Observabilidade com o Elastic Stack
Em minha função como Líder de Produto para Observabilidade na Elastic, recebo muitas reações diferentes quando uso o termo 'observabilidade'. A reação mais comum de longe ainda é: "O que é 'Observabilidade'?" Mas cada vez mais também ouço comentários do tipo: "Acabamos de dar início a uma 'iniciativa de observabilidade, mas ainda estamos imaginando exatamente como lidar com isso." E por fim algumas organizações com as quais tivemos a felicidade de trabalhar já consideram a 'observabilidade' uma parte integrante de como elas projetam e criam produtos e serviços.
Considerando que o termo ainda está se firmando, achei que seria útil desmistificar a maneira como nós na Elastic enxergamos a 'observabilidade', o que aprendemos com nossos clientes formadores de opinião e como pensamos a respeito do ponto de vista do produto à medida que evoluímos nossos recursos para casos de uso operacionais.
O que é 'Observabilidade'?
Com certeza não inventamos o termo 'observabilidade'. Começamos a ouvir pelos usuários, principalmente aqueles da comunidade SRE (Engenharia de confiabilidade de sites). Várias fontes remontam a origem desse termo às organizações SRE de gigantes do vale do Silício como o Twitter. E apesar de o inspirador Google SRE Book não mencionar o termo, ele estrutura muitos dos princípios associados à 'observabilidade' hoje.
'Observabilidade' não é algo que um fornecedor entrega prontinho -- ela é um atributo de um sistema que você cria, muito parecido com a usabilidade, a alta disponibilidade e a estabilidade. A meta de projetar e criar um sistema 'observável' é garantir que, ao ser colocado em produção, os operadores responsáveis por ele possam detectar comportamentos indesejáveis (p. ex.: inatividade do sistema, erros, respostas lentas) e ter informações produtivas para identificar a causa principal de maneira eficaz (p. ex.: logs de evento detalhados, informações de uso de recursos granulares e rastros de aplicativos). Os desafios comuns que impedem as organizações de alcançar essas metas aparentemente óbvias são não coletar informações suficientes, coletar informações excessivas porém não torná-las produtivas e fragmentar o acesso a essas informações.
O primeiro aspecto — detecção de comportamentos indesejáveis — normalmente começa com a configuração de SLIs (Indicadores de nível de serviço) e SLOs (Objetivos de nível de serviço). Elas são medidas internas de sucesso pelas quais os sistemas de produção são julgados nas organizações sensíveis à observabilidade. Se houver uma obrigação contratual para cumprir esses objetivos, um SLI/SLO também poderá se converter em SLA (Acordo de nível de serviço). O exemplo mais comum de um SLI é a atividade do sistema, para a qual você pode definir um SLO de 99,9999%. A atividade do sistema também é o SLA mais comum exposta a clientes externos. Entretanto, os SLI/SLOs podem ser internamente muito mais granulares, e o monitoramento e alerta sobre esses fatores mais importantes do comportamento do sistema de produção é a base de qualquer iniciativa de observabilidade. Esse aspecto da observabilidade também é conhecido pelo termo "monitoramento".
O segundo aspecto — fornecer operadores com informações granulares para depurar problemas de produção de maneira rápida e eficiente — é uma área em que vemos muito movimento e inovação. Existe muita conversa sobre os "três pilares da observabilidade" — métrica, logs e rastros de aplicativo. Também há o reconhecimento de que meramente coletar todos esses dados granulares usando um remendo de ferramentas não é necessariamente produtivo e geralmente não é econômico.
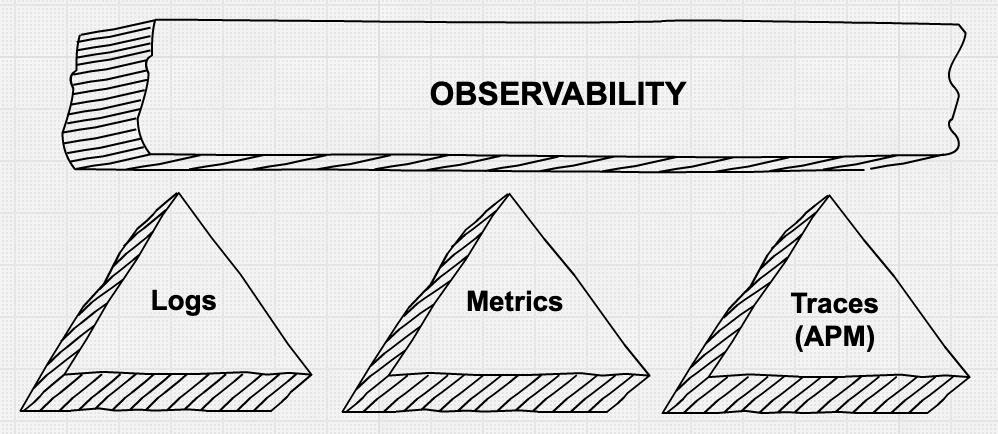
'Pilares' da observabilidade
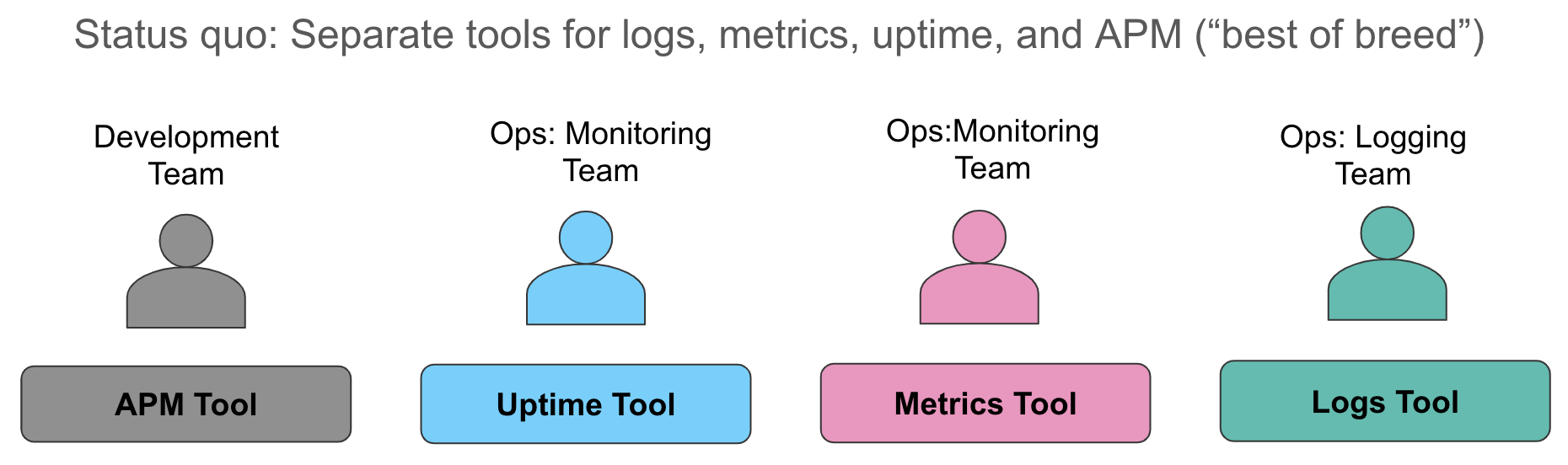
Vamos examinar esses aspectos da coleta de dados em mais detalhes. O status quo que normalmente encontramos hoje é coletar métricas para um sistema (normalmente um banco de dados de séries de tempo ou um serviço SaaS para monitoramento de recursos), coletar logs em um segundo sistema (não é de surpreender que sejam os recursos do ELK em nossas conversas) e usar ainda uma terceira ferramenta para instrumentar os aplicativos para fornecer rastro no nível da solicitação. Quando um alerta dispara, indicando uma violação em um nível de serviço, os operadores saem como loucos atrás dos sistemas e fazem a melhor integração possível -- olhando as métricas em uma janela de navegador, correlacionando-as manualmente com logs em outra janela e obtendo os rastros (se relevantes) em uma terceira janela.
Essa abordagem tem vários problemas. Primeiro, a correlação manual de diferentes fontes de dados todas com as mesmas informações desperdiça tempo valioso durante a degradação ou falha do serviço. Segundo, os custos operacionais de manter três diferentes armazenamentos de dados operacionais são onerosos — custos de licenciamento, efetivo separado para administradores de ferramentas operacionais distintas, recursos de aprendizado de máquina inconsistentes em cada armazenamento de dados, "espaço" para pensar por meio de diferentes semânticas para alertas — cada organização com quem falo enfrenta todos esses desafios.
Há um reconhecimento cada vez maior da importância de ter todas essas informações em um único armazenamento operacional com a capacidade de correlacionar automaticamente esses dados em uma interface de usuário intuitiva. O sonho dos usuários com quem falamos é expor seus operadores a cada dado relevante ao serviço ao qual oferecem suporte de maneira unificada, seja uma linha de log emitida pelo aplicativo, dados de rastro resultantes de instrumentação ou utilização de recursos representada pela métrica em uma série de tempo. Os requisitos que ouvimos falar enfatizam acesso uniforme e específico a esses dados, independentemente da fonte, incluindo pesquisa, filtragem, agregações e visualizações. Começar com a métrica e detalhar até logs e rastros em alguns cliques sem mudar o contexto acelera as investigações. Da mesma maneira, extrair valores numéricos de logs estruturados parece surpreendentemente como métrica e visualizar ambos lado a lado oferece um valor imensurável de uma perspectiva operacional.
Como mencionado acima, meramente coletar os dados pode resultar em excesso de informações em disco e inteligência produtiva insuficiente quando ocorre um incidente. Cada vez mais, há uma expectativa de que o sistema que coleta dados operacionais ofereça detecção automática de eventos, rastros e anomalias "interessantes" nos padrões de séries de tempo. Isso ajuda os operadores que investigam um problema a se concentrarem na causa principal mais rapidamente. Esses recursos de detecção de anomalias às vezes são chamados de "quarto pilar da observabilidade". A detecção de anomalias em dados de atividade, utilização de recursos, anomalias em padrões de log e rastros mais relevantes é um requisito emergente que as equipes de observabilidade propõem.
A observabilidade... e o ELK Stack?
Então o que a observabilidade tem a ver com o Elastic Stack (ou ELK Stack, como é carinhosamente chamado nos meios operacionais)?
O ELK Stack é amplamente conhecido como o verdadeiro método para centralizar logs a partir de sistemas operacionais. A suposição é que o Elasticsearch (um "motor de pesquisa") é um ótimo lugar para colocar logs baseados em texto para as finalidades de pesquisa de texto livre. E realmente a mera pesquisa em logs baseados em texto pela palavra "erro" ou a filtragem de logs com base em um conjunto de marcas bem conhecidas é extremamente poderosa e normalmente é o ponto de partida da maioria dos usuários.
Entretanto, como sabe a maioria dos usuários do ELK Stack, o Elasticsearch como armazenamento de dados oferece muito mais do que um índice invertido para a pesquisa de texto completo eficiente e capacidades de filtragem simples. Ele também contém um armazenamento colunar otimizado para armazenar e operar em séries de tempo numéricas. Esse armazenamento colunar é usado para armazenar dados de estrutura extraídos de logs analisados, tanto de sequência de caracteres quanto numéricos. Na verdade, o caso de uso de converter logs em métricas é o que inicialmente nos levou a otimizar o Elasticsearch para um armazenamento e recuperação eficientes de números.
Com o tempo, os usuários começaram a colocar séries de tempo numéricas diretamente no Elasticsearch, substituindo os bancos de dados de séries de tempo herdados. Levada por essa necessidade, a Elastic lançou recentemente o Metricbeat para a coleta automatizada de métricas, o conceito dos rollups automáticos e outras funcionalidades específicas de métricas tanto no armazenamento de dados quanto na interface de usuário. Consequentemente, cada vez mais usuários que adotaram o ELK Stack para logs, também começaram a inserir dados de métricas, como a utilização de recursos, no Elastic Stack. Além das economias operacionais já mencionadas acima, um motivo atraente para isso foi a falta de restrições que o Elasticsearch coloca na cardinalidade de campos elegíveis para agregações numéricas (uma reclamação comum ao discutir muitos bancos de dados de séries de tempo existentes).
Semelhantes à métrica, os dados de atividade são um tipo altamente valorizado de dados juntamente com os logs, representando uma fonte importante de alertas SLO/SLI de um monitor ativo. Os dados de atividade podem fornecer informações sobre degradação de serviços, APIs e sites, geralmente antes de os usuários sentirem o impacto. O bônus é que os dados de atividade são pequenos em termos de requisitos de armazenamento, portanto um grande valor por um custo adicional muito baixo.
No ano passado, a Elastic também lançou o Elastic APM, adicionando recursos de rastro de aplicativos e de rastro distribuído aos recursos. Essa foi uma evolução natural para nós, à medida que vários projetos de código-fonte aberto e fornecedores APM destacados já estavam usando o Elasticsearch para armazenar e pesquisar dados de rastro. O status quo nas ferramentas de APM tradicionais é manter os dados de rastro de APM separados dos logs e métricas, perpetuando os silos de dados operacionais. O Elastic APM oferece um conjunto de agentes para coletar dados de rastro das linguagens e estruturas compatíveis, além de oferecer suporte ao OpenTracing, e esses dados de rastro são correlacionados automaticamente às métricas e aos logs.
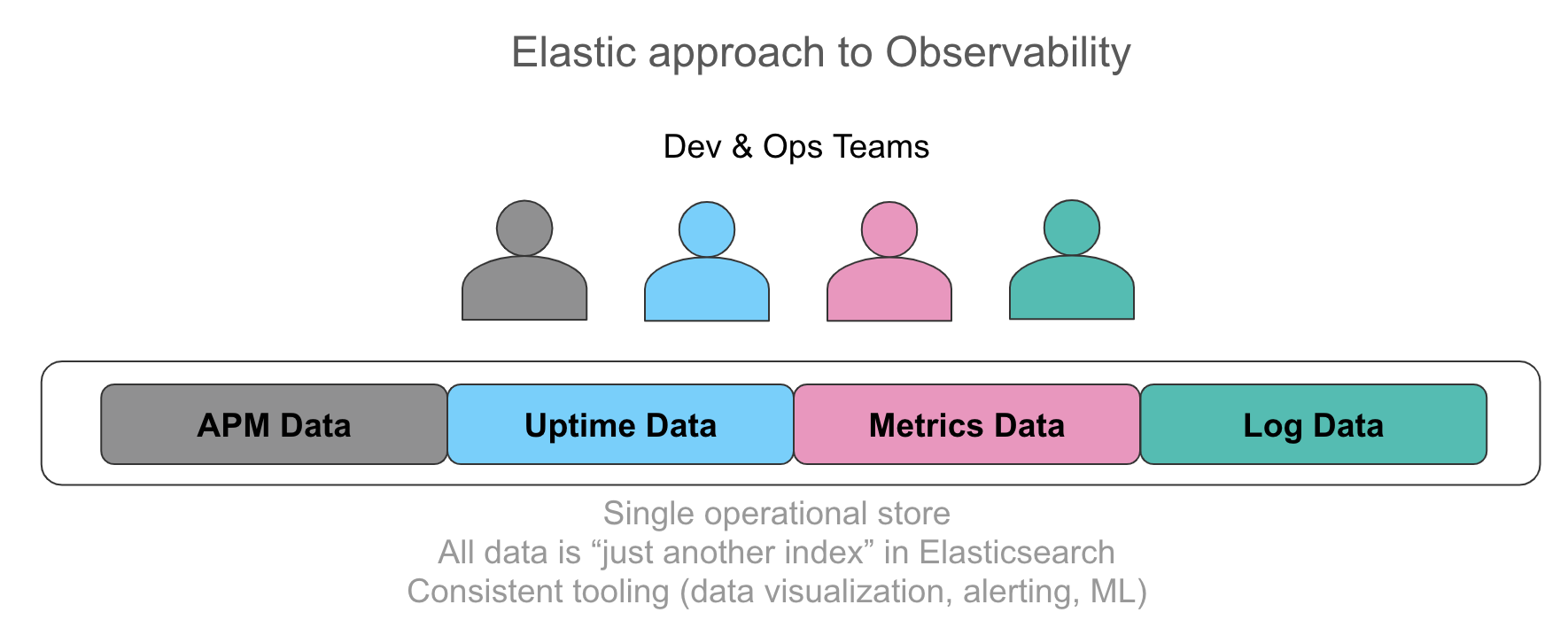
Um thread comum em todas essas entradas de dados é que cada uma delas é apenas outro índice no Elasticsearch. Não há restrições nas agregações que você executa em todos esses dados, como você os visualiza no Kibana e como os alertas e o aprendizado de máquina se aplicam a cada fonte de dados. Para ver isso em ação, confira este vídeo.
Kubernetes observável e o Elastic Stack
Uma comunidade em que o conceito da observabilidade é um tópico bastante ativo de conversas é o conjunto de usuários que adotam o Kubernetes para orquestração de containers. Esses usuários "nativos da nuvem", um termo popularizado pela Cloud Native Computing Foundation (ou CNCF), enfrentam desafios exclusivos. Eles encaram uma centralização em massa de aplicativos e serviços desenvolvidos sobre ou migrados para uma plataforma de orquestração de containers baseada em Kubernetes, aliada à tendência de dividir aplicativos monolíticos em "microsserviços". As ferramentas e os métodos que funcionavam antes para proporcionar a visibilidade necessária dos aplicativos executados sobre essa infraestrutura não funcionam mais.
A observabilidade do Kubernetes merece uma postagem separada toda especial, então por enquanto recomendo que você participe do webinar Observable Kubernetes e leia a postagem de blog Distributed Tracing with Elastic APM para obter mais informações.
E o que vem em seguida?
Em uma postagem como essa, parece apropriado deixar o leitor com alguns recursos para explorar.
Para saber mais sobre práticas recomendadas de observabilidade, recomendo começar com o Google SRE Book mencionado anteriormente. Postagens de blog de empresas cuja sobrevivência depende da operação infalível de seus aplicativos cruciais em produção normalmente também são instigantes. Por exemplo, eu considero esta postagem recente da engenharia da Salesforce um guia pragmático e prático para melhorar cada vez mais o estado da observabilidade.
Teste os recursos do Elastic Stack para suas iniciativas de observabilidade, execute a versão mais recente dos nossos recursos no Elasticsearch Service no Elastic Cloud (ótimo sandbox mesmo se você por fim implantar como autogerenciado) ou faça download e instalação dos componentes do Elastic Stack localmente. Confira as novas interfaces de usuário Logs, Infrastructure monitoring, APM e Uptime (em breve na versão 6.7) no Kibana, criados especialmente para fluxos de trabalho de observabilidade comuns. E faça perguntas nos fóruns de discussão — estamos prontos para ajudá-lo!