単語埋め込みとは何ですか?
単語埋め込みの定義
単語埋め込みとは自然言語処理(NLP)で使用される技法で、単語を数値で表してコンピュータが扱えるようにします。これは学習による文字の数値表現として広く使用されているアプローチです。
機械が単語を扱うには手助けが必要なため、各単語に数値による形式を割り当てて、処理できる形にする必要があります。これはいくつかの異なる方法があります。
- ワンホットエンコーディングは、テキスト本文の各単語に一意の数値を割り当てます。この数値を、その単語を表す0と1を複数個使用した二進数ベクトルに変換します。
- カウントベースの手法では、ある単語が本文に出てくる回数を数えて、対応するベクトルをその単語に割り当てます。
- SLIMコンビネーションではこの両方の手法を活用し、コンピュータは単語の意味と、それが文章に出てくる頻度の両方を理解できます。
単語埋め込みでは高次元空間を作成し、そこで各単語に数値の密なベクトル(後ほど詳しく説明)を割り当てます。コンピュータは次にこれらのベクトルを使用して単語間の関係性を理解し、予測を行います。
単語埋め込みは自然言語処理においてどのように作用するのでしょうか?
単語埋め込みは自然言語処理で作用し、場合によっては最大1000次元の高次元空間における実数の密なベクトルとして単語を表現します。ベクトル化とは、単語を数値ベクトルに変換する処理のことです。密なベクトルとは、ほとんどのエントリがゼロではないベクトルのことです。これは多くのゼロエントリを持つワンホットエンコーディングのようなまばらなベクトルとは真逆です。この高次元空間は、埋め込み空間と呼ばれます。
よく似た意味を持つ単語やよく似た文脈で使用される単語は、よく似たベクトルに割り当てられます。つまり埋め込み空間内でお互いが近くに配置されるということです。例えば「お茶(tea)」と「コーヒー(coffee)」は似た単語なのでお互いが近くに配置されますが、「お茶(tea)」と「海(sea)」は綴りこそ似ていますが意味が全く異なり、一緒に使われることがあまりないため、離れて配置されます。
自然言語処理では単語埋め込みの作成にさまざまな手法があるものの、いずれもコーパスと呼ばれる膨大な量の文章データでの訓練を伴います。コーパスにはさまざまな種類があり、WikipediaとGoogle Newsは、事前訓練した埋め込みコーパスに使用される一般的な2つの例です。
コーパスはカスタムの埋め込み層でもあり、他の事前訓練したコーパスが十分なデータを供給できない場合のユースケースとして特別に設計されています。訓練中に、モデルはそのデータにおける単語の使用パターンに基づいて、各単語を一意のベクトルに関連付けるよう学習します。このモデルを使用して、新しいテキストデータ内の単語を密なベクトルに変換できます。
単語埋め込みはどのように行われますか?
単語埋め込みにはさまざまな技法が用いられます。タスク特有の要件に応じて、技法を選択します。データセットの大きさ、データの領域、言語の複雑性を考慮する必要があります。よく使用される単語埋め込み技法がどのように作動するかを、以下で説明します。
- Word2vecは、2層のニューラルネットワークベースのアルゴリズムで、文章のコーパスを入力してベクトルのセット(すなわち名前)を出力します。よく使用されるWord2vecの例は「王 – 男 + 女 = 女王」です。 「王」と「男」、「男」と「女」の関係性をアルゴリズムが推論し、「王」に対応する適切な単語として「女王」を特定します。 Word2vecは、Skip-GramまたはContinuous Bag of Words(CBOW)アルゴリズムのいずれかを使用して訓練します。Skip-Gramは、目標とする単語から文脈に合う単語を予想しようとします。Continuous Bag of Wordsはその逆の方法で機能し、単語の周辺の文脈を使用して目標とする単語を予想します。
- GloVe(Global Vectors、グローバルベクトル)は、単語の意味は文章のコーパス内にある他の単語の同時発生(共起性)から推測できるという考え方に基づいています。このアルゴリズムは共起マトリクスを作成し、コーパス内に複数の単語が一緒に出現する頻度を取得します。
- fasTextは、Word2vecモデルを拡張したもので、単語を単に個別の単語としてではなく、n-gramの文字のバッグまたはサブ単語単位として表すという考え方に基づいています。Skip-Gramに似たモデルを使用して、fasTextは単語の内部構造についての情報を取得し、それを活用して新しい馴染みのない語彙を処理します。
- ELMo(Embeddings from Language Models、言語モデルからの埋め込み)は、上記の単語埋め込みとは異なり、その単語が使用されているコンテクスト全体を分析する深層ニューラルネットワークを使用します。これにより、他の埋め込み技法では獲得できなかった意味の微妙なニュアンスを拾い上げることができます。
- TF-IDF(Term Frequency - Inverse Document Frequency、用語頻度 - 逆文書頻度)は、数学的な値で、その用語の出現頻度(TF)に逆文書頻度(IDF)を乗算して決定します。TFとは、文書内の目的の用語の出現頻度を、その文書内の全用語と比較した比率を表します。IDFは全文書の、目的の用語を含む文書数に対する全文書数の比率の対数です。
単語埋め込みの利点とは?
