Kubernetes 可观测性教程:日志监测和分析
作为逐渐崭露头角的事实标准容器编排技术,Kubernetes 已然成为了云端原生活动中不可或缺的一种技术手段。 云端原生虽为软件开发赋予了速度、弹性和敏捷性,但也增加了复杂性(在成千上万或数百万个容器上有成百上千的微服务,运行于暂时和一次性的 pod)。监测如此复杂的分布式瞬态系统注定会困难重重,但重要性却不容忽视。幸运的是,Elastic 可以轻松化解这种难题,为 Kubernetes 环境赋予可观测性。
在本次 Kubernetes 可观测性教程系列中,我们将深度剖析如何对 Kubernetes 中运行的应用程序进行全方位监测,包括:
- 采集和分析日志
- 收集性能和健康指标
- 使用 Elastic APM 监测应用程序性能
在本次教程的结尾,您将拥有一个应用程序的工作示例,该应用程序会将其所有可观测性数据传输到用于监测和分析的 Elastic Stack。
为何选择 Elastic 可观测性用于 Kubernetes?
可观测性依赖三大“支柱性”数据块:日志、指标以及应用程序性能监测(简称为 APM)。阐述如何将不同工具和供应商拼凑在一起来打造 Kubernetes 监测“最佳组装产品”的文章数不胜数,不过这种集合了 3-6 种不同工具、供应商和技术的“非常规拼凑品”……
恐怕有点令人望而却步。Elastic 可观测性使用一种工具,即可将日志、指标和 APM 数据结合在一起,实现统一的可见性和分析。根据 APM 数据中面向用户的延迟异常(由 Machine Learning 检测)开始进行故障排除,切换到特定 Kubernetes pod 指标,查看该 pod 生成的日志、并将其与描述主机和网络上发生事件的指标和日志相关联,所有这些操作均可在同一用户界面完成。这种方式才是实现可观测性的正确解决之道!
