機械学習を使用してMeetupデータを分析する
Elastic Stackの機械学習は、ビジネスデータの分析や探索も含む様々なユースケースで既に幅広く利用されていますが、いわゆる「教師なし学習」と呼ばれる手法を使用しています。教師なし学習では、人間による特別な介在なしで、データの規則性を発見し、学習します。Elastic Stackの機械学習は、時系列データを自動的に分析し、データから通常の状態を学習し、異常パターンを識別します。本ブログでは、Elastic Stackの機械学習を使って、どのように現実世界に紐づいたデータセットから異常を検知するかを見ていきたいと思います。
Meetupは、共通の地域や興味に関するコミュニティを簡単に始め、運営することを可能にするサービスです。 Meetupは、サービスにアクセス出来るRESTful APIであるMeetup APIを提供しており、我々は自身のアプリケーションとMeetupのサービスを協調させることが出来るようになっています。そして、このAPIによって、我々はMeetupで組織化されたグループやイベントについて知ることが出来ます。Logstashは、既に限定されたイベントの更新情報を取得するMeetup input pluginを提供しているのですが、今回はこのプラグインではなく、Meetupが提供するMeetup APIを使って、幅広いデータを取得してElasticsearchに投入した上で、機械学習を使って人間が見落としがちな何か興味深い洞察を発見出来るか、見ていきたいと思います。
次に説明する例では、Meetupのグループ作成の履歴を、1日毎の間隔で集約し、国毎に分割し、グループ作成件数をカウントする機械学習ジョブを走らせて、件数が多いケースを異常として見ていきます。最も顕著な例は、1日で通常の24倍の848グループが登録されるという異常の検知です。
データの収集
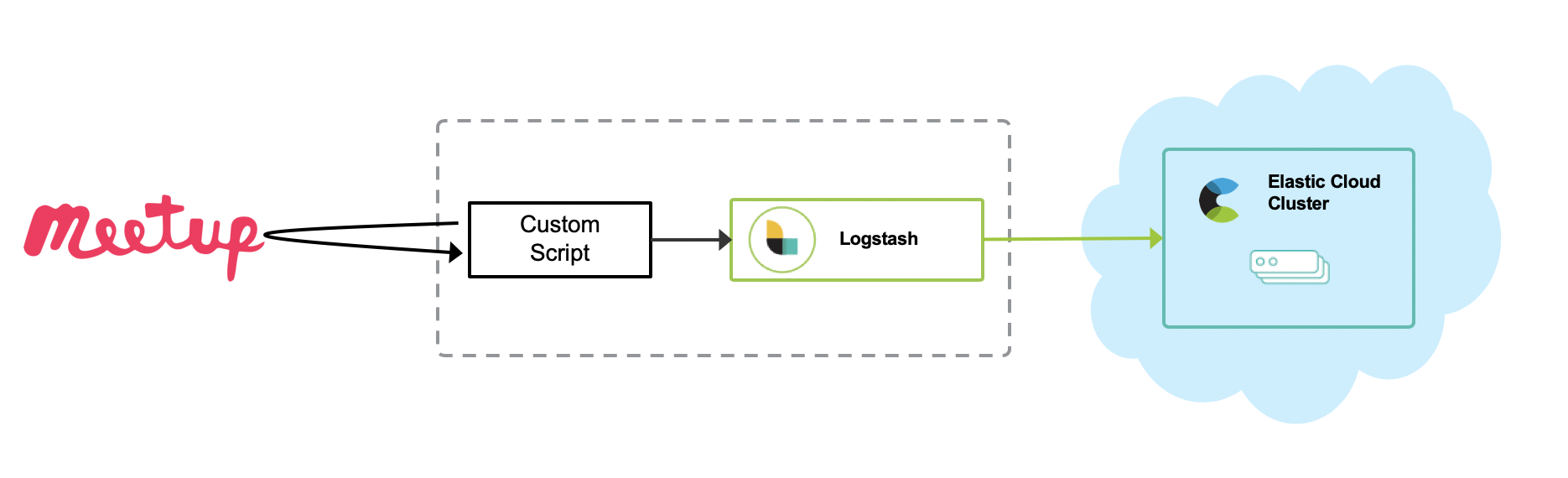
今回は、データの収集を簡単に行うために、カスタムのPythonスクリプトを作成しています。このPythonスクリプトでは、Meetup APIを使って情報を収集し、その情報を一連のイベントとしてLogstashに対してポストしています。Logstashへのポストには、Http input pluginを利用しています。Logstashは、受け取ったイベントデータにいくつかの変換とデータの追加を行なった上で、Elasticsearchに投入しています。興味のある方は、こちらのgithub repoを参照してください。もちろん、カスタムのLogstashプラグインを作ることも可能です。