単語埋め込みは、自然言語処理において単語を表す従来のアプローチに比べ、いくつか利点があります。単語埋め込みはNLPでは標準的なアプローチとなっており、さまざまな用途で多くの事前訓練した埋め込みが使用できるようになっています。この幅広い可用性により、研究者や開発者はまったく始めから訓練する必要なく、自分たちのモデルに単語埋め込みを簡単に組み込むことができます。
単語埋め込みは、言語モデリング(一連のテキストにおいて次の単語を予測するタスク)を改善するために使用されてきました。単語をベクトルで表すことで、モデルはある単語が出現するコンテクストをより適切に取得し、より正確な予測ができるようになりました。
単語埋め込みの構築は従来の工学的技法よりも迅速に行えます。大規模な文章データのコーパスを使用するニューラルネットワークの訓練の処理には監督が不要で、時間と労力を節約できるからです。一旦埋め込みを訓練すると、幅広いNLPタスクの入力機能として使用でき、追加の特徴エンジニアリングは不要です。
単語埋め込みは通常、ワンホットエンコードされたベクトルよりもずっと低い次元性を持ちます。つまり、保存や操作に使用するメモリや計算資源が少なくて済むということです。単語埋め込みとは、密なベクトルによる単語の表現であるため、スパースベクトル手法よりもより効率的に単語を表すことができます。これにより、単語間の意味の関係性をより適切に取得することもできます。
単語埋め込みの欠点は何ですか?
単語埋め込みには数多くの利点がありますが、考慮すべき欠点もいくつかあります。
単語埋め込みの訓練を行うには、特に大規模なデータセットや複雑なモデルを使う場合には計算コストが高くなります。また、事前訓練した埋め込みには大きな保存用のスペースが必要となる場合もあり、リソースが制限される用途においては問題となることがあります。単語の埋め込みは有限の語彙で訓練します。つまりその語彙に含まれていない単語を表すことはできないことがあります。これは膨大な語彙を持つ言語や、ある用途に特有の専門用語にとっては、問題となる場合があります。
単語埋め込みのデータ入力に偏りがある場合、単語埋め込みはその偏りの影響を受ける可能性があります。例えば、単語埋め込みは性別、人種、その他のステレオタイプの偏見をエンコードできるので、それを使用する現実世界の状況を暗に示すことがあります。
単語埋め込みはブラックボックスと見なされることがよくあります。GloVeやWord2Vecのニューラルネットワークのような根幹的なモデルが複雑で、解釈が難しいからです。
単語埋め込みの品質は、単に訓練データの品質に依存します。単語埋め込みを実際に使用する場合には、データが十分であるかを確認することが重要となります。単語埋め込みは、単語間の全般的な関係性を把握しますが、認識するのがより難しい、皮肉のようなある種の人間的なニュアンスを見逃す場合があります。
