Três maneiras pelas quais melhoramos a escalabilidade do Elasticsearch


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
“Encontramos limites testando-os.”
Herbert A. Simon
Nosso foco na Elastic é proporcionar valor agregado aos usuários por meio de resultados rápidos que operam em escala e são relevantes: velocidade, escala e relevância estão no nosso DNA. No Elasticsearch 7.16, voltamos a nossa atenção para a escala, ampliando os limites do Elasticsearch para tornar a busca ainda mais rápida, a memória menos exigente e os clusters mais estáveis. Ao longo do caminho, descobrimos uma variedade de dimensões nos shards e, no processo, aceleramos o Elasticsearch, fazendo-o alcançar novos patamares.
Historicamente, recomendamos evitar a criação de um zilhão de shards no seu cluster devido à sobrecarga de recursos envolvida. No entanto, com a nova estratégia de indexação de fluxos de dados no Fleet, mais e mais shards menores serão gerados de casos de uso de segurança e observabilidade; por isso, é essencial que encontremos novas maneiras de lidar com o crescimento no número de shards. Neste post do blog, abordaremos três desafios de redimensionamento no Elasticsearch e como estamos aprimorando a experiência na versão 7.16 e posteriores.

Simplificação da autorização
Imagine que você esteja entrando em um pub. Uma pessoa olha o seu documento de identidade na porta e, toda vez que pede uma bebida, você precisa mostrar a identidade novamente. Era assim que a autorização costumava executar verificações antes da versão 7.16: cada nó (porta) exigia uma verificação de autorização, e cada shard (pedido de bebida) também exigia uma verificação de autorização. Mas e se uma única verificação de identidade na porta pudesse cobrir os dois? Vamos aplicar essa mesma ideia à autorização no Elasticsearch!
O Elasticsearch permite que os usuários configurem o controle de acesso por função/atributo para conceder permissão refinada por campo, por documento ou por índice. Antes, o authorize estava presente em muitas fases de uma consulta de busca para garantir que solicitações não autorizadas não tivessem acesso a dados injustificados. No entanto, a vigilância da funcionalidade de autorização tem um custo, e parte da lógica não é redimensionada horizontalmente à medida que o tamanho do cluster aumenta. Por exemplo, obter funcionalidades de campo para todos os campos em todos os índices de um cluster grande pode levar muitos segundos ou até minutos, gastando quase todo o tempo de execução em trabalho relacionado à autorização.
A versão 7.16 aborda esses problemas de dois lados:
- As melhorias algorítmicas tornam a autorização de solicitações individuais mais rápida, tanto ao autorizar uma solicitação REST quanto ao autorizar durante a comunicação da camada de transporte (ou seja, toda a rede interna de nó a nó) entre nós dentro de um cluster Elasticsearch.
- A autorização de solicitações internas é herdada de verificações anteriores ou se torna significativamente mais barata em muitos casos. Antes da versão 7.16, o Elasticsearch executava a mesma lógica de autorização pela qual a solicitação externa inicial passava ao autorizar as solicitações de transporte internas no cluster. Isso era feito para evitar a introdução de uma superfície de ataque na comunicação interna de nó a nó, que permitiria que um invasor criasse solicitações internas para contornar a lógica de autorização. Isso ficou muito mais barato agora ignorando a expansão de curingas em subsolicitações, ignorando a autorização para solicitações locais de nó (dentro do mesmo nó) e reduzindo o número geral de solicitações necessárias para ações como a busca.
Redução das solicitações de shard na fase pre-filter
Uma nova estratégia de busca foi implementada na versão 7.16 nas fases de pre-filter para reduzir o número de solicitações para uma vez por nó correspondente. Antes da versão 7.16, a primeira fase de uma busca que tentasse filtrar todos os shards de uma consulta que não contivesse dados relevantes exigiria uma solicitação por shard do nó coordenador para um nó de dados. Ao consultar milhares de shards de uma vez, isso envolveu enviar milhares de solicitações por solicitação de busca do nó coordenador, lidar com milhares de respostas no nó coordenador, além de lidar com todas essas solicitações nos nós de dados e responder a elas. O redimensionamento do cluster para mais nós de dados melhoraria o desempenho ao lidar com tantas solicitações nos nós de dados, mas não ajudaria no desempenho dessa operação no nó coordenador.
