Elasticエンタープライズサーチのエンジンに言語のサポートを追加する方法


 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
Elastic App Searchのエンジンでは、ドキュメントをインデックスすることで、簡単に調整可能な検索機能を利用できます。デフォルトでは、エンジンは事前定義されたリストに含まれる言語をサポートします。このブログでは、リストにない言語を使用する場合に、言語のサポートを追加する方法を説明します。これは、その言語用に設定されたアナライザーを含むApp Searchエンジンを作成することで行います。
詳しい説明に移る前に、Elasticsearchアナライザーとは何かを確認しておきましょう。
Elasticsearchアナライザーは、文字フィルター、トークナイザー、トークンフィルターという3つの低レベルの構成要素を含むパッケージです。アナライザーはビルトインまたはカスタムです。ビルトインアナライザーは、各種の言語およびテキストタイプに適したアナライザーとして、構成要素を事前にパッケージ化したものです。
各フィールドのアナライザーは次の目的に使用されます。
- インデックス。各ドキュメントフィールドを対応するアナライザーによって処理し、検索しやすいようにトークンに分割します。
- 検索。すでに分析済みのインデックスされたフィールドと適切に一致するように、検索クエリを分析します。
Elasticsearchのインデックスベースのエンジンでは、既存のElasticsearchインデックスからApp Searchエンジンを作成できます。独自のアナライザーやマッピングを使用してElasticsearchインデックスを作成し、そのインデックスをApp Searchで使用します。
このプロセスには4つのステップがあります。
1.Elasticsearchインデックスを作成し、ドキュメントをインデックスする
最初に、どの言語にも最適化されていないインデックスを見てみましょう。これはマッピングが事前定義されていない新しいインデックスで、ドキュメントの最初のインデックス時に作成されると仮定します。
Elasticsearchでのマッピングとは、ドキュメントとそれに含まれるフィールドがどのように格納およびインデックスされるかを定義するプロセスです。各ドキュメントはフィールドの集まりであり、各フィールドには独自のデータタイプがあります。データをマッピングする際には、ドキュメントに関連するフィールドのリストを含むマッピング定義を作成します。
先ほどの例に戻りましょう。インデックスはbooksという名前で、titleはルーマニア語で記述されます。ここでルーマニア語を取り上げたのは私の母語だからで、これはApp Searchのサポートする言語リストにデフォルトでは含まれていません。
POST books/_doc/1
{
"title": "Un veac de singurătate",
"author": "Gabriel García Márquez"
}
POST books/_doc/2
{
"title": "Dragoste în vremea holerei",
"author": "Gabriel García Márquez"
}
POST books/_doc/3
{
"title": "Obosit de viaţă, obosit de moarte",
"author": "Mo Yan"
}
POST books/_doc/4
{
"title": "Maestrul și Margareta",
"author": "Mihail Bulgakov"
}2.booksインデックスに言語アナライザーを追加する
booksインデックスのマッピングを調べると、これはルーマニア語向けに最適化されていないことがわかります。settingsブロックにanalysisフィールドがなく、テキストフィールドはカスタムアナライザーを使用していません。
GET books
{
"books": {
"aliases": {},
"mappings": {
"properties": {
"author": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "books",
"creation_date": "1679310576178",
"number_of_replicas": "1",
"uuid": "0KuiDk8iSZ-YHVQGg3B0iw",
"version": {
"created": "8080099"
}
}
}
}
}booksインデックスを含むApp Searchエンジンを作成しようとする場合、2つの問題があります。1つは検索結果がルーマニア語に最適化されないことで、もう1つは適合率調整のような機能が無効になることです。
各種のElastic App Searchエンジンについて簡単な注意事項を示します。
- デフォルトのオプションはApp Searchで管理されるエンジンであり、非表示のElasticsearchインデックスを作成して管理します。このオプションでは、App SearchドキュメントAPIを使用してエンジンにデータを取り込む必要があります。
- もう1つのオプションでは、App Searchが既存のElasticsearchインデックスを使用してエンジンを作成します。この場合、App Searchはそのインデックスをそのまま使用します。ElasticsearchインデックスドキュメントAPIを使用して、基盤となるインデックスに直接データを取り込むことができます。
[関連記事:Elasticsearch Search API: A new way to locate app search documents(Elasticsearch Search API:App Searchのドキュメントを見つける新しい方法)]
既存のElasticsearchインデックスからエンジンを作成する場合、マッピングがApp Searchの規則に従っていないと、エンジンですべての機能が有効になりません。App Searchによって完全に管理されるエンジンを例に用いて、App Searchのマッピング規則を詳しく見てみましょう。このエンジンには、titleとauthorという2つのフィールドがあり、英語を使用します。
GET .ent-search-engine-documents-app-search-books/_mapping/field/title
{
".ent-search-engine-documents-app-search-books": {
"mappings": {
"title": {
"full_name": "title",
"mapping": {
"title": {
"type": "text",
"fields": {
"date": {
"type": "date",
"format": "strict_date_time||strict_date",
"ignore_malformed": true
},
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"float": {
"type": "double",
"ignore_malformed": true
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"location": {
"type": "geo_point",
"ignore_malformed": true,
"ignore_z_value": false
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
},
"index_options": "freqs",