単語埋め込みでは、各単語にひとつのベクトルを割り当てるので、同じ綴りで異なる意味を持つ同形異義語には苦労することがあります。(例えば「park」という単語には「屋外の空間」という意味と、車を「駐車」するという意味があります。)
単語埋め込みを使う理由は何ですか?
単語埋め込みを使用すると、ベクトル検索を活用できます。ベクトル検索は、センチメント分析、テキスト分類、言語の翻訳といった自然言語処理タスクの基盤となります。単語埋め込みは、機械が単語間のセマンティックな関係性を認識し取得するための、効果的な経路を提供します。これにより、NLPモデルは手作業で特徴エンジニアリングを行うよりも一層正確で効率的となります。その結果、ユーザーにとって最終結果に一層アクセスしやすくなり、効果が高まります。
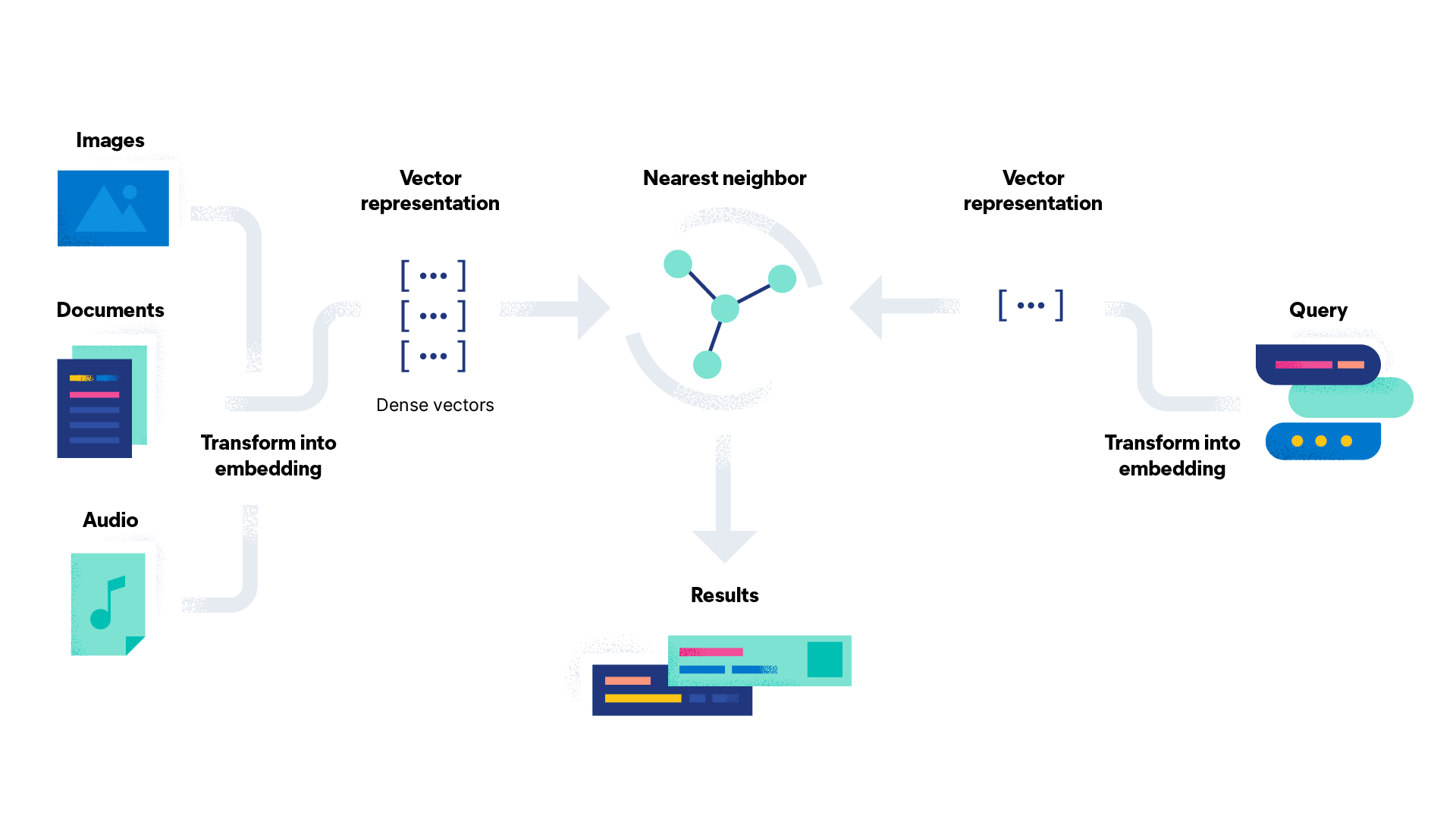
単語埋め込みは幅広いタスクに使用できます。単語埋め込みのユースケースをいくつか紹介します。
- センチメント分析:センチメント分析とは、単語埋め込みを使用して、ある文章を肯定的、否定的または中立的に分類することです。センチメント分析は、企業が自社製品についてのレビューやソーシャルメディアへの投稿から得たフィードバックを分析する際に、しばしば用いられます。
- レコメンデーションシステム:レコメンデーションシステムとは、過去のやりとりを基にユーザーに製品やサービスを提案するものです。例えば、ストリーミングサービスでは単語埋め込みを利用して、ユーザーの視聴履歴を基に新しい作品を推薦します。
- チャットボット:チャットボットは自然言語処理を使ってお客様と会話し、ユーザーの問い合わせに適切な応答を生成します。
- 検索エンジン:ベクトル検索を使用すると、検索エンジンは結果の正確性を改善できます。これは単語埋め込みを使用して、ユーザーの問い合わせを分析し、ウェブページの内容と比較して、より優れたマッチを見出します。
- オリジナルコンテンツ:オリジナルコンテンツは、データを読みとり可能な自然言語に変換して作成します。単語埋め込みは、製品の説明から試合終了後のスポーツレポートまで、幅広い範囲のコンテンツタイプに適用できます。
Elasticsearchで単語埋め込みとベクトル検索を始めましょう
Elasticsearchは、分散型の無料かつオープンな検索・分析エンジンで、構造化および非構造化テキスト分析を含む、あらゆる種類のデータに対応しています。データを安全に保管して、高速検索、微調整した関連性、効率的を評価する強力な分析機能に活用します。ElasticsearchはElastic Stackの根幹部分で、データインジェスト、データエンリッチメント、データの保管、解析、表示のための無料でオープンなツールのセットです。
Elasticsearchを採用すると以下の利点があります。
- ユーザー体験の改善とコンバージョンの増加
- 新しい洞察、自動化、分析、レポート機能の活用
- 社内文書とアプリケーションを扱う従業員の生産性が向上