



ECE 2.0: Host Tagging, ML, Hot-Warm Architecture, and More
When Elastic Cloud Enterprise (ECE) was first released over a year ago, we were all very excited and cautiously optimistic. ECE was built to provide a centralized and easy way to provision, manage, and scale your entire Elasticsearch fleet. The challenges that came with building a solution to manage a massive Elasticsearch fleet is something we knew too well — we faced them ourselves while building our own Elasticsearch Service!
ECE was built on exactly the same code base we used to run the Elasticsearch service, but packaged so that users can deploy it anywhere and enjoy the same battle tested software with the same set of features used to manage thousands of clusters across multiple cloud providers.
We quickly learned that ECE was being adopted by not only big companies managing large number of clusters but also companies with smaller workloads. It seemed everyone was finding a reason to use ECE.
During the past year we had an opportunity to learn from ECE users, improve our offering, and understand what the next step in its evolution should be. We are now thrilled to announce the release of a leaner, meaner, and better than ever version: ECE 2.0!
There are many goodies included with this version. Here are a few of the features we’re most excited about.
Any use case. At any scale.
The main area focus of ECE 2.0 was to better support larger and more complicated use cases such as logging and time-series data, and allow admins better control on how these use cases are being deployed and configured by cluster owners. Here are the major features that make this possible.
Tag it like you own it
Tags are key-value pairs that are added to each allocator host. This is a concept well-known to those coming from the world of cloud and container orchestration, where pairing is done