虽然用户体验因此而变得更加便捷容易,但后台中却涉及到大量繁琐的工作,原因在于……
Kubernetes 日志目标并不固定
Kubernetes 通过向可用主机中部署容器执行编排。因此,这种方式自然会令应用程序组件分布到不同主机,根本无法事先获悉组件的目标位置。
Kubernetes pod 内运行的容器会生成日志(以 stdout 或 stderr)。作为以 pod id 命名的文件,这些日志被写到 kubelet 已知的位置。为了将日志与生成日志的组件或 pod 相关联,用户需要找到在当前主机中运行的组件 pod 及其 id 分别为何。
而令情况更加复杂的一点是,Kubernetes 可能会决定扩大或缩小应用程序,结果可能导致代表应用程序组件的 pod 计数产生变化。
Filebeat 恰好是非固定式目标的完美捕手
要收集 pod 日志,我们只需要将 Filebeat 作为 DaemonSet,在 Kubernetes 集群中运行即可。Filebeat 可以配置为与本地 kubelet API 通信,获取在当前主机运行的 pod 列表,并收集这些 pod 生成的日志。利用所有相关 Kubernetes 元数据(例如 pod id、容器名、容器标签和注释等多种信息)对这些日志进行注释。
Filebeat 会使用这些注释来发现哪些组件正在 pod 中运行,然后可以决定对其正在处理的日志应用哪种日志记录模块。完全无需手动操作!使用 Filebeat 采集 Kubernetes 日志轻而易举。我们即将进入正题,但在开始前,请快速了解一项十分重要的说明:
