사이버 보안 분야의 머신 러닝: 지도형 모델을 훈련하여 DGA 활동 탐지
무작위 전화번호로 걸려오는 텔레마케팅 전화를 받으면 짜증이 나지 않으시나요? 그 전화번호를 차단해도 소용이 없습니다. 다음에는 완전히 다른 번호를 사용할 테니까요. 사이버 공격자들은 똑같이 지저분한 트릭을 사용합니다. 맬웨어 작성자는 DGA(도메인 생성 알고리즘)를 사용하여 명령 및 제어 인프라의 소스를 변경함으로써 탐지를 피하고 맬웨어 공격을 막으려는 보안 분석가를 좌절하게 만듭니다.
2부로 구성된 이 시리즈에서는 Elastic 머신 러닝을 사용하여 도메인 생성 알고리즘을 탐지하는 모델을 구축하고 평가합니다. 1부에서 다룰 내용은 다음과 같습니다.
- 원시 악성 및 양성 도메인에서 피처를 추출하는 프로세스
- 적합한 피처를 찾는 프로세스에 대한 간략한 설명
- Elastic Stack을 사용하여 머신 러닝 모델을 훈련하고 평가하는 방법
2부에서는 훈련된 모델을 수집 파이프라인에 배포하여 수집 시 Packetbeat 데이터를 보강하는 방법을 설명합니다. 구성 파일과 도움이 되는 자료는 예제 리포지토리에 제공되어 있습니다.
집에서 사용해보고 싶으신 경우 Elasticsearch Service 무료 체험판을 실행하면 모든 머신 러닝 기능에 액세스하실 수 있습니다. 그럼 시작해 보겠습니다.
DGA: 배경
대상 머신을 감염시킨 후 많은 악성 프로그램이 데이터를 유출하고 명령이나 업데이트를 수신하기 위해 명령 및 제어(C&C 또는 C2) 서버라고 하는 원격 서버에 연결하려고 시도합니다. 이는 악성 바이너리가 C&C 서버의 IP 주소 또는 도메인을 알아야 한다는 뜻입니다. 이 IP 주소 또는 도메인이 바이너리에 하드코딩된 경우 해당 도메인을 차단 목록에 추가하여 통신을 방해하면 비교적 쉽게 방어 조치를 취할 수 있습니다.
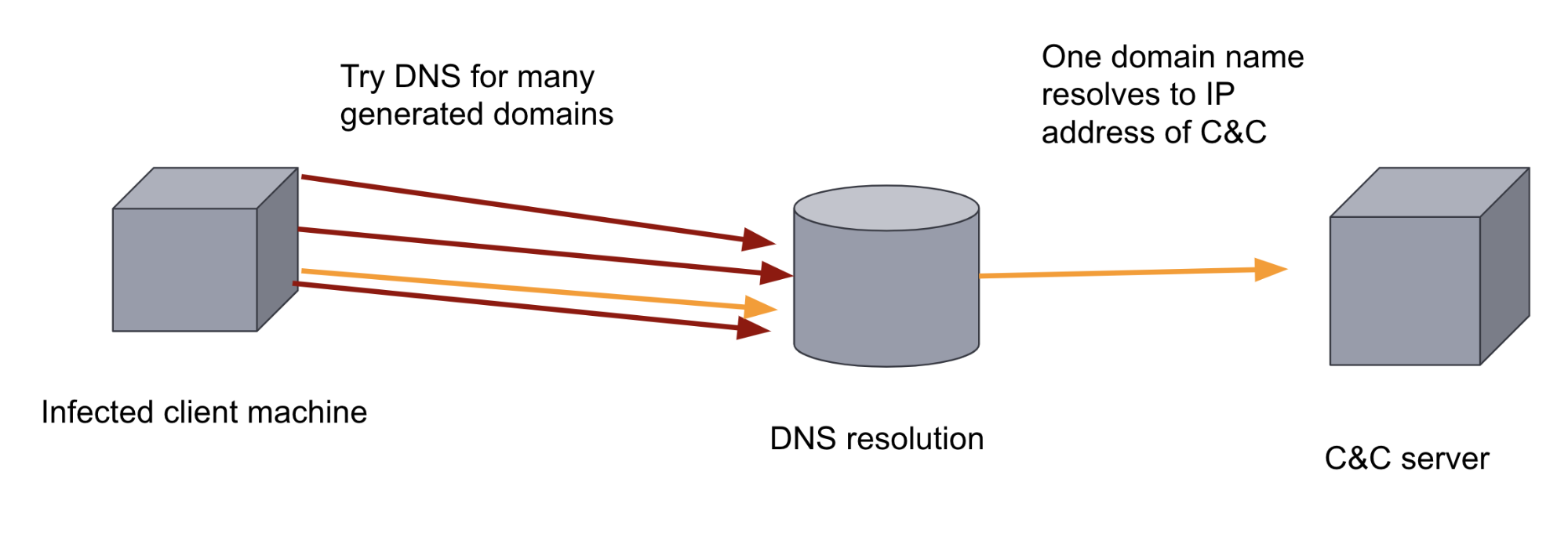
이러한 방어 조치를 와해시키기 위해 맬웨어 작성자는 DGA를 맬웨어에 추가합니다. DGA는 무작위로 수백 또는 수천 개의 도메인을 생성합니다. 그러면 감염된 머신에 있는 맬웨어 바이너리가 생성된 각 도메인을 순환하며 도메인 이름을 확인하고 이 중 C&C 서버로 등록된 도메인을 찾습니다. 도메인의 엄청난 볼륨과 무작위성으로 인해 규칙 기반의 방어 접근 방식으로는 이러한 통신 채널을 차단하기가 어렵습니다. 또한 DNS 트래픽은 일반적으로 볼륨이 매우 크기 때문에 분석가가 직접 찾기도 쉽지 않습니다. 대신 이 두 가지 요소는 머신 러닝을 적용하기에 매우 적합합니다.
도메인을 분류하도록 머신 러닝 모델 훈련
지도형 머신 러닝에서는 레이블이 지정된 악성 및 양성 도메인 훈련 데이터 세트를 제공하여 모델이 해당 데이터 세트를 학습하도록 합니다. 그러면 이 학습된 모델을 사용하여 처음 보는 도메인도 양성 또는 악성으로 분류할 수 있습니다.
DGA가 모두 똑같은 형태는 아니며 서로 다른 다양한 유형이 있습니다. 일부 DGA는 무작위 도메인을 생성하고 다른 DGA는 단어 목록을 사용합니다. 프로덕션 모델의 경우 다양한 피처와 모델을 사용하여 서로 다른 알고리즘의 특징을 포착할 수 있습니다. 이 예제에서는 가장 일반적인 알고리즘에서 발견된 특징들을 기반으로 단일 모델을 훈련하겠습니다.
다양한 맬웨어 제품군의 도메인과 양성 도메인으로 구성된 데이터 세트를 사용하여 모델을 훈련하겠습니다.

cryptolocker, banjori 및 suppobox 제품군에서 생성된 도메인 예제
피처 엔지니어링
효과적인 머신 러닝 모델을 생성하려면 DGA에서 생성한 도메인의 특징을 포착할 수 있는 피처를 입력해야 합니다. 따라서 악성 도메인과 양성 도메인을 구분하기 위해서는 스트링의 어떤 측면이 중요한지 모델에 알려줘야 합니다. 머신 러닝의 세계에서는 이를 피처 엔지니어링이라고 합니다.
악성 도메인과 양성 도메인을 가장 잘 구분하는 피처를 파악하기 위해서는 반복 프로세스가 필요합니다. 예를 들어 여기에서는 도메인 이름 길이 및 도메인 이름 엔트로피와 같은 간단한 피처로 시작했지만 이렇게 훈련한 모델은 LSTM 등의 다른 방법과 비교하여 특별히 정확하지 않았습니다. 이러한 모델들은 스트링의 순차적 특징을 활용하므로 이번에는 시퀀스를 좀 더 효과적으로 인코딩할 수 있는 다른 피처를 살펴보았습니다.
여러 방식으로 피처 엔지니어링을 반복한 후 다양한 길이의 하위 스트링을 사용하면 모델에서 양성 도메인과 악성 도메인의 차이를 가장 잘 포착할 수 있을 것이라는 결론을 내렸습니다.
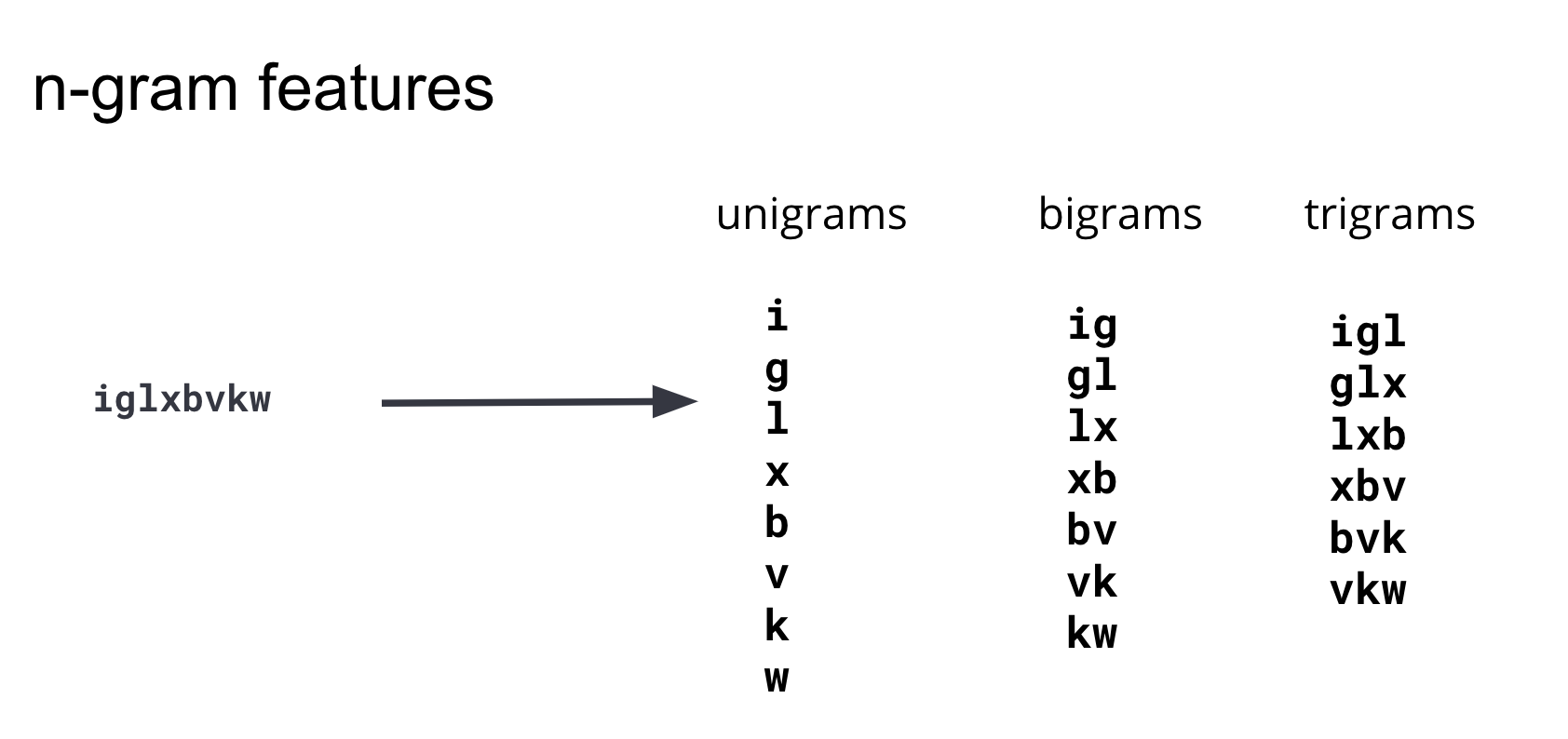
이러한 하위 스트링을 일반적으로 n-그램이라고 합니다. 피처를 개발할 때 피처 수(훈련 데이터 세트의 차원) 및 피처 계산의 복잡성과 모델이 제공하는 이점 간의 균형을 유지하는 것이 중요합니다. 다양한 길이의 n-그램을 반복 및 테스트 후, 길이가 4 이상인 n-그램은 모델에 별다른 예측 정보를 제공하지 않는다는 것을 확인하고 피처 세트를 유니그램, 바이그램 및 트라이그램으로 제한했습니다. 그림 3의 다이어그램은 예제 도메인에서 이러한 피처가 어떻게 생성되는지를 보여줍니다.
각 DGA 도메인이 유니그램, 바이그램 및 트라이그램으로 분할된 Elasticsearch 인덱스를 생성하려면 간단한 스크립트 프로세서로 수집 파이프라인을 통해 원래 소스 인덱스를 재색인하면 됩니다. 아래 그림 4에 예제가 나와 있습니다. 전체 구성, 명령 및 다양한 사용자 정의 옵션은 예제 리포지토리를 참조하세요.
POST _scripts/ngram-extractor-reindex
{
"script": {
"lang": "painless",
"source": """
String nGramAtPosition(String fulldomain, int fieldcount , int n){
String domain = fulldomain.splitOnToken('.')[0];
if (fieldcount+n>=domain.length()){
return ''
}
else
{
return domain.substring(fieldcount, fieldcount+n)
}
}
for (int i=0;i<ctx['domain'].length();i++){
ctx[Integer.toString(params.ngram_count)+'-gram_field'+Integer.toString(i)] = nGramAtPosition(ctx['domain'], i, params.ngram_count)
}
"""
}
}
일반적으로, 길이가 1, 2 및 3인 하위 스트링을 머신 러닝 알고리즘을 위한 숫자 벡터로 변환하려면 훨씬 더 많은 사전 처리가 필요합니다. 현재 사례에서는 이렇게 숫자 값으로 변환하는 작업을 Elastic 머신 러닝이 처리하며 이를 인코딩이라고 합니다. 또한 Elastic 머신 러닝은 피처를 검사하고 가장 중요한 정보를 담고 있는 피처를 자동으로 선택합니다.
데이터 프레임 분석 작업 생성
다음 단계는 데이터 프레임 분석 작업 UI를 사용하여 분류 작업을 생성하는 것입니다. 이 프로세스에서 중요한 측면 몇 가지를 아래 스크린샷에 강조 표시해 두었습니다.
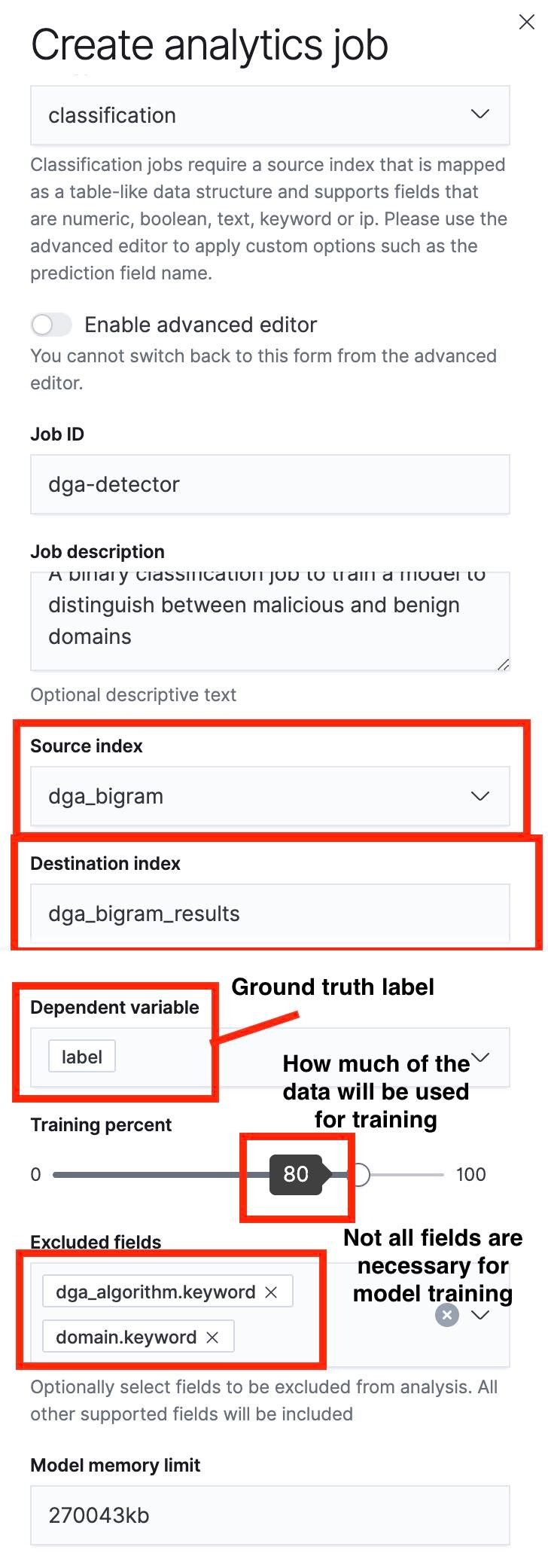
여기에서 주목할 부분은 슬라이더를 사용하여 훈련/테스트 분할을 지정할 수 있다는 점입니다. 그림 5의 스크린샷을 보면 훈련/테스트 분할이 80%로 설정되어 있습니다. 즉, 소스 인덱스에 있는 문서의 80%가 모델 훈련에 사용되고 나머지 20%가 모델 테스트에 사용됩니다.
훈련 프로세스가 완료되면 데이터 프레임 분석 결과 UI로 이동하여 모델의 성능을 평가할 수 있습니다. 소스 인덱스를 훈련 세트와 테스트 세트로 나누었으므로 각각에 대한 모델의 성능을 확인할 수 있습니다. 훈련 성능과 테스트 성능 모두 귀중한 정보를 제공하지만, 지금 사례에서는 모델의 일반화 오류를 파악할 수 있는 테스트 데이터 세트에서의 모델 성능에 좀 더 관심이 있습니다. 이 오류는 처음 보는 데이터 요소에서 모델이 어떻게 작동할지를 나타냅니다.
머신 러닝 모델 평가
훈련 프로세스가 완료되면 Elastic 머신 러닝 UI 작업 관리 페이지에서 간단하게 클릭을 통해 결과를 확인할 수 있습니다.
결과 페이지(그림 6 참조)는 두 가지 중요한 정보를 제공합니다. 하나는 모델의 성능을 요약하여 보여주는 confusion matrix(혼동 행렬)이고 다른 하나는 드릴다운하여 모델이 개별 데이터 요소를 어떻게 분류했는지 볼 수 있는 결과 테이블입니다. 테이블의 오른쪽 위에 있는 테스트/훈련 필터를 사용하면 테스트 및 훈련 데이트 세트에 대한 혼동 행렬과 요약 테이블 사이를 전환할 수 있습니다.
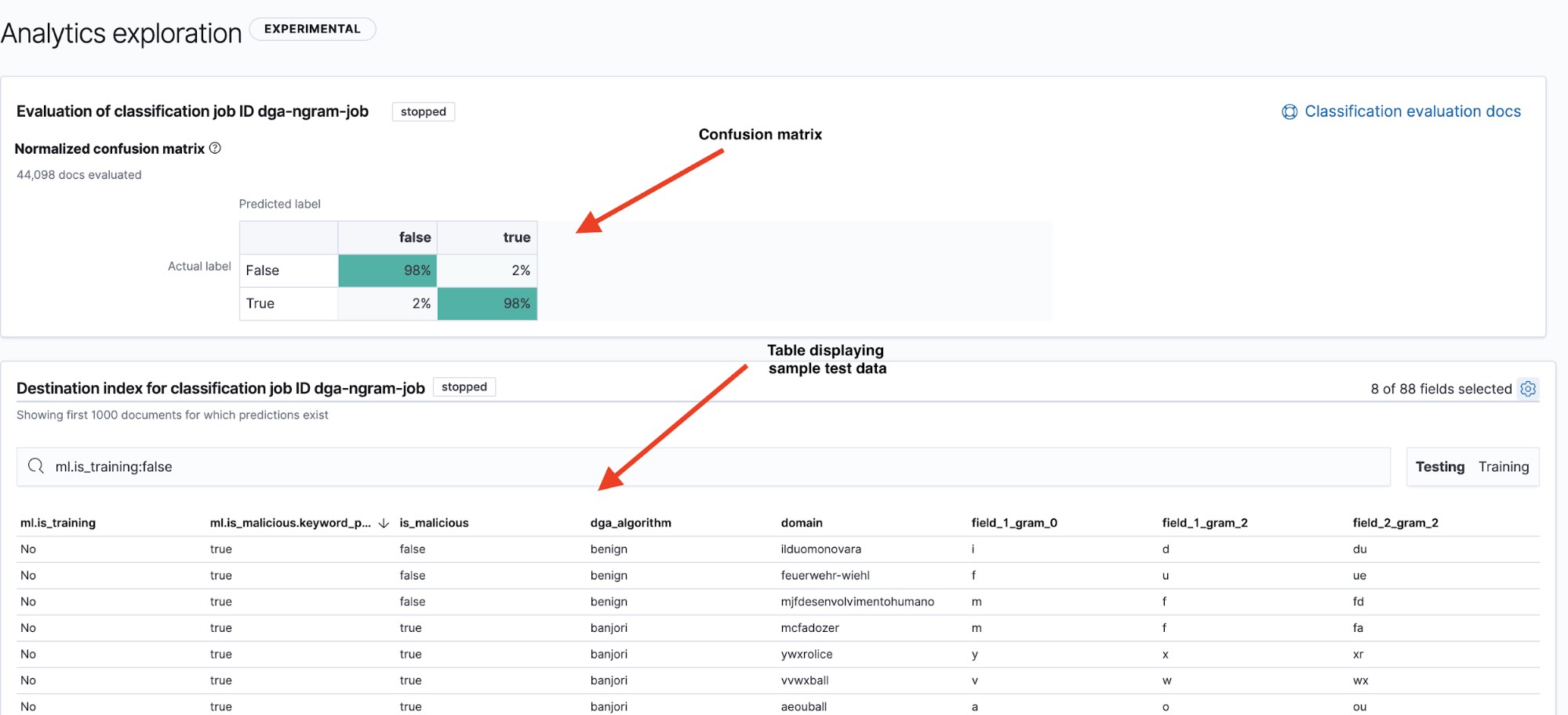
모델 성능을 표시하는 일반적인 방법은 혼동 행렬이라는 시각화를 사용하는 것입니다. 혼동 행렬은 true positives(모델이 악성으로 식별하였으며 실제로 악성인 악성 도메인)와 true negatives(모델이 양성으로 식별한 양성 도메인)로 분류된 데이터 요소의 백분율과 모델이 양성 도메인을 악성으로 혼동했거나(false positives) 악성 도메인을 양성으로 혼동한(false negatives) 문서의 백분율을 표시합니다.
이름 그대로, 혼동 행렬을 보면 모델이 한 클래스를 다른 클래스로 자주 혼동하는지를 금방 알 수 있습니다.
그림 6을 보면 현재 모델은 테스트 데이터에서 true positive 비율이 98%입니다. 즉, 이 모델을 프로덕션에 배포하여 수신되는 DNS 데이터를 분류하는 경우 약 2%의 false positive가 나타날 것으로 예상할 수 있습니다. 상당히 낮은 비율로 보이지만, DNS 트래픽의 막대한 볼륨을 고려하면 여전히 높은 경보 비율로 이어질 수 있습니다. 2부에서는 이상 징후 탐색을 사용하여 false positive 경보 수를 줄이는 방법을 살펴보겠습니다.
결론
이 블로그 게시물에서는 Elastic 머신 러닝을 사용하여 DGA 탐지용 머신 러닝 모델을 구축하고 평가하는 방법을 간략하게 살펴보았습니다. 원시 악성 및 양성 도메인에서 피처를 추출하는 프로세스를 알아보고 적합한 피처를 찾는 프로세스에 대해서도 약간 설명했습니다. 마지막으로, Elastic Stack을 사용하여 머신 러닝 모델을 훈련하고 평가하는 방법을 살펴보았습니다.
이 시리즈의 다음 파트에서는 수집 파이프라인에서 추론 프로세서를 사용하여 이 모델을 배포하고 도메인 악의성 예측을 통해 수신되는 Packetbeat 데이터를 보강하는 방법과 이상 징후 탐색 작업을 사용하여 false positive 경보 수를 줄이는 방법을 알아보겠습니다. 그동안 무료로 Elastic 머신 러닝 피처를 사용하면서 데이터에서 노이즈를 제거할 때 어떤 인사이트를 얻을 수 있는지 직접 확인해 보세요.