Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
I’ve spent the last several weekends in the fascinating world of “prompt engineering” and learning how vector databases like Elasticsearch can supercharge large language models (LLMs) like ChatGPT by acting as long-term memory and a semantic knowledge store. However, one thing that has troubled me — and many other experienced data architects — is that so many of the tutorials and demos out there are wholly dependent on sending large web companies and cloud based AI companies your private data.
Private data comes in many forms and is protected for more than one reason. For startups and enterprise companies alike know their private data is sometimes their competitive advantage. Internal data and customer data often has personally identifiable information which has both legal and real world human consequences if not protected. In the Observability and Security domains, lack of caution utilizing third party services can be the source of data breaches. We’ve even heard allegations of cybersecurity breaches that have been tied to use of AI chat tools.
No design is risk free or fully private, even when working with companies like Elastic that have made strong commitments to privacy and security or making deployments that are in a true air gap. However, I’ve worked with enough sensitive data use cases to know there is very real value in enabling AI search with a privacy-first approach. I loved my colleague Jeff Vestal’s excellent walkthrough of using OpenAI tools with Elasticsearch, but this article will take a different approach.
I have two goals for the approach of this project:
- Private — When I say private, I mean it. While I’ll use cloud hosted Elasticsearch, should the use case demand it, I want this to work fully air-gapped. Let’s prove that we can get AI search working without sending our private knowledge to third parties.
- Fun — Also, let’s have some fun while we do it. We’ll use a scrape of Wookieepedia, a community Star Wars wiki popular in data science exercises, and make a private AI trivia helper. It was nearing May the 4th as I was writing this, and although we’re past that date now at the time of this post publishing, my fandom is year-round.
The easiest way to follow along and try it yourself is to spin up an Elasticsearch instance on Elastic Cloud and run through the provided Python notebook, which will implement the project at a small scale. If you’d like to run the full Wookieepedia scrape of 180K paragraphs of Star Wars knowledge and create a well versed Star Wars knowledge search, you can follow the code in the GitHub repository here.
When it’s all done, it should look like this:
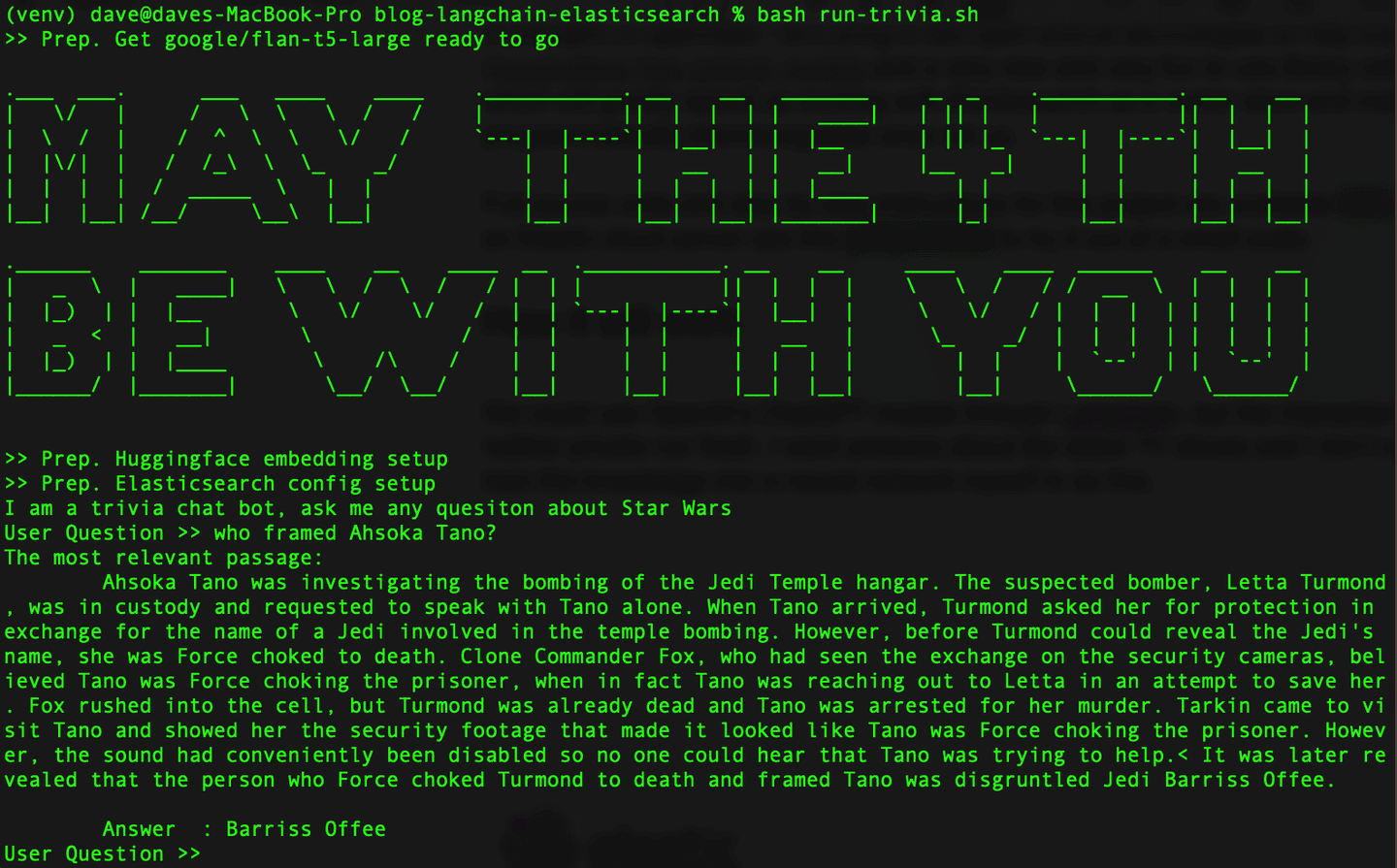
In the spirit of openness, let’s bring in two open source technologies to help Elasticsearch: Hugging Face transformers library and the new and fun to use Python library called LangChain, which will speed up working with Elasticsearch as a vector database. As a bonus, LangChain will make our LLMs programmatically interchangeable once they are set up, so that we’re free to experiment with various models.
How it will work
What is LangChain? LangChain is a Python and JavaScript framework for developing applications powered by large language models. LangChain will work with OpenAI’s APIs, but it also excels at abstracting away the differences between databases and AI tools.
On its own, ChatGPT is not bad at Star Wars trivia. However, its training data set is now several years old and we want answers about the latest TV shows and events in the Star Wars universe. Also remember that we are pretending this data is too private to share with a big LLM in the cloud. We could tune a large language model ourselves with more recent data, but there is a much easier way to get this done that also allows us to always use the freshest data available.
Today let’s bring in a smaller and easy to self-host LLM. I got good results with Google’s flan-t5-large model, which makes up for its lack of training with a good ability to parse out answers from injected context. We’ll use semantic search to retrieve our private knowledge and then inject that context with a question to our private LLM.
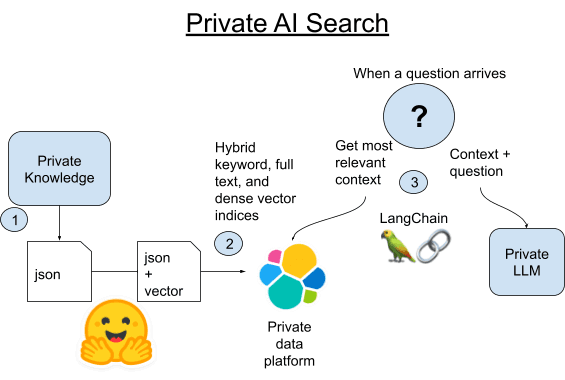
- Scrape all canon articles from Wookieepedia putting the data in staged Python Pickle files.