| 开始前:以下教程需要对 Kubernetes 环境进行设置。我们已经编写一篇补充博文,指导您设置单节点 Minikube 环境和演示应用程序的流程,从而运行其余活动。 |
使用 Filebeat 采集 Kubernetes 日志
我们将在 Elastic Cloud 上使用 Elasticsearch Service。但此处所描述的所有操作都可在您自己的基础架构上部署的 Elastic 集群上使用,不管是自我管型,还是使用编排系统,例如 Elastic Cloud Enterprise (ECE) 或 Elastic Cloud on Kubernetes (ECK)。可于以下 GitHub 存储库中找到本次教程的代码:http://github.com/michaelhyatt/k8s-o11y-workshop
将 Filebeat 作为 DaemonSet 进行部署
根据 Kubernetes 主机,应该仅部署 Filebeat 的一个实例。部署后,Filebeat 会通过 kubelet API 与主机通信,从而检索有关运行 pod、所有元数据注释以及日志文件位置的信息。
DaemonSet 的部署配置定义,请参见文件 $HOME/k8s-o11y-workshop/filebeat/filebeat.yml。 让我们来进一步了解代表 Filebeat 配置的部署描述符部分。
该部分将可能的字段总数从默认的 1000 提高到了 5000。Kubernetes 部署会引入大量的标签和注释,导致模式字段的数量可能超过默认的 1000。