Meetup グループ
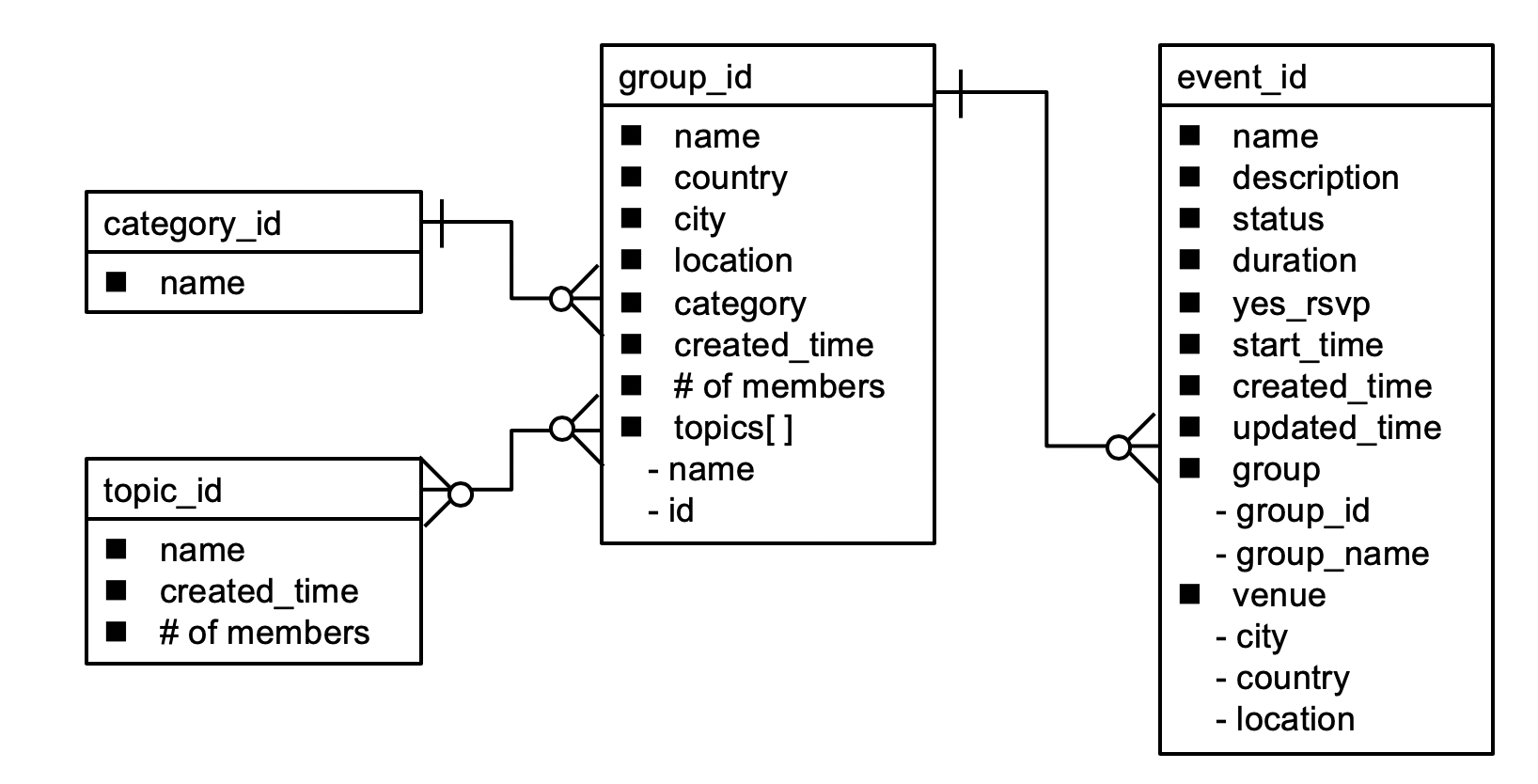
Meetup APIは、様々なデータの種類に応じて、様々なエンドポイントを提供しています。典型的なデータは、グループ、イベント、カテゴリ、トピックスなどです。この中でも、グループは基本となるエンティティとなります。例えば、誰かがMeetupのグループを始めようとする時、このグループエンティティが作成されます。それぞれのグループは、ある特定のカテゴリに属します。例えば、ソーシャライジング、テクノロジー、カルチャーなどです。また、それぞれのグループはいくつかのトピックスに関連付けられます。トピックスは、カテゴリよりもう少し小さな概念で、オープンソース、クラウド、プログラミングなどになり、グループとトピックスの関係は多対多になります。また、誰かがあるグループに関するイベントを企画する時には、イベントエンティティが作成されます。イベントエンティティはグループに対して、複数となり得ます。大まかなエンティティモデルは、以下の図のようになります。
以下は、Meetupの基本的なデータセットとなるグループのデータをElasticsearchに投入した時のMappingです。グループの基本的な属性、例えば名称name、国country、都市city、運営者organizer、カテゴリcategoryなどがあります。機械学習が扱うためには、日時フィールドが必要となりますので、ここでは当該グループが作成された時間、すなわちcreated_timeを日時フィールドとして使用します。
{
"meetup-group" : {
"mappings" : {
"dynamic_templates" : [
{
"string_fields" : {
"match" : "*",
"match_mapping_type" : "string",
"mapping" : {
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
},
"norms" : false,
"type" : "text"
}
}
}
],
"properties" : {
"@timestamp" : {
"type" : "date"
},
"@version" : {
"type" : "keyword"
},
"category" : {
