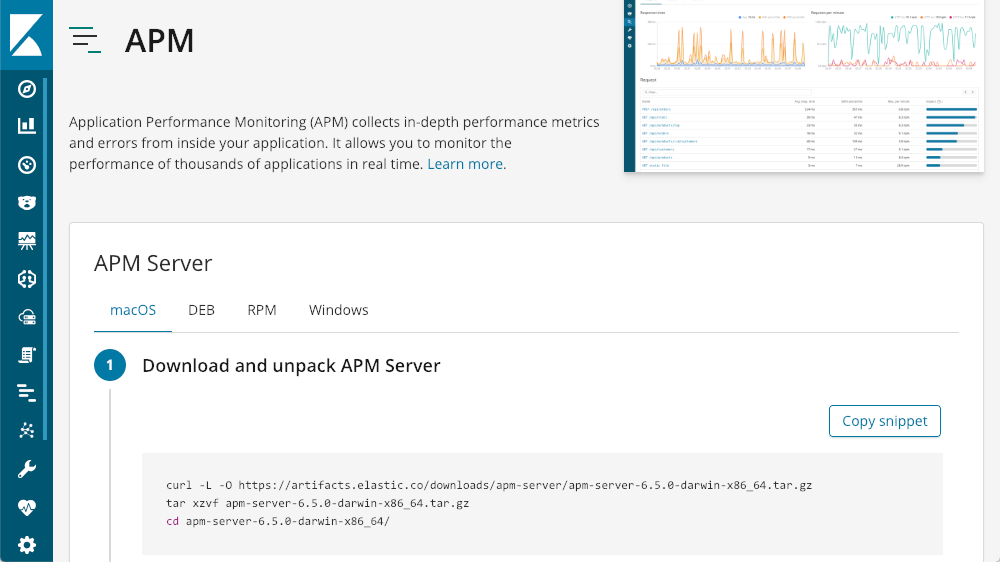
然后,它会引导您启动并运行 APM 服务器:
一旦您启动并运行起来,Kibana 内置了针对每种代理类型的教程:
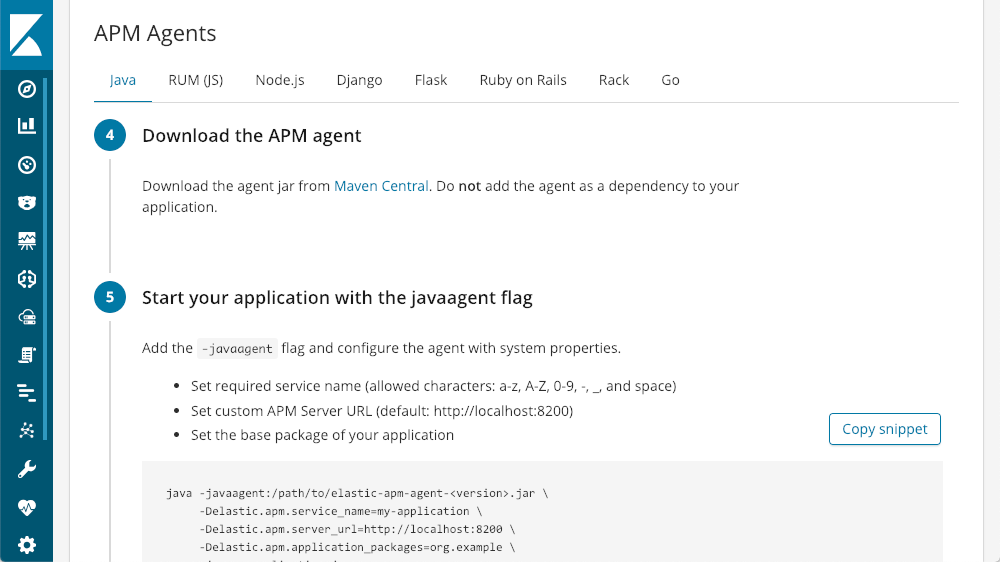
您只需要几行代码就可以启动并运行。
以 Elastic APM 为例
没有什么方法比亲自动手来学习新东西更好了,我们有几种不同的方法供参考。如果您想亲眼看到界面,您可以点击我们的 APM 演示环境。如果您更愿意在本地运行,您可以按照 APM 服务器下载页面上的步骤操作。
最短的路径是通过Elastic Cloud上的Elasticsearch 服务,我们的 SaaS 产品可以让您在几分钟内启动并运行整个 Elasticsearch 部署,包括 APM 服务器(比如 6.6)、Kibana 实例和 Machine Learning 节点(还有一个 为期两周的免费试用)。最好的部分是我们为您维护您的部署基础架构。
在 Elasticsearch 服务上启用 APM