2A. Load each paragraph of those articles into Elasticsearch using LangChain’s built-in Vectorstore library.
2B. Alternatively, we can compare LangChain with the new way of hosting pytorch transformers in Elasticsearch itself. We’ll deploy the text embedding model to Elasticsearch to leverage distributed compute and speed up the process.
- When a question comes in, we’ll find the most semantically similar paragraph to the question using Elasticsearch’s vector search. We’ll then take that paragraph and add it to the prompt of a small, local LLM as context to the question and then leave it to the magic of generative AI to get a short answer to our trivia question.
Setting up the Python and Elasticsearch environment
Make sure you have Python 3.9 or similar on your machine. I use 3.9 for easier library compatibility with GPU acceleration, but that won’t be necessary for this project. Any recent 3.X version of Python will work.
If you’ve downloaded the sample code, you can just pull the exact versions of the code I was using with the following pip install command instead.
You can set up an Elasticsearch cluster following instructions here. The free cloud trial is the easiest way to get started.
Make a .env file in the folder and load up your connection details for Elasticsearch.
Step 1. Scraping the data
The code repo has a small data set at Dataset/starwars_small_sample_data.pickle. You can skip this step if you are okay working at a small scale.
The scraping code is adapted from Dennis Bakhuis’s excellent data science blog and project — check it out! He only pulls the first paragraph of each article, and I’ve changed the code to pull it all. He may have needed to keep the data at a size that fit in primary memory, but we don’t have that problem because we have Elasticsearch, which would enable this to scale well into the petabyte range.
You could also very easily plug in your own private data source here. LangChain has some excellent utility libraries for splitting up your text data into shorter chunks.
Scraping isn’t the focus of this article, so check out the Python notebook if you want to run it yourself at a small scale, or download the source code and run like this:
When you are done, you should be able to go through the saved Pickle files like this to make sure it worked.
If you skipped web scraping, just change the bookFilePath to “starwars_small_sample_data.pickle” to use the sample that I included in the GitHub repo.
Step 2A. Loading embeddings in Elasticsearch
The full code shows how I do this with just LangChain. The key part of the code is looping through the saved Pickle files like the above example and extracting out a list of strings that are the paragraphs, and then handing them to the from_texts() function of the LangChain Vectorstore.
Step 2B. Saving time and money with Hosted Trained Models
I found that on my older Intel Macbook, creating embeddings would require many hours of processing. I’m being kind — it was looking like multiple days. I think I can do it faster and for less money using the dynamically scalable machine learning (ML) nodes of Elastic’s hosted service. The free trial clusters won’t let you scale that tier, so this step may make more sense for some than others.
The final result: this approach took 40 minutes on nodes that cost $5/hr to run in Elastic Cloud, which is much faster than what I can do locally and on par with the cost of processing embeddings with OpenAI’s current token charges. Doing this efficiently is a larger topic, but I’m impressed by how quickly I could get a parallel inference pipeline working in Elastic Cloud without having to learn new skills or hand my data to a non-private API.
For this step, we are going to offload embedding generation to the Elasticsearch cluster itself, which can host the embedding model and embed the paragraphs of text in a distributed fashion. To do this, we’ll have to load data and use ingest pipelines to make sure the final form matches the index mapping that LangChain uses. Run the following REST command in Kibana’s Dev Tools:
Next, we’ll upload the embedding model to Elasticsearch using the eland Python library.
Next let's go to the Elastic Cloud console and scale our ML tier to 64 total vCPUs (8x the power of my current laptop).

