Elasticsearch에서 PyTorch를 사용한 첨단 자연어 처리 소개


 Share on Twitter
Share on Twitter트위터에서 공유하기

 Share on LinkedIn
Share on LinkedIn링크드인에서 공유하기

 Share on Facebook
Share on Facebook페이스북에서 공유하기

 Share by Email
Share by Email이메일로 공유하기

 Print this page
Print this page인쇄하기
Elastic은 8.0 출시와 함께 PyTorch 머신 러닝 모델을 Elasticsearch로 업로드하여 Elastic Stack에서 첨단 자연어 처리(NLP)를 제공하는 기능을 도입하게 되어 무척 기대가 됩니다. 이제 Elasticsearch 사용자는 NLP 모델을 구축하기 위해 가장 인기 있는 형식 중 하나를 통합하고 이러한 모델을 NLP 데이터 파이프라인의 일부로 Elastic의 유추 프로세서를 통해 Elasticsearch에 포함시킬 수 있습니다. 새로운 ANN 검색 API와 함께 PyTorch 모델을 추가하는 기능은 Elastic Enterprise Search에 완전히 새로운 벡터를 추가합니다.
NLP란 무엇인가?
NLP는 소프트웨어를 사용하여 구어나 서면 텍스트 또는 자연어를 조작하고 이해할 수 있는 방법을 말합니다. 2018년에 Google은 트랜스포머의 양방향 인코더 표현, 즉 BERT라고 하는 NLP 사전 훈련을 위한 새로운 기술을 오픈 소스화했습니다. BERT는 사람의 개입 없이 인터넷 크기의 데이터 세트(예: 모든 위키백과와 디지털 책)에 대한 훈련을 통해 "전송 학습"을 활용합니다.
전송 학습을 통해 BERT 모델을 범용 언어 이해를 위해 사전 훈련할 수 있습니다. 모델이 단 한 번만 사전 훈련을 받으면, 다시 사용될 수 있으며 언어가 사용되는 방법을 이해하기 위해 더 구체적인 작업에 맞게 미세 조정할 수 있습니다.
BERT와 동일한 토크나이저를 사용하는 모델인 BERT 유사 모델을 지원하기 위해, Elasticsearch는 PyTorch 모델 지원을 통해 가장 일반적인 NLP 작업의 대부분을 지원하는 것으로 시작합니다. PyTorch는 활성 사용자들의 대규모 커뮤니티가 있는 가장 인기 있는 첨단 머신 러닝 라이브러리 중 하나이며, BERT가 활용하는 트랜스포머 아키텍처와 같은 심층 신경망을 지원하는 라이브러리입니다.
다음은 NLP 작업의 몇 가지 예입니다.
- 정서 분석: 긍정문 대 부정문을 식별하기 위한 이진 분류
- 명명된 엔티티 인식(NER): 구조화되지 않은 텍스트에서 구조 구축, 예를 들어 이름, 위치 또는 조직과 같은 세부 정보 추출 시도
- 텍스트 분류: 제로샷 분류를 사용하면 사전 훈련 없이 선택하는 클래스에 따라 텍스트를 분류할 수 있습니다.
- 텍스트 임베딩: k-최근접 유사 항목(kNN) 검색에 사용

Elasticsearch의 NLP
NLP 모델을 Elastic Platform에 통합할 때 모델을 업로드하고 관리하기 위한 훌륭한 사용자 경험을 제공하고자 했습니다. PyTorch 모델을 업로드하기 위한 Eland 클라이언트와 Elasticsearch 클러스터에서 모델을 관리하기 위한 Kibana의 ML Model Management 사용자 인터페이스를 통해, 사용자는 다양한 모델을 사용해보고 데이터에서 어떤 성능을 발휘하는지 제대로 느낄 수 있습니다. 또한 클러스터에서 사용 가능한 여러 노드에 걸쳐 NLP 모델을 확장할 수 있도록 하고 우수한 유추 처리량 성능을 제공하고자 했습니다.
이 모든 것이 가능하도록 하기 위해, 유추를 수행할 수 있는 머신 러닝 라이브러리가 필요했습니다. Elasticsearch에서 PyTorch에 대한 지원을 추가하려면 PyTorch를 지원하는 네이티브 라이브러리 libtorch를 사용해야 하며 TorchScript 표현으로 내보내거나 저장한 PyTorch 모델만 지원하게 됩니다. 이것은 libtorch가 필요로 하는 모델의 표현이며 이로써 Elasticsearch는 Python 인터프리터를 실행하지 않아도 됩니다.
PyTorch 모델에서 NLP 모델을 구축하는 데 가장 인기 있는 형식 중 하나와 통합함으로써 Elasticsearch는 다양한 NLP 작업 및 사용 사례와 함께 작동하는 플랫폼을 제공할 수 있습니다. NLP 모델을 훈련하기 위해 많은 우수한 라이브러리를 사용할 수 있으므로, Elastic은 이를 현재 다른 도구에 맡기고 있습니다. PyTorch NLP, Hugging Face 트랜스포머 또는 Facebook의 fairseq와 같은 라이브러리로 모델을 훈련하는 경우에도, 모델을 Elasticsearch로 가져오고 해당 모델에 대한 유추를 수행할 수 있습니다. Elasticsearch 유추는 처음에는 수집 시에만 있게 되며, 향후에는 쿼리 시에도 유추를 도입할 수 있도록 확장할 수 있습니다.
지금까지는 API 호출과 플러그인을 통해 NLP 모델을 통합하는 방법과 Elasticsearch에서 데이터를 스트리밍하는 다른 옵션이 있었습니다. 그러나 Elasticsearch 데이터 파이프라인 내에 NLP 모델을 통합하면 다음과 같은 이점을 얻을 수 있습니다.
- NLP 모델을 중심으로 더 나은 인프라 구축
- NLP 모델 유추 확장
- 데이터 보안 및 개인정보 보호 유지관리
NLP 모델은 Kibana에서 중앙 집중식으로 관리되어 최적화된 로드 밸런싱을 제공하기 위해 여러 머신 러닝 노드에 쿼리를 배포할 수 있습니다.
PyTorch 모델에 대한 유추 호출은 클러스터 주위에 배포될 수 있으며 향후에는 사용자가 부하를 기반으로 확장할 수 있습니다. 데이터를 이동하지 않고 CPU 기반 유추를 위해 클라우드 VM을 최적화함으로써 성능을 향상시킬 수 있습니다. Elasticsearch에 NLP 모델을 통합함으로써, 데이터 개인정보 취급방침과 규정 준수를 염두에 두고 전체적으로 중앙 집중화된 보안 네트워크 내에 데이터를 유지할 수 있습니다. Elasticsearch에 NLP 모델을 통합함으로써 공통 인프라, 쿼리 성능 및 데이터 개인정보 보호를 모두 향상시킬 수 있습니다.
PyTorch NLP 모델 구현 워크플로우
PyTorch로 NLP 모델을 구현하기 위한 몇 가지 간단한 단계가 있습니다. 우리가 해야 할 첫 번째 단계는 모델을 Elasticsearch에 업로드하는 것입니다. 이를 위한 한 가지 방법은 모든 Elasticsearch 클라이언트에서 사용할 수 있는 REST API를 사용하는 것이지만, 우리는 프로세스를 지원하는 더 간단한 도구를 추가하고 싶었습니다. Elastic Stack을 위한 Python Data Science 라이브러리인 Eland 클라이언트에서, 로컬 디스크로부터 모델을 업로드하거나 훈련된 모델을 공유하는 가장 인기 있는 방법 중 하나인 Hugging Face 모델 허브로부터 모델을 가져올 수 있는 몇 가지 간단한 방법과 스크립트를 공개합니다. 이러한 접근 방식 중 어느 쪽에 대해서든, PyTorch 모델을 TorchScript 표현으로 변환하고 마지막으로 모델을 클러스터에 업로드하는 데 도움이 되는 도구가 있습니다.
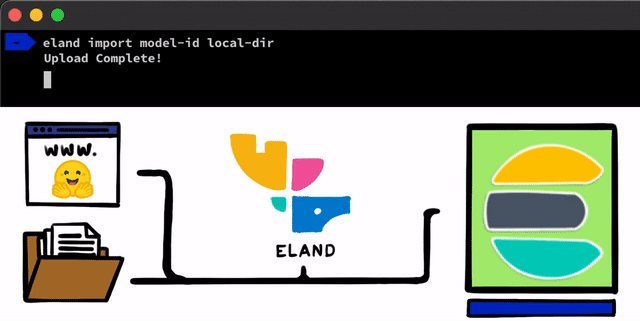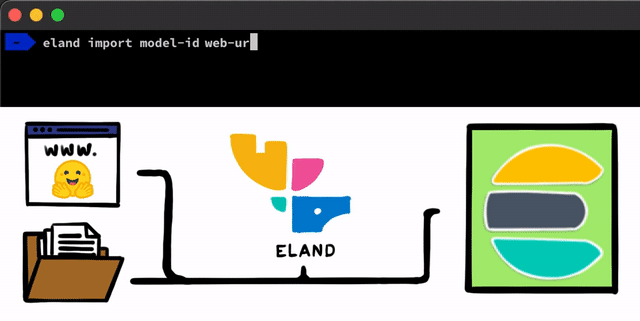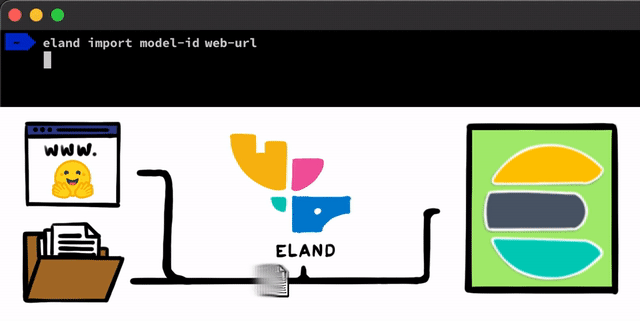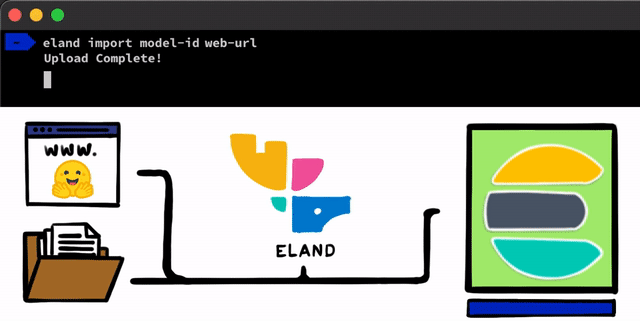
PyTorch 모델이 클러스터에 업로드되면 해당 모델을 특정 머신 러닝 노드에 할당할 수 있게 됩니다. 이 프로세스는 모델을 메모리에 로드하고 네이티브 libtorch 프로세스를 시작하여 유추할 수 있도록 합니다.
마지막으로, 모델 할당이 완료되면, 유추할 준비가 됩니다. 수집 시에는 유추를 위한 프로세서가 있으며, 유추 전후에 문서를 사전 처리하거나 후 처리하도록 모든 종류의 수집 처리 파이프라인을 설정할 수 있습니다. 예를 들어, 문서 필드의 텍스트를 입력으로 가져와서 해당 입력에 대해 예측된 양의 또는 음의 클래스 레이블을 반환하고 해당 예측을 문서의 출력 필드에 추가하는 정서 분석 작업을 수행할 수 있습니다. 그 결과 생성된 새로운 문서는 다른 수집 프로세서에 의해 추가로 처리되거나 그대로 색인될 수 있습니다.
그럼 이제 무엇을 해야 할까요?
앞으로 곧 있을 블로그 업데이트 및 웨비나에서 구체적인 모델과 NLP 작업에 대한 더 많은 예를 제공해 드리기를 기대합니다. Elasticsearch에서 시도해 보고 싶은 모델이 있다면, 오늘 시작하시고 머신 러닝 토론 포럼 또는 커뮤니티 Slack에서 여러분의 경험에 대해 알려주실 수 있습니다. 프로덕션 사용 사례의 경우, Elasticsearch는 NLP 모델을 업로드하고 유추 프로세서를 사용하려면 Platinum 또는 Enterprise 라이선스가 필요하지만 무료 체험판 라이선스를 통해 지금 바로 사용해 보실 수 있습니다. 또는 Elastic Cloud 클러스터를 구축하고 Eland 클라이언트를 사용하여 모델을 새 클러스터에 업로드하는 방식으로 시작하실 수 있습니다. 지금 바로 Elastic Cloud의 14일 무료 체험판을 시작하실 수 있습니다.
한 가지 더 있습니다. NLP 모델에 대해 자세히 알아보고 Elasticsearch에 통합하는 데 관심이 있다면, NLP 모델 및 벡터 검색 소개 웨비나에 참석하세요.
추가 관련 링크:
- Josh Devins와의 ElasticON 대담
- Ben Trent와 Jay Miller와의 Elastic 커뮤니티 NLP 토론
- Julie Tibshirani 검색 블로그의 ANN
- 8.0 NLP 설명서
공유하기
- Share on Twitter
트위터에서 공유하기
- Share on LinkedIn
링크드인에서 공유하기
- Share on Facebook
페이스북에서 공유하기
- Share by Email
이메일로 공유하기
- Print this page
인쇄하기