Kubernetes 可观测性教程:指标收集和分析
本篇博文是我们 Kubernetes 可观测性教程系列第二篇,其中将带您探索如何实现对 Kubernetes 中运行的应用程序的全面监测,包括:
- 采集和分析日志
- 收集性能和健康指标
- 使用 Elastic APM 监测应用程序性能
我们将介绍使用 Elastic 可观测性,采集和分析 Kibana 中的容器指标(使用 Metrics 应用和开箱即用的仪表板)。
从 Kubernetes 收集指标
与 Kubernetes 日志目标并不固定如出一辙,从 Kubernetes 中收集指标可能颇具挑战,原因涉及以下几方面:
- Kubernetes 在不同主机中运行组件,而每个主机需要通过收集 CPU、内存、磁盘利用率以及磁盘和网络 I/O 等指标进行监测。
- Kubernetes 容器类似迷你的 VM,也有自己的一套指标
- 虽然应用程序服务器和数据库都可作为 Kubernetes pod 运行,但每种技术手段会有不同的方式报告相关指标。
组织通常使用诸多技术处理 Kubernetes 中的指标收集,这进一步加大了监测其 Kubernetes 部署任务的难度。而 Elastic 可观测性通过组合您的日志、指标和 APM 数据,使用一种工具便可统一可视化和分析,为上述情况带来了新气象。
使用 Metricbeat 进行 K8s 指标收集