要使用 APM 创建集群(或将 APM 添加到现有集群),只需向下滚动到集群上的 APM 配置部分,单击“启用”,然后“保存更改”(更新现有部署时)或“创建部署”(创建新部署时)。
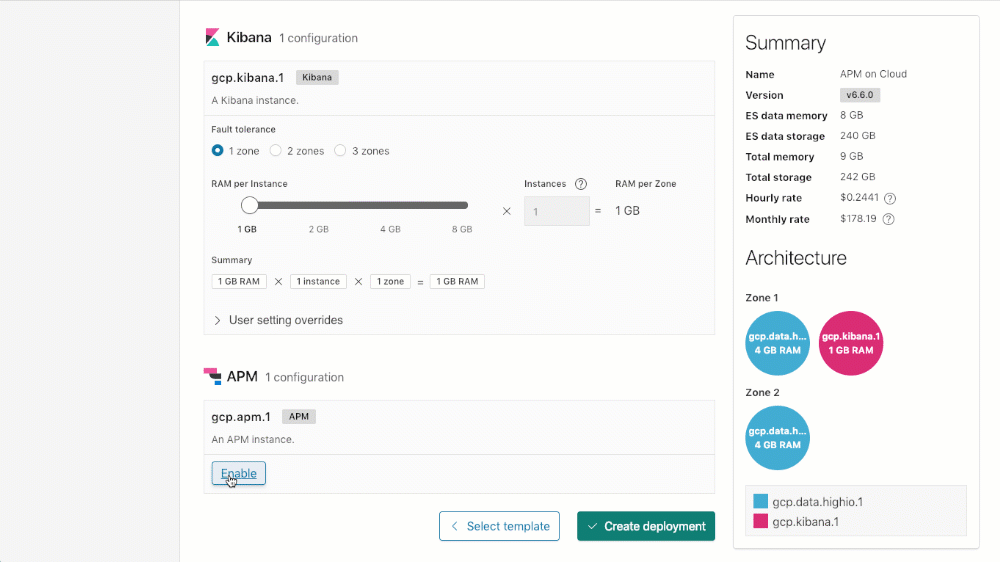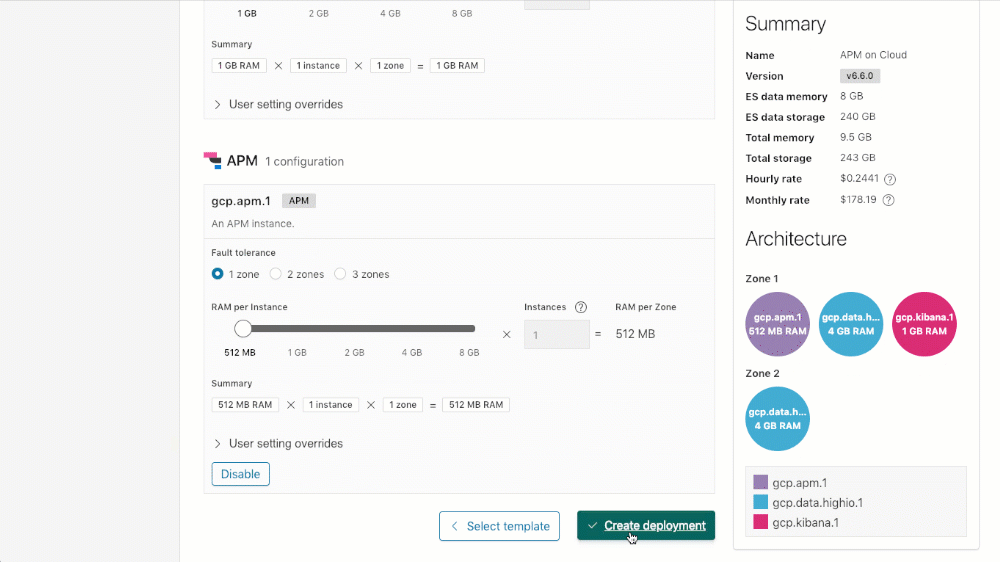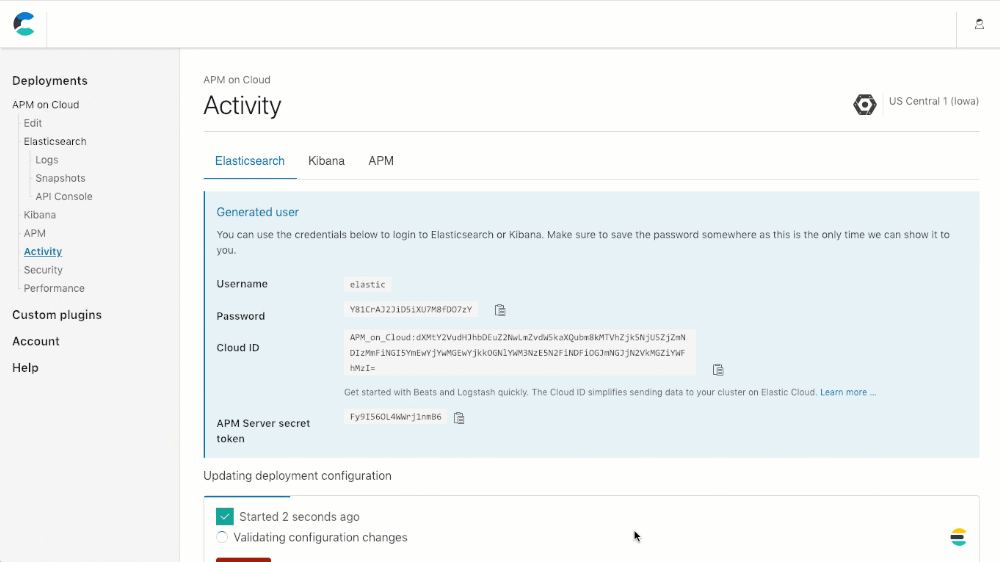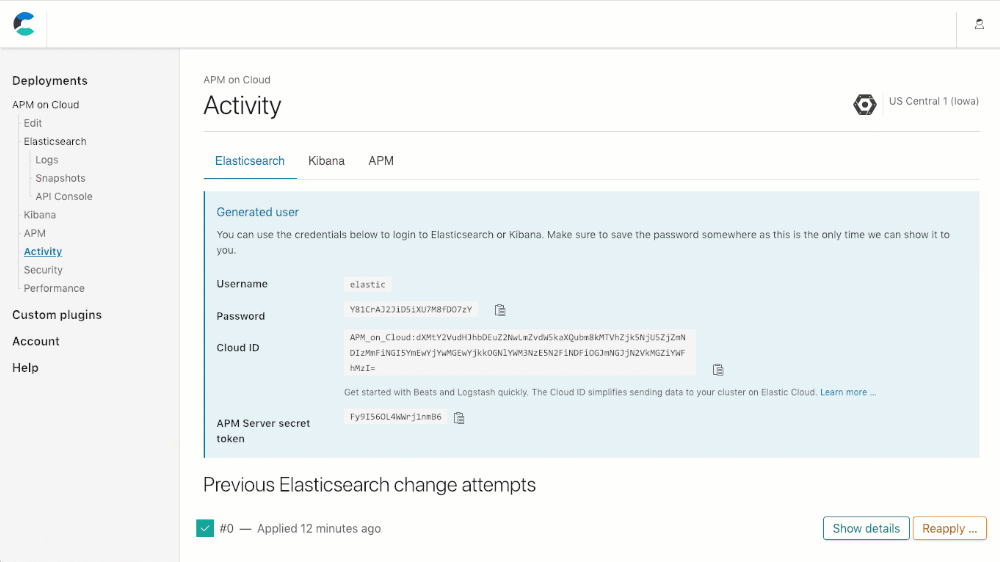
许可证
Elastic APM服务器 和所有的APM 代理 都是开源的,并且精确的 APM UI 包含在免费基本许可证下的 Elastic Stack 的默认分发中。我们前面提到的集成(警报和 Machine Learning )与基本功能的基础许可证相关,因此黄金用于警报,白金用于 Machine Learning 。
摘要
APM 让我们了解我们的应用程序在所有层上的运行情况。通过与 Machine Learning 和警报的集成,结合搜索能力,Elastic APM 为您的应用程序基础架构增加了另一层可见性。我们可以使用它来可视化处理、跟踪、错误和异常,所有这些都来自于精心策划的 APM 用户界面。即使我们没有问题,我们也可以利用来自 Elastic APM 的数据来帮助确定修复的优先级,从我们的应用程序中获得最佳性能,并克服瓶颈。
如果您想了解更多关于 Elastic APM 和可观察性的信息,请查看我们过去的一些网络研讨会:
- 使用 Elastic APM 的仪器和监测 Java 应用程序
- 使用 Elastic Stack 进行应用程序性能监测
- 使用 Elasticsearch、Beats 和 Elastic APM 来监测 OpenShift 数据
- 统一 APM、Logs 和 Metrics 以提高操作可视性
- 跟踪 Elastic Stack (ELK Stack) 中的基础架构 Logs 和 Metrics
今天就试试吧! 在我们的 讨论论坛 上点击 APM 主题,或者在我们的 APM GitHub repos 上提交标签或功能请求。