借助 Elastic Stack 实现可观察性
作为 Elastic 可观察性的产品主管,当我使用“可观察性”这个术语时,我会收到一些不同的反应。迄今为止,最常见的反应仍然是:“什么是‘可观察性’?” 但我也越来越多地听到这样的话:“我们刚刚启动了一个‘可观察性计划’,但仍在思考具体的实施方法。” 最后,我们有幸与之合作的一些组织已经将“可观察性”视为他们设计和构建产品和服务的一个组成部分。
目前,这一术语的热度还在不断提升。在这个时候,如果能够阐明 Elastic 对“可观察性”的看法,分享我们从具有创新思维的客户那里学到的经验,并说明我们在为运营用例开发堆栈时如何从产品角度看待这一概念,我想将会非常有帮助。
什么是“可观察性”?
当然,“可观察性”这个术语并不是我们发明的。我们最开始从用户那里听到这个概念,这些用户主要来自网站可靠性工程 (SRE) 社区。有些信息来源认为,这个术语起源于硅谷巨头(如 Twitter)建立的 SRE 组织。尽管开创性的 Google SRE Book 没有提到这个术语,但它列出了当今许多与“可观察性”相关的原则。
“可观察性”不是供应商能够在系统之外单独交付的功能,而是您在构建系统时植根于其中的一个属性,就像易用性、高可用性和稳定性一样。设计和构建“可观察”系统的目标在于,确保当它在生产中运行时,负责操作它的人员能够检测到不良行为(例如,服务停机、错误、响应缓慢),并拥有可操作的信息以有效地确定根本原因(例如,详细的事件日志、细粒度的资源使用信息,以及应用程序跟踪)。这个目标看似平淡无奇,但组织在实现这一目标时会遇到诸多挑战,常见挑战包括:没有收集足够的信息;收集了太多信息,但没有提取出有指导意义的内容;这些信息分别存储在诸多不同的位置。
第一个方面是检测不良行为,这通常从设置服务级别指标 (SLI) 和服务级别目标 (SLO) 开始。 这些是衡量成功的内部标准,重视可观察性的组织可通过这些标准来评判生产系统。如果有合同义务来实现这些目标,SLI/SLO 也可以转化为服务级别协议 (SLA)。SLI 最常见的例子是系统正常运行时间,您可以为此设置 99.9999% 的 SLO。系统正常运行时间也是外部客户最常见的服务级别协议。然而,您的 SLI/SLO 内部可能更加精细,对生产系统行为的这些最重要因素的监测和警报是任何可观察性计划的基础。这方面的可观测性也被称为“监测”。