setup.template.settings:
index.mapping.total_fields.limit:5000
自动发现机制的设置会指示 Filebeat 使用 Kubernetes 自动发现,并依靠基于提示的自动发现,在注释上发挥作用。
filebeat.autodiscover:
providers:
- type: kubernetes
host: ${NODE_NAME}
hints.enabled: true
下一环节定义了将应用于该 Filebeat 实例捕获的所有日志的处理器链。首先,将利用来自 Docker、Kubernetes、主机和云服务提供商的元数据扩充事件。然后,drop_event 部分会基于内容和上述处理器创建的部分元数据字段筛选消息。当存在持续控制日志的干扰事件类型时,这会大有用处。注意逻辑和以及或如何用于构建匹配条件。
processors:
- add_cloud_metadata:
- add_host_metadata:
- add_docker_metadata:
- add_kubernetes_metadata:
- drop_event:
when:
or:
- contains:
message:"OpenAPI AggregationController:Processing item k8s_internal_local_delegation_chain"
- and:
- equals:
kubernetes.container.name: "metricbeat"
- contains:
message:"INFO"
- contains:
message:"Non-zero metrics in the last"
- and:
- equals:
kubernetes.container.name: "packetbeat"
- contains:
message:"INFO"
- contains:
message:"Non-zero metrics in the last"
- contains:
message: "get services heapster"
- contains:
kubernetes.container.name: "kube-addon-manager"
- contains:
kubernetes.container.name: "dashboard-metrics-scraper"
使用注释的 Filebeat 模块和自动发现
我们在上文了解了自动发现将如何获得相应的模块应用到 stdout/stderr 中,将其解析为特定模块的格式。请在 Filebeat 文档中了解有关自动发现的详情。
现在我们来讲解如何在样例应用程序中配置不同组件,从而与 Kubernetes 基于提示的自动发现一同协作。
NGINX 示例
此处为来自 $HOME/k8s-o11y-workshop/nginx/nginx.yml 的代码片段,指示 Filebeat 将本 pod 的日志作为 NGINX 日志处理,其中 stdout 代表访问日志,stderr 代表错误日志:
annotations:
co.elastic.logs/module: nginx
co.elastic.logs/fileset.stdout: access