using labels and selectors. ECE 2.0 now introduces allocator tagging, which allows you to add arbitrary tags to an allocator to help classify it. This can include an indication for which team it belongs to, its underlying hardware specs and essentially any other identifier that would help you classify this allocator. These tags are later used to match cluster nodes and Kibana instances to the allocator best fit to host them.
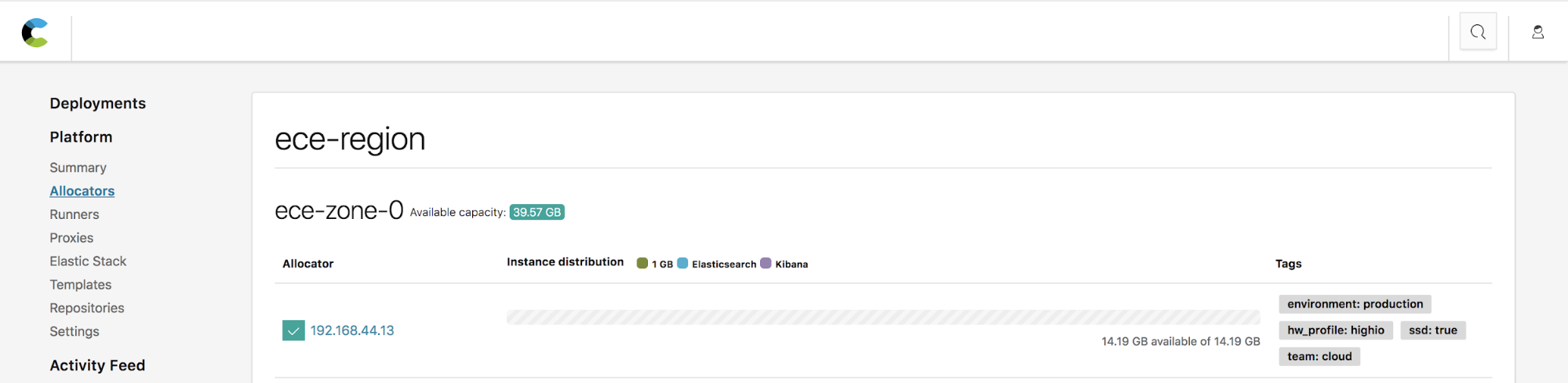
Instance configuration, tailored just for you
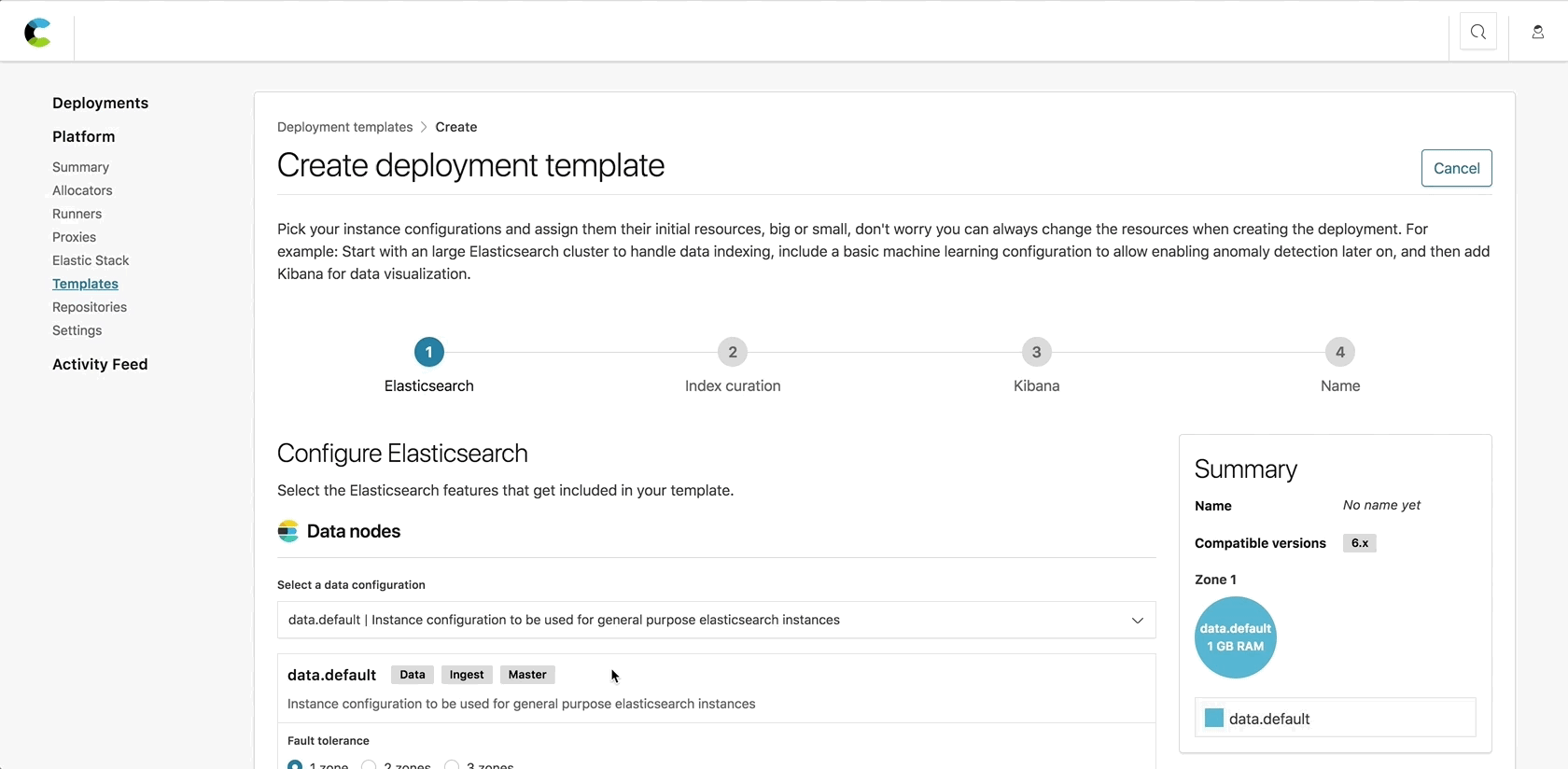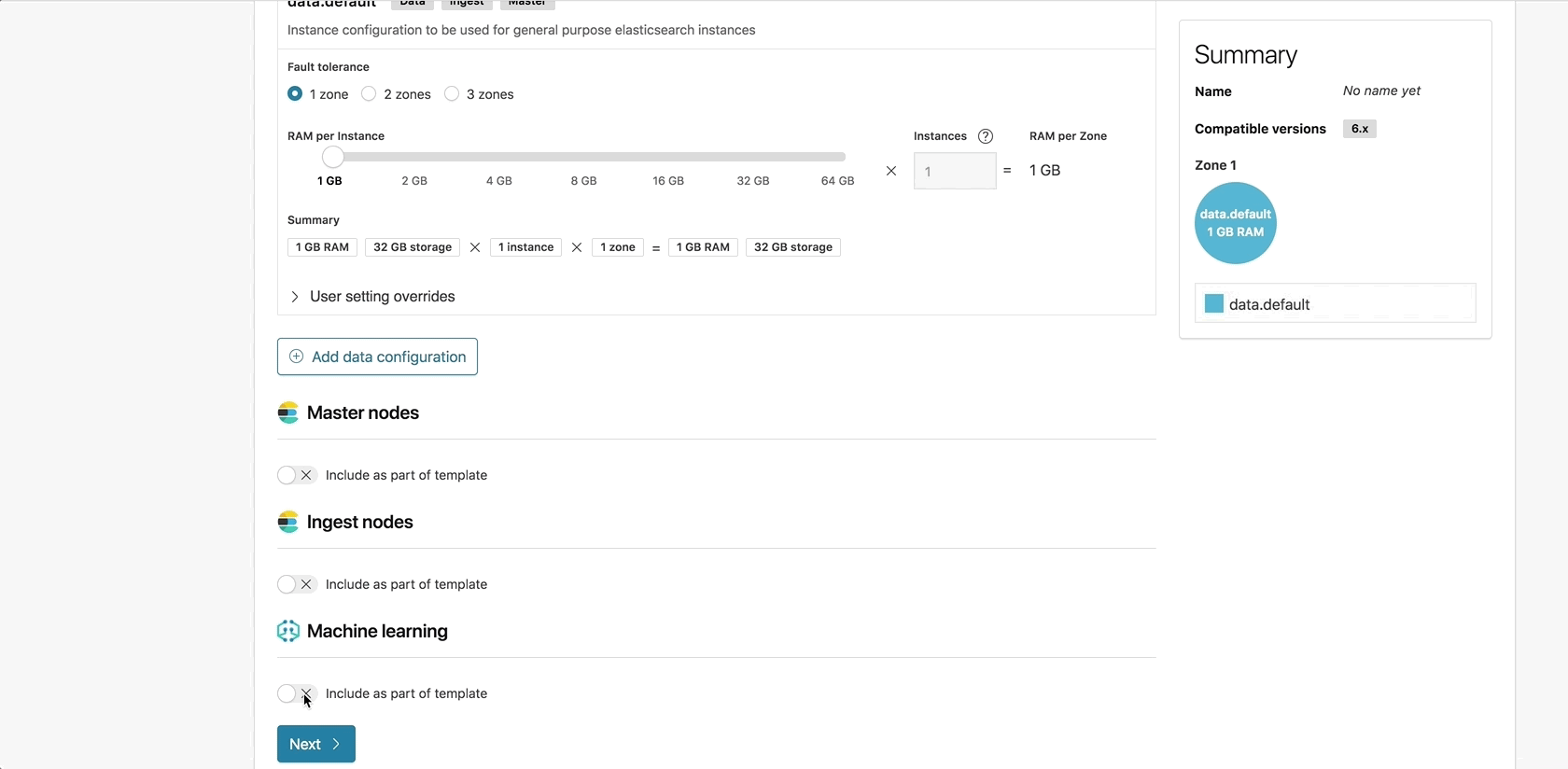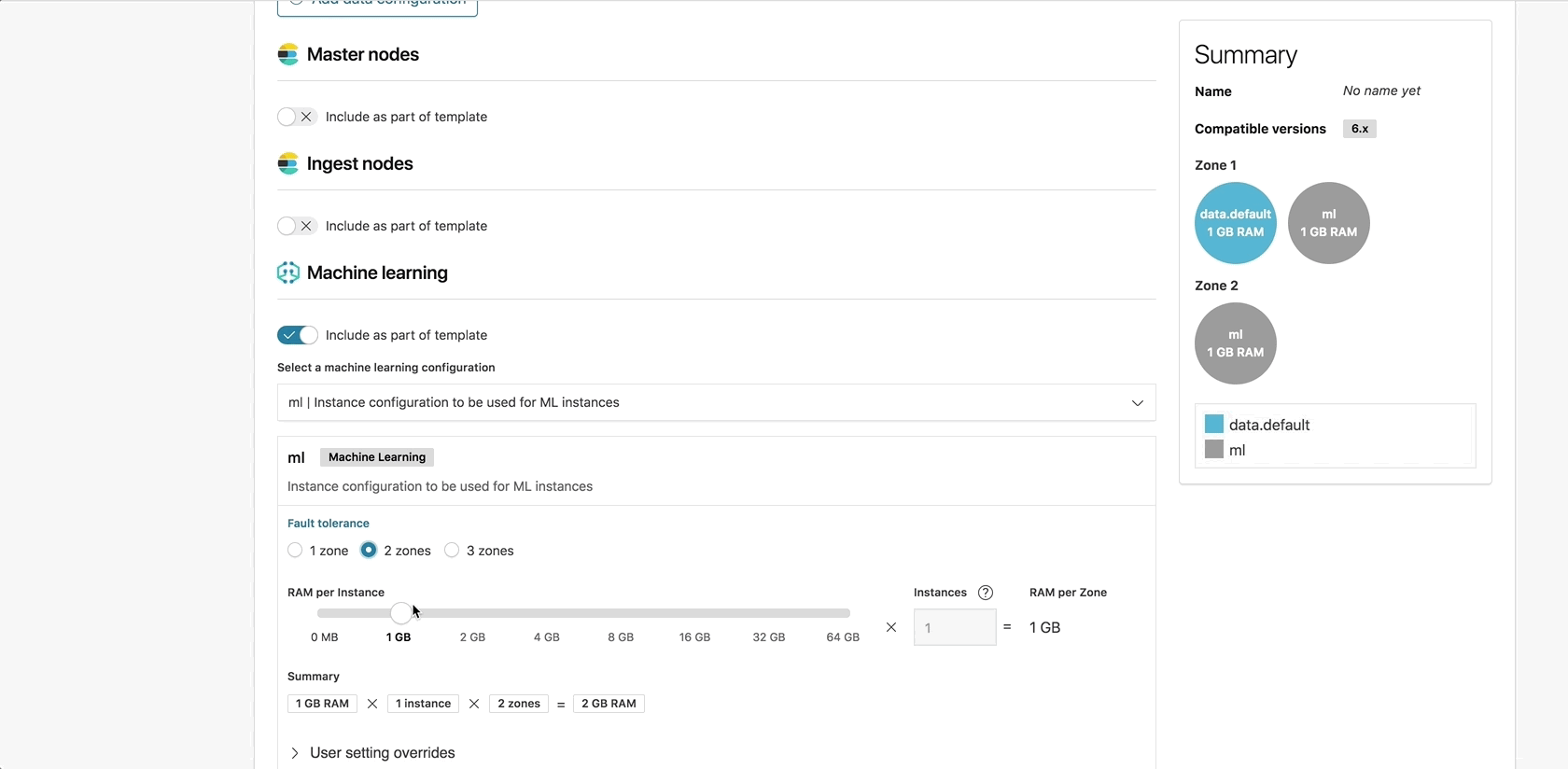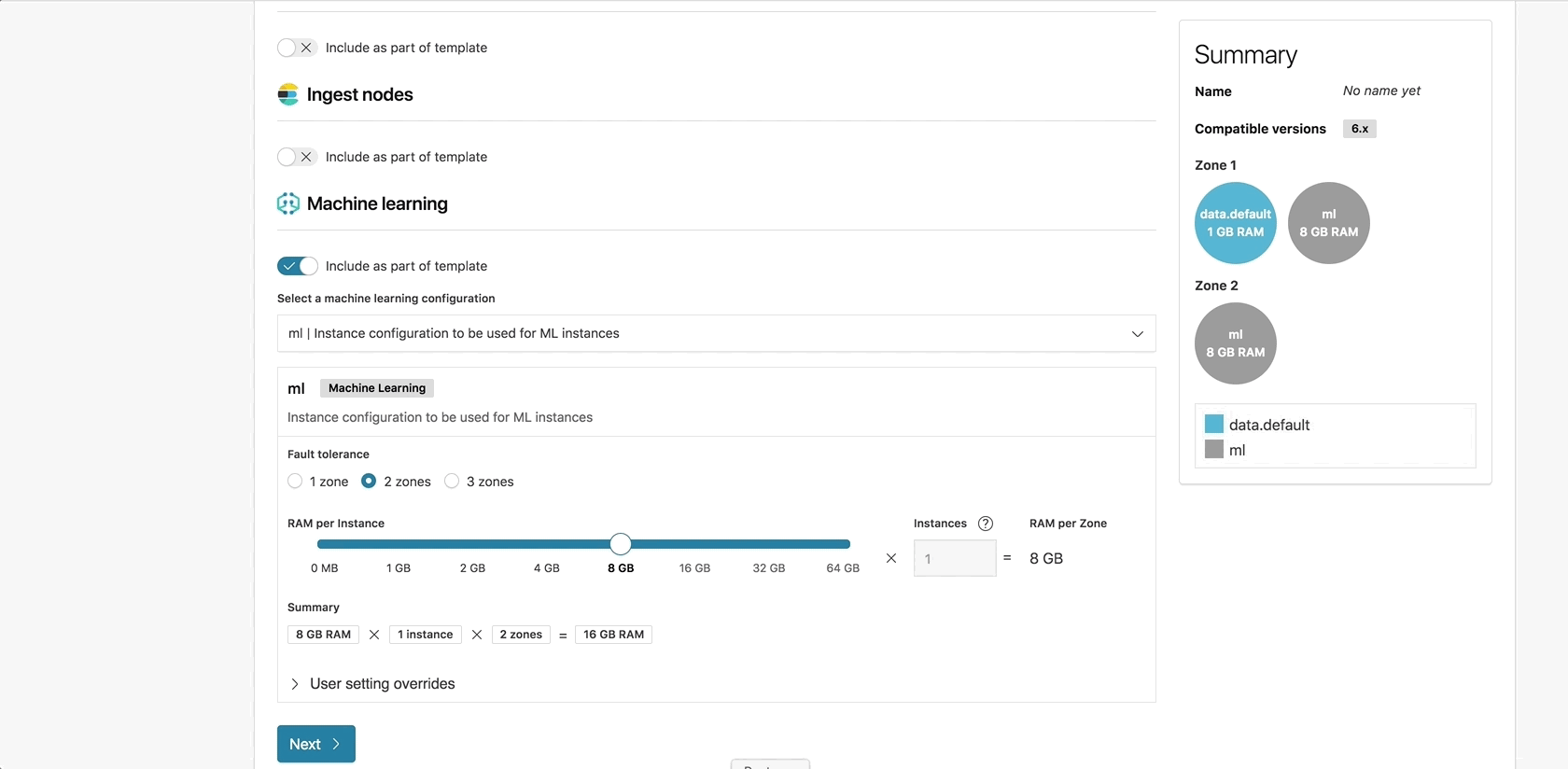
In older ECE versions, all Elasticsearch nodes were born equal. They shared the same configuration, and had the same roles enabled. This limited a user’s ability to manage each node type separately, which for many use cases is a necessary requirement.