第二个方面 - 为操作员提供精确的信息,以便快速有效地调试生产问题 - 这是一个我们发现有大量发展和创新的领域。关于“可观察性的三大支柱” - 指标、日志和应用程序跟踪 - 网上有很多讨论。人们还认识到,简单地使用拼凑的工具收集所有这些粒度数据不一定是可行的,而且往往不具有成本效益。
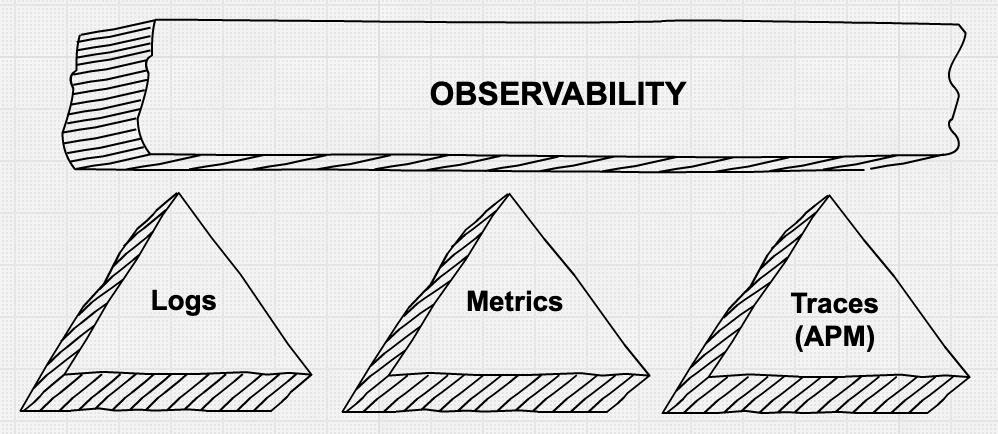
可观察性的支柱
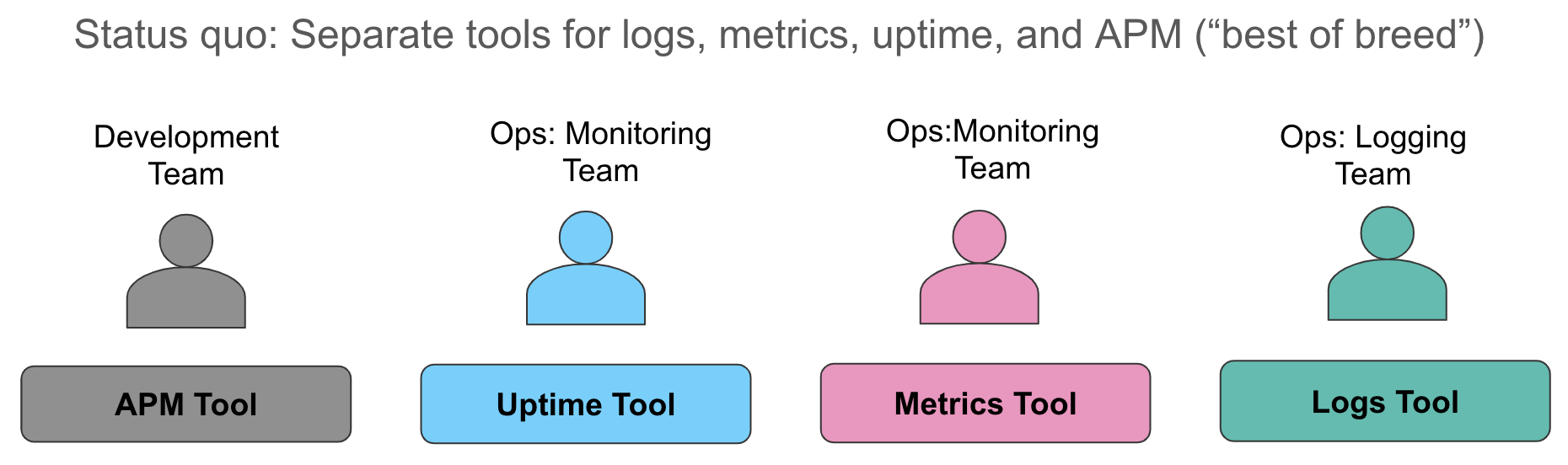
让我们更详细地检查这些数据收集方面。我们今天通常遇到的现状是将指标收集到一个系统中(通常是到时间序列数据库或用于资源监控的 SaaS 服务),将日志收集到第二个系统中(不出所料,在我们的对话中通常是 ELK Stack),并使用第三个工具来测量应用程序以提供请求级别跟踪。当警报响起,表明服务级别出现漏洞时,操作员会疯狂地奔向他们的系统,执行他们最大能力执行最佳的“转椅集成” - 在一个浏览器窗口中查看指标,手动将其与另一个窗口中的日志关联,并在第三个窗口中调出跟踪(如果相关的话)。
这种方法有几个缺点。首先,在服务慢速或中断期间,不同数据源之间的手动关联会浪费宝贵的时间。其次,维护三个不同的运营数据存储的运营成本很高 - 许可成本、不同运营工具管理员的独立人数、每个数据存储中不一致的机器学习能力、思考不同警报语义所需的“空间” - 我谈话过的每个组织都在努力应对所有这些挑战。
越来越多的人认识到,将所有这些信息保存在一个可操作的库中,并能够在直观的用户界面中自动关联这些数据是多么重要。对于我们交谈的用户来说,Nirvana 是以统一的方式向他们的操作员展示与他们所支持的服务相关的每一条数据,无论是应用程序发出的日志行、由检测产生的跟踪数据,还是由时间序列中的指标表示的资源利用率。从搜索和过滤到聚合,再到可视化,我们听到的需求强调了对这些数据的统一、特别的访问,而不管其来源是什么。从指标开始,在不切换背景的情况下,只需点击几下鼠标就可以深入日志和跟踪,从而加快调查速度。类似地,从结构化日志中提取数值看起来令人惊讶地像指标,并且从操作角度来看,并行可视化两者具有巨大的价值。
如前所述,简单地收集数据可能会导致磁盘上有太多信息,而在事件发生时没有足够的有行动价值的情报。人们越来越期望收集操作数据的系统能够自动检测时间序列模式中的“有趣”事件、轨迹和异常。这有助于操作员更快地从根本上调查问题。这些异常检测能力有时被称为“可观察性的第四个支柱”。在多个正常运行时间数据、资源利用率、日志模式中的异常以及大多数相关跟踪来检测异常是一个由可观察性团队提出的新兴的需求。
可观察性...那 ELK Stack 呢?