co.elastic.logs/fileset.stderr: error
处理多行应用程序日志
基于提示的自动发现的另一示例是配置 Filebeat,将 petclinic 多行日志条目作为单一日志事件处理。这在组件记录多行消息时非常有用,例如代表单一事件的 Java 堆栈跟踪,但默认情况将根据行作为单一事件进行处理(以行尾为界限)。
此处为来自 $HOME/k8s-o11y-workshop/petclinic/petclinic.yml 的代码片段,代表了 Filebeat 使用基于提示的自动发现来理解的多行事件处理配置:
annotations:
co.elastic.logs/multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
co.elastic.logs/multiline.negate: "true"
co.elastic.logs/multiline.match: "after"
有关多行事件处理的更多详情,请查阅 Filebeat 文档。
分析 Elastic Stack 中的 Kubernetes 日志
现在日志已经采集进 Elasticsearch 之中,此刻便是充分开展利用的最佳时机。
使用 Kibana 中的 Logs 应用
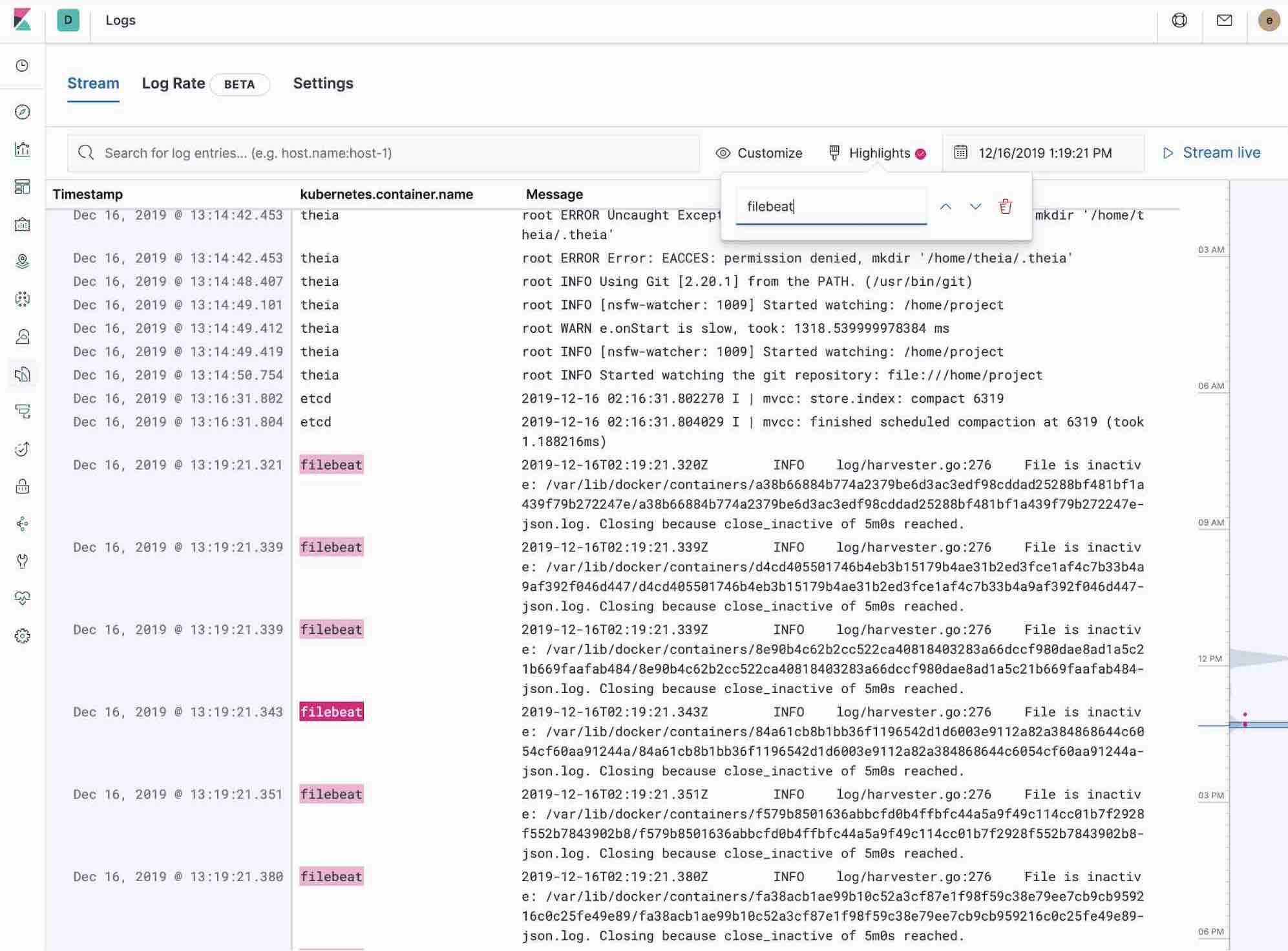
Kibana 中的 Logs 应用可以对收集到 Elastic Stack 之中的所有日志进行搜索、筛选和跟踪。所有日志均可在 Logs 应用的某一工具中找到,无需使用 ssh 命令登录不同服务器或是使用 cd 命令进入目录并跟踪单个文件。