"properties" : {
"id" : {
"type" : "long"
},
"name" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"shortname" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"city" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"country" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"created" : {
"type" : "long"
},
"created_time" : {
"type" : "date"
},
"data_type" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"description" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"document_id" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"group_photo" : {
"properties" : {
"base_url" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"highres_link" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"photo_id" : {
"type" : "long"
},
"photo_link" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"thumb_link" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"type" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"id" : {
"type" : "long"
},
"join_mode" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"lat" : {
"type" : "float"
},
"link" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"location" : {
"type" : "geo_point"
},
"lon" : {
"type" : "float"
},
"members" : {
"type" : "long"
},
"name" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"organizer" : {
"properties" : {
"member_id" : {
"type" : "long"
},
"name" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"photo" : {
"properties" : {
"base_url" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"highres_link" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"photo_id" : {
"type" : "long"
},
"photo_link" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"thumb_link" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"type" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
},
"rating" : {
"type" : "float"
},
"timezone" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"topics" : {
"properties" : {
"id" : {
"type" : "long"
},
"name" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"urlkey" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"urlname" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"utc_offset" : {
"type" : "long"
},
"visibility" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"who" : {
"type" : "text",
"norms" : false,
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
グループ作成の経緯から紐解く
さて、それではMeetupグループをElasticsearchに投入し、グループが作成された様子を時系列で見てみましょう。
ここで構成するMLジョブは、Meetupのグループ作成の履歴を、1日の時間枠(bucket span)で集約し、国毎に分割(split)し、グループ作成件数をカウントする機械学習ジョブを走らせて、件数が多い場合(high_count)を異常としています。ElasticのMLジョブは、データのある側面(field)、に対して適用される関数(function)の組合せをディテクター(detector)として定義します。ディテクターには様々な関数を適用することが出来ますが、このMLジョブでは、シンプルに件数をカウントしているだけです。実際には、カウントと言っても大きく次の3つの関数があります。
- count: ある時間枠のイベント数が異常な場合を識別する
- high_count: ある時間枠のイベント数が異常に多い場合を識別する
- low_count: ある時間枠のイベント数が異常に少ない場合を識別する
ここでは、Meetupグループの登録数のスパイクがいつ起きているに興味があったため、 high_countを関数として使っています。
さて、Single Metric Viewerを開くと、ここ5年間で、ある特定の期間 (bucket span)において、どれだけのグループが作成されたか (count)を見ることが出来ます。もしグループの作成が通常より多い場合、それは異常(high_count)として認識されます。ここ5年間、グループ作成は徐々に増加してきており、特にここ1年ではより増加傾向となっています。
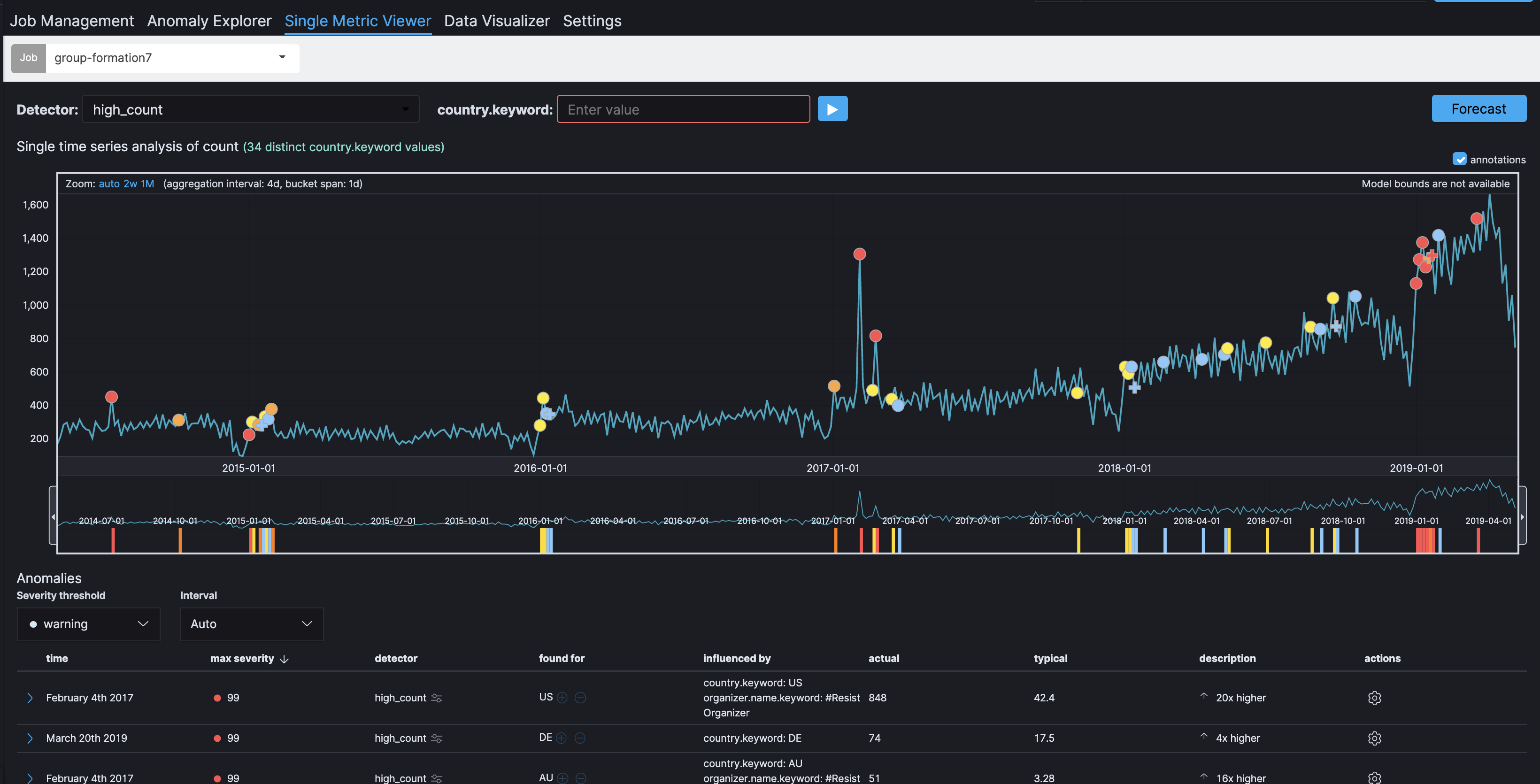
ここで、2017年の初めの方に、明らかなスパイクが見受けられます。Anomaly Explorerで見てみましょう。Anomaly timelineで表示される赤色、黄色、水色は、先ほどのSingle Metric Viewerでマークされている異常と同じであることがわかるはずです。
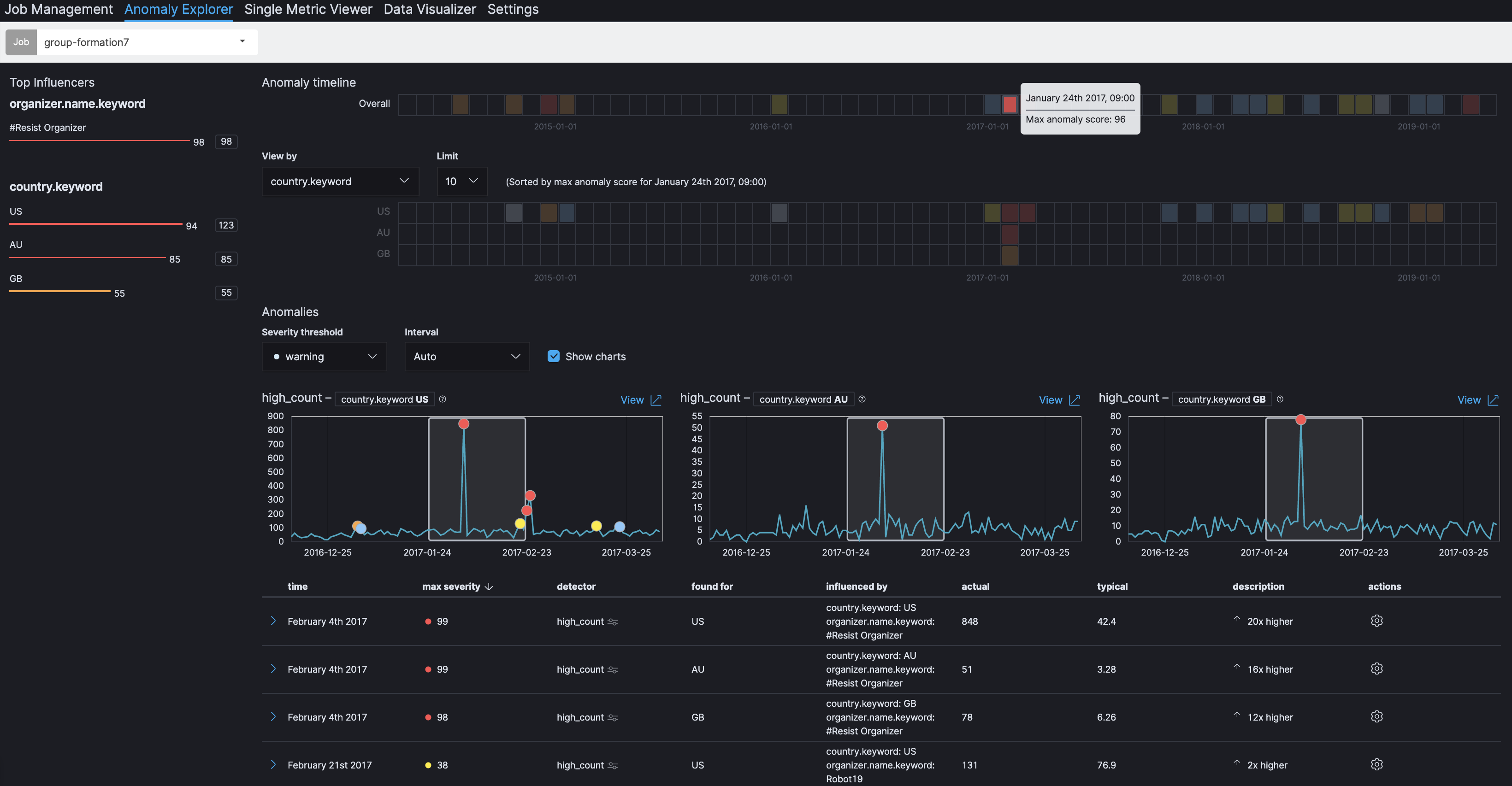