那么,可观察性与 Elastic Stack(或在操作圈里被亲切地称为ELK Stack)有什么关系?
ELK Stack 是众所周知的从操作系统集中日志的实用方法。假设 Elasticsearch(一个“搜索引擎”)是一个放置基于文本的日志进行自由文本搜索的好地方。事实上,简单地在基于文本的日志中搜索“错误”一词或者基于一组众所周知的标签过滤日志是非常强大的,并且通常是大多数用户的出发点。
然而,正如大多数 ELK Stack 用户所知,Elasticsearch 作为一种数据存储途径提供的不仅仅是高效全文搜索和简单过滤能力的倒排索引。它还包含一个针对密集数字时间序列的存储和操作而优化的柱状存储。该列存储用于存储从解析的日志中提取的结构数据,包括字符串和数字。事实上,将日志转换为指标标准的用例是最初促使我们优化 Elasticsearch,以实现数字的高效存储和检索的动力。
随着时间的推移,用户开始将数字时间序列直接放入 Elasticsearch ,取代传统的时间序列数据库。在这种需求的驱动下,Elastic 最近引入了Metricbeat,用于指标的自动收集、自动汇总的概念以及数据存储和用户界面中其他特定于指标的功能。因此,越来越多的用户将 ELK Stack 用于日志,也开始将指标数据(如资源利用率)放入 Elastic Stack。除了上面已经提到的能省去的操作之外,一个有吸引力的原因是 Elasticsearch 对符合数字聚合条件的字段基数没有限制(在讨论许多现有的时间序列数据库时,大家多有抱怨)。
与指标类似,正常运行时间数据与日志一起是一种非常有价值的数据类型,代表了来自活动监视器的 SLO/SLI 警报的重要来源。正常运行时间数据可以提供关于服务、应用程序接口和网站慢速的信息,而且通常是在用户感受到影响之前提供。好处是,就存储需求而言,正常运行时间数据很小,因此很有价值,而额外成本很少。
在过去的一年中,Elastic 还引入了Elastic APM,将应用程序跟踪和分布式跟踪功能添加到堆栈中。这对我们来说是一个自然的演变,因为几个开源项目和著名的 APM 供应商已经在使用 Elasticsearch 来存储和搜索跟踪数据。传统 APM 工具的现状是将 APM 跟踪数据与日志和指标分开,使运营数据孤岛永久化。Elastic APM 提供了一组代理,用于从支持的语言和框架中收集跟踪数据以及支持 OpenTracing,并且该跟踪数据自动与指标和日志相关联。