- 使用关键词或纯文本搜索查看筛选日志。
- 您可以使用时间选取器或边栏的时间线视图,来回移动时间。
- 如果只想查看在 tail -f 样式之前的日志更新,只需单击 Streaming(流式处理)按钮,使用高亮突出显示您想要查看的那一部分重要信息即可。
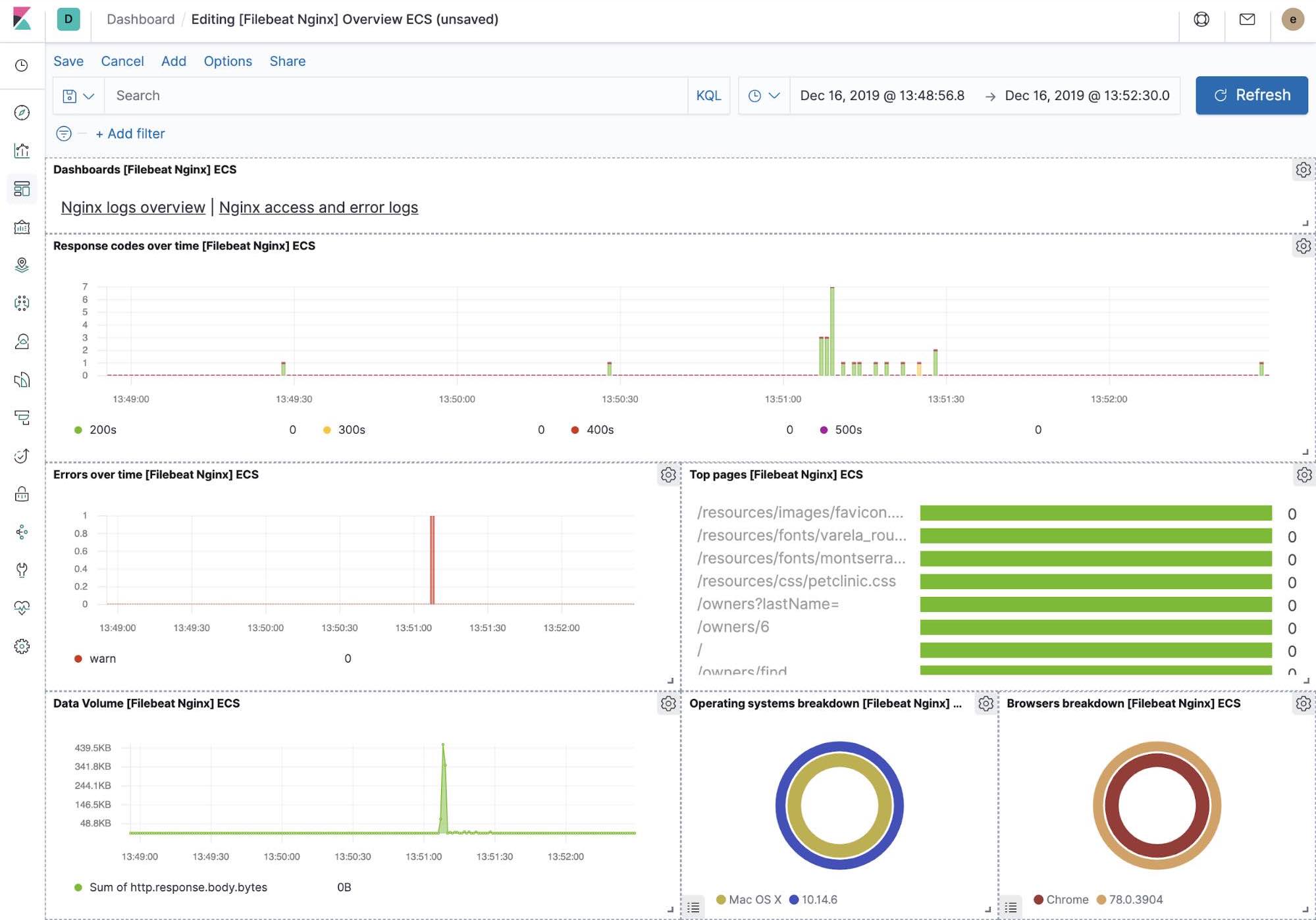
开箱即用的 Kibana 可视化
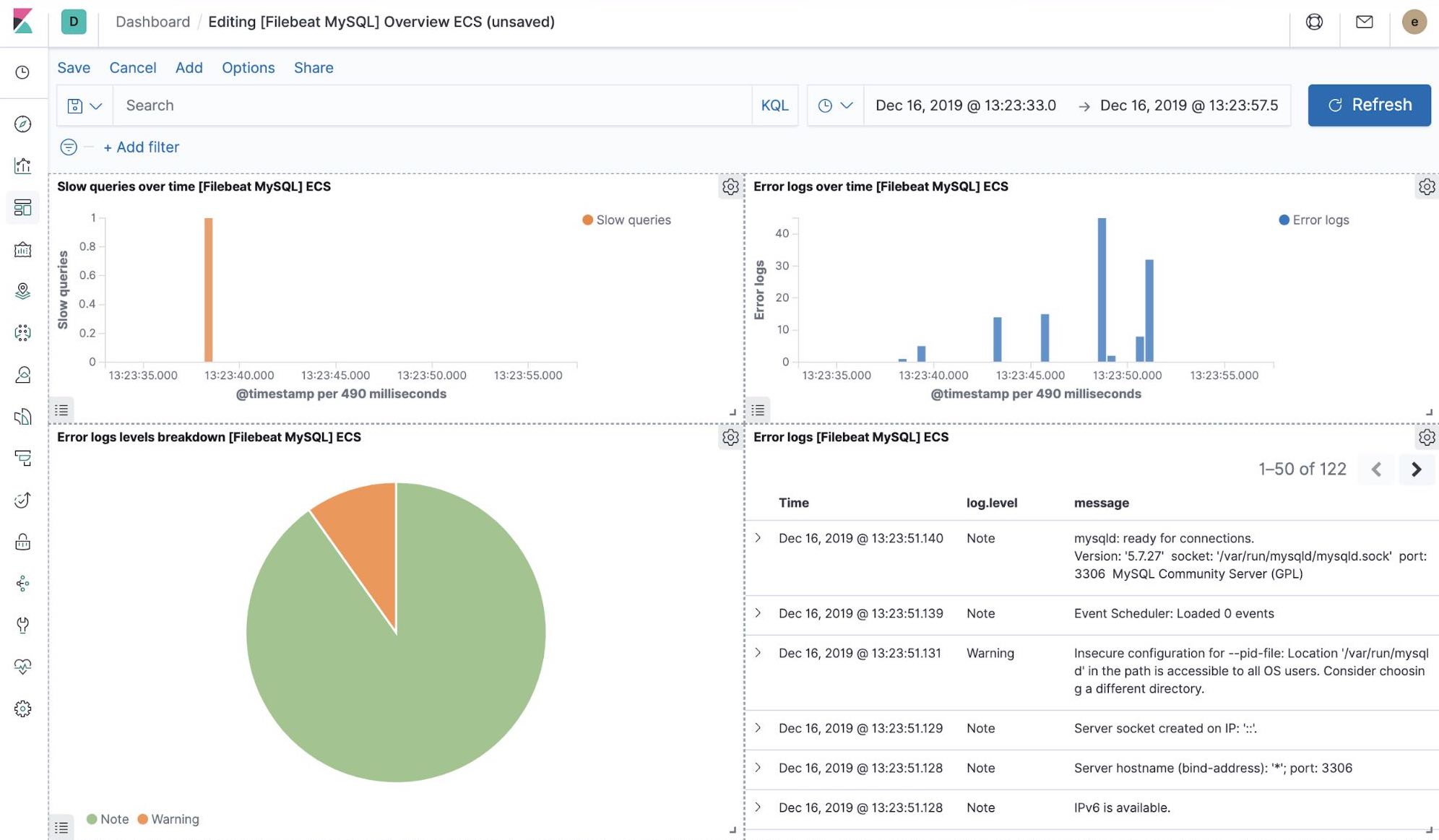
当我们运行 Filebeat-setup 作业时,除了其他操作,这会在 Kibana 中预创建一系列开箱即用的仪表板。在我们的样例 petclinic 应用程序最终部署完成后,便可以导航至 MySQL、NGINX 开箱即用的 Filebeat 仪表板,并会发现 Filebeat 模块不仅会捕获日志,还会获取组件记录的指标。实现这些可视化功能,需要运行样例应用程序的 MySQL 和 NGINX 组件。
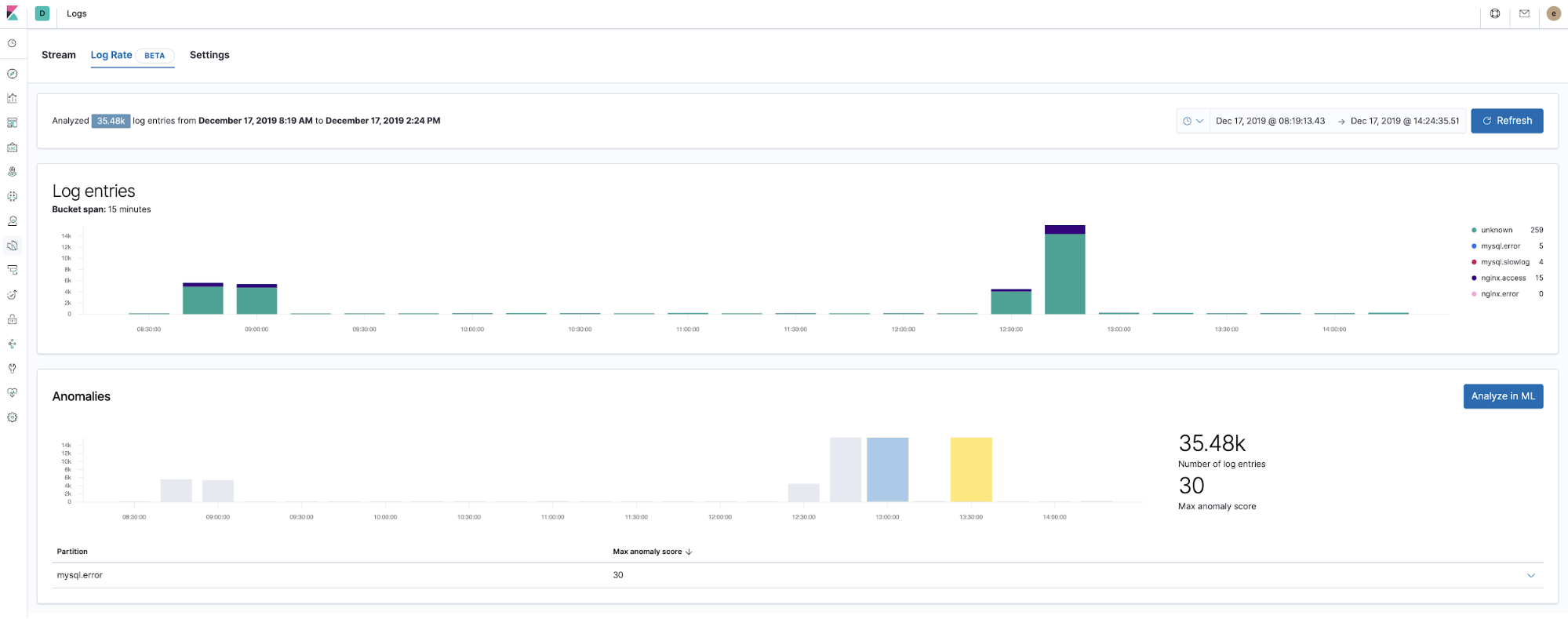
Machine Learning 和检测日志记录异常
从 7.5 版本开始,Elastic Stack 便支持检测应用程序组件日志速率中的异常情况。这一功能可用于检测:
- 刚部署的新应用程序或日志来源
- 由于推广(或攻击!)突然上升的日志记录活动
- 日志传输突然停止,可能是由于代理或采集管道故障
我们在 Logs 应用中引入了日志速率异常检测功能,让操作人员可以及时化解上述问题。在 Logs 应用中单击一下即可实现。
使用日志条目分类,检测未知的异常问题
