Elastic on Elastic: How we saved $100,000/month by keeping our own software up to date


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Let's start with the bottom line: When we upgraded to Elasticsearch 7.15 last year, our internal observability clusters saw a reduction in inter-node traffic from 464TB to 204.5TB per day. We monitored this reduction through subsequent upgrades and noticed its impact on our data transfer and storage costs. So here it is: upgrading saved Elastic $3,500 per day, or approximately $100,000 a month, or $1.2 million annually. We are excited to see these innovations directly lower the total cost of ownership and potentially save money for our customers. Here's a closer look at how we did it, and how you can, too.
Note: As of the date of this blog post, the latest Elastic release is 8.1 — however rest assured that if you're upgrading to the latest release, you're getting the data (and cost) savings present in 7.15, along with all the efficiencies and improvements we've since introduced.
Introducing Elastic’s own observability (O11y) clusters
Observing production software, services, and infrastructure is critical to the success of any organization. That is why at Elastic, we use Elastic Observability to ensure the availability of Elastic Cloud. Not only do our customers depend on this managed service for their observability, security, and search, but we also use Elastic Cloud for these same use cases.
All told, Elastic’s observability cluster comprises approximately 207 production clusters spanning 4 different cloud providers, hosting over 1.2 trillion documents. The 207 clusters can be broken up into 3 clusters in each cloud region, where we gather, store, and analyze data like metrics, logs, and APM data. While this provides the benefits of restricting network traffic to regions and for isolation and security, it can be challenging to recognize patterns across a distributed platform. If there is an interesting data point in one region, how can you easily determine if the same data point is occurring in any of our other regions?

By applying cross-cluster search, the Elastic Cloud Observability team uses a single overview cluster that executes searches across all of the regional logging, metrics, and traces clusters. Cross-cluster search is both a scalable and seamless solution to keep up with the pace of Elastic Cloud’s regional expansion as our team monitors each new region. If you would like to know about our single overview cluster, you can read about it here. Or if you are curious about how we defined our SLI/SLO parameters for Elastic Cloud, you can check this ElasticON talk here.
Avoiding a network traffic jam
With the size and scale of the observability cluster monitoring Elastic Cloud, there is bound to be “some” network traffic. Other than the terabyte of logs, metrics, and trace data ingested per day, there is also roughly 464TB worth of inter-node traffic! This includes data being relocated between tiers defined by index lifecycle management (ILM) and data sync between nodes that are located in different availability zones to ensure high availability. Searches that are executed across multiple nodes of a cluster from the overview cluster also contribute to this network traffic. If you are familiar with the pricing from some of the major cloud providers, then you already know how data transfer and storage (DTS) network traffic charges can quickly add up.
With the enhancements made in Elasticsearch 7.15, inter-node traffic was reduced by more than half to 204.5TB — and with this significant reduction in DTS saved Elastic more than $3,500 dollars a day, $100,000 per month, or $1.2 million a year!
How we did it
In Elasticsearch 7.15 there were two critical changes to drastically reduce DTS:
1. Network data compression
The first change was utilizing lz4, a lossless compression algorithm we used to compress indexing data. From our benchmarks shown below, we show negligible performance overhead for heavy-indexing use cases like logs, metrics, and time-series data while reducing inter-node traffic by more than 70%.
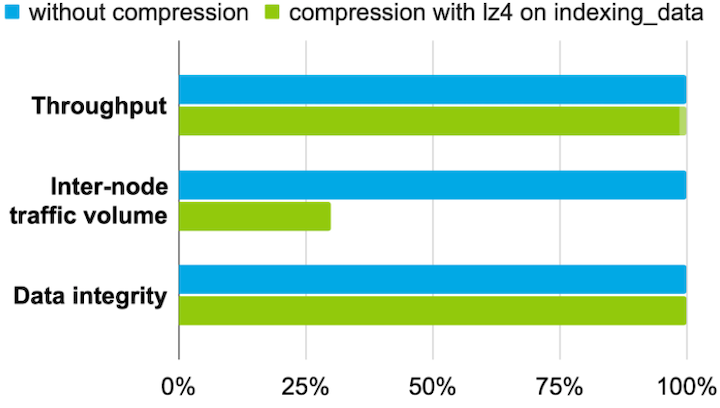
This greatly reduced node traffic which helped ultimately reduced our DTS cost.
2. New data relocation and recovery methods
Prior to 7.15, data relocation between phases in ILM like hot and warm could be sent to different data nodes within the cluster. If nodes are located in different availability zones then a cost would be incurred for sending network data from node to node from the cloud provider.
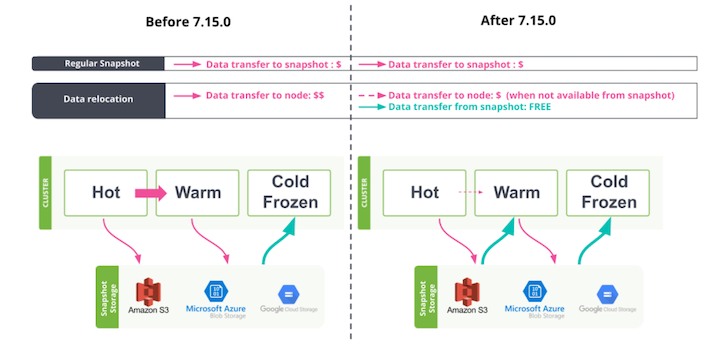
In 7.15, data relocation is handled by utilizing snapshot data. Communication between the data nodes and the snapshot storage doesn’t traverse different availability zones which reduces DTS costs.
In addition to data relocation, automatic shard recovery and resilience are improved by using snapshot data. Prior to 7.15 if a data node is added, replaced, removed, or simply unreachable, copies of data would be rebalanced across the remaining data nodes within the cluster to ensure resiliency. Shards would be copied from node to node via inter-node communication which would increase DTS.
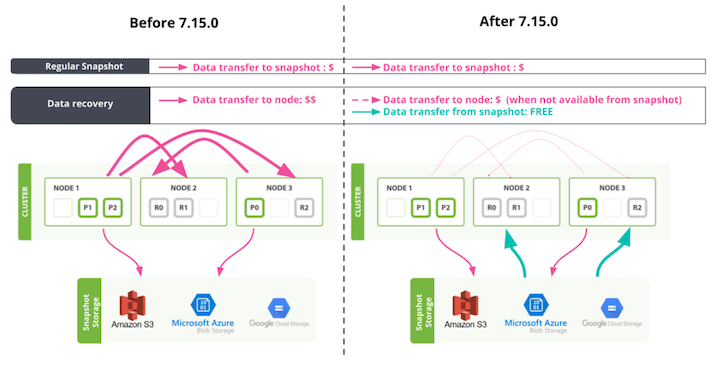
Using the same technology, 7.15 shards are now recovered from snapshot data stored on cloud object storage, avoiding communication from node to node that would otherwise increase DTS.
If you would like to know more about these changes in 7.15 and DTS reduction, I would highly recommend reading reducing data transfer and storage DTS costs in Elastic Cloud. There is great information on pricing and additional details about some of the technical changes in Elasticsearch.
Are you ready to experience life in the (network) fast lane?
For clusters with heavy indexing like Elastic’s internal observability cluster, we expected a significant drop in DTS which resulted in a reduced cloud bill. Simply upgrading to 7.15 (or a later version of Elastic) can help deliver similar cost benefits.
We recommend you upgrade to the latest version of Elastic so you don’t miss out on all the new features from faster and more efficient search in Elasticsearch 7.16, to NLP and vector search 8.0 — and even more speed and cost search benefits in 8.1
Sound interesting? Try them out now on Elastic Cloud by upgrading your deployments today and enjoy these features. Or sign up for a free 14-day trial and check out our blog for a step-by-step guide on how to try it out.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print