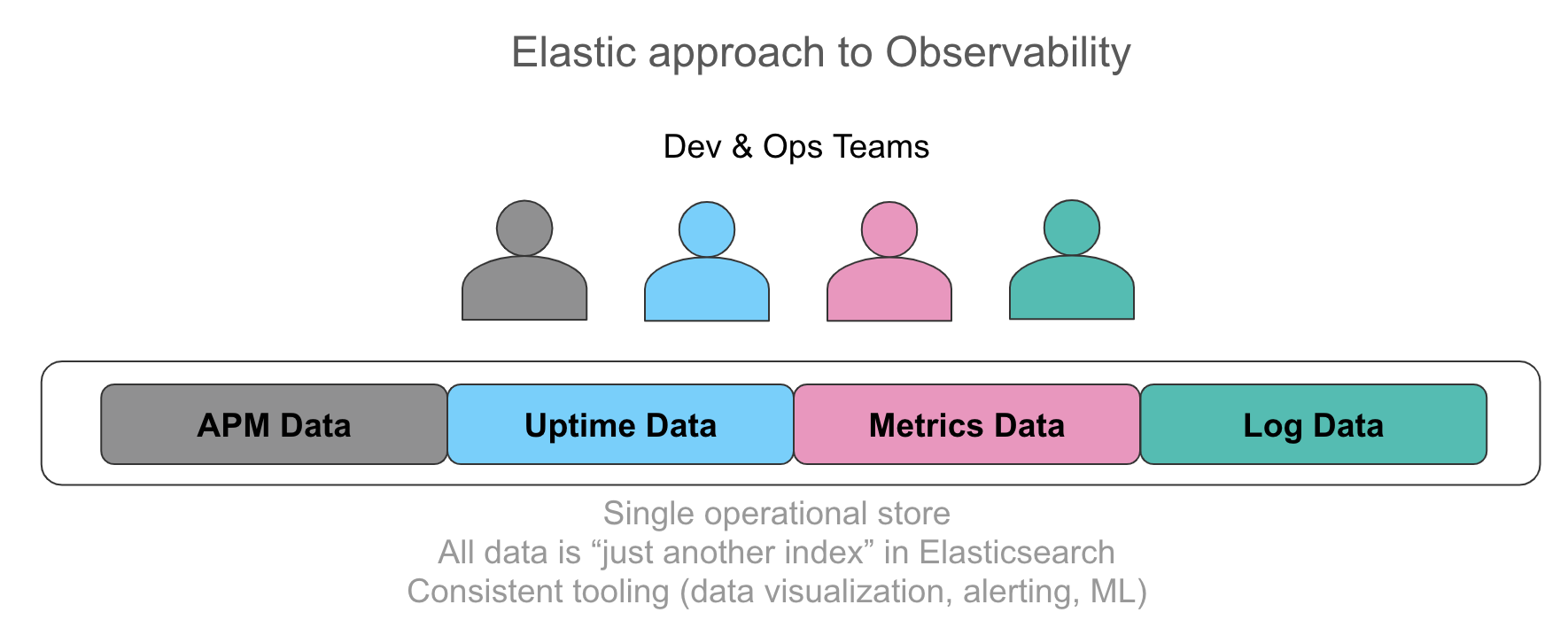
所有这些数据输入的一个共同点是,它们都只是 Elasticsearch 中的另一个索引。对您在所有这些数据数据上运行的聚合、您在 Kibana 中如何可视化数据以及警报和机器学习如何应用于每个数据源这些方面都没有任何限制。若要观看,请观看此视频。
可观察的 Kubernetes 和 Elastic Stack
在观察性概念非常活跃的社区的用户采用 Kubernetes 进行容器编排。这些“云原生”用户(由云原生计算基金会(简称 CNCF) 推广的术语)面临着特殊的挑战。他们面临着应用程序和服务的大规模集中化现状,这些应用程序和服务是建立在 Kubernetes 支持的容器编排平台上或迁移到 Kubernetes 支持的容器编排平台上,再加上将单块应用程序拆分成“微服务”的趋势。以前用来提供对运行在该基础架构之上的应用程序的必要可见性的工具和方法已经失效。
Kubernetes 可观测性值得单独写一篇博客文章,因此现在我将向您推荐可观测 Kubernetes 网络研讨会和Elastic APM 分布式跟踪博客,欢迎您前往了解更多信息。
下一步是什么?
在这样的帖子中,留给读者一些资源去探索似乎较为合适。
要了解更多关于可观察性最佳实践的信息,我建议您从上面提到的 Google SRE Book 开始。那些靠生产中关键应用的完美运行为生的公司的博客帖子通常也引发我们深度思考。例如,我发现最近 Salesforce 工程发布的这篇文章是一个实用的指南,可以反复改善可观察性的状态。
要为您的可观察性计划尝试 Elastic Stack 功能,请在 Elastic Cloud 上的 Elasticsearch 服务上升级我们的堆栈的最新版本(即使您最终部署了自我管理的沙箱),或者下载和在本地安装的 Elastic Stack 组件。请务必查看 Kibana 的新日志、基础架构监控、APM 和正常运行时间(即将在 6.7 版中推出)UI,这些日志专为常见的可观察性工作流而构建。欢迎您随时在讨论论坛上向我们提问,我们随时提供帮助!