日志相关的 Machine Learning 的另一项有用的应用便是检测此前未观测到的新日志类型条目。Machine Learning 可以极大程度地从日志条目中剥离所有数字和变量部分(例如时间戳、数值等),捕获余下部分,然后对日志条目的固定部分进行分类。然后尝试将其分组归类为存储桶,继续标记出现的新存储桶,代表此前未观测到的日志条目异常。

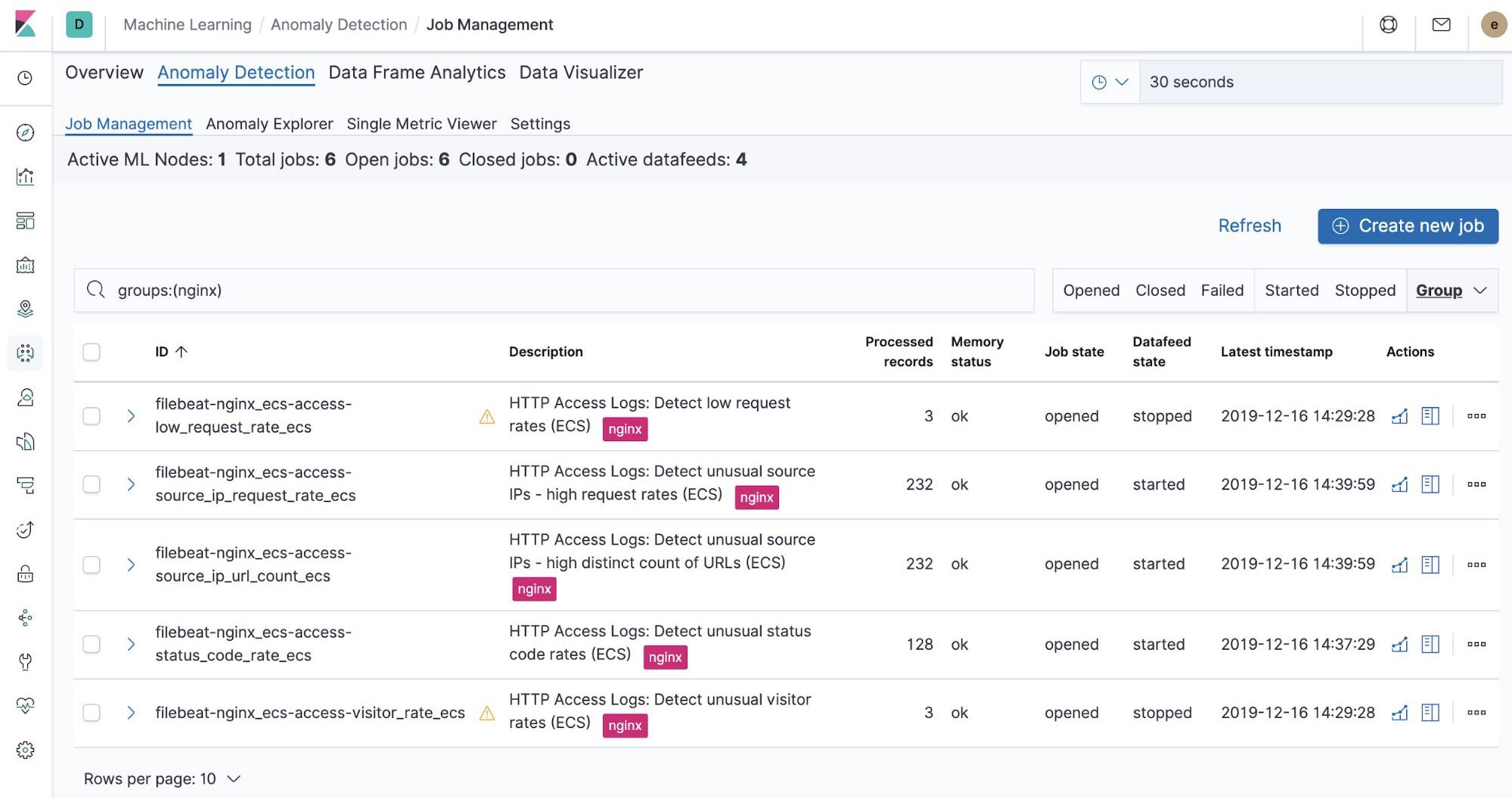
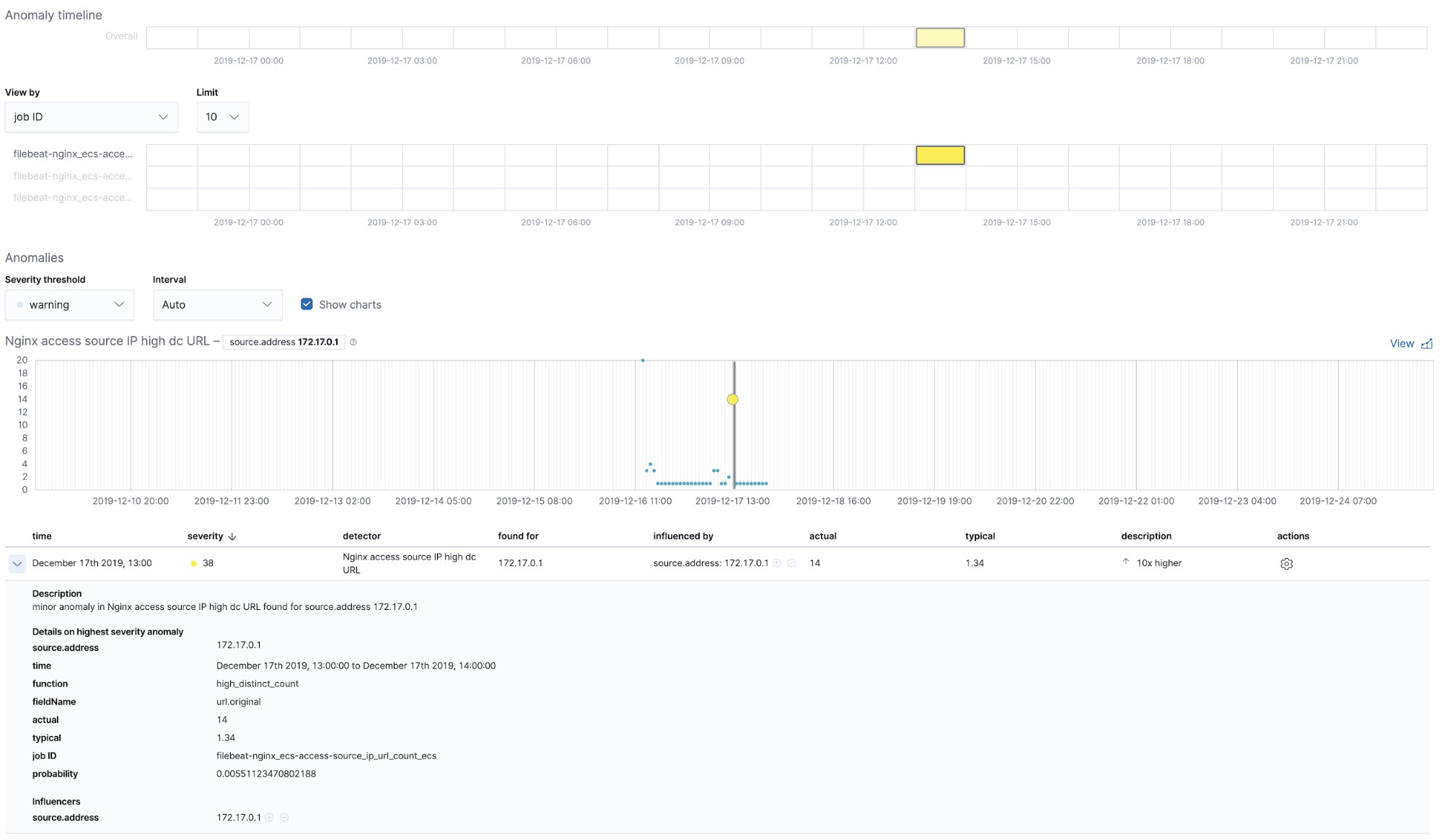
开箱即用的 Machine Learning 作业 — NGINX
当我们在运行 Filebeat-setup 作业时,同时会预创建开箱即用的 Machine Learning 作业。如果予以激活,则其会开始检测 Filebeat 采集的 NGINX stdout 和 stderr 数据异常。
总结
在本部分中,我们使用 Filebeat 及其模块,将 Kubernetes 日志采集到了 Elastic Stack 之中。通过在 Elastic Cloud 上注册免费试用的 Elasticsearch Service,或下载 Elastic Stack 并自行托管,您可以立即开始监测自己的系统和基础架构。配置完成并开始运行后,您便可以利用 Elastic 运行状态监测对主机可用性进行监测,使用 Elastic APM 检测在主机上运行的应用程序。这样您便可以顺利朝着全方位可观测系统的发展方向行进,实现全新指标集群的完整集成。如果您遇到任何困难或问题,请跳转至我们的讨论论坛,我们时刻准备为您服务。
下篇博文:收集性能和健康指标