Elastic에서 머신 러닝 모델에 액세스하기



트위터에서 공유하기


링크드인에서 공유하기


페이스북에서 공유하기


이메일로 공유하기


인쇄하기
필요한 머신 러닝 모델을 지원하는 Elastic
Elastic®을 사용하면 사용 사례와 머신 러닝 전문 지식 수준에 맞는 머신 러닝을 적용할 수 있습니다. 다음과 같은 다양한 옵션이 있습니다.
- 기본 제공되는 모델을 활용합니다. Elastic의 Observability 및 보안 솔루션에서 특정 보안 위협 및 여러 유형의 시스템 문제를 대상으로 하는 모델 외에도, 독점적인 Elastic Learned Sparse Encoder 모델을 즉시 사용할 수 있으며, 영어가 아닌 텍스트 데이터를 사용하는 경우 유용한 언어 ID도 사용할 수 있습니다.
- HuggingFace 모델 허브를 포함하여 어디서나 서드파티 PyTorch 모델에 액세스합니다.
- 직접 훈련한 모델(현재는 주로 NLP 트랜스포머)을 로드합니다.
기본 제공 모델을 사용하면 머신 러닝 전문 지식이 필요 없이 바로 활용할 수 있지만, 다양한 모델을 시험해보고 데이터에 가장 적합한 성능을 발휘하는 모델을 결정할 수 있는 유연성이 있습니다.
Elastic은 클러스터의 여러 노드에서 확장 가능하도록 모델 관리를 설계하는 동시에 높은 처리량과 낮은 대기 시간 워크로드 양쪽 모두에서 우수한 유추 성능을 보장했습니다. 이는 부분적으로는 수집 파이프라인이 유추를 실행할 수 있도록 지원함으로써 그리고 수집 단계뿐만 아니라 데이터 분석 및 검색 동안 계산이 까다로운 모델 유추를 위해 전용 노드를 사용함으로써 가능합니다.
Elastic에 모델을 로드할 수 있게 해주는 Eland 라이브러리와 Elasticsearch® 내에서 사용할 수 있는 다양한 유형의 머신 러닝(최신 트랜스포머 및 자연어 처리(NLP) 모델부터 회귀를 위한 향상된 트리 모델까지)에 대해 자세히 알아보세요.
Elastic에 머신 러닝 모델을 로드할 수 있게 해주는 Eland 라이브러리
Elastic의 Eland 라이브러리는 PyTorch를 사용하여 훈련된 경우 머신 러닝 모델을 Elasticsearch에 로드할 수 있는 손쉬운 인터페이스를 제공합니다. 기본 라이브러리 libtorch를 사용하고 TorchScript 표현으로 내보내거나 저장된 모델을 기대하면, Elasticsearch는 모델 유추를 수행하는 동안 Python 인터프리터를 실행하지 않습니다.
PyTorch에서 NLP 모델을 구축하는 데 가장 인기 있는 형식 중 하나와 통합함으로써, Elasticsearch는 대단히 다양한 NLP 작업 및 사용 사례와 함께 작동하는 플랫폼을 제공할 수 있습니다. 다음에 나오는 트랜스포머에 관한 섹션에서 이에 대해 좀더 자세히 설명하겠습니다.
Eland를 사용하여 모델을 업로드하려면 명령줄, Docker, 자체 Python 코드 내에서 등의 세 가지 옵션이 있습니다. Docker는 Eland와 그 모든 종속성의 로컬 설치가 필요하지 않기 때문에 덜 복잡합니다. Eland에 액세스하면, 아래 코드 샘플은 DistilBERT NER 모델을 업로드하는 방법을 보여줍니다. 예를 들면, 다음과 같습니다.

아래에서는 eland_import_hub_model의 각 인수에 대해 설명하겠습니다. 그리고 Docker 컨테이너에서 동일한 명령을 내릴 수 있습니다.
업로드되면, Kibana의 머신 러닝 모델 관리 사용자 인터페이스를 통해 추가 처리량을 위한 할당 증가 등 Elasticsearch 클러스터에서 모델을 관리하고 시스템을 (재)구성하는 동안 모델을 중지/재개할 수 있습니다.
지원되는 모델
Elastic은 가장 인기 있는 지도 학습 라이브러리뿐만 아니라 다양한 트랜스포머 모델을 지원합니다.
- NLP 및 임베딩 모델: 표준 BERT 모델 인터페이스를 준수하고 WordPiece 토큰화 알고리즘을 사용하는 모든 트랜스포머. 지원되는 모델 아키텍처의 전체 목록을 참조하세요.
- 지도 학습: Elasticsearch에서 유추 모델로 직렬화하고 사용하기 위한 scikit-learn, XGBoost 및 LightGBM 라이브러리의 훈련된 모델. Elastic의 설명서는 Elastic의 데이터에 대한 XGBoost 분류를 훈련하기 위한 예를 제공합니다. 또한 Elastic의 데이터 프레임 분석을 사용하여 Elastic에서 훈련된 지도 모델을 내보내고 가져올 수도 있습니다.
- 생성형 AI: 대규모 언어 모델(LLM)을 위해 제공되는 API를 사용하여 Elastic에서 검색된 컨텍스트로 잠재적으로 보강된 쿼리를 전달하고 반환된 결과를 처리할 수 있습니다. 자세한 지침은 이 블로그를 참조하세요. 이 블로그는 ChatGPT의 API를 통해 통신하기 위한 코드 예제와 함께 GitHub 리포지토리로 연결됩니다.
아래에서는 검색 애플리케이션의 맥락에서 사용할 가능성이 가장 높은 모델 유형인 NLP 트랜스포머에 대한 자세한 정보를 제공합니다.
Elastic에서 트랜스포머와 NLP를 쉽게 적용하는 방법!
아래 코드 조각에서 확인된 인수를 검토하여 Hugging Face의 인기 NER 모델과 같은 NLP 모델을 로드하고 사용하는 단계를 설명하겠습니다.