With ECE 2.0 you can deploy, manage, and scale each component in your cluster independently. Instance configurations, available on ECE 2.0, allow you to determine which roles to enable on each node, configure filters that match a node to an allocator host using the tags mentioned above, and set the RAM to storage ratio based on the node’s intended use.
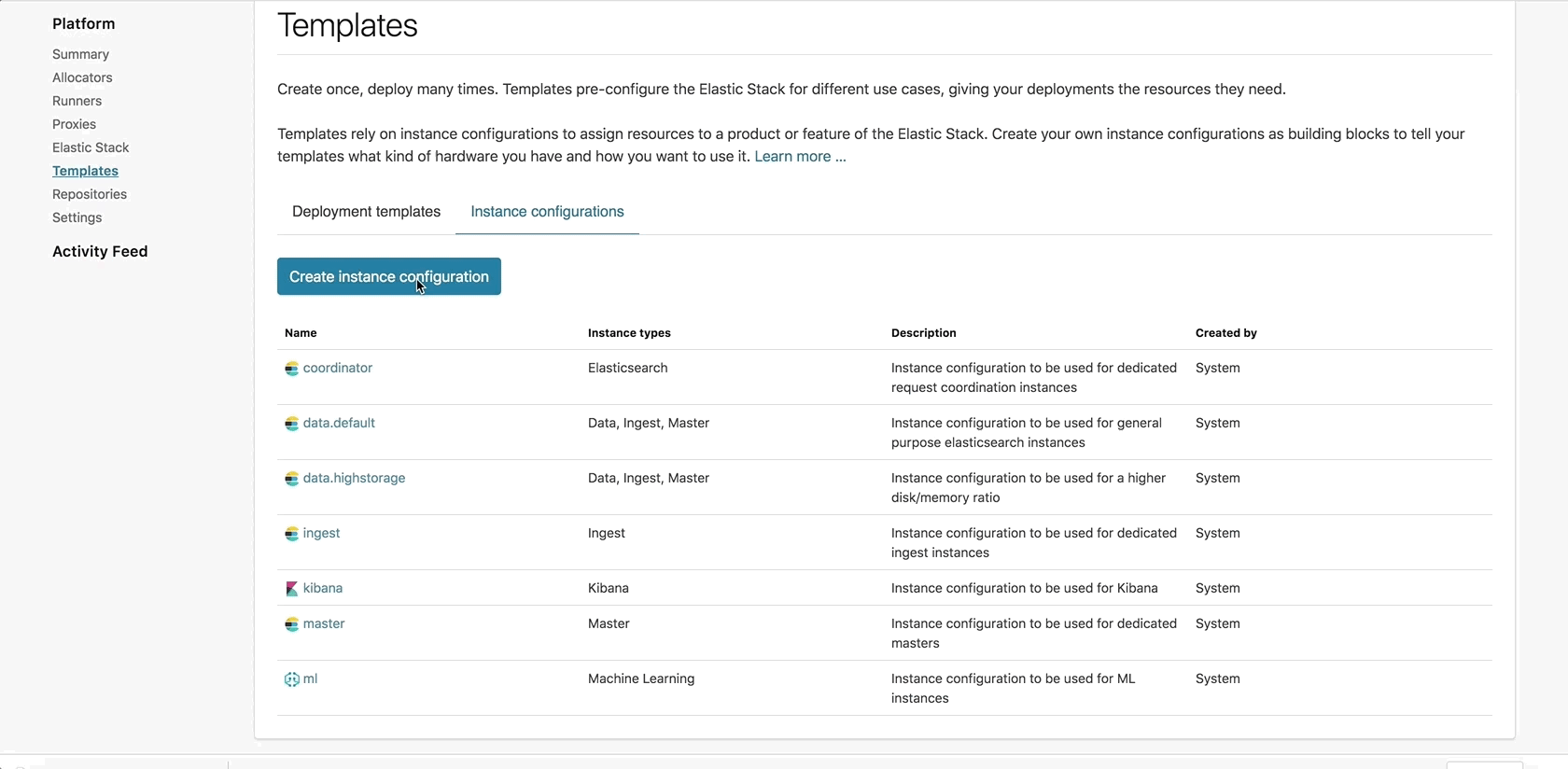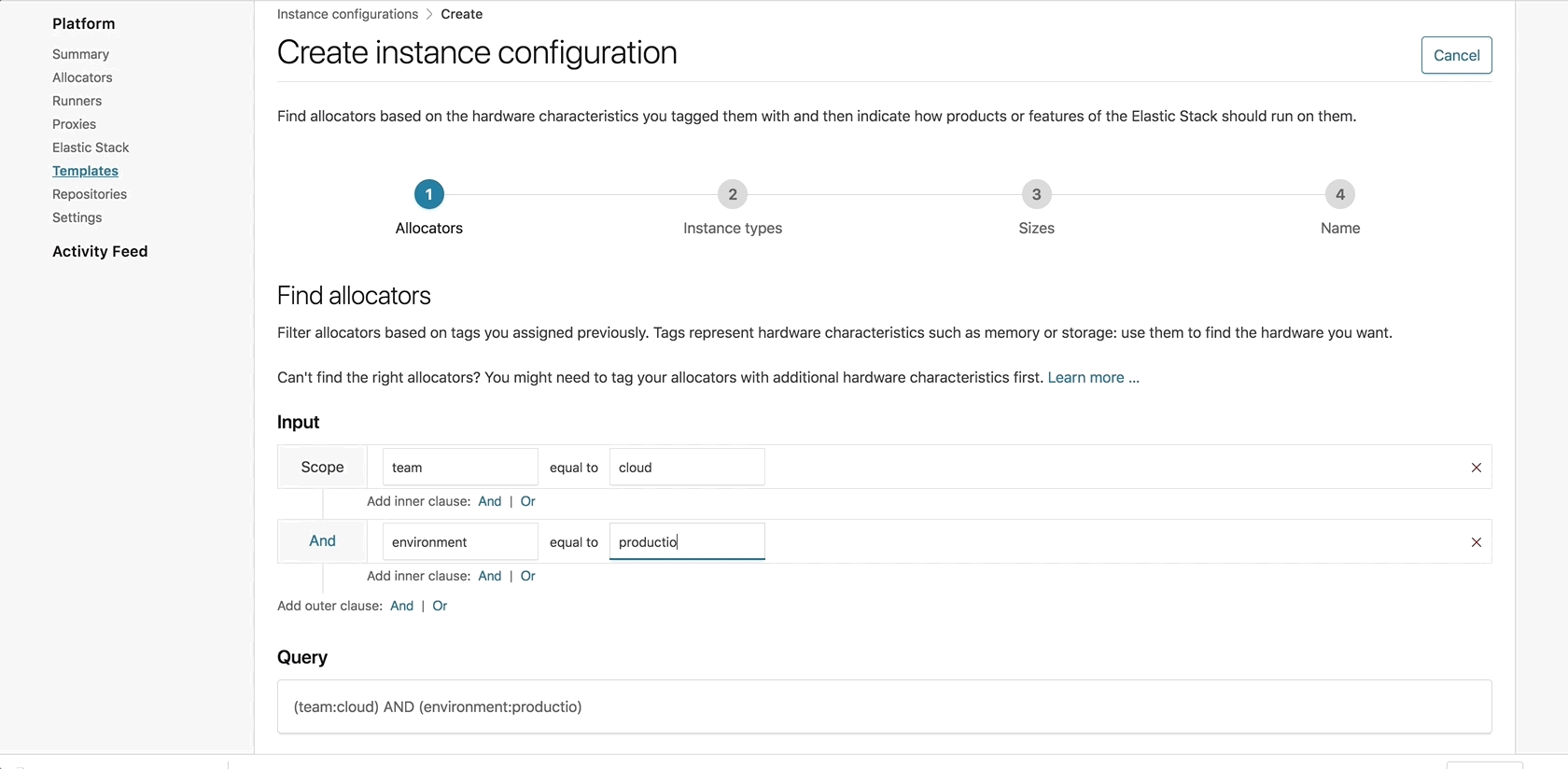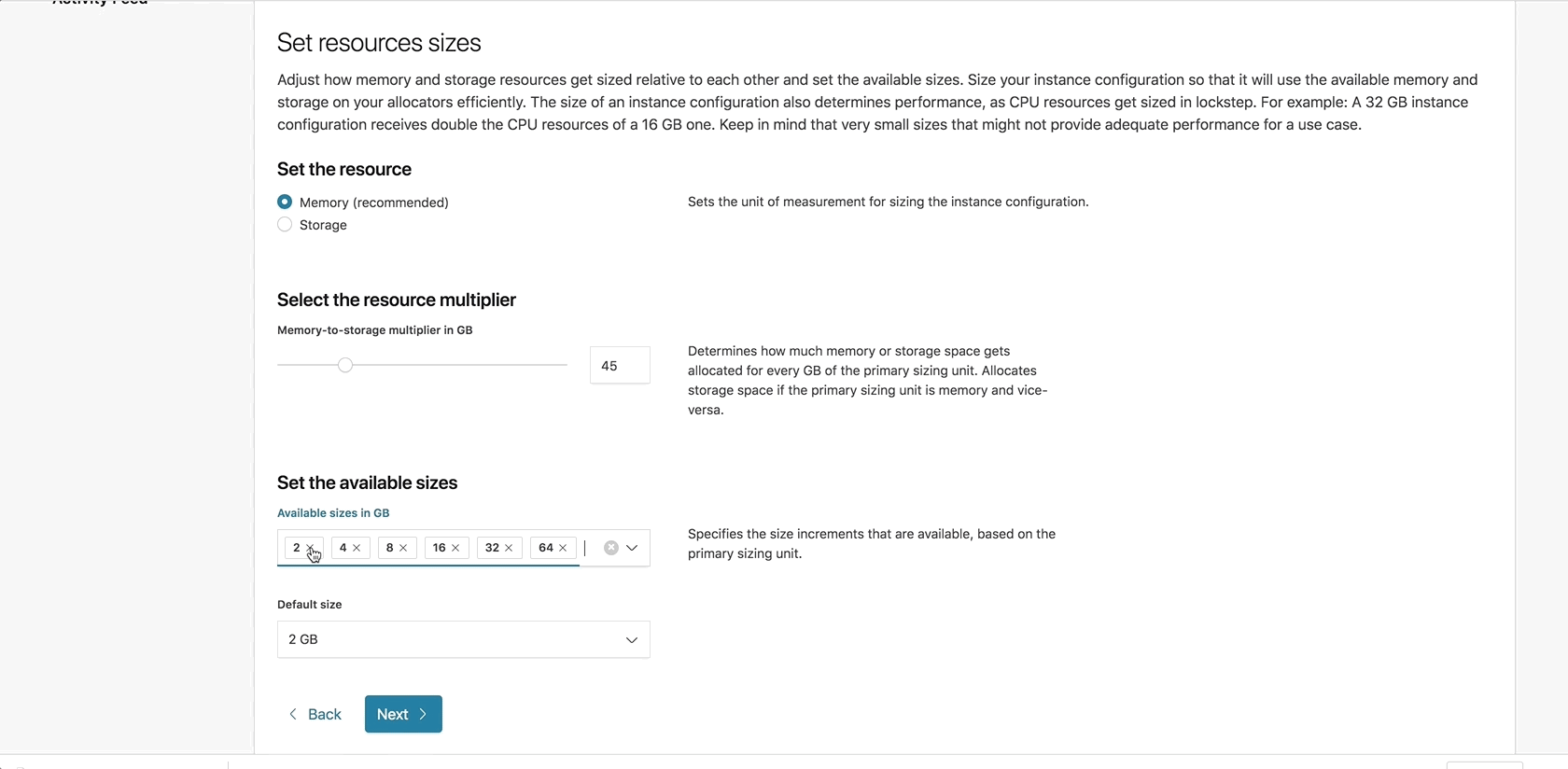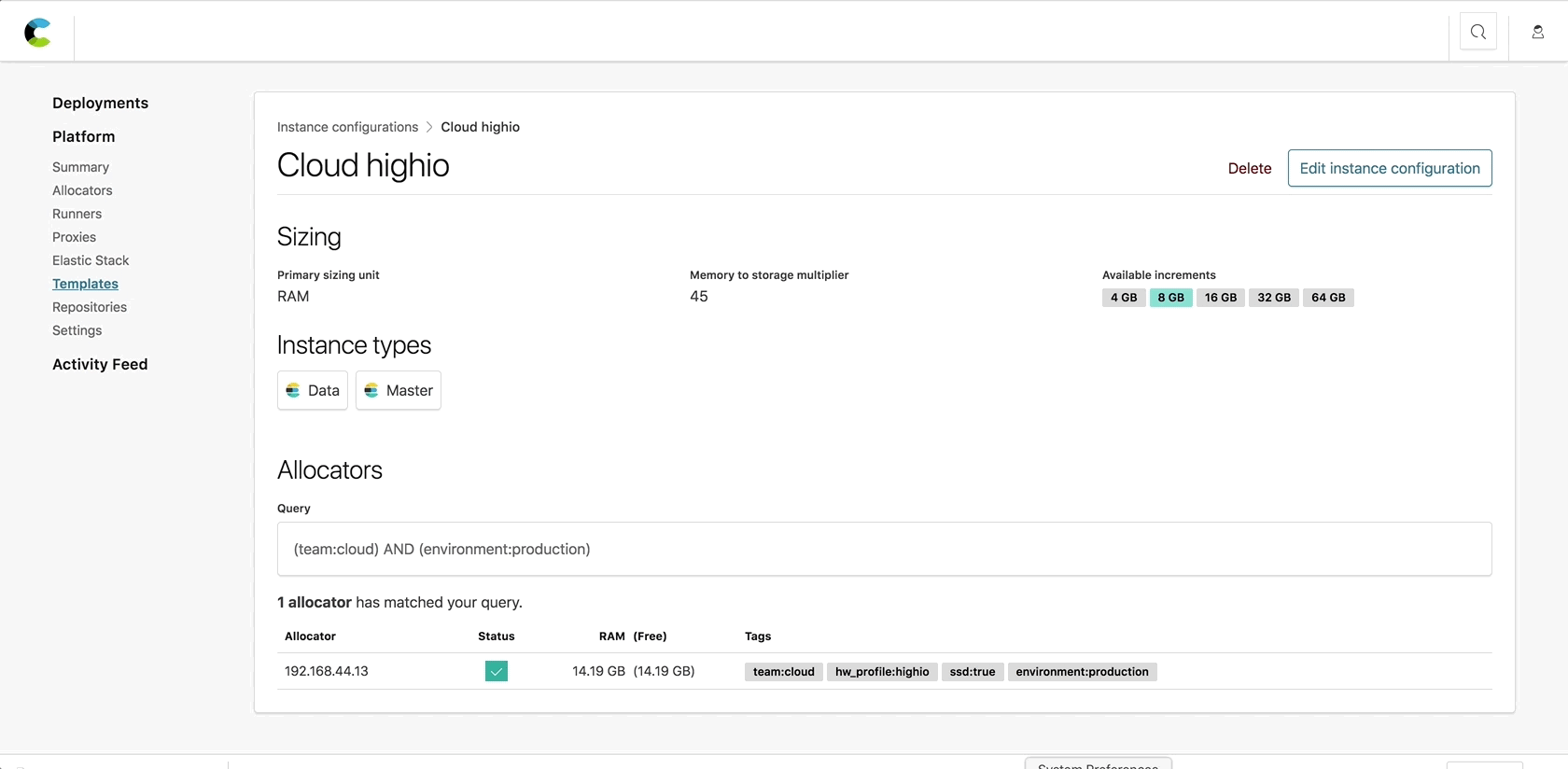
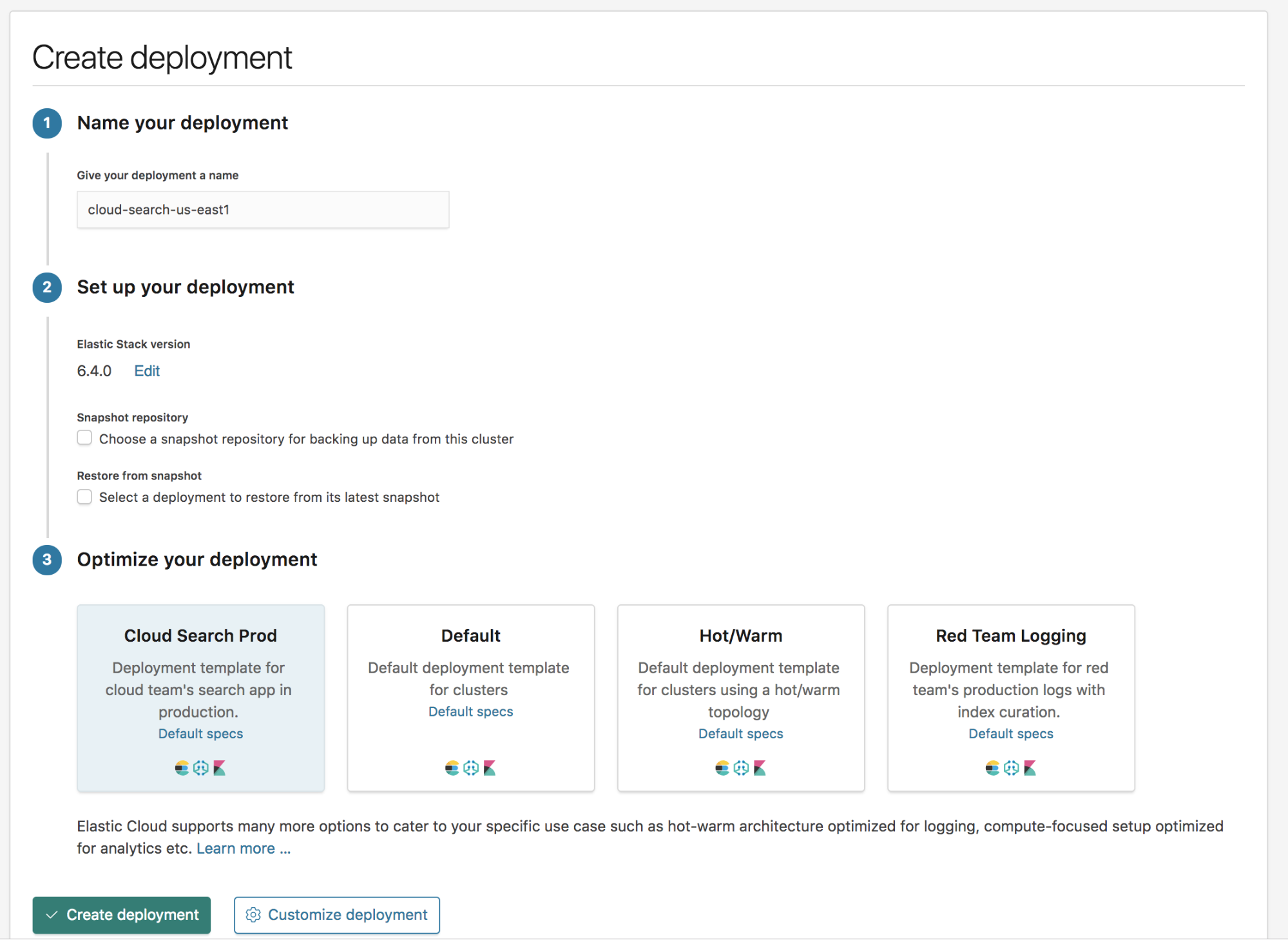
Introducing: deployment templates
Some of the most versatile tools in your console are the new customizable deployment templates. A deployment template groups a set of instance configurations of different node types together as a blueprint for your cluster. With deployment templates, you can determine the default values and configurations for each node type such as node size, number of availability zones, etc.
You can also create your own templates, which you can configure according to use case, team, or anything else that requires a unique set of allocators. Deployment templates offer preconfigured settings when creating a new cluster, which will help you streamline your deployment process every step of the way.
Using the Elastic Stack for time-series indices? You’re going to like this
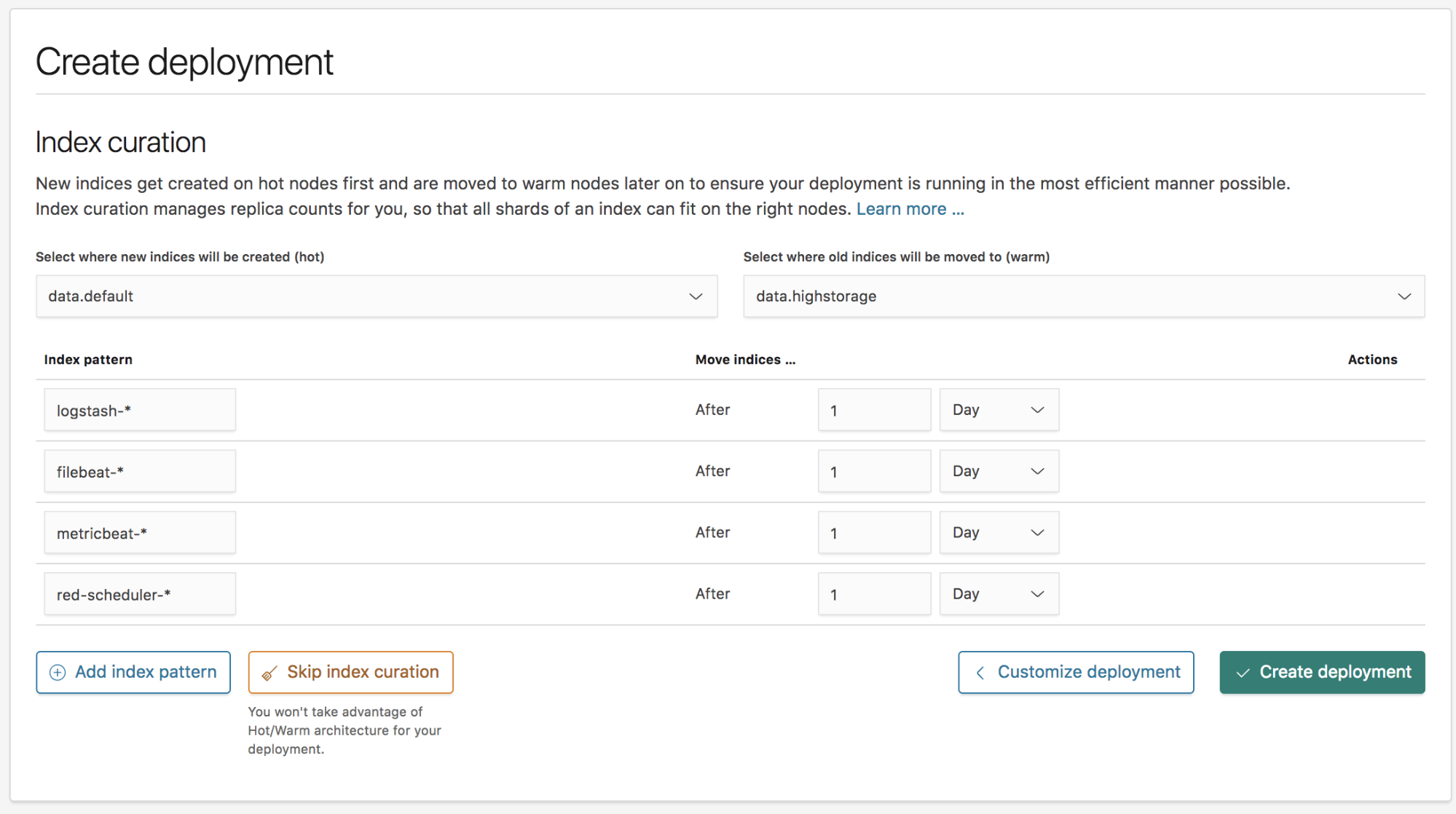
A common use case for the Elastic Stack is ingesting time series data, such as log messages. In such scenarios we often recommend using a hot-warm architecture, especially at larger scale.
With ECE 2.0 we have included a built-in hot-warm architecture template that will allow you to configure two different data node tiers. Hot data nodes will be used to ingest data and store the more recent indices, which are also more likely to be searched and should be deployed on a more robust hosts with better I/O performance. Your warm data nodes are meant to store large amounts of longer term data retention. In most cases, older data is immutable and is accessed much less frequently, which means it can be stored on cheaper allocator hosts with spinning disks that provide less performant results but are far cheaper for data storage.
To configure when to roll over indices from the hot to the warm tier, ECE 2.0 offers built-in index curation that will allow you to configure those time periods so that you can sit back and relax, while ECE takes care of the rest.
How these features come together
It is no secret that the Elastic Stack is versatile and can be used for a variety of use cases such as log analytics, security analytics, metrics, search, and more. When creating a deployment, users may find that individual use cases work better when run on a a specific hardware profile. Furthermore, even within the same cluster, it may make sense to run each node type on an allocator host paired with the relevant profile. For example, your Kibana instances may work best on a host with more RAM and not a lot of storage, whereas your machine learning nodes, while also not requiring a lot of storage, are happiest on a host with a bit more CPU.
ECE 2.0 host tagging, instance configurations, and deployment template features provide you with much more flexibility and control in managing your clusters. It also opens the gate for natively supporting different hardware profiles, optimising hardware utilization while improving performance, and reducing costs.
There are several ways in which you can leverage these features within your use case, and we will dedicate a future blog post to a deeper dive into them. We will also provide further examples of how to implement the right configuration for your needs.
Unleash the power of machine learning
As described in the instance configuration section, users could not enable specific roles on each node in the cluster in previous ECE versions. This prevented us from officially supporting machine learning in hosted clusters, since running machine learning jobs in a production environment required dedicated machine learning nodes.
With the Introduction of instance configurations, you can now configure dedicated machine learning nodes and manage and scale those nodes separately from the rest of the nodes in your cluster.
You can also leverage instance configurations to create dedicated master nodes which are required to support larger clusters or dedicated ingest nodes. This is especially useful if you’re utilizing heavy ingest-time processing and wish to scale your ingest layer as you add more pipelines to further enrich your data.
Support for latest Docker version on Ubuntu
You can now install ECE on Ubuntu 16.04 with Docker 18.03! This is an important update, since ECE 1.x only supported Docker 1.11, which has officially reached its end of life a while ago. Now you can upgrade the Docker engine on all ECE nodes!
Going forward, we will introduce support for new Docker versions on a more regular cadence to align with the bi-yearly Docker LTS support.
SAML Authentication for Deployments
ECE already brings security and authentication integrations, such as LDAP/AD, to all your deployments. With ECE 2.0, we are expanding your authentication integration options to include SAML authentication.
Upgrade Compatibility
While ECE 2.0.0 is a major release, all the functionality described above is backwards compatible. That means you can upgrade to ECE 2.0.0 from your ECE 1.x installation and take full advantage of the changes.
Look at all the pretty colors
A lot of work was done on the user console side to improve usability. Just to name a few:
- Clusters are out. Deployments are the new thing: As we introduce support for additional products from the Elastic Stack, we feel it's only right to use a more generic term for what’s being created in ECE. While an Elasticsearch cluster is an important part of any deployment, the new “deployment” term better describes how the Elastic Stack is being managed in ECE.
- Create deployment workflow: A new "Create Deployment" workflow was needed to support instance configurations and deployment templates. This new workflow allows you to tweak configurations, save defaults for deployments, and create a new deployment by simply selecting your template of choice.
- Easier navigation: Navigation was updated to make it easier for you to find your way around the UI and edit your deployments. Also, the overview page for all deployments and when drilling down into a specific deployment received a necessary facelift, now displaying more relevant information and available actions.
- Let there be night: If you like working when the sun is hiding, you can set ECE to use a night theme to ease strain on your eyes and to enjoy a little bit of darkness.
There are a lot more new features where that came from in ECE 2.0. Read all about them in the release notes. Want to try it out yourself? Take ECE 2.0 for a spin with a 30 days free trial and let us know what you think!