A partir da versão 7.16, a estratégia de execução da fase pre-filter foi ajustada para enviar apenas uma única solicitação por nó na fase, cobrindo todos os shards do nó. Isso pode ser visto na Figura 1 abaixo. Um cluster com milhares de shards em três nós de dados veria o número de solicitações de rede na fase de busca inicial passar de milhares para até três solicitações, independentemente do número de shards buscados. Como as solicitações por shard enviadas antes da versão 7.16 continham basicamente os mesmos dados em todos os shards, ou seja, a consulta de busca, o envio de apenas uma solicitação por nó significa que essas informações não são mais duplicadas em várias solicitações, reduzindo drasticamente o número de bytes que precisam ser enviados pela rede.
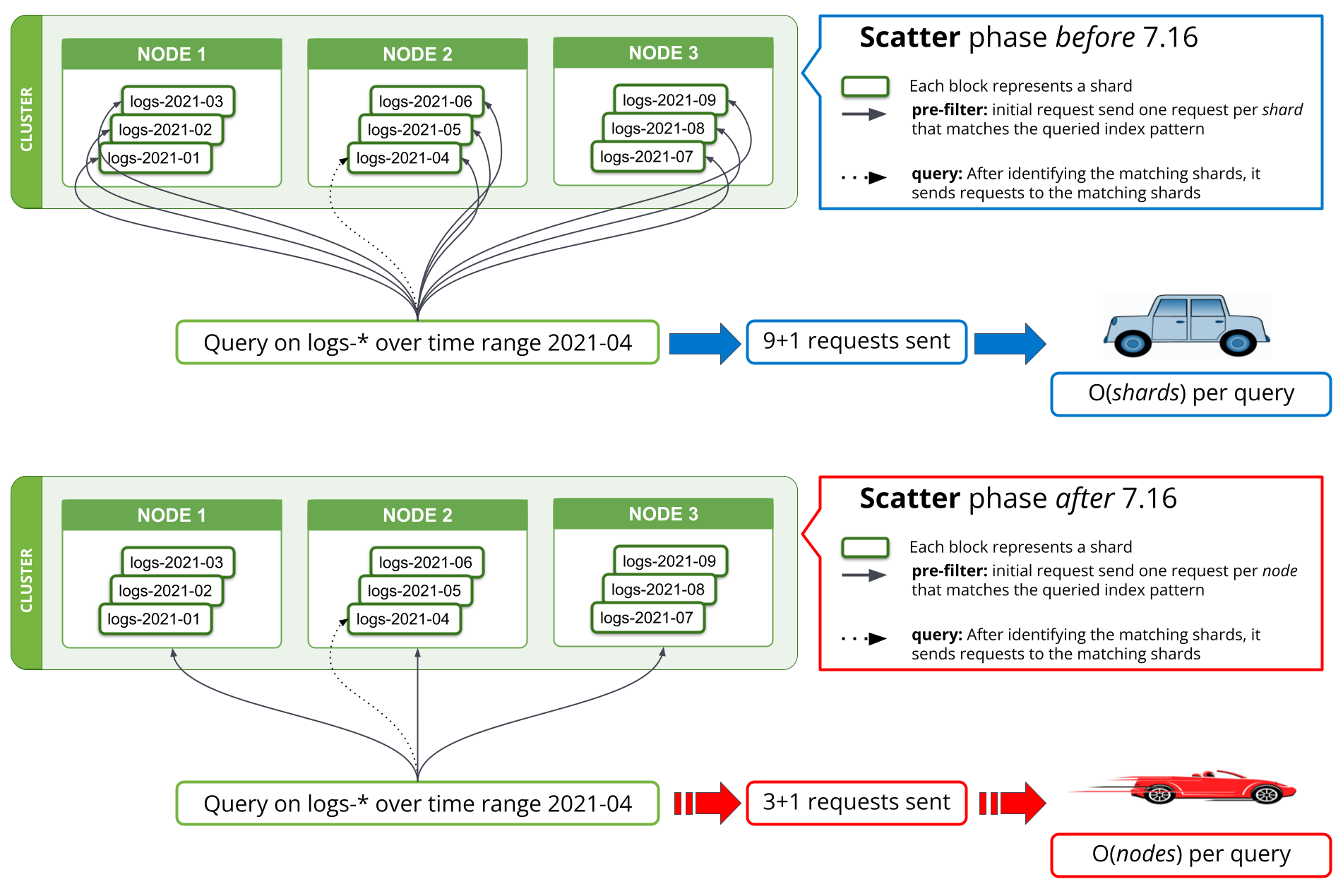
Uma implementação semelhante foi feita para field_caps, que é usado por consultas do Kibana e *QL. Teoricamente, as solicitações de busca salvas na solicitação de rede foram reduzidas de O(shards) para O(nodes) por consulta; praticamente, nosso resultado de benchmark mostra que a consulta de logs de vários meses de dados em um grande cluster de logging cai de minutos para menos de 10 segundos. As economias feitas aqui ajudam não apenas no número de solicitações de rede, mas também reduzem a utilização de memória e CPU associada a essas solicitações.
Redução da ocupação da memória
