Monitoramento do Prometheus em escala com o Elastic Stack
Ferramentas. Sendo engenheiros, todos nós gostamos de ótimas ferramentas que ajudem nossas equipes a trabalhar produtivamente, resolver problemas mais rapidamente e melhorar. Mas as ferramentas podem tender a crescer em número, exigir manutenção adicional e, o mais importante, criar silos. Cada equipe tem certas responsabilidades e está constantemente procurando ferramentas que possam atender a requisitos específicos da melhor maneira possível. Como resultado, as equipes se tornam eficientes enquanto unidade, mas o subproduto dessa autonomia com desempenho é a falta de insight sobre outras partes da organização. Multiplique isso pelo número de equipes e você verá rapidamente clusters isolados que descartam uma visão holística do desempenho de seus negócios.
O Prometheus é um ótimo exemplo dessa ferramenta. Ele cresceu rapidamente e se tornou a ferramenta principal para monitoramento e alerta de sistemas de containers. Sua principal força reside no monitoramento e armazenamento eficientes de métricas do lado do servidor. O Prometheus é totalmente open source e conta com uma comunidade vibrante que estende sua cobertura a muitos sistemas de terceiros, na forma de exportadores. Como a maioria das ferramentas especializadas, o Prometheus pretende ser simples e fácil de operar. Essa simplicidade vem à custa de compensações particularmente relevantes nos casos de implantações em larga escala e colaboração entre equipes. Neste blog, examinaremos algumas dessas compensações e veremos como o Elastic Stack pode ajudar a resolvê-las.
Retenção de dados de longo prazo
O Prometheus armazena dados localmente na instância. Ter computação e armazenamento de dados em um único nó pode facilitar a operação, mas também torna mais difícil ampliar e assegurar alta disponibilidade. Como consequência, o Prometheus não é otimizado para ser um armazenamento de métricas de longo prazo. Dependendo do tamanho do seu ambiente, sua taxa de retenção ideal para séries temporais no Prometheus pode ser curta, com duração de alguns dias ou até horas.
Para reter os dados do Prometheus de maneira escalável e durável para análises estendidas (por exemplo, sazonalidade de séries temporais), você precisará complementar o Prometheus com uma solução de armazenamento de longo prazo. E há muitas soluções para escolher, como outros TSDBs especializados ou bancos de dados colunares otimizados para séries temporais. Essas soluções, embora sejam eficientes para armazenar métricas, têm uma desvantagem em comum: são especializadas em apenas um tipo de dados — métricas. As métricas são extremamente importantes para ajudar a entender como seus sistemas estão se comportando; no entanto, elas representam apenas uma parte do que torna os sistemas observáveis.
Quando os usuários pensam na observabilidade, tentam combinar outros tipos de dados operacionais, como logs e rastreamentos, com as métricas. Em nosso blog sobre observabilidade no Elastic Stack, falamos sobre um número crescente de casos de uso nos quais os usuários que adotaram o Elastic Stack para logs também começaram a colocar métricas, rastreamentos e dados de tempo de funcionamento no Elasticsearch. E não é de se admirar: o Elasticsearch trata todos esses tipos de dados como apenas mais um índice e lhe permite agregar, correlacionar, analisar e visualizar todos os seus dados operacionais da maneira que desejar. Recursos como rollups de dados na Elastic tornam possível armazenar dados históricos de série temporal por uma fração do custo de armazenamento de dados brutos.
