Como implantar o PLN: exemplo de análise de sentimentos


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
Como parte da nossa série de posts do blog sobre processamento de linguagem natural (PLN), analisaremos um exemplo usando o modelo de PLN para análise de sentimentos e avaliaremos se os campos de comentários (texto) contêm sentimentos positivos ou negativos. Usaremos um modelo disponível publicamente nesse exemplo e mostraremos como implantar esse modelo no Elasticsearch para usá-lo em um pipeline de ingestão e classificar as avaliações dos clientes como positivas ou negativas.
A análise de sentimentos é um tipo de classificação binária na qual o campo é previsto como um valor ou outro. Em geral há uma pontuação provável para essa previsão entre 0 e 1, com pontuação próxima a 1, indicando maior confiabilidade. Esse tipo de análise de PLN pode ser aplicado de forma útil a muitos conjuntos de dados, como avaliações de produtos ou feedback de clientes.
As avaliações do cliente que queremos classificar estão em um conjunto de dados público do 2015 Yelp Dataset Challenge. O conjunto de dados, agrupado com base no site Yelp Review, é o recurso perfeito para testar a análise de sentimentos. Neste exemplo, vamos avaliar uma amostra do conjunto de dados das avaliações do Yelp com o modelo de PLN para análise de sentimentos comuns e usar o modelo para rotular os comentários como positivos ou negativos. Esperamos descobrir qual porcentagem de avaliações é positiva e contrastar com a das negativas.
Implantação do modelo de análise de sentimentos no Elasticsearch
docker run -it --rm elastic/eland \
eland_import_hub_model \
--url $ELASTICSEARCH_URL \
--hub-model-id distilbert-base-uncased-finetuned-sst-2-english \
--task-type text_classification \
--start
Desta vez, --task-type é definido como text_classification, e a opção --start é passada para o script do Eland para que o modelo seja implantado automaticamente sem que seja necessário iniciá-lo na UI de Gerenciamento de Modelos.
Depois da implantação, tente estes exemplos no console do Kibana:
POST _ml/trained_models/distilbert-base-uncased-finetuned-sst-2-english/deployment/_infer
{
"docs": [
{
"text_field": "The movie was awesome!"
}
]
}
O resultado deve ser mais ou menos este:
{
"predicted_value" : "POSITIVE",
"prediction_probability" : 0.9998643924765398
}
Você pode também tentar este exemplo:
POST _ml/trained_models/distilbert-base-uncased-finetuned-sst-2-english/deployment/_infer
{
"docs": [
{
"text_field": "The cat was sick on the bed"
}
]
}
Produz uma resposta extremamente negativa tanto para o gato quanto para a pessoa que teve que lavar os lençóis.
{
"predicted_value" : "NEGATIVE",
"prediction_probability" : 0.9992468477843378
}
Como analisar as avaliações do Yelp
Conforme mencionamos na introdução, usaremos um subconjunto de avaliações do Yelp disponíveis no Hugging Face que foram marcadas manualmente com sentimentos. Dessa forma, poderemos comparar os resultados com o índice com marcações. Usaremos o recurso de carregamento de arquivo do Kibana para carregar uma amostra deste conjunto de dados para processar com o uso do processador de inferência.
No console do Kibana, podemos criar um pipeline de ingestão (como fizemos no post do blog anterior), desta vez para a análise de sentimentos, e o chamar de sentiment. As avaliações ficam em um campo chamado de review. Como fizemos antes, definiremos um field_map para mapear o review para o campo que o modelo espera. O mesmo manipulador on_failure do pipeline REN é definido:
PUT _ingest/pipeline/sentiment
{
"processors": [
{
"inference": {
"model_id": "distilbert-base-uncased-finetuned-sst-2-english",
"field_map": {
"review": "text_field"
}
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
Os documentos de avaliação ficam armazenados no índice do Elasticsearch yelp-reviews. Use a API de reindexação para inserir os dados das avaliações pelo pipeline de análise de sentimentos. Como ela levará algum tempo para processar todos os documentos e inferir com base neles, faça a reindexação em segundo plano invocando a API com o sinalizador wait_for_completion=false. Verifique o progresso com a API de gerenciamento de tarefas.
POST _reindex?wait_for_completion=false
{
"source": {
"index": "yelp-reviews"
},
"dest": {
"index": "yelp-reviews-with-sentiment",
"pipeline": "sentiment"
}
}
Isso retorna um id de tarefa. Podemos monitorar o progresso da tarefa com:
The above returns a task id. We can monitor progress of the task with:
Como alternativa, acompanhe o progresso observando o aumento da contagem de inferência na UI de estatísticas do modelo.

Os documentos reindexados agora contêm os resultados da inferência. Como exemplo, um dos documentos analisados fica mais ou menos assim:
{
"review": "The food is good. Unfortunately the service is very hit or miss. The main issue seems to be with the kitchen, the waiters and waitresses are often very apologetic for the long waits and it's pretty obvious that some of them avoid the tables after taking the initial order to avoid hearing complaints.",
"ml": {
"inference": {
"predicted_value": "NEGATIVE",
"prediction_probability": 0.9985209630712552,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
}
},
"timestamp": "2022-02-02T15:10:38.195345345Z"
}
O valor previsto é NEGATIVO, o que faz sentido, se considerarmos o atendimento ruim.
Como visualizar quantas avaliações são negativas
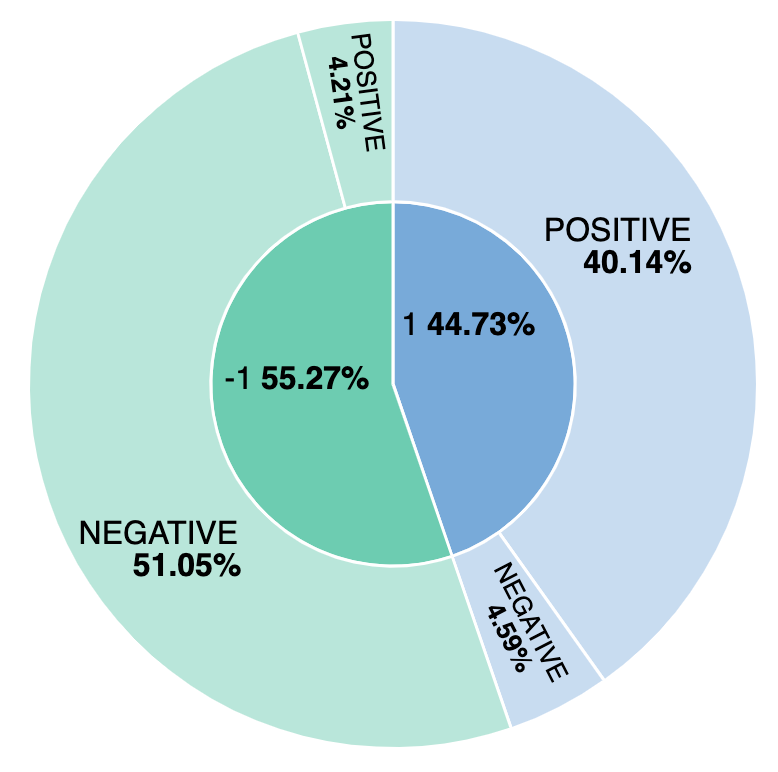
Qual é a porcentagem de avaliações negativas? E como nosso modelo se compara às avaliações com sentimentos rotulados manualmente? Vamos descobrir isso criando uma visualização simples para relacionar as avaliações positivas e as negativas provenientes tanto do modelo quanto das entradas manuais. Criando uma visualização baseada no ml.inference.predicted_value field, podemos gerar um relatório da comparação e ver que aproximadamente 44% das avaliações são consideradas positivas e que destas, 4,59% estão rotuladas incorretamente com base no modelo de análise de sentimentos.
Experimentando
Se quiser ler mais sobre PLN:
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir