Como implantar o PLN: exemplo de reconhecimento de entidades nomeadas (REN)


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
Como parte de nossa série de posts sobre processamento de linguagem natural (PLN), apresentaremos um exemplo usando um modelo de PLN de reconhecimento de entidades nomeadas (REN) para localizar e extrair categorias predefinidas de entidades em campos de texto não estruturados. Usando um modelo disponível publicamente, mostraremos como implantar esse modelo no Elasticsearch, encontrar entidades nomeadas no texto com a nova API _infer e usar o modelo de REN em um pipeline de ingestão para extrair entidades à medida que os documentos são ingeridos no Elasticsearch.
Os modelos de REN são úteis quando se utiliza linguagem natural para extrair entidades como pessoas, lugares e organizações de campos de texto completo.
Neste exemplo, vamos passar parágrafos do livro Les Misérables por um modelo de REN, usar o modelo para extrair os personagens e locais do texto e visualizar as relações entre eles.
Como implantar um modelo de REN no Elasticsearch
Primeiro, precisamos selecionar um modelo de REN que possa extrair os nomes dos personagens e locais dos campos de texto. Felizmente, existem alguns modelos de REN disponíveis em Hugging Face que podemos escolher. Ao verificar a documentação da Elastic, vemos um modelo da Elastic de REN sem diferenciação de maiúsculas e minúsculas para experimentar.
Uma vez selecionado o modelo de REN a ser usado, podemos usar o Eland para instalar o modelo. Neste exemplo, executaremos o comando do Eland por meio de uma imagem do Docker. No entanto, primeiro devemos construir a imagem do Docker clonando o repositório do Eland no GitHub e criar uma imagem do Docker do Eland no seu sistema cliente:
git clone git@github.com:elastic/eland.git
cd eland
docker build -t elastic/eland .
Agora que nosso cliente do Docker do Eland está pronto, podemos instalar o modelo de REN executando o seguinte comando eland_import_hub_model na nova imagem do Docker:
docker run -it --rm elastic/eland \
eland_import_hub_model \
--url $ELASTICSEARCH_URL \
--hub-model-id elastic/distilbert-base-uncased-finetuned-conll03-english \
--task-type ner \
--startVocê precisará substituir ELASTICSEARCH_URL pelo URL do cluster do Elasticsearch. Para fins de autenticação, você precisará incluir um nome de usuário e uma senha de administrador no URL no formato https://username:password@host:port.
Como usamos a opção --start no final do comando de importação do Eland, o Elasticsearch implantará o modelo em todos os nós de machine learning disponíveis e carregará o modelo na memória. Se tivéssemos vários modelos e quiséssemos selecionar qual modelo implantar, poderíamos usar a interface de usuário Machine Learning > Model Management (Gerenciamento de modelos) do Kibana para gerenciar o início e a interrupção dos modelos.
Teste do modelo de REN
Os modelos implantados podem ser avaliados usando a nova API _infer. A entrada é a string que desejamos analisar. Na solicitação abaixo, text_field é o nome do campo onde o modelo espera encontrar a entrada, conforme definido na configuração do modelo. Por padrão, se o modelo foi carregado via Eland, o campo de entrada é text_field.
Tente este exemplo no Console do Dev Tools do Kibana:
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_infer
{
"docs": [
{
"text_field": "Hi my name is Josh and I live in Berlin"
}
]
}
O modelo encontrou duas entidades: a pessoa “Josh” e o local “Berlin”.
{
"predicted_value" : "Hi my name is [Josh](PER&Josh) and I live in [Berlin](LOC&Berlin)",
"entities" : {
"entity" : "Josh",
"class_name" : "PER",
"class_probability" : 0.9977303419824,
"start_pos" : 14,
"end_pos" : 18
},
{
"entity" : "Berlin",
"class_name" : "LOC",
"class_probability" : 0.9992474323902818,
"start_pos" : 33,
"end_pos" : 39
}
]
}
predicted_value é a string de entrada no formato de texto anotado, class_name é a classe prevista e class_probability indica o nível de confiança na previsão. start_pos e end_pos são as posições dos caracteres inicial e final da entidade identificada.
Inclusão do modelo de REN em um pipeline de ingestão de inferência
A API _infer é uma maneira divertida e fácil de começar, mas aceita apenas uma única entrada, e as entidades detectadas não são armazenadas no Elasticsearch. Uma alternativa é realizar inferência em massa nos documentos conforme são ingeridos por meio de um pipeline de ingestão com o processador inference.