Now, in Kibana, we’ll deploy the trained ML model. At scale, performance testing has shown that users should start with 1 thread per model allocation and increase the number of allocations to increase throughput. The documentation and guidance can be found here. I experimented, and for this smaller set I got the best results with 32 instances at 2 threads each. To set this up, go to Stack Management > Machine Learning. Use the Synchronize saved objects feature to make Kibana see the model we pushed into Elasticsearch with the Python code. Then deploy the model in the menu that comes up when you click it.

Now let's use Dev Tools again to create a new index and ingest pipeline that processes the paragraph of text in a document, puts the result in a dense vector field called "vector," and copies the paragraph to the expected "text" field.
Test the pipeline to make sure it's working.
Now we are ready to batch load data using the normal Python library for Elasticsearch, targeting our ingest pipeline to correctly create the vector embedding and transform our data to match LangChain’s expectations.
Success! The data is about 13M tokens in OpenAI terms, so processing this in the non-private and cloud would be around 5/hr.
With the data loaded, remember to scale your Cloud ML back down to zero or something more reasonable using the cloud console.
Step 3. Win at Star Wars trivia
Next let's play with the LLM and LangChain. I created a library file lib_llm.py to hold this code.
The template_informed is the critical but also easy to understand part of this. All we are doing is formatting a prompt template, which will take our two parameters: the context and the question from the user.
With this final main code continued from above, it looks like the following:
Conclusion
So with some data wrangling, we’ve now used AI without exposing our data to a 3rd party hosted LLM. The world of AI is changing quickly, but preserving the security and control of private data is something we should all be taking seriously for the regulatory, financial, and human consequences of data breaches. That is unlikely to change. We work with customers who use search to investigate fraud, defend their nation, and improve outcomes for vulnerable patient communities. Privacy matters. To learn more about how Elastic is used in these spaces, check out:
Have you fallen in love with LangChain as much as I have? As a wise old Jedi once said: “That's good. You have taken your first step into a larger world.” There are lots of directions to go from here. LangChain takes the complexity away from working with AI prompt engineering. I know Elasticsearch has many other roles to play here as long term memory for generative AI, so I am very excited to see what comes out of this quickly changing space.
In this blog post, we may have used third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Frequently Asked Questions
What is Langchain?
LangChain is a Python and JavaScript framework for developing applications powered by large language models.
Related Content

March 13, 2026
Entity resolution with Elasticsearch, part 4: The ultimate challenge
Solving and evaluating entity resolution challenges in a highly diverse “ultimate challenge” dataset designed to prevent shortcuts.

March 4, 2026
Entity resolution with Elasticsearch, part 3: Optimizing LLM integration with function calling
Learn how function calling enhances LLM integration, enabling a reliable and cost-efficient entity resolution pipeline in Elasticsearch.

February 26, 2026
Entity resolution with Elasticsearch & LLMs, Part 2: Matching entities with LLM judgment and semantic search
Using semantic search and transparent LLM judgment for entity resolution in Elasticsearch.
February 18, 2026
Better text analysis for complex languages with Elasticsearch and neural models
Using neural models and the Elasticsearch inference API to improve search in Hebrew, German, Arabic, and other morphologically complex languages.

February 12, 2026
Entity resolution with Elasticsearch & LLMs, Part 1: Preparing for intelligent entity matching
Learn what entity resolution is and how to prepare both sides of the entity resolution equation: your watch list and the articles you want to search.