左上にTop Influencersが表示されていることに気付くかと思います。Top Influencerの1つは、国(country.keyword)で、ジョブを構成する時にSplit Dataとして指定したものです。実際、Meetupがどれくらい活用されているかは国によって異なるので、Meetupグループの登録を国毎に分析することは、理に適っていると言えます。さらに、もう一つのInfluencerとして、グループ運営者(organizer.name.keyword)が表示されています。これは、ジョブの構成でKey Fields(influencers)として指定したもので、異常検知に何らかの影響を与える可能性のあるフィールドを指定することが出来ます。今回は、グループ運営者の影響を見るために設定してみました。
Anomaly timelineで、2017年1月24日の箇所をクリックします。このOverallにおけるMax anomaly score:96 は当該時間枠の全体集約です。実際には、その下の国毎のヒートマップに示される、米国、オーストラリア、英国といった国々でスパイクが同時発生しているのがわかるはずです。2017年2月4日に、米国では848という通常の20倍以上のグループが登録されています。オーストラリアでも同様に、51という通常の16倍以上、英国では78という通常の12倍以上のグループ登録があったことがわかります。
さらに、もう一つ興味深いことは、左上のTop Influencersを見ると、グループ運営者 に#Resist Organizerのスコアが98と表示されていることです。これは、このグループ登録のスパイクに、#Resist Organizerという運営者が大きく関与していることを示唆しています。それでは、実際のデータを見てみましょう。
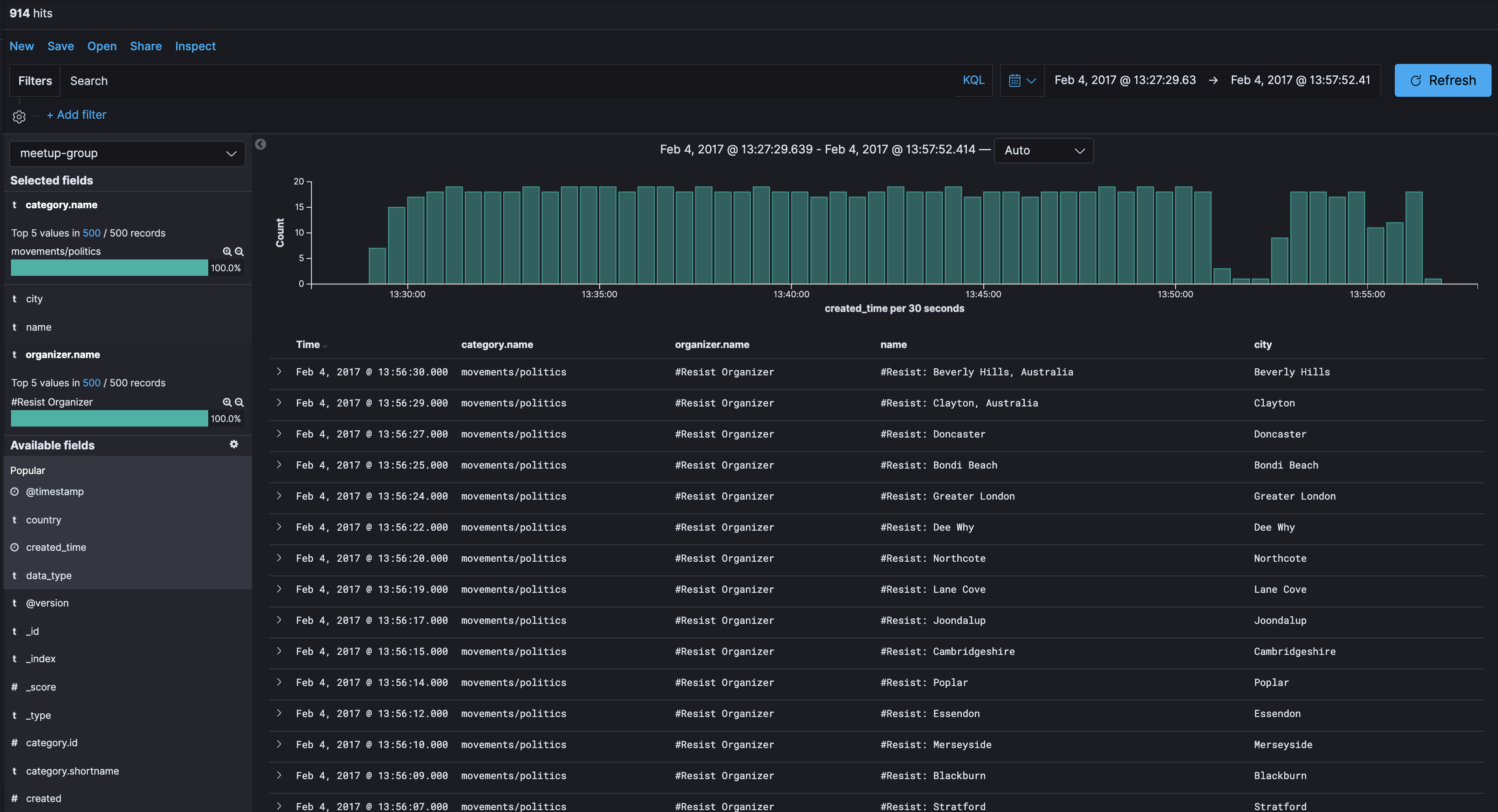
Kibanaからデータを見ると、2017年2月4日のおおよそ30分の間で、categoryがmovements/politicsで、#Resist Organizerが組織するグループが914件登録されていたことがわかります。Meetupのサイトで確認すると、何らかの民主主義、人権、社会的正義に関するグループであることがわかります。2017年2月4日付近に何か引き金となる出来事があったのでしょうか?
当時の出来事を検索すると、Meetupがトランプ大統領の政策に対抗して1,000にも及ぶ#Resist meetupグループを設定し、それに対してトランプ支援者が反発している、という記事を見つけることが出来ました。February 16, 2017 by Sarah Perez - TechCrunch
#Resist GroupはMeetup社による政治的立場の表明に起因したものだったようです。。。
より良い機械学習ジョブを構成するためのヒント
適切な時間枠
一般的にログ分析やセキュリティ分析のユースケースにおいて機械学習を使う場合、Bucket span(時間枠)は、分の単位、あるいは長くても時間の単位となることが多いでしょう。ログ分析などのユースケースでは、Webサイトへのアクセス数を10分単位でカウントして異常なアクセス増減を監視する、ということはよくあります。ところが、今回のケースのように着目すべき時間枠が比較的長い場合、つまり「グループの作成が一日のどの時間帯か」ではなく「グループの作成が年間通してどの日にあったか」のような場合は、このBucket spanを長めに設定することがポイントとなります。Bucket spanがどのように影響を与えるかを見るために、同一データセットで、60分、1日、7日のBucket spanで、ごくシンプルなsingle metric jobを走らせてみましょう。
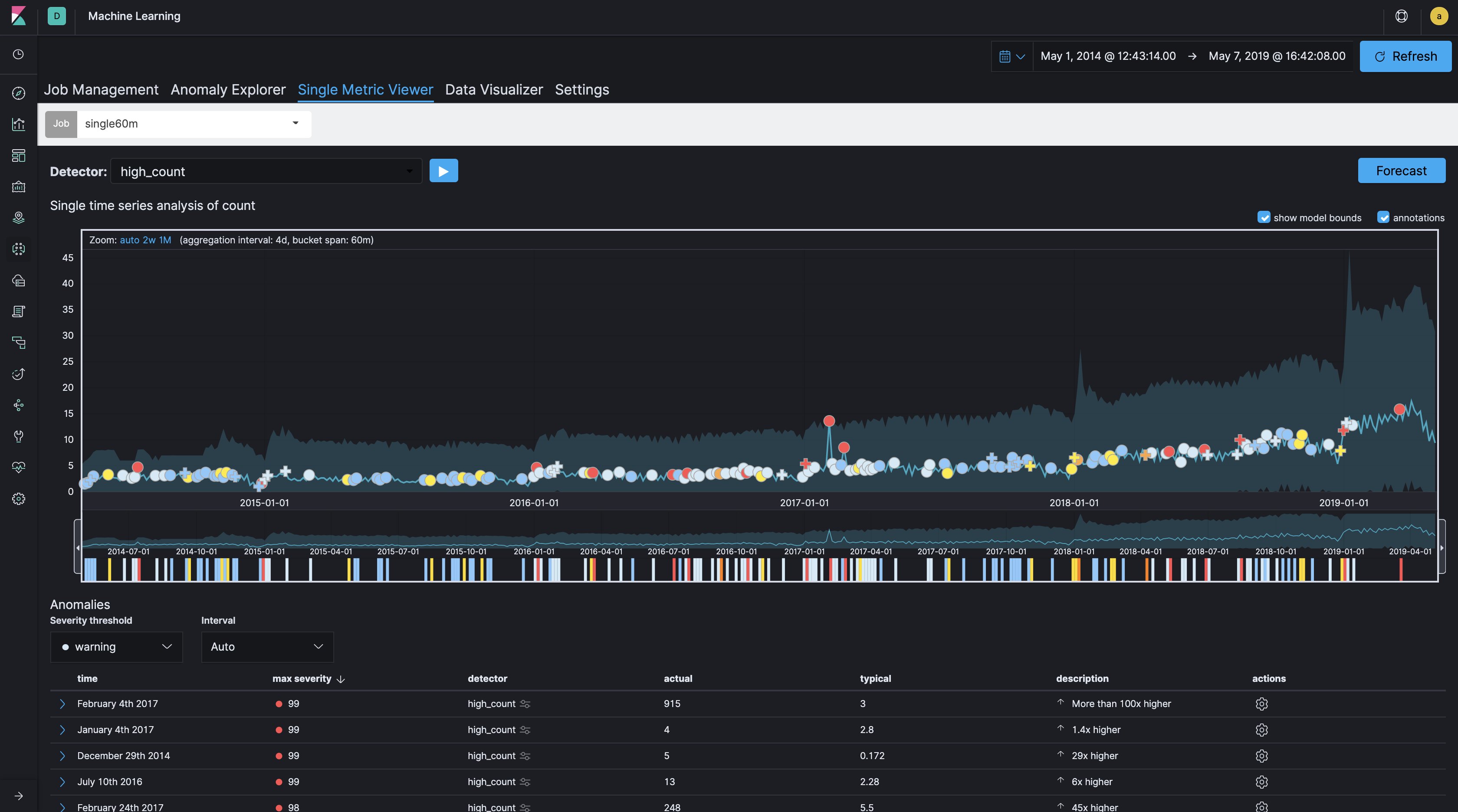 Bucket span: 60分
Bucket span: 60分
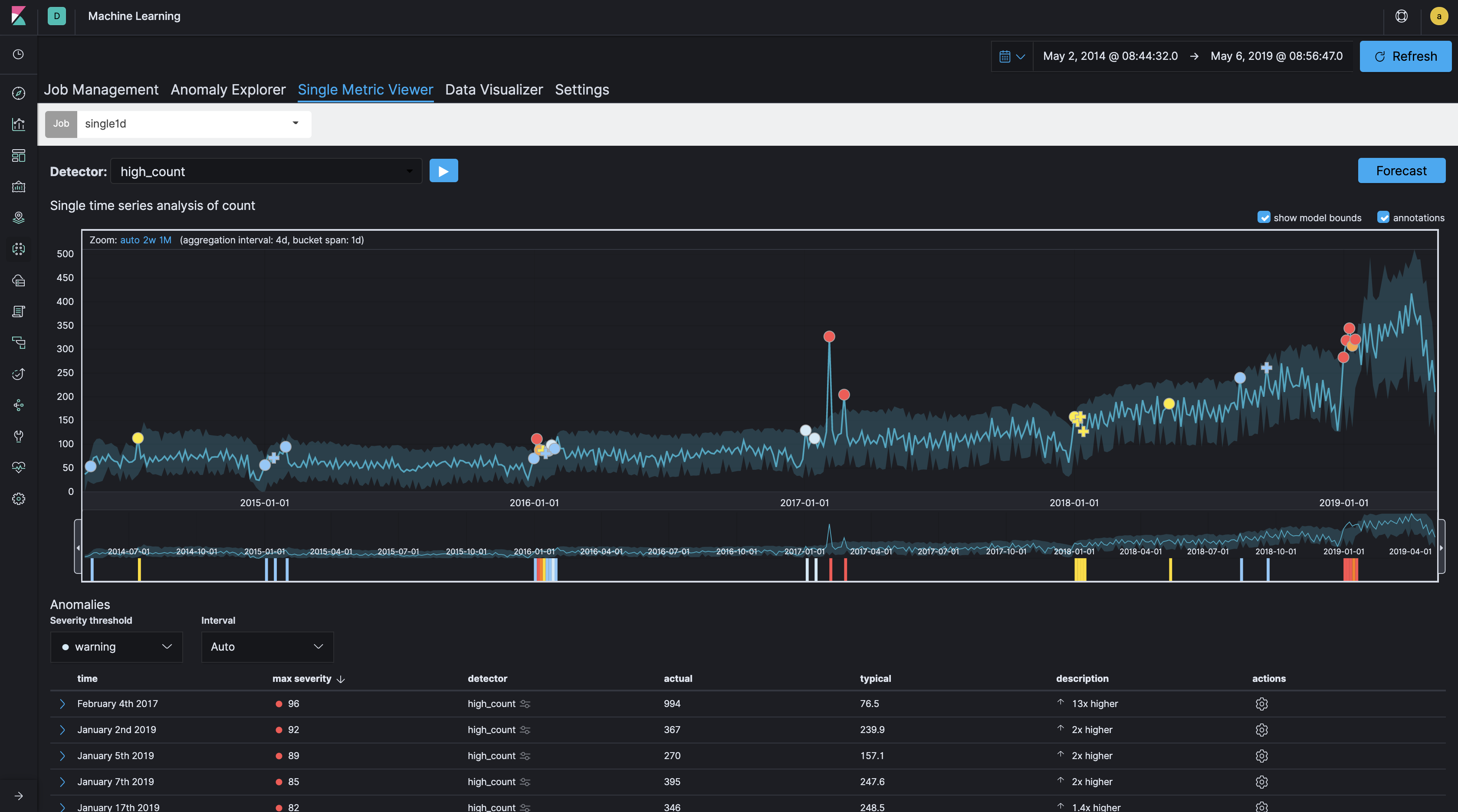 Bucket span: 1日
Bucket span: 1日
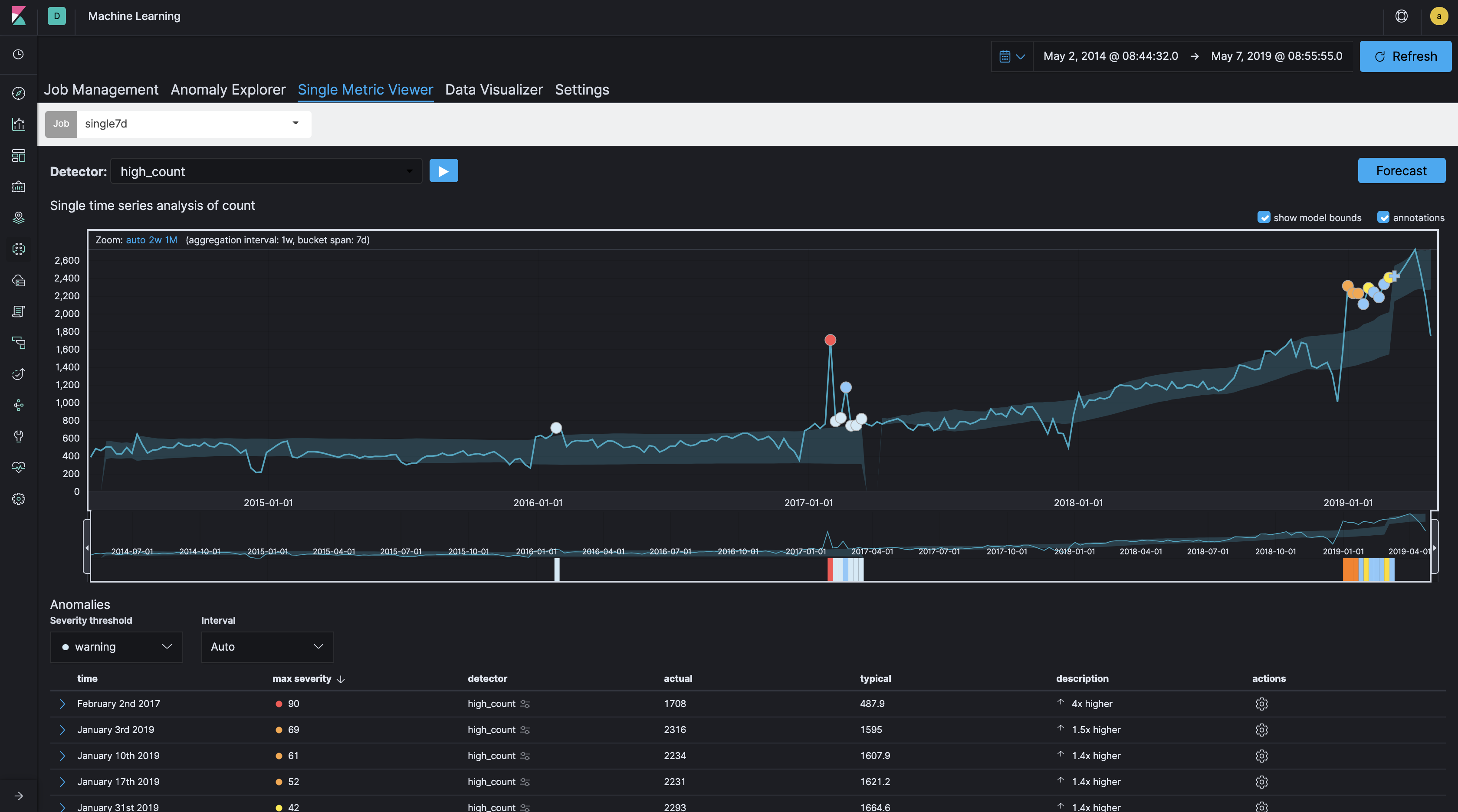 Bucket span: 7日
Bucket span: 7日
Bucket spanの長さによって、作成されるモデルと異常検知の違いが分かるかと思います。このデータセットにおいて、60分では粒度が細かすぎ、7日では荒すぎるように見えます。今回のケースでは、Bucket spanは1日1dとして設定しています。
ノイズと戦う
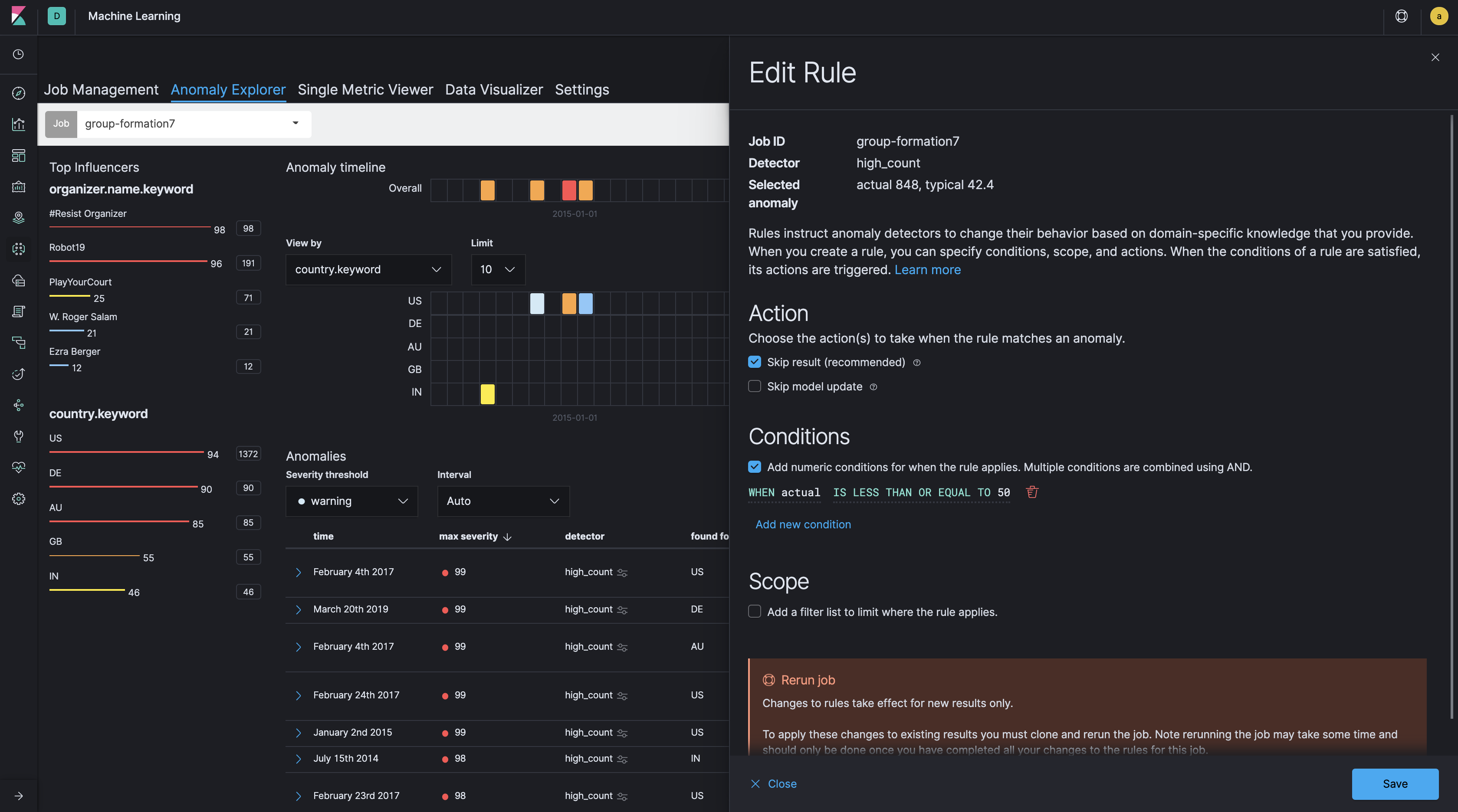
機械学習でデータを分析する際に直面する課題として、「ノイズの多さ」があります。今回のケースで言えば、データ全体で見るとグループ登録数は日に数百件ありますが、実際のデータは実は約70%が米国内のグループに偏っています。国別に見た場合、例えば英国やオーストラリアでは、グループ登録数は一日に数十件にすぎません。こうした国では、ちょっとしたグループ登録数の上振れが直ぐに異常として検知されてしまい、いわゆる「ノイズの山」となってしまうのです。こうした事態を抑制する方法として、機械学習ではCustom rulesという機能によって機械学習ジョブを構成することが出来ます。
"analysis_config": {
"bucket_span": "1d",
"detectors": [
{
"detector_description": "high_count",
"function": "high_count",
"partition_field_name": "country.keyword",
"custom_rules": [
{
"actions": [
"skip_result"
],
"conditions": [
{
"applies_to": "actual",
"operator": "lte",
"value": 50
}
]
}
],
"detector_index": 0
}
],
...
今回のケースでは、custom_rulesでconditionsを設定し、実際のカウントactualが50以下の場合スキップするようにしています。
custom_rulesは、以下のようにGUIから対話形式で設定することも出来ます。MLジョブが実行されたら、Anomaly Explorerからそれぞれの異常を検証し、もし異常検知が想定と違う場合、Edit RuleからCustom ruleを追加したり、編集したりすることが可能です。
まとめ
Elastic Stackは、非常に強力な検索エンジン(Elasticsearch)をベースに開発されており、その全ての可能性を活用することで様々な興味深い洞察を得ることができます。さらに、機械学習の機能を活用して、大きなデータセットから異常を簡単に発見できることを見てきました。複雑なアルゴリズムや背景となる理論を知る必要はありませんし、皆さん自身がデータサイエンティストになる必要もありません。データの概要を理解し、様々なMLジョブの設定を試してみれば、簡単に価値のある洞察を得ることが出来ます。皆さんの手元にある様々なデータに機械学習を使ってみましょう。何か新しい発見があるかもしれません。
その他の参考記事
Explaining the Bucket Span in Machine Learning for Elasticsearch Machine Learning Anomaly Scoring and Elasticsearch - How it Works