Pode ser surpreendente, mas as companhias aéreas conseguem obter uma economia significativa de peso fazendo coisas como remover uma única azeitona das saladas, tornar os copos mais finos e imprimir revistas em tamanhos menores. Estamos adotando uma abordagem semelhante no Elasticsearch reduzindo o custo da memória por campo. Embora estejamos falando de apenas alguns quilobytes por campo, quando multiplicados por milhões de campos de todos os índices em um cluster, podemos economizar uma quantidade enorme de heap.
A utilização de heap nos nós de dados do Elasticsearch depende do número de índices, campos por índice e shards armazenados no estado do cluster. Ter um grande número de índices significa que a memória heap está constantemente ocupada, independentemente da carga no nó. Na versão 7.16, reestruturamos os construtores de campo para os campos text e number, resultando em uma redução da ocupação da memória e alcançando uma redução de memória de mais de 90% apenas para manter essas estruturas de campo.
Nós ingerimos, nós buscamos, nós conquistamos
Desde o lançamento da versão, conseguimos observar as melhorias feitas em clusters de carga de trabalho realistas. Aqui estão alguns gráficos que mostram o efeito da atualização neste cluster de 60 nós de dados.
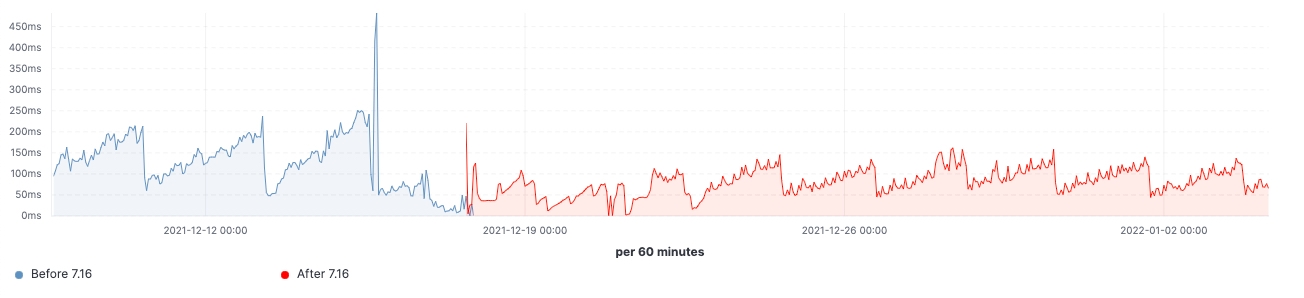
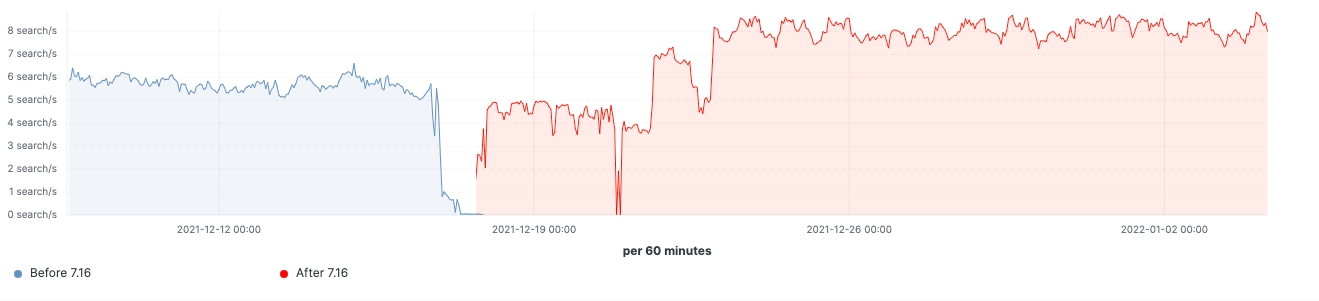
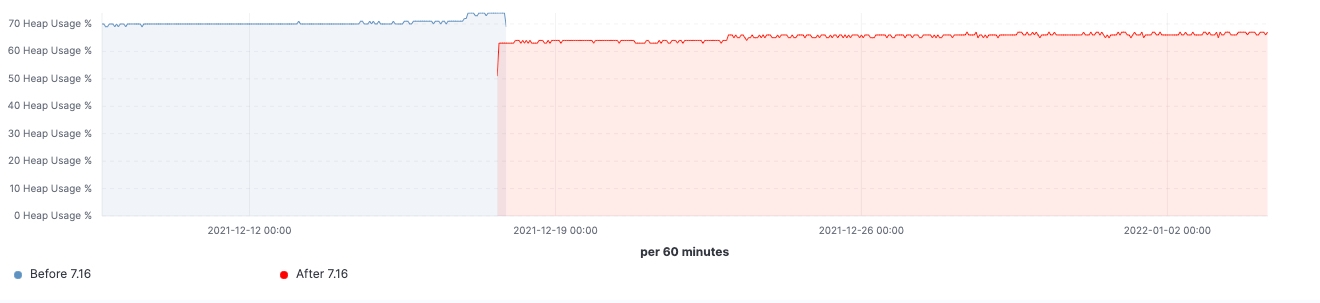
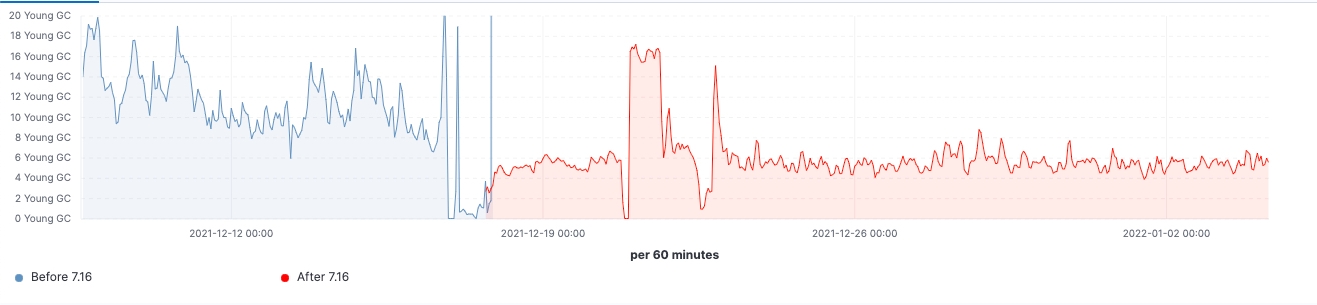
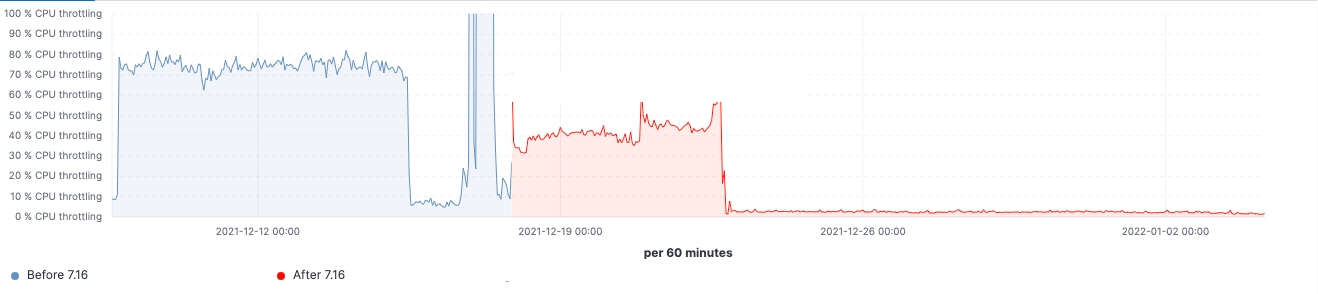
Para esse cluster, podemos observar uma carga de trabalho consistente antes e depois da atualização, mas o 99º percentil da latência de busca foi reduzido uniformemente, a taxa de busca (taxa de transferência) foi aumentada e a utilização de heap em nós frozen é consistentemente menor como resultado da redução da ocupação da memória no armazenamento da estrutura de dados. Espera-se que isso tenha um impacto em todas as camadas de dados; no entanto, seria mais proeminente na camada frozen, onde o heap é usado principalmente para armazenar a estrutura de dados, diferentemente dos nós hot, onde o heap pode ser usado para indexação, consulta e outras atividades. Dividindo por funções de nó, os nós coordenadores estão tendo a redução mais notável nas contagens de GC jovem graças à redução das solicitações de shards na fase pre-filter. Por fim, com melhorias no gerenciamento de estado do cluster, a demanda por estrangulamento da CPU nos nós master é bastante reduzida.
Investigamos os motivos pelos quais o Elasticsearch estava tendo problemas de desempenho ao redimensionar para dezenas de milhares de shards e buscamos melhorias de escalabilidade no Elasticsearch 7.16. Ter um zilhão de shards e mapear explosões são os principais fatores conhecidos por travar o Elasticsearch, portanto, ainda devem ser evitados. Entretanto, com as melhorias na versão 7.16, espera-se que o impacto seja muito menor. Nesta versão, as melhorias se concentraram no tamanho geral do cluster, possibilitando que um master menor lide com as atualizações de estado do cluster e agilizando a coordenação da busca em um grande número de índices.
Com a potência do Elasticsearch na versão 7.16, seu mecanismo de busca agora é mais rápido, a memória é menos exigente e a estabilidade do cluster é reforçada — e tudo o que você precisa fazer é atualizar! Continuamos a melhorar vários aspectos na parte da escalabilidade e compartilharemos mais conquistas que virão na versão 8.x.
Pronto(a) para alçar voos mais altos?
Quem já trabalha com o Elastic Cloud pode acessar muitos desses recursos diretamente no console Elastic Cloud. Se você está começando agora no Elastic Cloud, dê uma olhada em nossos guias Quick Start (pequenos vídeos de treinamento para você começar rapidamente) ou nossos cursos gratuitos de treinamento sobre fundamentos. Você pode começar gratuitamente com uma avaliação gratuita do Elastic Cloud por 14 dias. Ou baixe a versão autogerenciada do Elastic Stack também gratuitamente.
Leia sobre essas funcionalidades e muito mais nas notas de lançamento do Elastic 7.16 e outros destaques do Elastic Stack no post de anúncio do Elastic 7.16.Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir