사이버 보안에 대한 머신 러닝: 네트워크 데이터에서 DGA 활동 탐지
이 블로그 시리즈 1부에서는 Elastic Stack 머신 러닝을 사용하여 악성 도메인을 탐지하는 지도 분류 모델을 훈련하는 방법을 살펴보았습니다. 2부에서는 훈련한 모델을 사용하여 수집 시에 분류를 통해 네트워크 데이터를 보강하는 방법을 알아보겠습니다. Packetbeat 데이터에서 잠재적인 DGA 활동을 탐지하고자 하는 모든 분들에게 유용할 것입니다.
Elastic Stack을 사용한 DGA 탐지
시스템을 감염시키는 악성 프로그램은 흔히 공격자가 제어하는 서버, 즉 이른바 명령 및 제어(C&C 또는 C2) 서버와 다시 통신할 수 있는 방법이 필요하게 됩니다. 하드코딩된 IP 주소나 URL을 차단하는 방어 수단을 방해하기 위해 공격자는 DGA(도메인 생성 알고리즘)를 사용합니다. Malware는 C&C 서버에 접속해야 할 때 DGA를 사용하여 수백, 수천 개의 후보 도메인을 생성하고 각각에 대해 IP 주소를 해결하려고 시도할 것입니다. 그런 다음 공격자는 감염된 시스템과 통신할 수 있도록 DGA에서 생성된 도메인 중 하나 또는 몇 개만 등록해야 합니다. DGA는 수비자들의 차단과 탐지를 더욱 어렵게 하기 위해 다양한 방식으로 시드되고 무작위화됩니다.
DGA 활동은 대개 DNS 쿼리를 포함하기 때문에 감염된 시스템에서 만들어진 DNS 요청에 자주 나타나게 됩니다. Packetbeat는 DNS 트래픽을 수집하고 Elasticsearch로 전송하여 분석할 수 있습니다. 이 블로그 게시물에서는 Packetbeat 데이터의 DNS 쿼리 정보를 도메인이 얼마나 악성인지 나타내는 점수로 어떻게 보강할 수 있는지 살펴보겠습니다.

추론 프로세서 및 수집 파이프라인
양성 도메인과 악성 도메인을 구별하도록 훈련된 모델의 예측으로 Packetbeat 데이터를 보강하려면 적절한 추론 프로세서로 수집 파이프라인을 구성해야 합니다. 추론 프로세서는 사용자에게 Elastic Stack에서 훈련된 모델(또는 지원되는 외부 라이브러리 중 하나에서 훈련된 모델)을 사용하여 Elasticsearch로 수집되고 있는 새 문서에 대한 예측을 할 수 있는 방법을 제공합니다. 이 모든 움직이는 조각들이 어떻게 어울리고 어떤 구성이 필요한지 이해하기 위해 이 블로그의 1부로 잠시 돌아가 봅시다.
1부에서는 해당 도메인이 악성인지 여부를 예측하기 위한 분류 모델을 훈련하는 과정을 논의하였습니다. 이 프로세스의 단계 중 하나는 훈련 데이터, 즉, 이전에 보이지 않았던 새 도메인의 점수를 매기는 방법을 학습하는 데 우리 모델이 사용할 알려진 악성과 양성 도메인 집합에 대해 피쳐 엔지니어링을 수행하는 것입니다. 모델에 유용한 피처(유니그램, 바이그램, 트라이그램)를 추출하도록 원시 도메인을 조작해야 합니다. 그런 다음 악성에 대한 점수를 매기고자 하는 Packetbeat 데이터의 도메인에도 동일한 피처 엔지니어링 절차를 적용해야 합니다.
그렇기 때문에 추론 프로세서 외에 우리의 수집 파이프라인에는 수집 시 Packetbeat DNS 데이터에서 유니그램, 바이그램, 트라이그램을 추출하는 Painless 스크립트 프로세서도 포함됩니다. 전체 파이프라인을 보여주는 도표는 그림 2에 나와 있습니다.
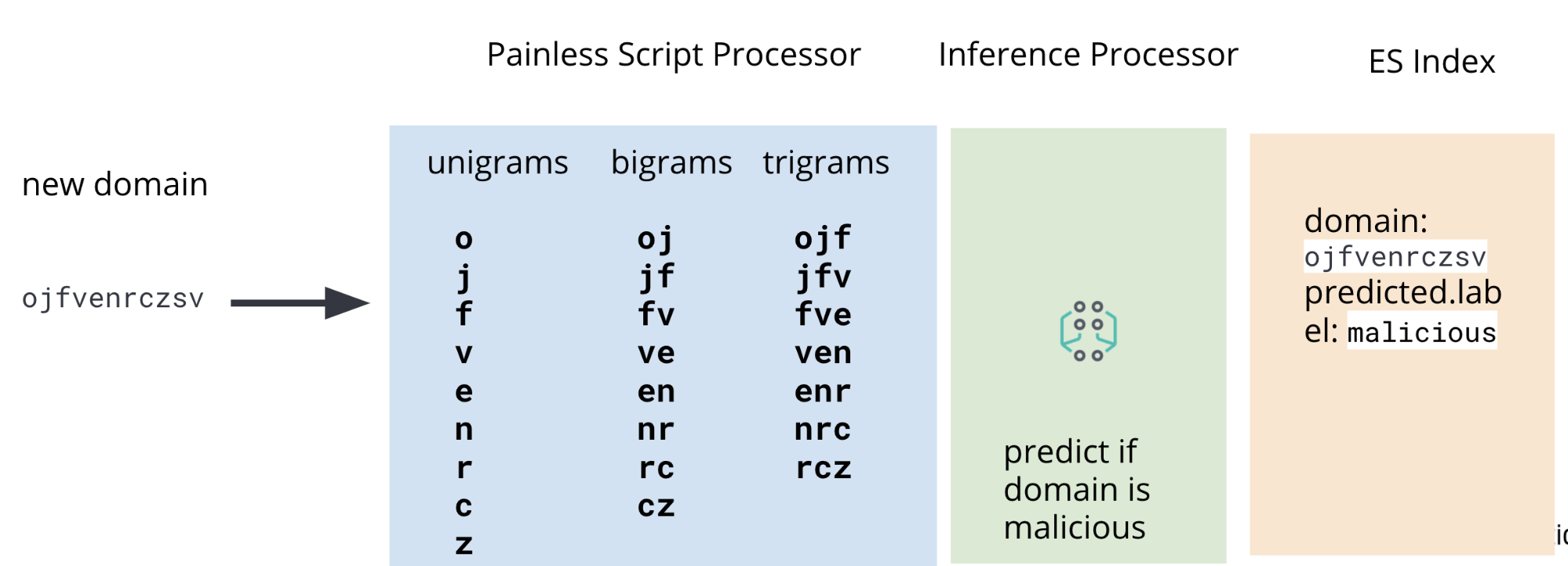
Packetbeat 데이터 내에서, 우리가 운용하고 싶은 필드는 DNS 등록 도메인입니다. 이 필드에 관심 있는 도메인이 포함되지 않는 일부 엣지 케이스가 있긴 하지만, 이 블로그의 목적을 위한 사용 사례를 설명하기에는 충분할 것입니다. 그림 3의 이미지는 예제 Packetbeat 문서의 관심 필드를 보여줍니다.

dns.question.registered_domain이 됨dns.question.registered_domain에서 유니그램, 바이그램, 트라이그램을 추출하려면 그림 4에 나와 있는 것과 같은 Painless 스크립트를 사용해야 합니다.
POST _scripts/ngram-extractor-packetbeat
{
"script": {
"lang": "painless",
"source": """
String nGramAtPosition(String fulldomain, int fieldcount, int n){
String domain = fulldomain.splitOnToken('.')[0];
if (fieldcount+n>=domain.length()){
return ''
}
else
{
return domain.substring(fieldcount, fieldcount+n)
}
}
for (int i=0;i<ctx['dns']['question']['registered_domain'].length();i++){
ctx['field_'+Integer.toString(params.ngram_count)+'_gram_'+Integer.toString(i)] = nGramAtPosition(ctx['dns']['question']['registered_domain'], i, params.ngram_count)
}
"""
}
}
필요한 피처를 추출한 후, 여전히 수집 파이프라인을 통과하는 문서는 추론 프로세서를 거치게 되며, 이 추론 프로세서에서 이전 편에서 훈련된 분류 모델이 추출된 피처를 사용하여 예측을 하게 됩니다. 마지막으로 모델에 필요한 모든 추가 피처로 인덱스를 어수선하게 하고 싶지 않기 때문에 일련의 Painless 스크립트 프로세서를 추가하여 유니그램, 바이그램, 트라이그램이 포함된 필드를 제거합니다.
따라서 수집 파이프라인의 끝에서 우리가 수집할 것은 머신 러닝 예측의 결과를 포함하는 새로운 추가 필드의 Packetbeat 문서입니다. 샘플 수집 파이프라인 구성은 그림 5에 나와 있습니다. 자세한 내용은 예제 리포지토리를 참조하세요.
PUT _ingest/pipeline/dga_ngram_expansion_inference
{
"description": "Expands a domain into unigrams, bigrams and trigrams and make a prediction of maliciousness",
"processors": [
{
"script": {
"id": "ngram-extractor-packetbeat",
"params":{
"ngram_count":1
}
}
},
{
"script": {
"id": "ngram-extractor-packetbeat",
"params":{
"ngram_count":2
}
}
},
{
"script": {
"id": "ngram-extractor-packetbeat",
"params": {
"ngram_count":3
}
}
},
{
"inference": {
"model_id": "dga-ngram-job-1587729368929",
"target_field": "predicted_label",
"field_mappings":{},
"inference_config": { "classification": {"num_top_classes": 2} }
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params":{
"ngram_count":1
}
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params":{
"ngram_count":2
}
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params": {
"ngram_count":3
}
}
}
]
}
모든 Packetbeat 문서가 DNS 요청을 기록하는 것은 아니기 때문에, 수집된 문서에 필요한 DNS 필드가 있고 비어 있지 않은 경우에만 수집 파이프라인이 조건부로 실행되도록 해야 합니다. 파이프라인 프로세서(그림 6의 구성 참조)를 사용하여 원하는 필드가 존재하고 채워져 있는지 확인한 다음, 그림 5에서 정의한 dga_ngram_expansion_inference 파이프라인으로 문서 처리를 리디렉션하면 됩니다. 아래 구성은 프로토타입에 적합하지만, 프로덕션 사용 사례의 경우 수집 파이프라인에서 오류 처리를 고려해야 합니다. 전체 구성 및 지침은 예제 리포지토리를 참조하세요.
PUT _ingest/pipeline/dns_classification_pipeline
{
"description": "A pipeline of pipelines for performing DGA detection",
"version": 1,
"processors": [
{
"pipeline": {
"if": "ctx.containsKey('dns') && ctx['dns'].containsKey('question') && ctx['dns']['question'].containsKey('registered_domain') && !ctx['dns']['question']['registered_domain'].empty",
"name": "dga_ngram_expansion_inference"
}
}
]
}
이상 징후 탐지를 추론 결과에 대한 2차 분석으로 사용
이 시리즈의 1부에서 훈련한 모델은 2%의 오탐율을 보였습니다. 이것은 상당히 낮게 들리지만, DNS 트래픽은 대개 볼륨이 높다는 것을 명심해야 합니다. 따라서 2%의 오탐율이 있더라도 다수의 쿼리가 악성인 것으로 채점될 수 있습니다. 오탐의 수를 줄이는 한 가지 방법은 추가 피처 엔지니어링 구조에서 작업하는 것입니다. 또 다른 방법은 우리의 분류 결과에 대한 이상 징후를 탐지하는 것입니다. Elastic Stack에서 후자를 수행하는 방법을 살펴봅시다.
가장 먼저 관찰해야 할 것은 보강된 Packetbeat 문서를 가지고 시간에 대해 악성으로 표시된 문서의 수를 그림으로 나타내면, 시계열을 얻게 된다는 점입니다(그림 7).
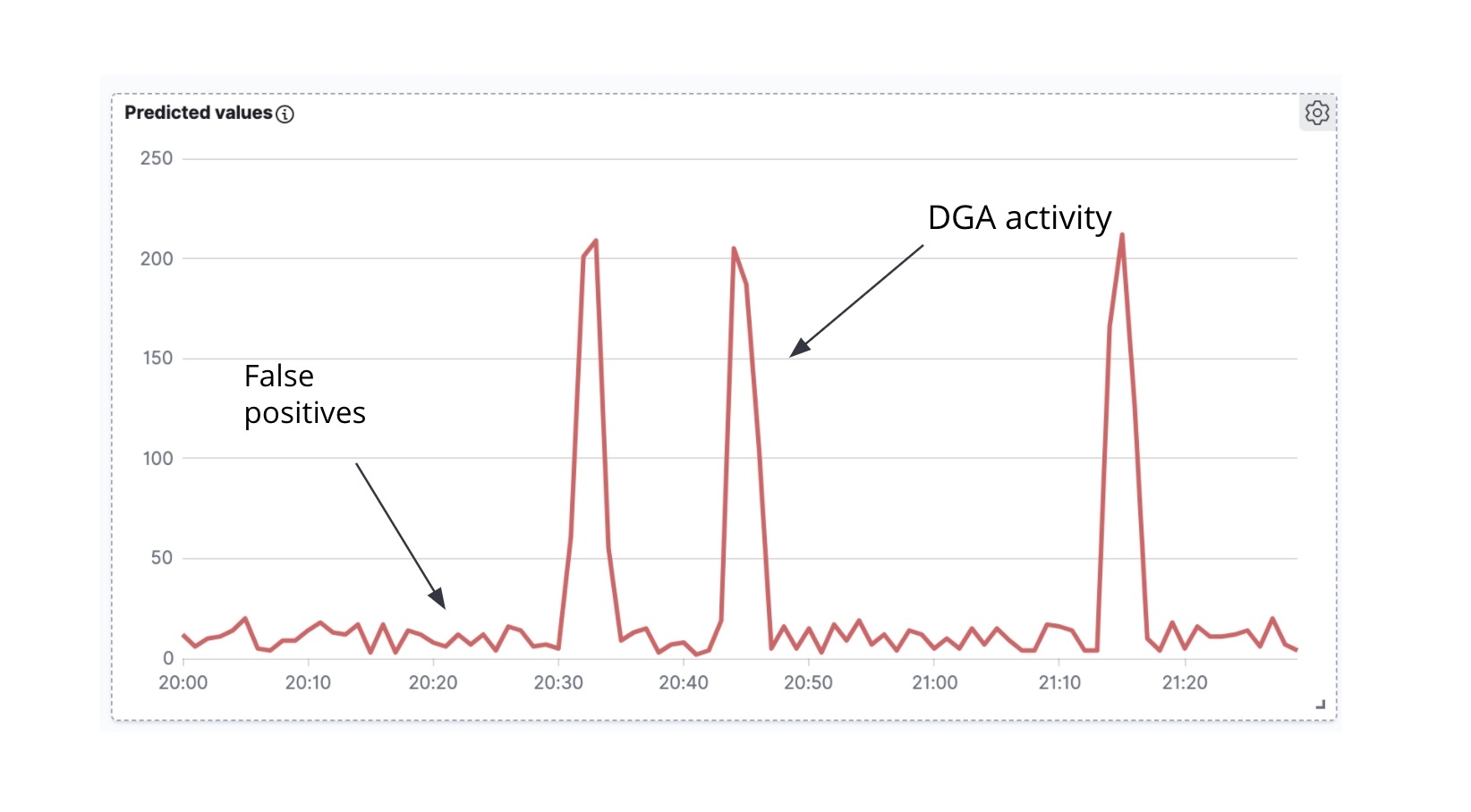
두 번째로 유의해야 할 것은 DGA Malware가 C&C 서버와 적극적으로 통신을 시도할 때 DNS 요청의 파장을 한 번에 생성하는 경향이 있다는 점입니다. (즉, Malware는 알고리즘에 의해 생성된 많은 도메인을 순환하며 각 도메인의 IP 주소를 해결하려고 합니다.) 시간 경과에 따른 예측 악성 도메인의 시계열 분석(그림 6)에서 활동 피크와 피크 사이의 작은 노이즈를 확인할 수 있습니다. 이 피크들은 우리의 분류 모델이 짧은 기간 동안 많은 도메인을 악성으로 분류했고 따라서 우리가 진정한 DGA를 다루고 있을 가능성이 높다는 것을 나타냅니다. 이와는 대조적으로, 피크 사이의 배경 소음은 대부분 오탐의 결과일 가능성이 높습니다. 우리가 이 시계열에서 high_count 이상 징후 탐지 작업에 인코딩을 하려고 하는 것은 바로 이 직관입니다.
그림 7의 시계열과 함께 이상 징후 탐지 수영 레인을 오버레이하면 시계열의 피크(진정한 DGA 활동)에 해당하는 이상 징후 경보가 표시되며, 피크 사이의 간격에는 아무런 경보(오탐의 배경 소음)도 표시되지 않는 것을 알 수 있습니다.
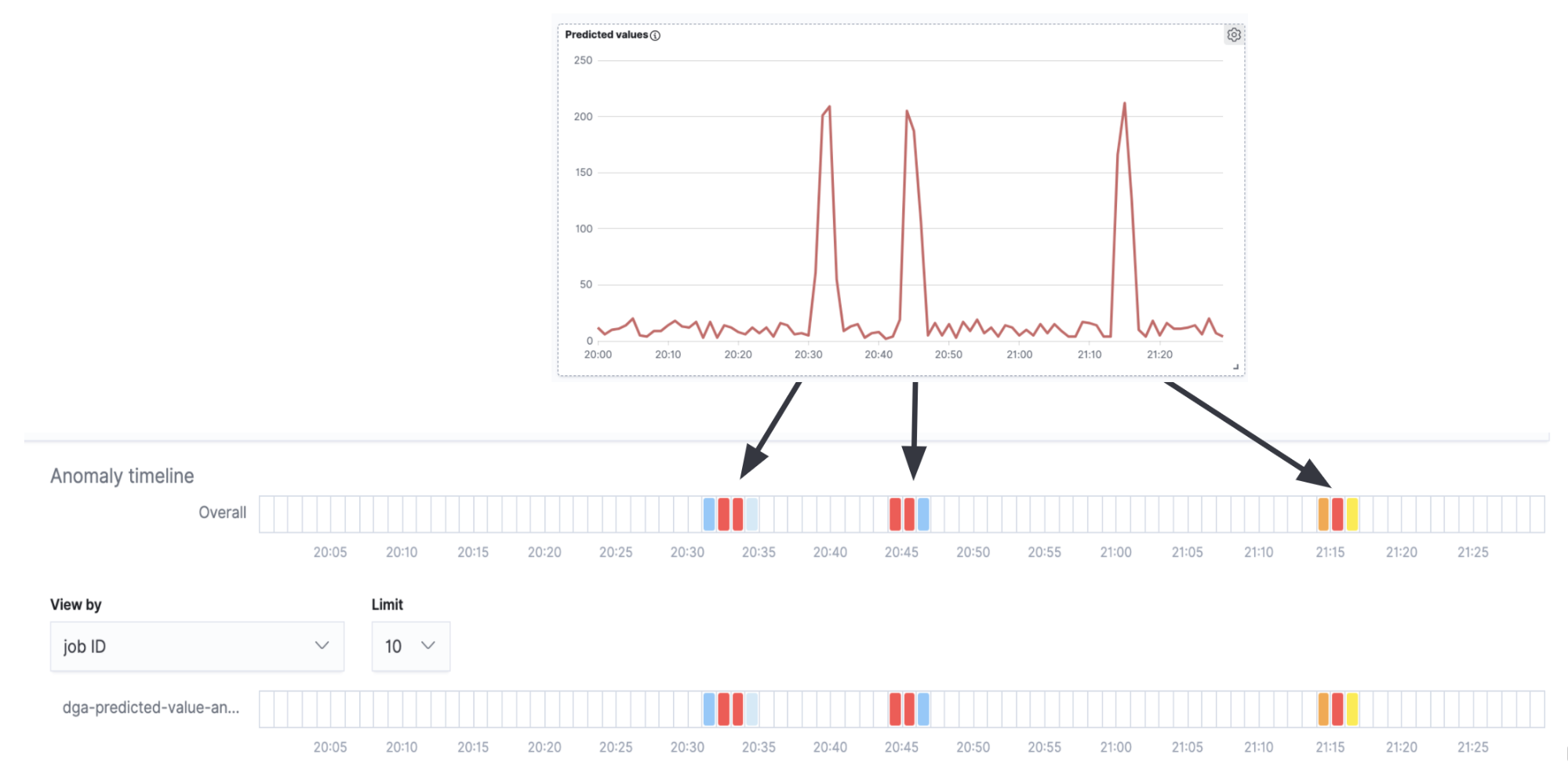
이는 매우 간단한 예로서 프로덕션 사용 사례의 경우 보다 세밀한 조정과 구성이 필요할 수 있지만, 그럼에도 불구하고 이상 징후 탐지 작업은 추론 결과에 대한 2차 분석으로 효과적으로 사용될 수 있음을 보여줍니다.
결론
이 게시물에서는 수집 시 네트워크 데이터(Packetbeat 문서)를 보강하기 위해 훈련된 분류 모델을 이용했습니다. 추론 프로세서와 수집 파이프라인에 의해 촉진되는 보강 프로세스는 DNS 요청 중에 쿼리된 각 도메인에 예측 라벨을 추가합니다. 이것은 그 도메인이 얼마나 악성일 수 있는지를 보여줍니다. 아울러 오탐 경보를 줄이기 위해 추론 결과에 이상 징후 탐지 작업을 사용하는 방법도 조사했습니다. 또한 Elastic SIEM에서 DGA 탐지를 위한 큐레이팅된 구성과 모델을 제공할 계획입니다.
자체의 네트워크 데이터로 직접 사용해보고 싶으시면 14일 동안 Elasticsearch Service 무료 평가판을 가동해 수집과 분석을 시작하세요. 또한 로컬로 Elastic Stack을 다운로드하고 평가판 라이센스를 시작하여 30일 동안 무료로 머신 러닝을 시험 사용해보실 수 있습니다. 또는 무료 개방형 Elastic SIEM을 사용하여 지금 바로 데이터 보호를 시작하세요.