Você pode definir um pipeline de ingestão na UI Stack Management (Gerenciamento da stack) ou configurá-lo no Console do Kibana; este contém vários processadores de ingestão:
PUT _ingest/pipeline/ner
{
"description": "NER pipeline",
"processors": [
{
"inference": {
"model_id": "elastic__distilbert-base-uncased-finetuned-conll03-english",
"target_field": "ml.ner",
"field_map": {
"paragraph": "text_field"
}
}
},
{
"script": {
"lang": "painless",
"if": "return ctx['ml']['ner'].containsKey('entities')",
"source": "Map tags = new HashMap(); for (item in ctx['ml']['ner']['entities']) { if (!tags.containsKey(item.class_name)) tags[item.class_name] = new HashSet(); tags[item.class_name].add(item.entity);} ctx['tags'] = tags;"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{ _index }}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
Começando com o processador inference, o propósito de field_map é mapear paragraph (o campo a ser analisado nos documentos de origem) para text_field (o nome do campo que o modelo está configurado para usar). target_field é o nome do campo no qual gravar os resultados da inferência.
O processador script extrai as entidades e as agrupa por tipo. O resultado final são listas de pessoas, locais e organizações detectadas no texto de entrada. Estamos adicionando este script Painless para que possamos criar visualizações a partir dos campos criados.
A cláusula on_failure existe para detectar erros. Ela define duas ações. Primeiro, define o metacampo _index com um novo valor, e o documento agora será armazenado lá. Segundo, a mensagem de erro é gravada em um novo campo: ingest.failure. A inferência pode falhar por vários motivos facilmente corrigíveis. Talvez o modelo não tenha sido implantado ou o campo de entrada esteja ausente em alguns dos documentos de origem. Com o redirecionamento dos documentos com falha para outro índice e a definição da mensagem de erro, essas inferências com falha não são perdidas e podem ser revisadas posteriormente. Depois que os erros forem corrigidos, reindexe a partir do índice com falha para recuperar as solicitações malsucedidas.
Seleção dos campos de texto para inferência
O REN pode ser aplicado a muitos conjuntos de dados. Como exemplo, escolhi Les Misérables, o clássico romance publicado em 1862 por Victor Hugo. Você pode carregar os parágrafos de Les Misérables do nosso arquivo json de amostra usando o recurso de upload de arquivo do Kibana. O texto é dividido em 14.021 documentos JSON, cada um contendo um único parágrafo. Vamos pegar um parágrafo aleatório como exemplo:
{
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"line": 12700
}
Depois que o parágrafo é ingerido por meio do pipeline de REN, o documento resultante armazenado no Elasticsearch é marcado com uma única pessoa identificada.
{
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"@timestamp": "2020-01-01T17:38:25",
"line": 12700,
"ml": {
"ner": {
"predicted_value": "Father [Gillenormand](PER&Gillenormand) did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"entities": [{
"entity": "Gillenormand",
"class_name": "PER",
"class_probability": 0.9806354093873283,
"start_pos": 7,
"end_pos": 19
}],
"model_id": "elastic__distilbert-base-cased-finetuned-conll03-english"
}
},
"tags": {
"PER": [
"Gillenormand"
]
}
}
Uma nuvem de tags é uma visualização que dimensiona as palavras pela frequência com que ocorrem e é o infográfico perfeito para visualizar as entidades encontradas em Les Misérables. Abra o Kibana, crie uma nova visualização baseada em agregação e escolha Tag Cloud (Nuvem de tags). Selecione o índice que contém os resultados do REN e adicione uma agregação de termos no campo tags.PER.keyword.
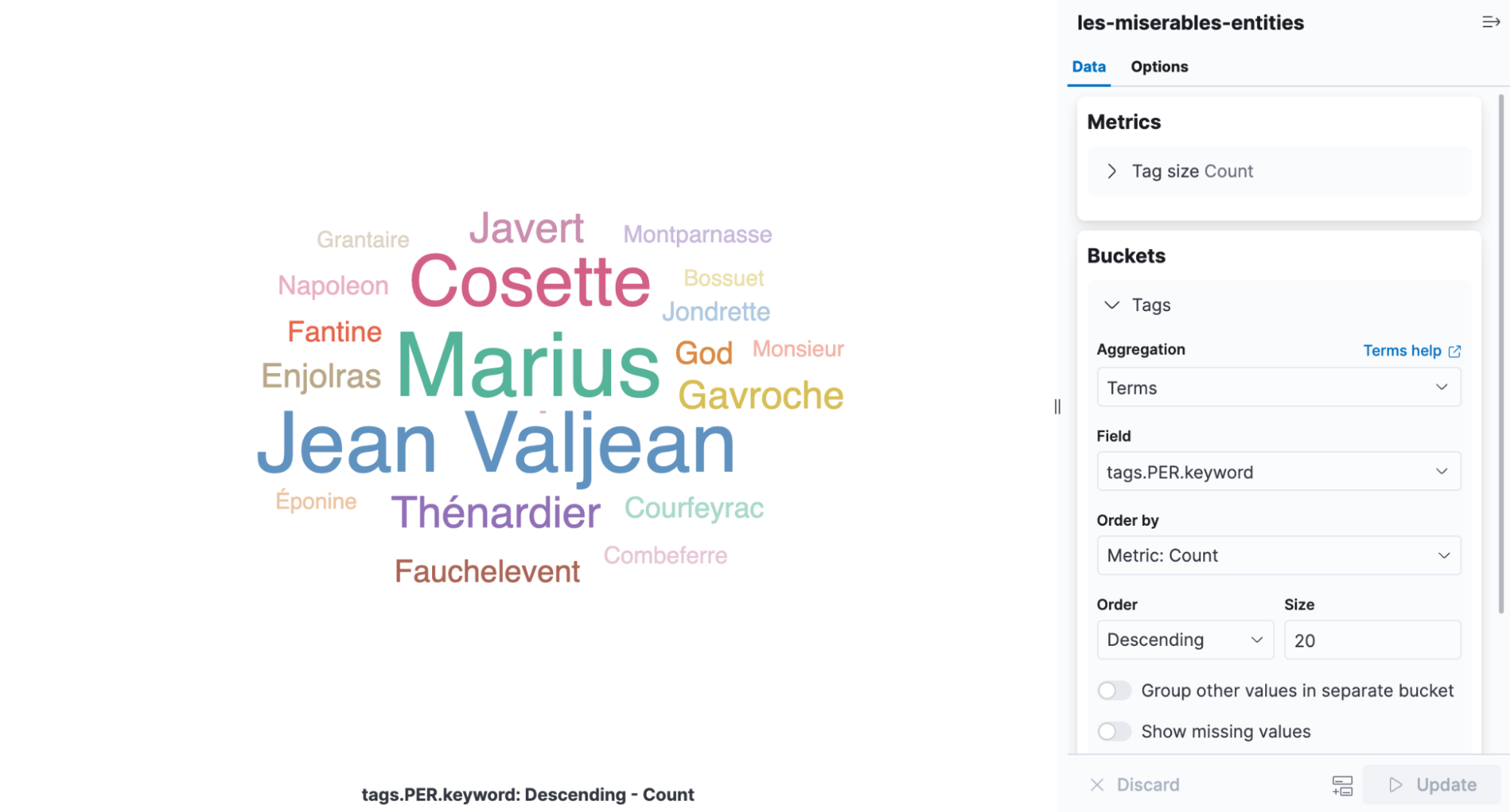
É fácil notar pela visualização que Cosette, Marius e Jean Valjean são os personagens mencionados com mais frequência no livro.
Ajuste da implantação
Voltando à UI Model Management (Gerenciamento de modelos), em Deployment stats (Estatísticas de implantação), você encontrará Avg Inference Time (Tempo médio de inferência). Esse é o tempo medido pelo processo nativo para realizar a inferência em uma única solicitação. Ao iniciar uma implantação, há dois parâmetros que controlam como os recursos da CPU são usados: inference_threads e model_threads.
inference_threads é o número de threads usados para executar o modelo por solicitação. O aumento de inference_threads reduz diretamente o tempo médio de inferência. O número de solicitações avaliadas em paralelo é controlado por model_threads. Essa configuração não reduzirá o tempo médio de inferência, mas aumentará a taxa de transferência.
Em geral, você ajusta a latência aumentando o número de inference_threads e aumenta a taxa de transferência elevando o número de model_threads. Ambas as configurações têm um único thread por padrão, portanto, pode-se obter um bom ganho de desempenho ao modificá-las. O efeito é demonstrado usando o modelo de REN.
Para alterar uma das configurações de thread, a implantação deve ser interrompida e reiniciada. O parâmetro ?force=true é passado para a API de interrupção porque a implantação é referenciada por um pipeline de ingestão que normalmente impediria a interrupção.
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_stop?force=true
Reinicie com quatro threads de inferência. O tempo médio de inferência é redefinido quando a implantação é reiniciada.
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_start?inference_threads=4No processamento dos parágrafos de Les Misérables, o tempo médio de inferência cai para 55,84 milissegundos por solicitação, em comparação com 173,86 milissegundos para um único thread.
Aprendendo mais e experimentando
O REN é apenas uma das tarefas de PNL prontas para uso agora. Classificação de texto, classificação zero-shot e embeddings de texto também estão disponíveis. Mais exemplos podem ser encontrados na documentação de PLN, juntamente com uma lista de modelos (não exaustiva) que pode ser implantada no Elastic Stack.
A PLN é um novo recurso importante no Elastic Stack para a versão 8.0 com um roadmap muito interessante. Descubra novos recursos e acompanhe os desenvolvimentos mais recentes criando seu cluster no Elastic Cloud. Inscreva-se para fazer uma avaliação gratuita de 14 dias hoje mesmo e teste os exemplos deste post.
Se quiser ler mais sobre PNL:
- Como implantar o PLN: embeddings de texto e busca vetorial
- How to deploy NLP: Sentiment Analysis Example (Como implantar o PLN: exemplo de análise de sentimentos
- How to deploy natural language processing: Getting started (Como implantar o processamento de linguagem natural: uma introdução)
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir