Como criar um dashboard customizado de relatório de incidente do ServiceNow no Canvas
Bem-vindo(a) de volta mais uma vez! Esta é a terceira e última parte desta série sobre o uso do Elastic Stack com o ServiceNow para gerenciamento de incidentes. No primeiro post do blog, apresentamos o projeto e configuramos o ServiceNow para que as alterações em um incidente fossem enviadas automaticamente para o Elasticsearch. No segundo post, implementamos a lógica para unir o ServiceNow e o Elasticsearch por meio de alertas e transformações, bem como algumas configurações gerais do Elasticsearch.
A esta altura, tudo está totalmente funcional. No entanto, está faltando o front end prático (e bonito) que usaremos para o gerenciamento de incidentes! Neste post, criaremos o workpad do Canvas abaixo para que as pessoas possam aproveitar todo esse valor que temos até agora e transformá-lo em algo que possam entender e usar facilmente.
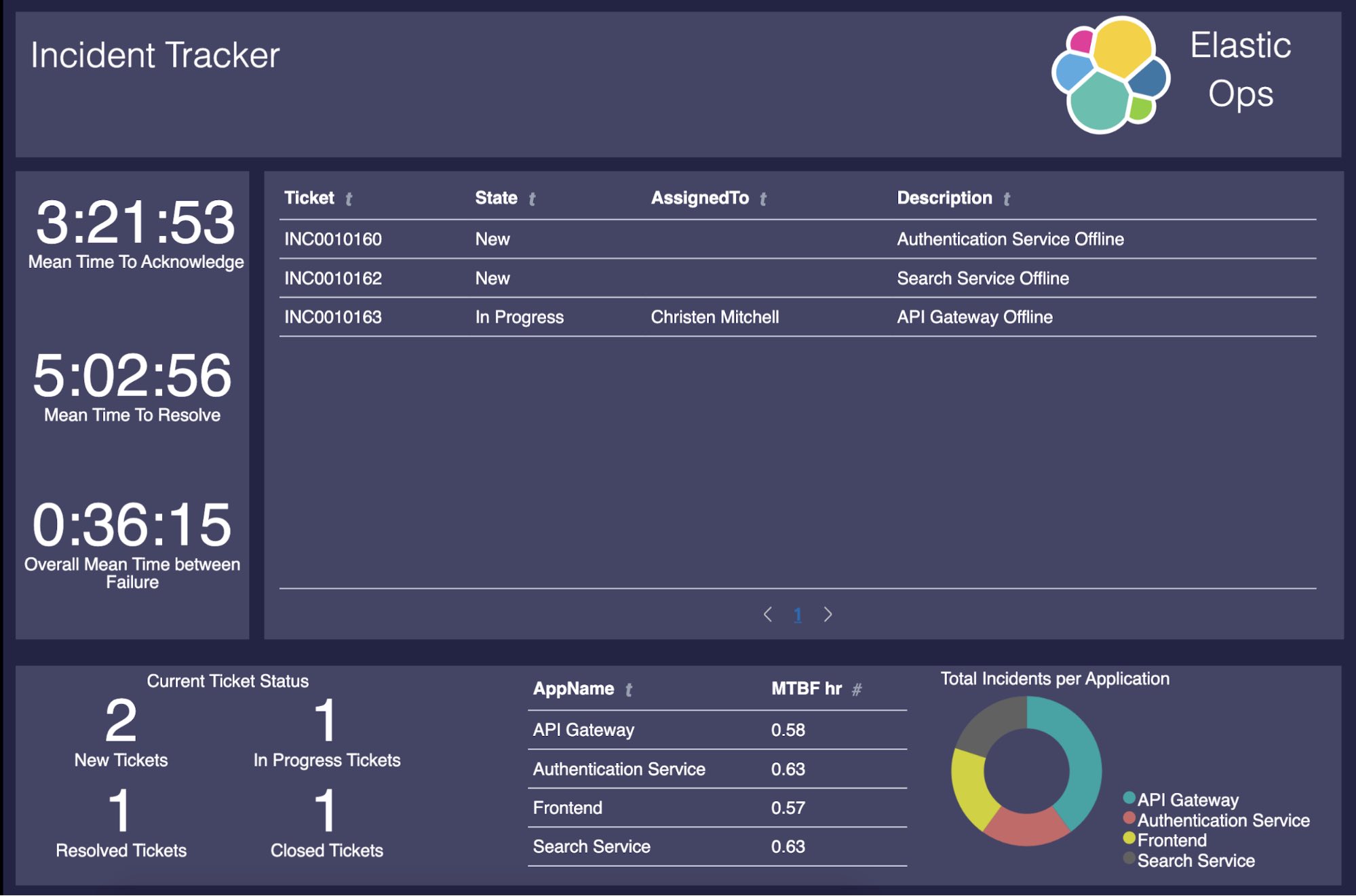
Aqui está o que mostraremos no nosso dashboard:
- Tíquetes abertos, fechados, resolvidos e com trabalho em andamento
- MTTA do incidente
- MTTR do incidente
- MTBF geral
- MTBF da aplicação
- Incidente por aplicação
Vamos começar.
Configuração de um workpad do Canvas
Neste post, usaremos muito as expressões do Canvas porque todos os elementos em um workpad são representados por expressões subjacentes. Portanto, isso significa que é a maneira mais fácil de mostrar como recriar recursos.
Observe que se, você não tiver nenhum dado dentro dos índices centrados na entidade preenchido pelas transformações, alguns dos elementos abaixo fornecerão uma mensagem de erro semelhante a “Empty datatable” (Tabela de dados vazia).
Antes de começar, vamos abrir o Canvas:
- Expanda a barra de ferramentas do Kibana.
- Se você está executando a versão 7.8 ou superior, ele pode ser encontrado no Kibana; caso contrário, estará na lista de todos os outros ícones.
- Clique no botão Create Workpad (Criar workpad).
- Depois de criar um workpad, dê um nome a ele. Isso pode ser definido em Workpad Settings (Configurações do workpad) no lado direito. Eu recomendaria alterar “My Canvas Workpad” (Meu workpad do Canvas) para “Incident Tracker” (Controle de incidentes). É aqui também que definimos a cor de fundo nas próximas etapas.
- Para editar a expressão do Canvas para um determinado componente, clique nela e, a seguir, clique no </> Expression editor (Editor de expressão </>) no canto inferior direito.
Configuração do tema
A primeira etapa da criação do nosso workpad do Canvas é a aparência do plano de fundo:
- Defina a cor do plano de fundo como #232344.
- Crie os quatro elementos de forma na forma de um retângulo e defina sua cor de preenchimento como #444465.
- Adicione o logotipo e o texto na barra superior, como logotipo da empresa, nome da empresa e um título.
Exibição dos tíquetes em ação
Agora precisamos construir a tabela no meio que mostra quais tíquetes estão em ação. Para fazer isso, usaremos uma combinação de expressões do Elasticsearch SQL e do Canvas junto com um elemento de “tabela de dados”. Para criar o elemento de tabela de dados, copie a seguinte expressão do Canvas no editor e clique em run (executar):
filters
| essql
query="SELECT incidentID as Ticket, LAST(state, updatedDate) as State, LAST(assignedTo, updatedDate) as AssignedTo, LAST(description, updatedDate) as Description FROM \"servicenow*\" group by Ticket ORDER BY Ticket ASC"
| filterrows fn={getCell "State" | any {eq "New"} {eq "On Hold"} {eq "In Progress"}}
| table
font={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="left" color="#FFFFFF" weight="normal" underline=false italic=false} paginate=true perPage=10
| render
Nessa expressão, executamos a consulta e, em seguida, filtramos todas as linhas, exceto aquelas que têm o campo State (Estado) definido como “New” (Novo), “On Hold” (Em espera) ou “In Progress” (Em andamento).
Neste ponto, ele provavelmente estará vazio, pois não temos nenhum dado. Isso ocorre porque nossa regra de negócios pode não ter sido executada, então não há dados do ServiceNow no Elasticsearch. Se quiser, você poderá criar alguns incidentes simulados aqui. Caso faça isso, certifique-se de ter tíquetes em vários estágios para dar à tabela uma aparência mais realista.
Cálculo do tempo médio de reconhecimento (MTTA)
Para mostrar o MTTA do incidente, adicionaremos um elemento de métrica e usaremos a expressão do Canvas abaixo.
filters
| essql
query="SELECT * FROM (SELECT incidentID, updatedDate, state FROM \"servicenow-incident-updates\") PIVOT (MIN(updatedDate) FOR state IN ('New' as New, 'In Progress' as \"InProgress\"))"
| mapColumn "New" fn={getCell "New" | formatdate "X" | math "value"}
| mapColumn "InProgress" fn={getCell "InProgress" | formatdate "X" | math "value"}
| filterrows fn={getCell "InProgress" | gt 0}
| mapColumn "Duration" expression={math expression="InProgress - New"}
| math "mean(Duration)"
| metric "Mean Time To Acknowledge"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="00:00:00"
| render
Essa expressão usa funções do Elasticsearch SQL mais avançadas, incluindo PIVOT. Para calcular o MTTA, calculamos o tempo total entre a criação e o reconhecimento e, então, o dividimos pelo número de incidentes. Precisamos usar PIVOT aqui porque armazenamos cada atualização que o usuário faz no tíquete no ServiceNow. Isso significa que toda vez que alguém atualiza o estado, as notas de trabalho, o responsável e assim por diante, a atualização é enviada para o Elasticsearch. Isso é fantástico para trabalhar com analítica nesses resultados. Devido a isso, precisaremos dinamizar os dados para obter uma linha por incidente, com a primeira vez que o incidente foi “New” (Novo) e a primeira vez que mudou para “In Progress” (Em andamento).
Podemos, então, calcular o tempo para o reconhecimento subtraindo a hora em que foi criado da hora em que cada incidente foi reconhecido. O MTTA é calculado usando a média sobre essa função do campo de duração.
Cálculo do tempo médio de resolução (MTTR)
Para mostrar o MTTR do incidente, adicionaremos um elemento de métrica e usaremos a seguinte expressão do Canvas:
filters
| essql
query="SELECT * FROM (SELECT incidentID, updatedDate, state FROM \"servicenow-incident-updates\") PIVOT (MIN(updatedDate) FOR state IN ('New' as New, 'Resolved' as \"Resolved\"))"
| mapColumn "New" fn={getCell "New" | formatdate "X" | math "value"}
| mapColumn "Resolved" fn={getCell "Resolved" | formatdate "X" | math "value"}
| filterrows fn={getCell "Resolved" | gt 0}
| mapColumn "Duration" expression={math expression="Resolved - New"}
| math "mean(Duration)"
| metric "Mean Time To Resolve"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="00:00:00"
| render
De forma semelhante ao MTTA, usamos a função PIVOT porque precisamos ter uma visão resumida de cada incidente. Ao contrário do MTTA, obtemos a primeira vez que vemos o estado quando é novo e também resolvido. Isso ocorre porque o MTTR é o tempo médio que leva para um tíquete ser resolvido. Isso é muito semelhante ao MTTA, portanto, por uma questão de brevidade, não vou repetir os mesmos detalhes.
Cálculo do tempo médio entre falhas (MTBF) geral
Agora que temos o MTTA e o MTTR, é hora de obtermos o MTBF para cada aplicação. Para isso, usaremos nossas duas transformações: app_incident_summary_transform e calculate_uptime_hours_online_transfo. Por causa dessas transformações, calcular o MTBF geral é muito fácil. Como o MTBF é medido em horas e nossa transformação o calcula em segundos, calculamos a média de todas as aplicações e multiplicamos o resultado por 3.600 (segundos em uma hora).
Vamos criar outro elemento de métrica usando a expressão do Canvas abaixo:
filters
| essql query="SELECT AVG(mtbf) * 3600 as MTBF FROM app_incident_summary"
| math "MTBF"
| metric "Overall Mean Time between Failure"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="00:00:00"
| render
Cálculo do tempo médio entre falhas (MTBF) da aplicação
Agora que calculamos o MTBF geral, podemos mostrar facilmente o MTBF de cada aplicação. Tudo o que precisamos fazer aqui é criar um novo elemento de tabela de dados e exibir os dados em uma tabela usando a expressão do Canvas a seguir. Por uma questão de legibilidade, arredondei o MTBF de cada aplicação para duas casas decimais.
filters
| essql
query="SELECT app_name as AppName, ROUND(mtbf,2) as \"MTBF hr\" FROM app_incident_summary"
| table paginate=false
font={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="left" color="#FFFFFF" weight="normal" underline=false italic=false}
| render
Cálculo dos tíquetes resolvidos
Queremos ver algumas vitórias, então vamos nos certificar de ter uma contagem de tíquetes fechados no nosso workpad. Este é um elemento de métrica simples que obtém todos os incidentes nos quais o estado está definido como “Resolved” (Resolvido) e, em seguida, a função matemática conta o número único de IDs de incidente.
filters
| essql query="SELECT state,incidentID FROM \"servicenow*\" where state = 'Resolved'"
| math "unique(incidentID)"
| metric "Resolved Tickets"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="0,0.[000]"
| render
Cálculo de incidentes por aplicação
Agora vamos criar um gráfico de rosca que conta o número de incidentes únicos por aplicação. Eu recomendaria adicionar um elemento de markdown acima dele com o texto “Total Incidents per Application” (Total de incidentes por aplicação) para dar contexto ao que o gráfico de rosca está mostrando.
filters
| essql
query="SELECT incidentID as IncidentCount, app_name as AppName FROM \"servicenow*\""
| pointseries color="AppName" size="unique(IncidentCount)"
| pie hole=41 labels=false legend="se" radius=0.72
palette={palette "#01A4A4" "#CC6666" "#D0D102" "#616161" "#00A1CB" "#32742C" "#F18D05" "#113F8C" "#61AE24" "#D70060" gradient=false} tilt=1
font={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="left" color="#FFFFFF" weight="normal" underline=false italic=false}
| render
Cálculo dos status dos tíquetes atuais
Esta seção consiste em quatro elementos de métrica. Todos eles têm expressões do Canvas muito semelhantes, com apenas pequenas alterações. Resumindo, obteremos a atualização mais recente para todos os incidentes e, em seguida, usaremos a função de expressão Filterrows do Canvas para manter os que queremos com base em seu status. Com isso, simplesmente contamos o número de incidentes únicos.
Use a expressão abaixo e atualize o estado de New (Novo) para cada estado desejado. Além disso, não se esqueça de atualizar o texto na métrica de “New Tickets” (Novos tíquetes).
filters
| essql
query="SELECT incidentID, LAST(state, updatedDate) as State FROM \"servicenow*\" group by incidentID" count=1000
| filterrows fn={getCell "State" | eq 'New'}
| math "unique(incidentID)"
| metric "New Tickets"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="0,0.[000]"
| render
Produto final
Agora que temos todas as diferentes partes do nosso workpad do Canvas criadas, obtemos este dashboard de gerenciamento de incidentes extremamente útil:
Terminamos, agora é só você começar a usar o que aprendeu!
E é isso! Passamos por uma jornada de uso de vários componentes do Elastic Stack para calcular o MTTA, o MTTR e o MTBF com base em incidentes do ServiceNow e, em seguida, exibimos essas informações em um dashboard útil e visualmente atraente. Uma lição importante que temos aqui é que essas informações convivem com seus dados reais, e não ficam em outra ferramenta. Essas métricas fornecem uma boa base de conhecimento que as pessoas podem usar para entender a integridade de um aplicação em relação aos incidentes relatados. Por exemplo, se o MTBF está muito baixo, isso significa que a aplicação falha com frequência. Se o MTTA está alto, significa que leva muito tempo para que uma investigação de uma falha seja iniciada.
Se você acabou de ler e ainda não experimentou por si mesmo(a), incentivo-o(a) a arregaçar as mangas e botar a mão na massa. Você pode criar uma avaliação gratuita do Elastic Cloud e usá-la com a sua instância existente do ServiceNow ou com uma instância de desenvolvedor pessoal.
Além disso, se você quer fazer buscas em dados do ServiceNow junto com outras fontes, como GitHub, Google Drive e outras, o Elastic Workplace Search tem um conector pré-criado para ServiceNow. O Workplace Search oferece uma experiência de busca unificada para as suas equipes, com resultados relevantes em todas as suas fontes de conteúdo. Ele também está incluído na sua avaliação do Elastic Cloud.
Este post do blog fornece uma base para você usar seus dados para acompanhar essas métricas. Como exemplo, se quiser ir mais longe, você poderá criar incidentes com base nos seus logs, métricas de infraestrutura, traces de APM e anomalias encontradas com machine learning. Para fornecer valor adicional às partes interessadas neste dashboard do Canvas, uma boa sugestão é adicionar links para os apps no Kibana (Logs, APM etc) ou seus próprios dashboards que lhe dão uma vantagem para investigar a causa raiz do respectivo problema.
Se você gostou desta série, aqui estão alguns links que acho que você também vai apreciar:
- When to use Data Transforms (Quando usar transformações de dados)
- Getting started with machine learning (Como começar a usar machine learning)
- Intro to Canvas: A new way to tell visual stories in Kibana (Introdução ao Canvas: uma nova maneira de contar histórias visuais no Kibana)
- Uso do elemento de métrica do Canvas e de markdown para adicionar links
Bom proveito!