- Elastic Cloud 식별자를 지정합니다. 또는 --url을 사용합니다.
- 클러스터에 액세스할 수 있는 인증 세부 정보를 제공합니다. 이용 가능한 인증 방법을 검색할 수 있습니다.
- Hugging Face 모델 허브에서 모델의 식별자를 지정합니다.
- NLP 작업의 유형을 지정합니다. 지원되는 값은 fill_mask, ner, text_classification, text_embedding, zero_shot_classification입니다.
모델을 로드한 후에는 다음으로 이를 배포해야 합니다. Kibana의 머신 러닝 탭에 있는 모델 관리 화면에서 이 작업을 수행한 다음, 모델이 제대로 작동하고 있는지 일반적으로 테스트합니다.
이제 배포된 모델을 유추에 사용할 준비가 되었습니다. 예를 들어 명명된 엔티티를 추출하려면, 다음과 같이 로드된 NER 모델의 _infer 엔드포인트를 호출합니다.
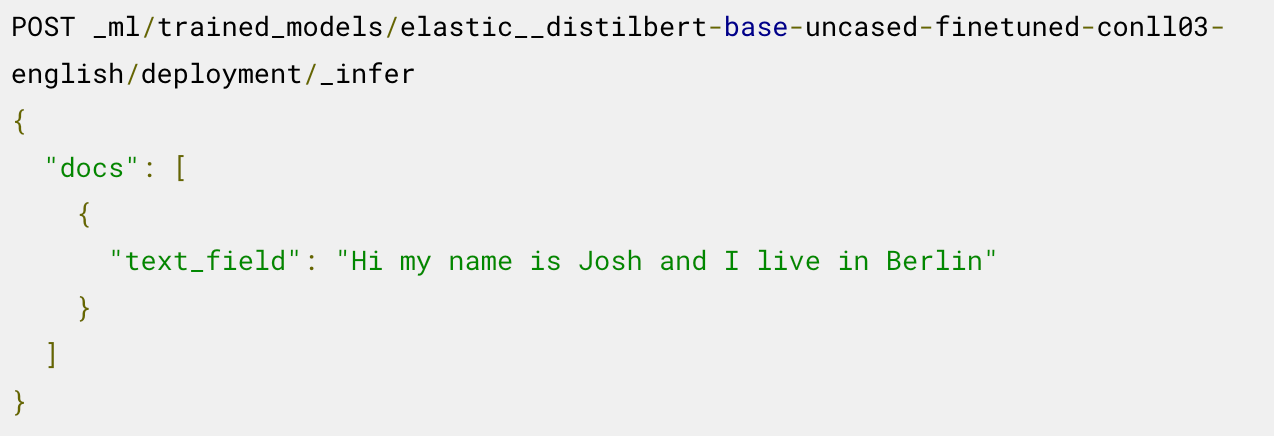
모델은 두 개의 엔티티를 식별했습니다. 사람 "Josh"와 위치 "Berlin"입니다.

유추 파이프라인에서 이 모델을 사용하고 배포를 조정하는 등의 추가 단계는 이 예제를 설명하는 블로그를 참조하세요.
예를 들어, 텍스트에 대한 임베딩을 만든 다음 벡터 검색을 적용하여 관련 문서를 찾는 방법과 같은 시맨틱 검색을 적용하는 방법을 알고 싶으신가요? 이 블로그에서는 모델 성능 검증 등을 단계별로 설명합니다.
어떤 모델에 대한 어떤 유형의 작업인지 모르시나요? 시작하시는 데 이 표가 도움이 될 것입니다.
Hugging Face 모델 | task-type |
|---|---|
ner | |
text_embedding | |
text_classification | |
zero_shot_classification | |
| 질문 답변 | question_answering |
또한 Elastic은 두 텍스트가 서로 text_similarity task-type과 얼마나 비슷한지 비교할 수 있습니다. 이는 제공된 다른 텍스트 입력과 비교할 때 문서 텍스트의 순위를 매기는 데 유용하며 크로스 인코딩이라고도 합니다.
자세한 내용을 위한 리소스
- Eland를 위한 설계 고려 사항을 포함한 PyTorch 트랜스포머 지원
- 트랜스포머를 Elastic으로 로딩하고 유추에 사용하기 위한 단계
- ChatGPT를 사용하여 독점 데이터를 쿼리하는 방법을 설명하는 블로그
- 미리 훈련된 트랜스포머를 텍스트 분류 작업에 맞게 조정하고 사용자 정의 모델을 Elastic으로 로드
- 영어만 지원하는 모델로 전달하기 전에 비영어 텍스트를 식별할 수 있는 기본 제공 언어 식별
Elastic, Elasticsearch 및 관련 상표는 미국 및 기타 국가에서 Elasticsearch N.V.의 상표, 로고 또는 등록 상표입니다. 기타 모든 회사 및 제품 이름은 해당 소유자의 상표, 로고 또는 등록 상표입니다.
이 게시물에 설명된 기능의 릴리즈 및 시기는 Elastic의 단독 재량에 따릅니다. 현재 이용할 수 없는 기능은 정시에 또는 전혀 제공되지 않을 수 있습니다.
공유하기
트위터에서 공유하기
링크드인에서 공유하기
페이스북에서 공유하기
이메일로 공유하기
인쇄하기