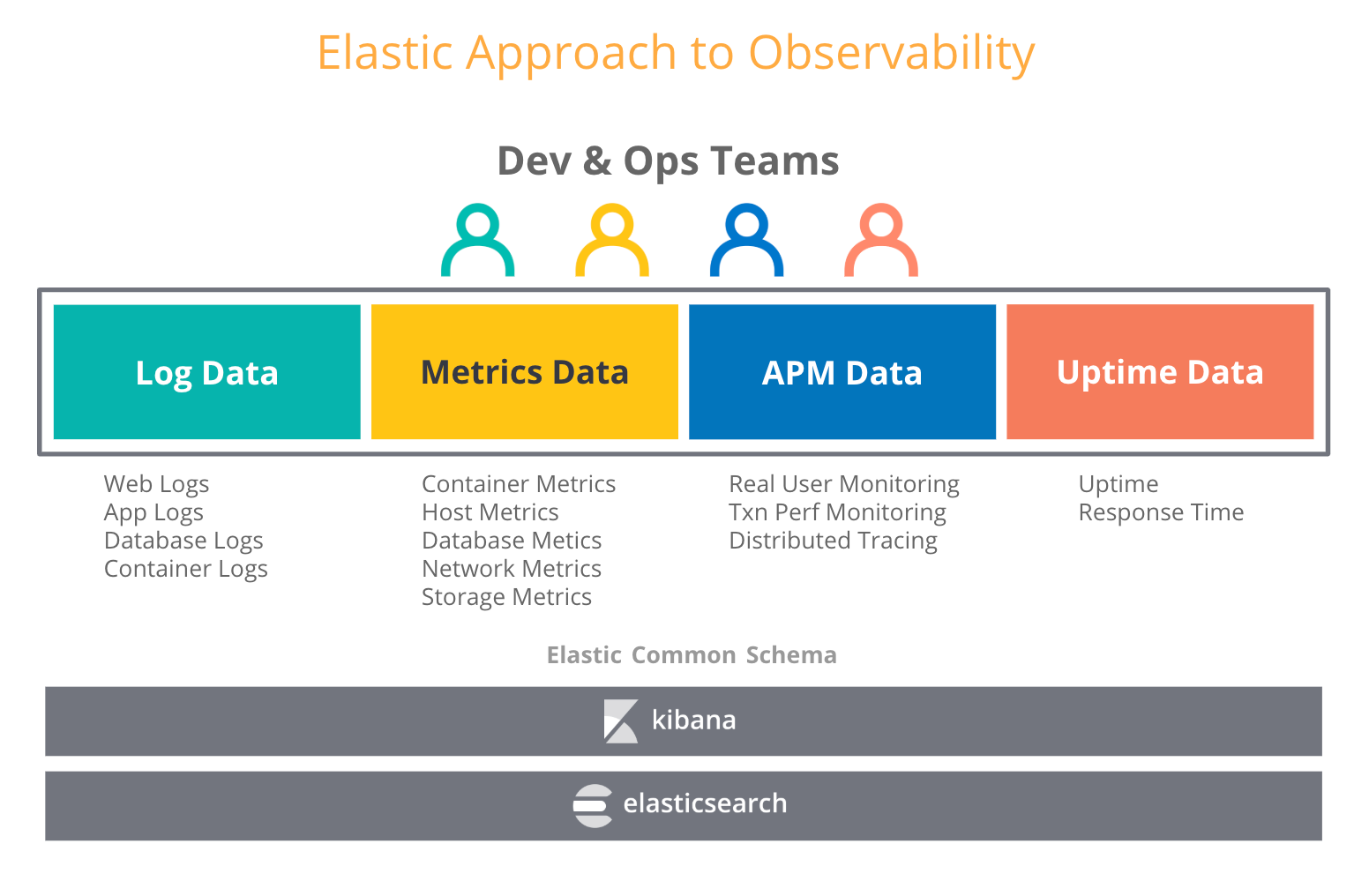
Então, o que isso significa para a escolha de um armazenamento de longo prazo para o Prometheus? Você pode escolher um armazenamento de métricas dedicado para obter taxas de retenção mais longas para as métricas do Prometheus e, possivelmente, criar outro silo. Ou, com o Elastic Stack, você pode combinar o melhor dos dois mundos: executar o Prometheus na borda e reter as métricas pelo tempo que desejar, juntamente com outros dados operacionais em uma implantação escalável e centralizada do Elasticsearch. Isso significa armazenamento de longo prazo e maior observabilidade.
Visão global centralizada dos dados do Prometheus
Em uma configuração de produção, você provavelmente está gerenciando vários clusters do Kubernetes. Cada cluster executa uma ou mais instâncias do Prometheus que podem ver a integridade dos nós, pods, serviços e endpoints. Falta alguma coisa?
Uma instância do Prometheus pode abranger um subconjunto de recursos no seu ambiente. Se você quiser fazer uma pergunta que exija a consulta de métricas de vários clusters, não haverá uma maneira direta de fazer isso com o Prometheus.

O uso da Elastic como um armazenamento centralizado pode ajudar você a consolidar dados de centenas de instâncias do Prometheus e obter uma visão global dos dados provenientes de todos os recursos. O módulo de Prometheus para Metricbeat pode extrair automaticamente métricas de instâncias, gateways push e exportadores do Prometheus, bem como de praticamente qualquer outro serviço que seja compatível com o formato de exposição do Prometheus. A melhor parte é que você não precisa alterar nada no seu ambiente de produção — é puro plug-and-play.
Dimensões de alta cardinalidade
Por que a “alta cardinalidade” é importante? A alta cardinalidade permite adicionar contexto arbitrário às suas métricas como tags ou rótulos. Na maioria dos casos, você quer reter esses metadados, pois eles podem ser incrivelmente úteis na depuração dos seus serviços. Todos esses IDs de rastreamento, IDs de solicitação, IDs de container e números de versões, entre outros, sempre fornecerão mais informações sobre o que está acontecendo nos seus sistemas.

TSDBs puros são bons em lidar com dimensões de baixa cardinalidade. A eficiência de armazenamento declarada que os TSDBs especializados têm sobre o Elasticsearch depende muito de dimensões de baixa cardinalidade. A documentação do Prometheus desestimula fortemente o uso de dados de alta cardinalidade:
CUIDADO: lembre-se de que toda combinação exclusiva de pares de rótulos de chave-valor representa uma nova série temporal, que pode aumentar drasticamente a quantidade de dados armazenados. Não use rótulos para armazenar dimensões com alta cardinalidade (muitos valores de rótulos diferentes), como IDs de usuário, endereços de e-mail ou outros conjuntos de valores não delimitados.
É realmente um bom conselho? Em um ambiente distribuído, a depuração é uma tarefa muito complexa. Anteriormente, com monólitos, a depuração era um processo simples no qual se percorria o código da aplicação. Era possível identificar facilmente qual módulo monolítico era o culpado de ter causado o problema observando alguns dashboards. Esse não é mais o caso. O software de infraestrutura está no meio de uma mudança de paradigma. Containers, orquestradores, microsserviços, malhas de serviço, sem servidor, lambdas — todas essas são tecnologias incrivelmente promissoras que mudam a maneira como construímos e operamos o software. Consequentemente, ele se torna mais distribuído, e a depuração pode ser comparada a um trabalho de detetive, no qual é necessário descobrir onde no sistema está o código com o problema.
A alta cardinalidade não é um problema para a Elastic. Nada deve restringir os usuários de adicionar contexto relevante a seus dados. Graças aos seus recursos de indexação, o Elasticsearch pode permitir que os usuários anotem as métricas da forma que desejarem, com qualquer metadado que possa ajudar a encontrar fatores de contribuição para ajudar a identificar a causa raiz no menor tempo possível.
Segurança. Em toda parte.
Uma das coisas que esperamos das boas ferramentas é que elas não introduzam riscos de segurança em nossos ambientes. Dois elementos fundamentais de segurança em qualquer implantação distribuída são a comunicação criptografada e o controle de acesso.
Na ocasião em que este artigo foi escrito, o servidor, o Alertmanager e os exportadores oficiais do Prometheus não ofereciam suporte à criptografia TLS dos endpoints HTTP. Para implantar esses componentes de maneira segura, você precisará usar um proxy reverso como o nginx e aplicar a criptografia TLS na camada de proxy. Qualquer controle de acesso baseado em função (RBAC) para métricas também deverá ser tratado externamente, e não pelo próprio servidor Prometheus. A boa notícia é que o TLS e o RBAC não são um problema se você está executando o Prometheus dentro de um cluster do Kubernetes, pois ele fornece os dois. Em todos os outros casos (por exemplo, executar centenas de servidores Prometheus em implantações geograficamente distribuídas ou híbridas), lidar com essas preocupações de segurança com ferramentas de terceiros não é uma tarefa trivial.
Na Elastic, levamos esses riscos muito a sério, e a segurança é parte integrante da nossa pilha. Opções básicas de segurança fazem parte da nossa distribuição padrão gratuitamente, e o Elasticsearch fornece várias maneiras de proteger o acesso aos seus dados em um cluster, além de criptografar o tráfego entre o cluster e os shippers de dados. Além do RBAC, o Elasticsearch oferece suporte para o mecanismo de controle refinado de acesso baseado em atributo (ABAC), que permite restringir o acesso a documentos em agregações e consultas de busca. Com as definições de configuração SSL no Metricbeat, você pode garantir que seus dados operacionais trafeguem com segurança, independentemente do tamanho e da distribuição dos seus ambientes.
Envio de métricas do Prometheus para o Elasticsearch
Você já pode começar a enviar as métricas do Prometheus para o Elasticsearch com o Metricbeat. Usando o módulo do Prometheus, você pode extrair métricas dos servidores, exportadores ou gateways push do Prometheus de várias maneiras:
- Se você já está executando o servidor Prometheus e deseja consultar essas métricas diretamente, pode começar se conectando ao servidor Prometheus e obtendo as métricas já coletadas usando o endpoint
/metricsou a API de federação do Prometheus.
- Se você não tem um servidor Prometheus ou não se importa de ter seus exportadores e gateways push explorados em paralelo por várias ferramentas, você pode se conectar a eles diretamente.

Execute o Metricbeat o mais próximo possível do seu servidor Prometheus. Você pode escolher uma configuração que melhor atenda às suas necessidades no nosso blog sobre Prometheus e padrões abertos.
De olho na integridade dos seus servidores Prometheus
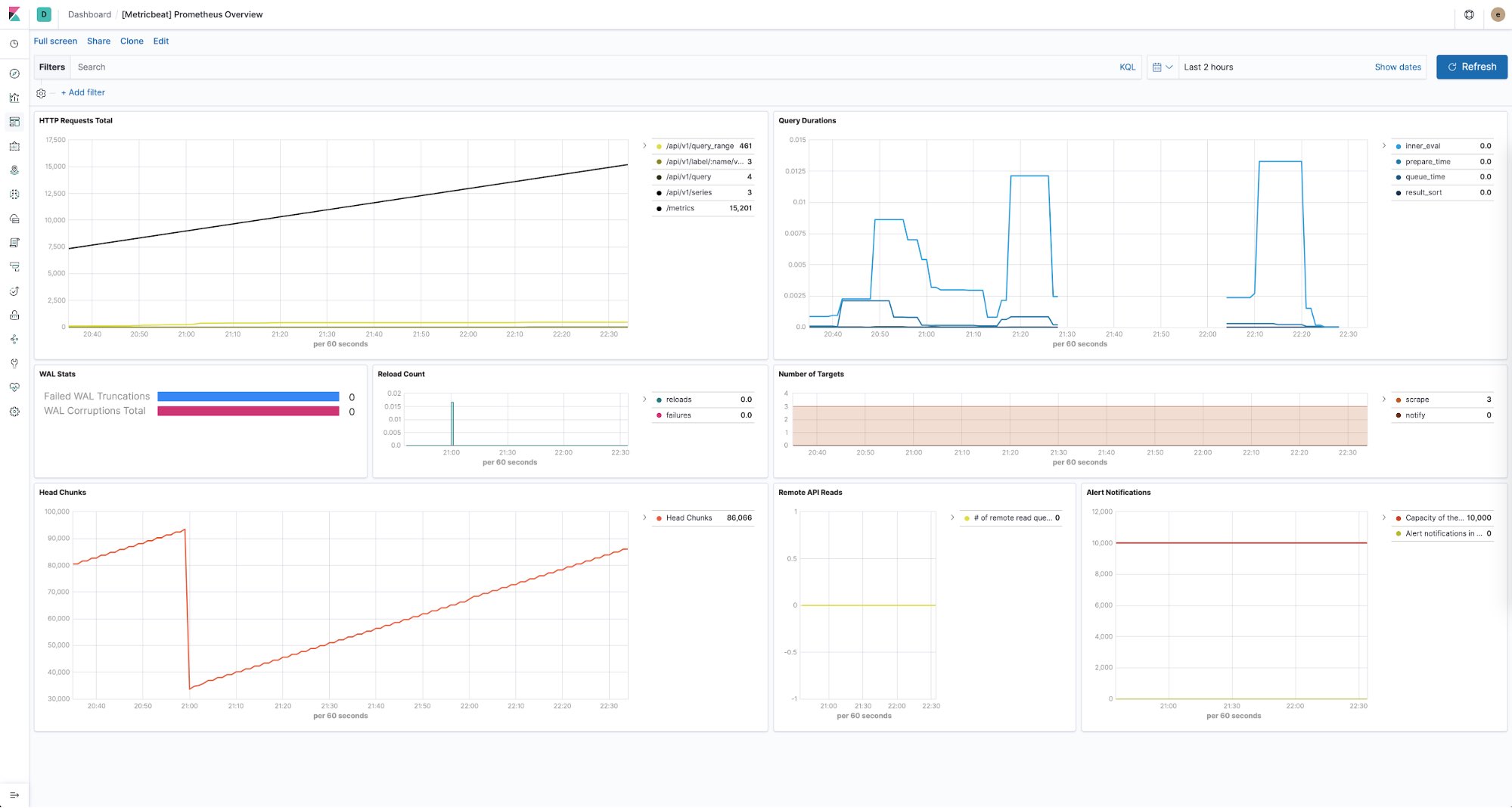
O Elastic Stack também fornece uma maneira de monitorar a integridade de todas as suas instâncias do Prometheus. Você pode usar o Metricbeat para coletar e armazenar métricas de desempenho de cada servidor Prometheus em seus ambientes. Com dashboards predefinidos prontos para uso, é possível ver facilmente itens como o número de solicitações HTTP por endpoint, duração das consultas, número de destinos descobertos e muito mais.
Levando tudo em consideração
No final das contas, o objetivo é que você, sua equipe e toda a sua organização sejam bem-sucedidos. Todas as ferramentas devem ser vistas como um meio para atingir um fim. Cada equipe deve ser livre para escolher o que a ajuda a alcançar seu pleno potencial. E quando se trata de quebrar os silos operacionais, acreditamos que o Elastic Stack pode ajudar a criar a melhor plataforma de observabilidade, onde todos na sua organização possam acessar dados operacionais com segurança, interagir com eles e ser uma equipe novamente.
Você pode saber mais sobre como trabalhamos com dados de série temporal na nossa página da Web do Elastic Metrics. Experimente enviar suas métricas para o Elasticsearch Service — é a maneira mais fácil e rápida de começar. Se tiver alguma dúvida, fique à vontade para nos contatar em nossos fóruns de discussão.