与 Filebeat 相似,我们将仅使用 Metricbeat 收集在 Kubernetes 集群中运行的各项 pod 指标,以及 Kubernetes 自有的集群指标。Metricbeat 模块能快速、便捷地从各类源收集指标,并将其作为 ECS-兼容事件传输到 Elasticsearch 中,以便与日志、运行时间和 APM 数据相关联。Metricbeat 可以采用两种方式在 Kubernetes 中同时部署:
- 单一 pod,收集 Kubernetes 指标。该 pod 使用 kube-state-metrics,收集集群级别指标。
- DaemonSet 在每个 Kubernetes 主机中部署 Metricbeat(作为单一实例),从部署在该主机中的 pod 收集指标。Metricbeat 与 kubelet API 交互以获取在该主机中运行的组件,并使用不同的方式(例如自动检测),进一步询问组件,收集特定技术指标。
| 开始前:以下教程需要对 Kubernetes 环境进行设置。我们已经编写一篇补充博文,指导您设置单节点 Minikube 环境和演示应用程序的流程,从而运行其余活动。 |
收集主机、Docker 和 Kubernetes 指标
每个 DaemonSet 实例将收集如 YAML config $HOME/k8s-o11y-workshop/metricbeat/metricbeat.yml 中定义的主机、Docker 和 Kubernetes 指标:
系统(主机)指标配置
system.yml: |-
- module: system
period:10s
metricsets:
- cpu
- load
- memory
- network
- process
- process_summary
- core
- diskio
# - socket
processes: ['.*']
process.include_top_n:
by_cpu:5 # include top 5 processes by CPU
by_memory:5 # include top 5 processes by memory
- module: system
period:1m
metricsets:
- filesystem
- fsstat
processors:
- drop_event.when.regexp:
system.filesystem.mount_point: '^/(sys|cgroup|proc|dev|etc|host|lib)($|/)'
Docker 指标配置
docker.yml: |-
- module: docker
metricsets:
- "container"
- "cpu"
- "diskio"
- "event"
- "healthcheck"
- "info"
# - "image"
- "memory"
- "network"
hosts: ["unix:///var/run/docker.sock"]
period:10s
enabled: true
Kubernetes 指标配置
这包括通过与 kubelet API 通信收集于部署在主机上 pod 中的指标:
kubernetes.yml: |-
- module: kubernetes
metricsets:
- node
- system
- pod
- container
- volume
period:10s
host: ${NODE_NAME}
hosts: ["localhost:10255"]
- module: kubernetes
metricsets:
- proxy
period:10s
host: ${NODE_NAME}
hosts: ["localhost:10249"]
有关指标集中 Metricbeat 模块和数据更多信息,请查阅 Metricbeat 文档。
收集 Kubernetes 状态指标和事件
我们部署了收集 Kubernetes 指标的单一实例,其与 kube-state-metrics API 集成以监测由 Kubernetes 管理对象的状态变化。这是定义 state_metrics 收集的配置部分。$HOME/k8s-o11y-workshop/Metricbeat/Metricbeat.yml:
kubernetes.yml: |-
- module: kubernetes
metricsets:
- state_node
- state_deployment
- state_replicaset
- state_pod
- state_container
# Uncomment this to get k8s events:
- event
period:10s
host: ${NODE_NAME}
hosts: ["kube-state-metrics:8080"]
使用 pod 注释的 Metricbeat 自动发现
Metricbeat DaemonSet 部署能够自动检测 pod 中运行的组件,应用特定的 Metricbeat 模块收集特定技术指标。启用自动发现的方式之一便是使用 pod 注释以表明应用的哪一模块以及其他特定模块配置。Metricbeat 配置的这一部分可以启用基于 Kubernetes 的自动发现。$HOME/k8s-o11y-workshop/metricbeat/metricbeat.yml:
metricbeat.autodiscover:
providers:
- type: kubernetes
host: ${NODE_NAME}
hints.enabled: true
本教程中有两个组件使用了基于提示的自动发现:
- NGINX 定义
$HOME/k8s-o11y-workshop/nginx/nginx.ymltemplate: metadata: labels: app: nginx annotations: co.elastic.metrics/module: nginx co.elastic.metrics/hosts: '${data.host}:${data.port}' - MySQL 定义
$HOME/k8s-o11y-workshop/mysql/mysql.ymltemplate: metadata: labels: app: mysql annotations: co.elastic.metrics/module: mysql co.elastic.metrics/hosts: 'root:petclinic@tcp(${data.host}:${data.port})/'
有关基于提示的自动发现更多信息,请查阅 Metricbeat 文档。
收集应用程序指标(Prometheus 型)
我们的 Spring Boot petclinic 应用程序可以全方位公开呈现特定应用程序指标(公开的形式可以通过 Prometheus 抓取)。您可导航至应用程序 http 端点(地址为 http://
以下为应用程序报告内容的示例:
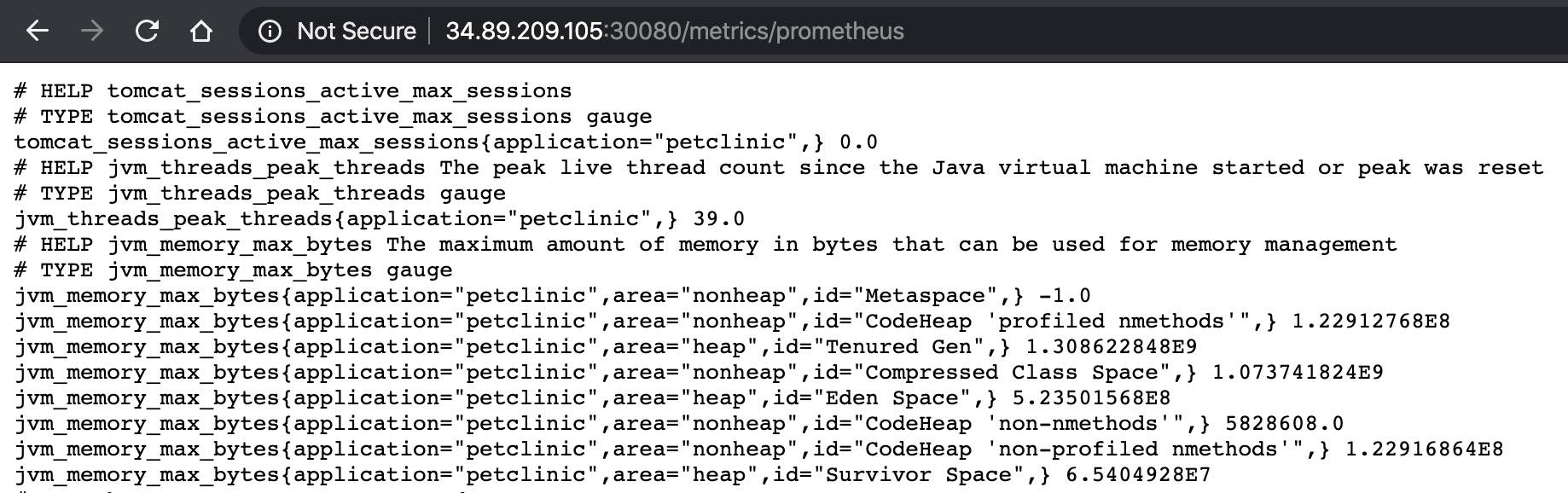
此处为 petclinic YAML 部署配置中提示的配置,通知 Metricbeat 使用 Prometheus 模块收集这些指标。$HOME/k8s-o11y-workshop/petclinic/petclinic.yml:
template:
metadata:
labels:
app: petclinic
annotations:
co.elastic.metrics/module: prometheus
co.elastic.metrics/hosts: '${data.host}:${data.port}'
co.elastic.metrics/metrics_path: '/metrics/prometheus'
co.elastic.metrics/period:1m
一般情况下,Metricbeat 可增加或完全取代 Prometheus 服务器。如果您已经部署并在使用 Prometheus 服务器,则 Metricbeat 可使用 Prometheus Federation API 将指标从服务器导出,进而提供跨多个 Prometheus 服务器、Kubernetes 命名空间和集群的可见性,实现 Prometheus 指标与日志、APM 和运行时间的关联。如果选择简化监测基础架构,请使用 Metricbeat 收集 Prometheus 指标,并将其直接传输至 Elasticsearch。
元数据扩充
Metricbeat 收集的所有事件都通过以下处理器扩充。$HOME/k8s-o11y-workshop/metricbeat/metricbeat.yml:
processors: - add_cloud_metadata: - add_host_metadata: - add_kubernetes_metadata: - add_docker_metadata:
这可实现指标与主机、Kubernetes pod、Docker 容器和云服务提供商基础架构元数据的关联,以及与应用程序性能监测数据和日志等可观测性问题的其他部分进行结合。
Kibana 中的指标
本教程中的 Metricbeat 配置会生成以下 Metrics 应用视图。您可随意点击并查看这些内容。请注意:为了方便您进行搜索,Kibana 的每个界面均配备搜索栏。当您试图在繁杂琐碎的内容中搜索需要的信息时,支持筛选视图并可以对相关内容深入查看的方式绝对是您的不二之选。我们的教程仅涉及一个主机,具体如下:
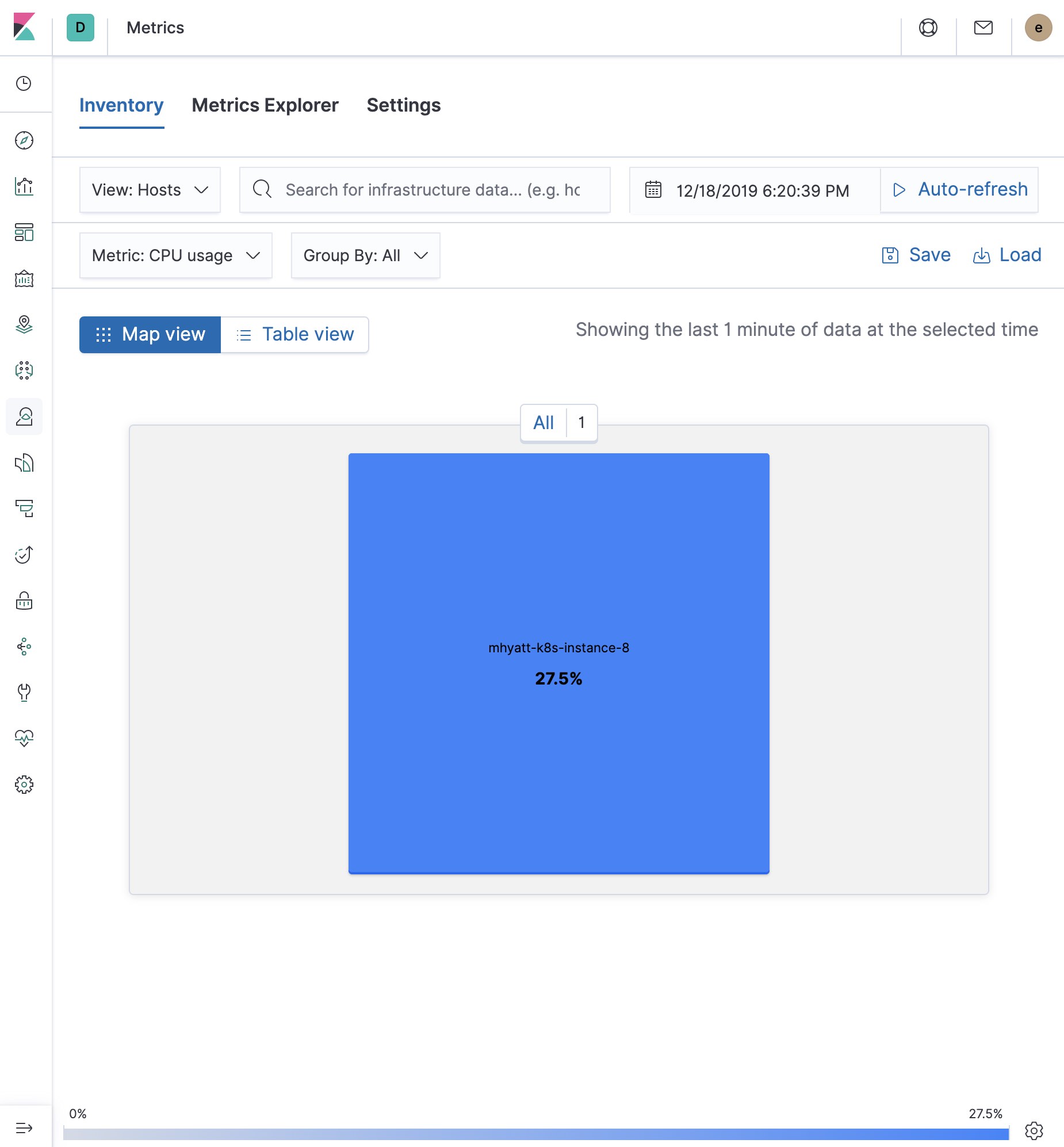
主机基础架构指标
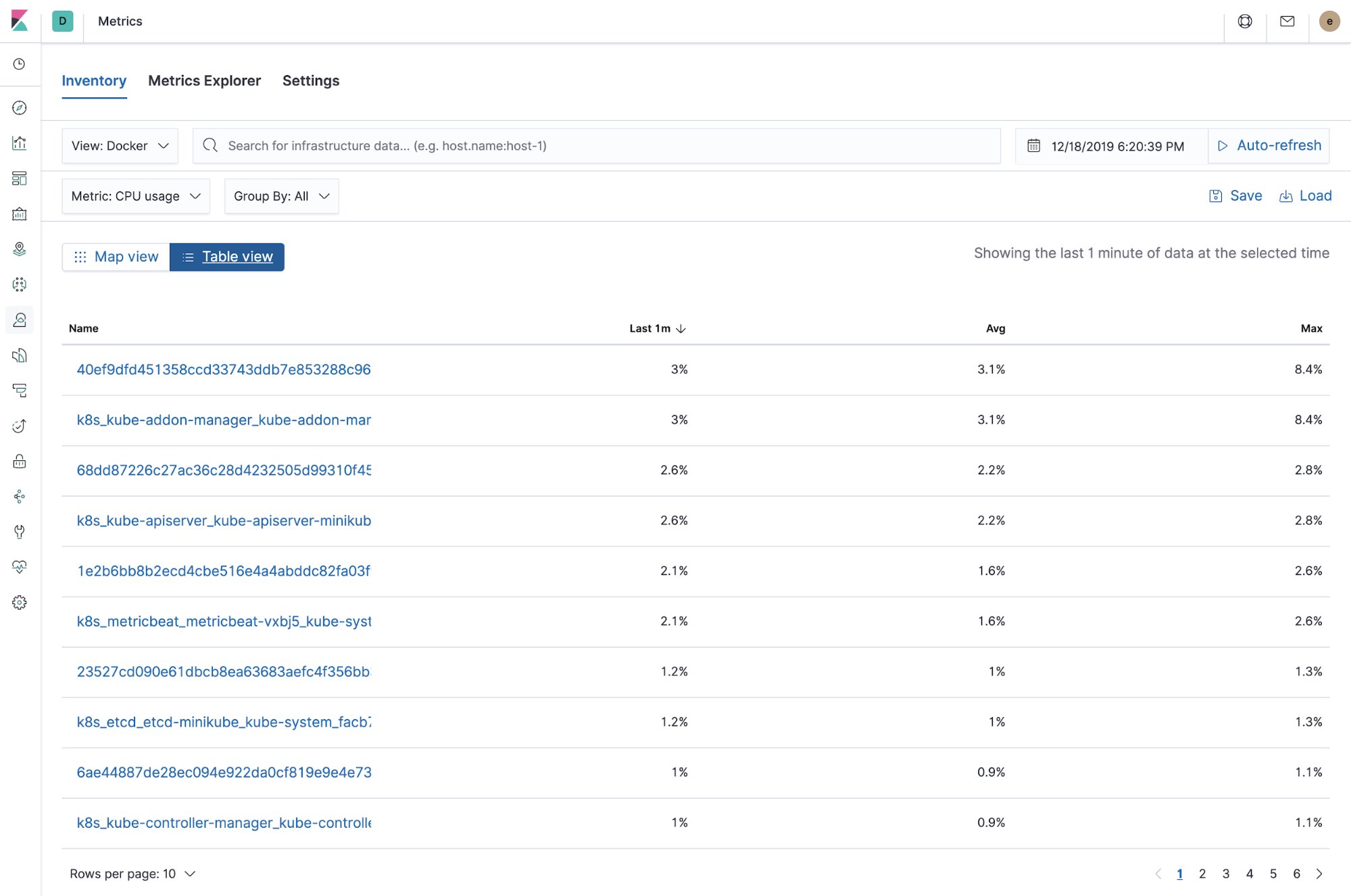
Docker 基础架构和指标(表视图)
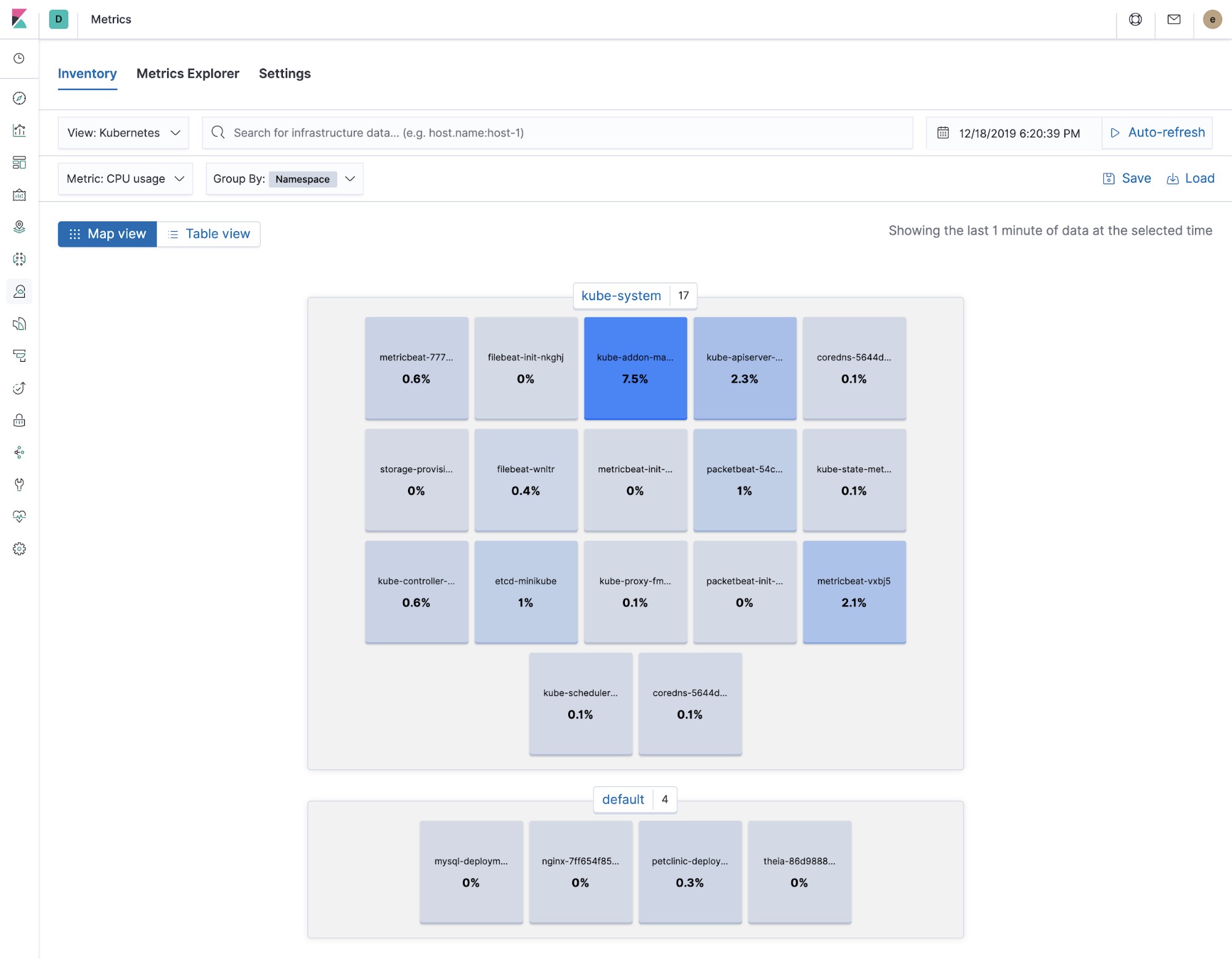
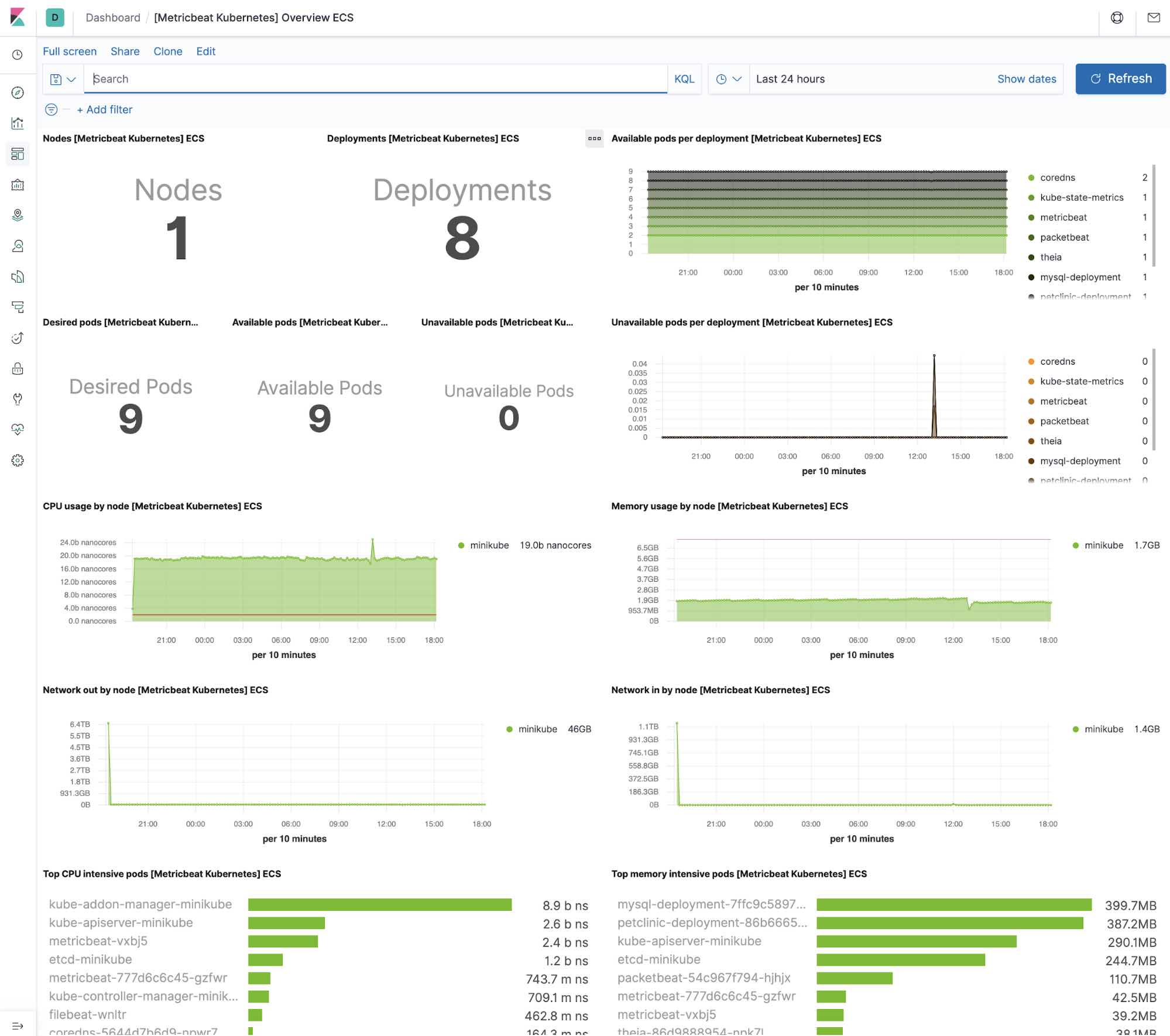
Kubernetes 基础架构和指标
指标浏览器
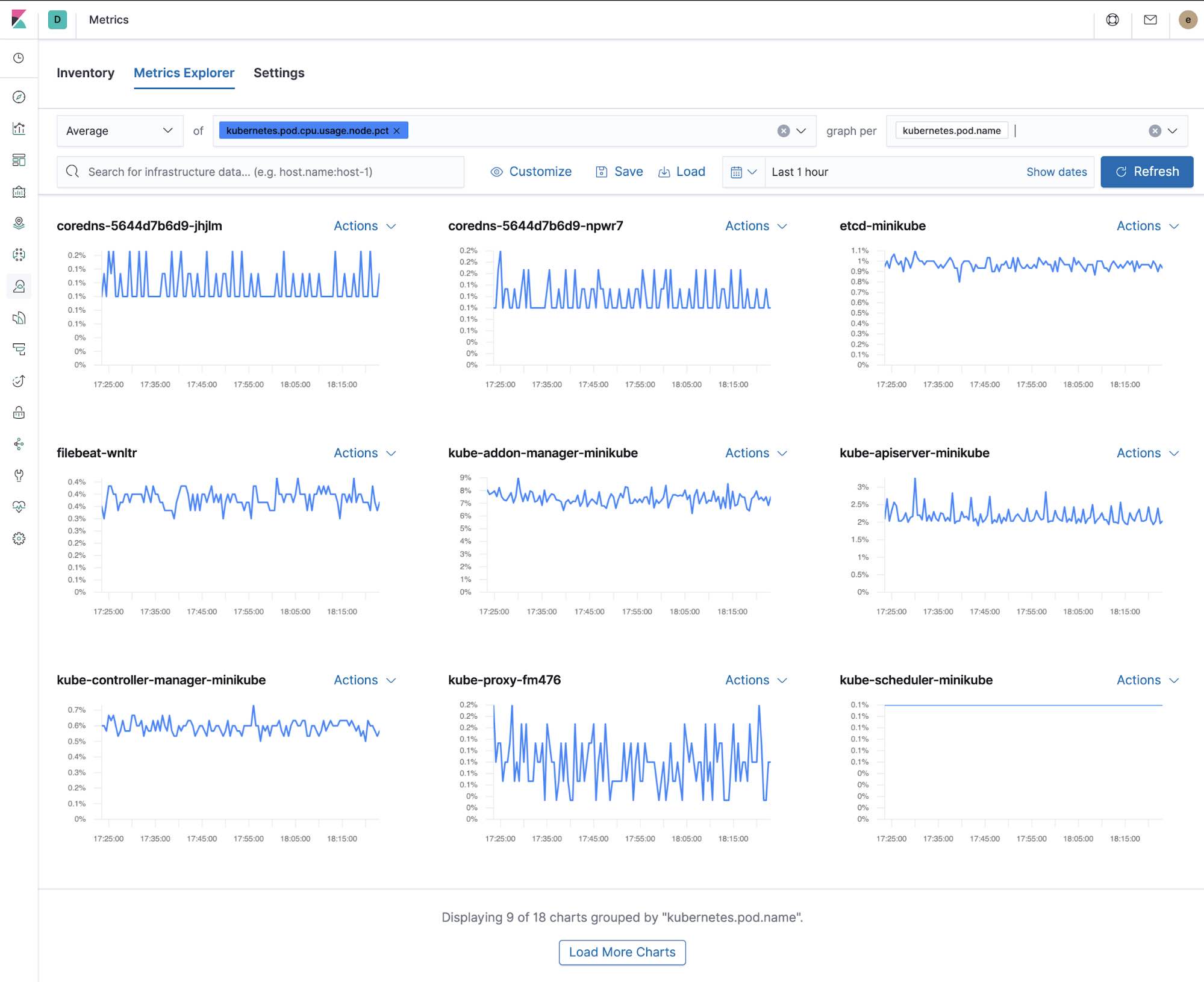
开箱即用的 Kibana 仪表板
Metricbeat 传输使用多个预建的 Kibana 仪表板(使用一个命令,便可轻松添加到集群中)。然后,您可直接按照已有形式使用这些仪表板,或将其作为基础,构建符合自己需求的定制仪表板。以下仪表板可帮助您清晰展示教程环境中的数据。
主机
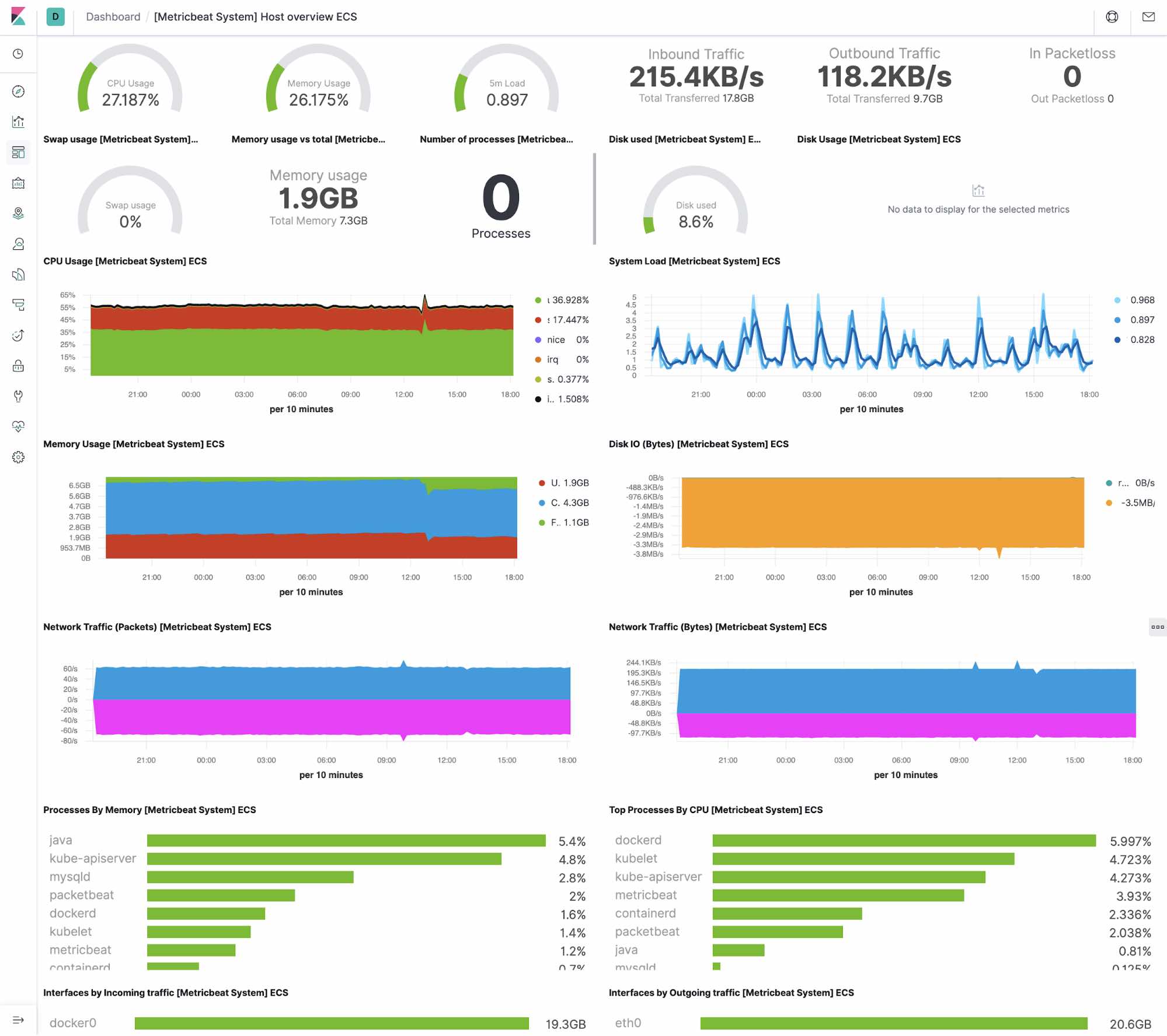
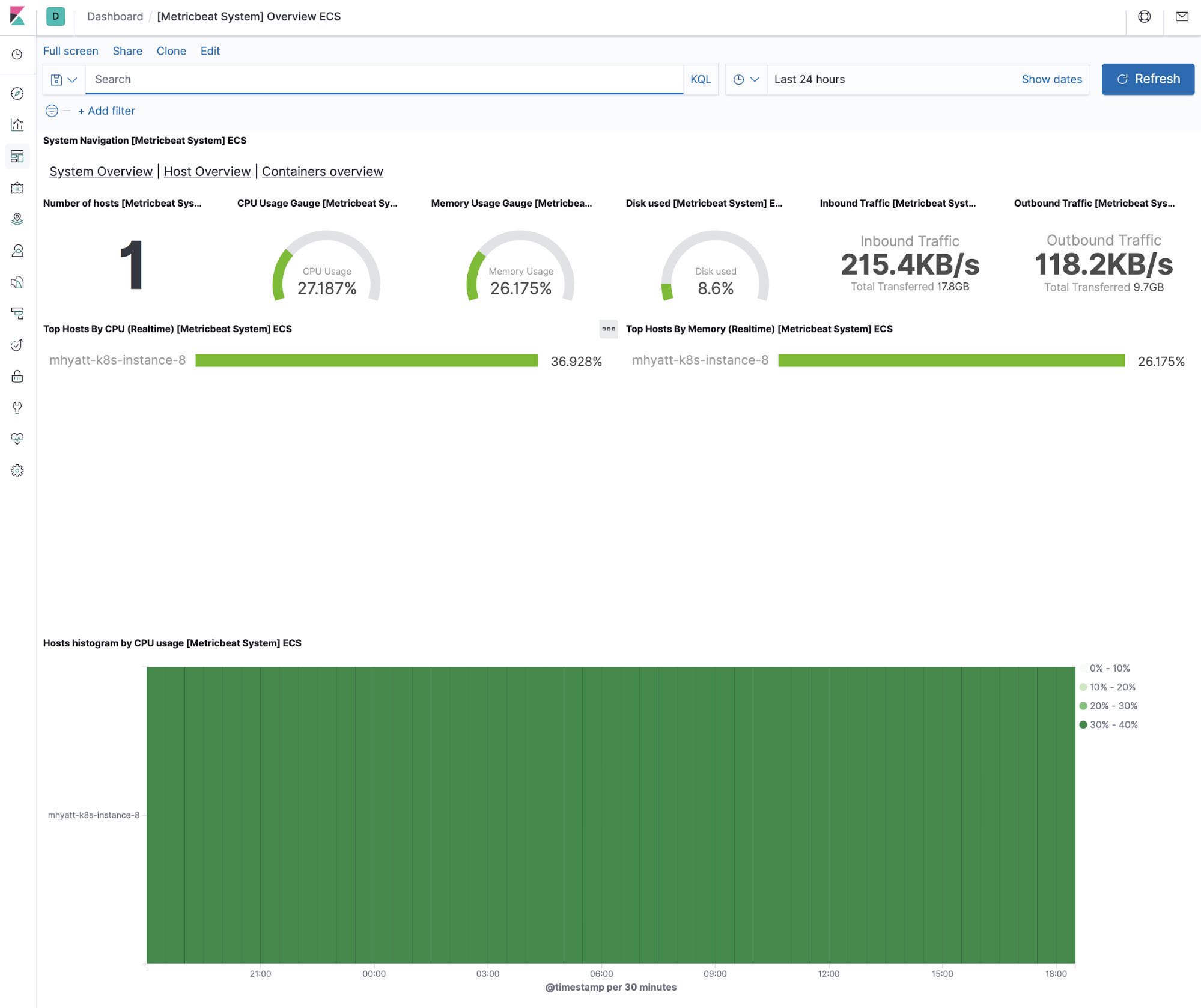
系统
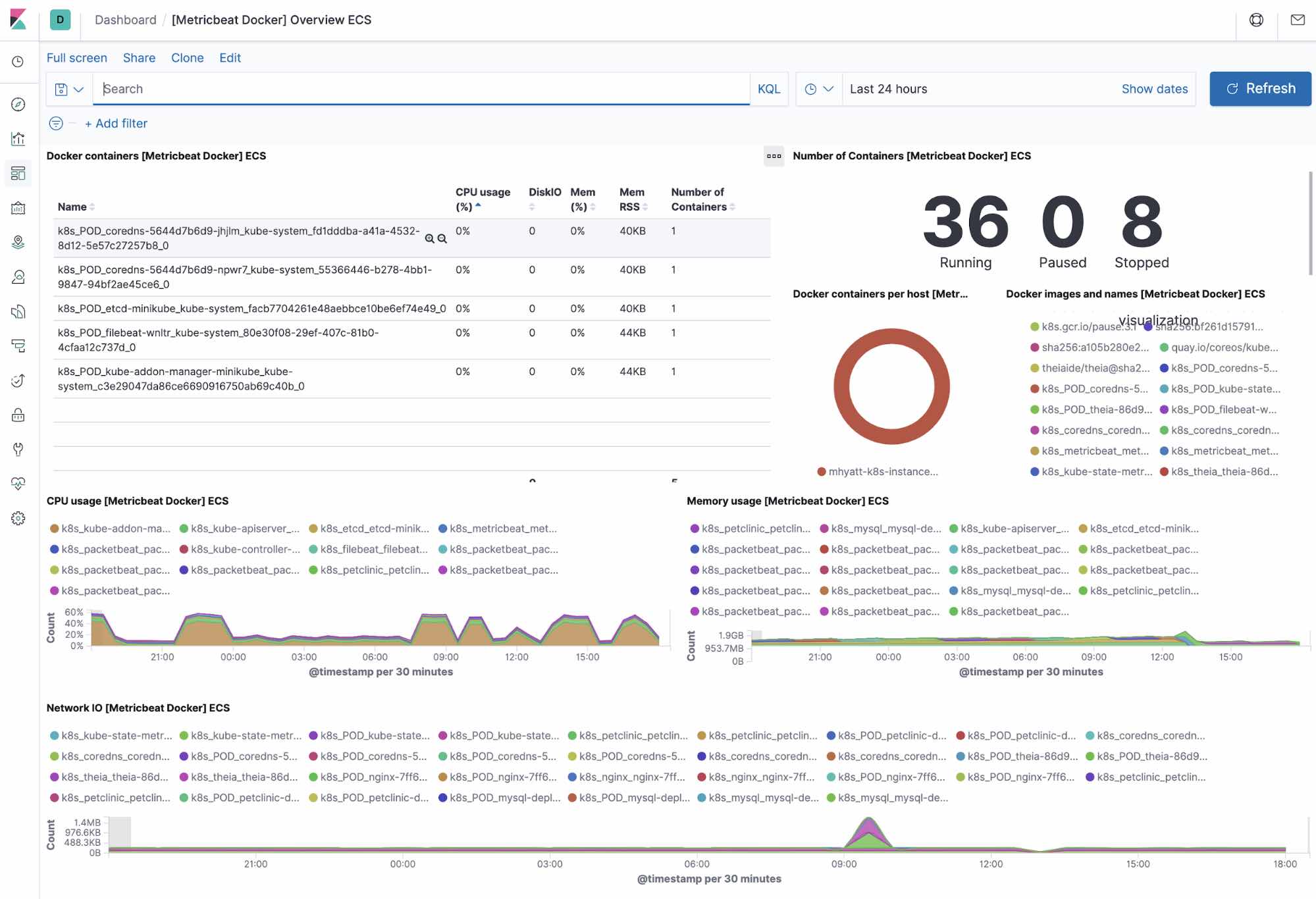
Docker
Kubernetes
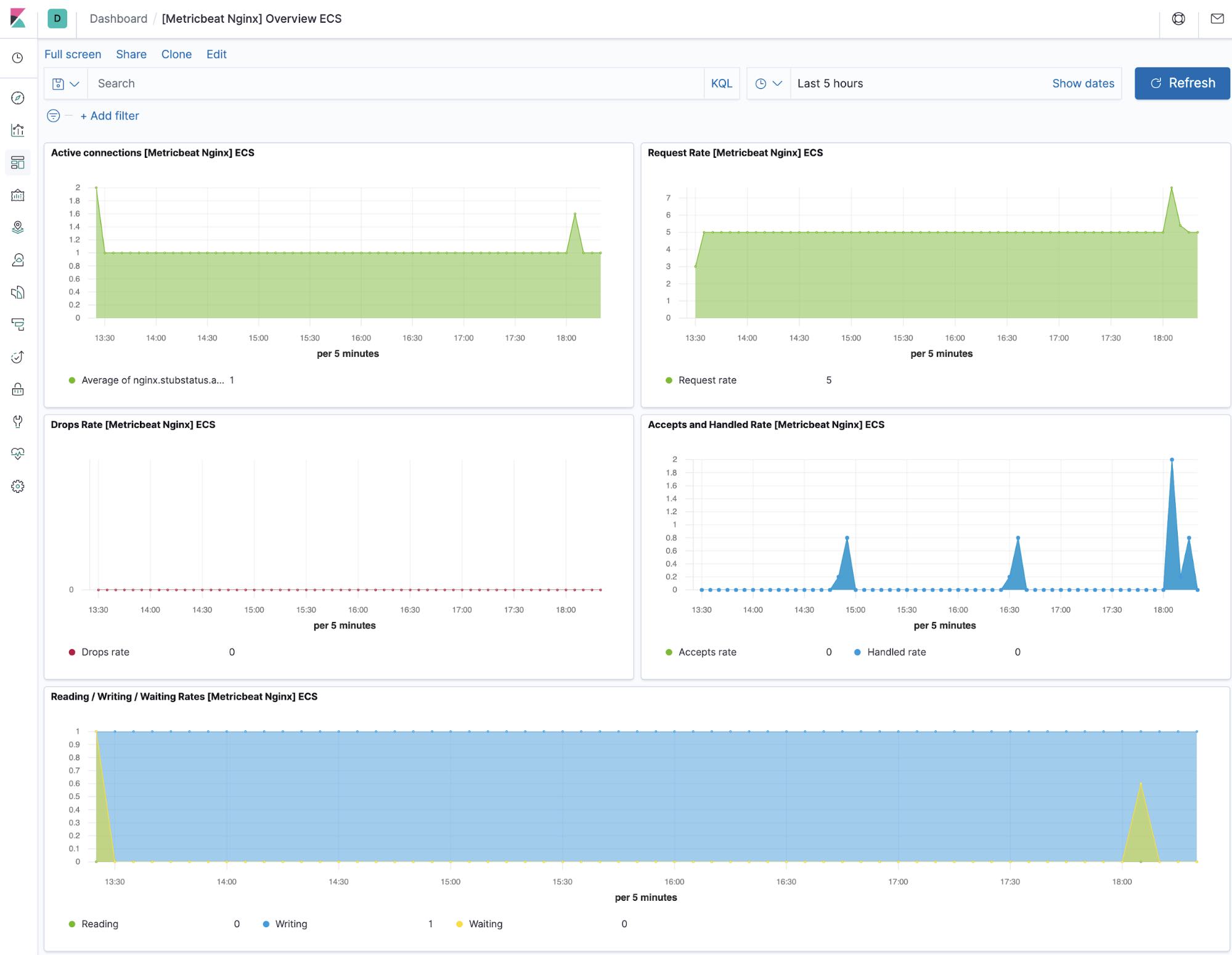
NGINX
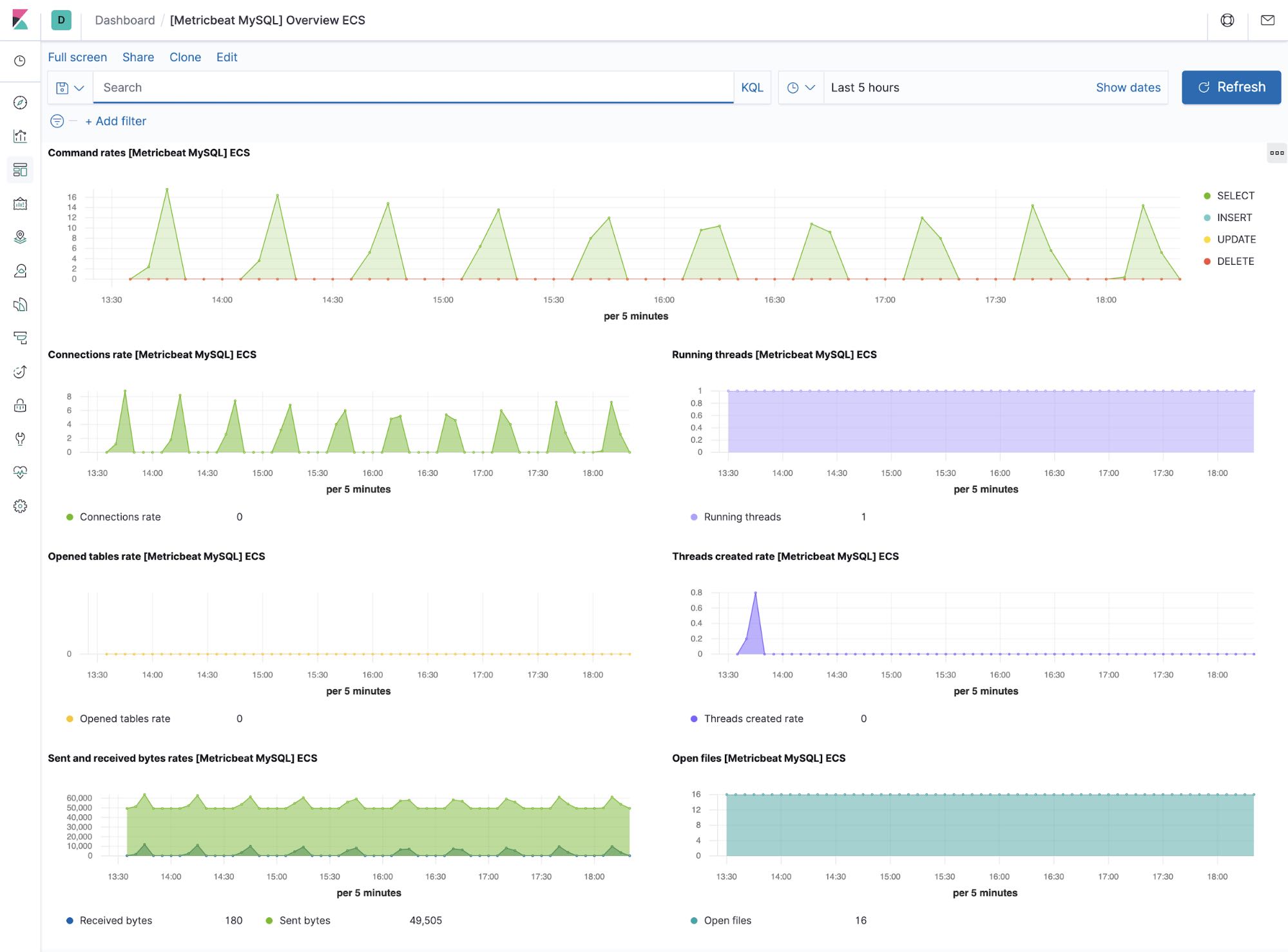
MySQL
总结
我们在这一部分讲解了使用 Metricbeat 收集应用程序和 Kubernetes 指标。 您可以立即开始监测自己的系统和基础架构。您可以在 Elastic Cloud 上注册免费试用 Elasticsearch Service,或者下载 Elastic Stack 并自行托管。
部署完成并开始运行后,您便可以使用运行状态监测对主机可用性进行监测,使用 Elastic APM 检测在您主机上运行的应用程序。这样您便可以顺利朝着全方位可观测系统的发展方向行进,实现全新指标集群的完整集成。如果您遇到任何困难或问题,请跳转至我们的讨论论坛,我们时刻准备为您服务。