"analyzer": "iq_text_base"
}
}
}
}
}
}titleフィールドには、いくつかのサブフィールドがあることがわかります。date、float、locationの各サブフィールドは、テキストフィールドではありません。
ここで関心があるのは、App Searchで必要となるテキストフィールドを設定する方法です。フィールドの数は決して少なくありません。このドキュメントページで、App Searchで使用されるテキストフィールドについて説明しています。App Searchで管理されるエンジンに属する非表示のインデックスに対してApp Searchが設定するアナライザーを見てみましょう。
GET .ent-search-engine-documents-app-search-books/_settings/index.analysis*
{
".ent-search-engine-documents-app-search-books": {
"settings": {
"index": {
"analysis": {
"filter": {
"front_ngram": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "12"
},
"bigram_joiner": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "false",
"type": "shingle"
},
"bigram_max_size": {
"type": "length",
"max": "16",
"min": "0"
},
"en-stem-filter": {
"name": "light_english",
"type": "stemmer"
},
"bigram_joiner_unigrams": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "true",
"type": "shingle"
},
"delimiter": {
"split_on_numerics": "true",
"generate_word_parts": "true",
"preserve_original": "false",
"catenate_words": "true",
"generate_number_parts": "true",
"catenate_all": "true",
"split_on_case_change": "true",
"type": "word_delimiter_graph",
"catenate_numbers": "true",
"stem_english_possessive": "true"
},
"en-stop-words-filter": {
"type": "stop",
"stopwords": "_english_"
}
},
"analyzer": {
"i_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"front_ngram"
],
"tokenizer": "standard"
},
"iq_text_delimiter": {
"filter": [
"delimiter",
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter",
"en-stem-filter"
],
"tokenizer": "whitespace"
},
"q_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding"
],
"tokenizer": "standard"
},
"iq_text_base": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter"
],
"tokenizer": "standard"
},
"iq_text_stem": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter",
"en-stem-filter"
],
"tokenizer": "standard"
},
"i_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stem-filter",
"bigram_joiner",
"bigram_max_size"
],
"tokenizer": "standard"
},
"q_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stem-filter",
"bigram_joiner_unigrams",
"bigram_max_size"
],
"tokenizer": "standard"
}
}
}
}
}
}
}App Searchで別の言語(たとえば、ノルウェー語、フィンランド語、アラビア語など)に対して使用できるインデックスを作成したい場合は、同様なアナライザーが必要となります。この例では、語幹フィルターとストップワードフィルターにルーマニア語バージョンを使用するよう設定する必要があります。
最初のbooksインデックスに戻り、適切なアナライザーを追加しましょう。
ちょっとした注意事項を述べます。既存のインデックスの場合、アナライザーは、インデックスを閉じたときにのみ変更できるElasticsearch設定の一種です。このアプローチでは、既存のインデックスから始めます。そのため、インデックスを閉じ、アナライザーを追加してから、インデックスを再び開く必要があります。
注:代替方法として、適切なマッピングを使用してインデックスをゼロから再作成した後、すべてのドキュメントをインデックスすることもできます。その方がユースケースに適している場合は、インデックスを閉じて開く方法や再インデックスする方法の説明はスキップしてもかまいません。
インデックスを閉じるには、POST books/_closeを実行します。その後で、アナライザーを追加します。
PUT books/_settings
{
"analysis": {
"filter": {
"front_ngram": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "12"
},
"bigram_joiner": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "false",
"type": "shingle"
},
"bigram_max_size": {
"type": "length",
"max": "16",
"min": "0"
},
"ro-stem-filter": {
"name": "romanian",
"type": "stemmer"
},
"bigram_joiner_unigrams": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "true",
"type": "shingle"
},
"delimiter": {
"split_on_numerics": "true",
"generate_word_parts": "true",
"preserve_original": "false",
"catenate_words": "true",
"generate_number_parts": "true",
"catenate_all": "true",
"split_on_case_change": "true",
"type": "word_delimiter_graph",
"catenate_numbers": "true"
},
"ro-stop-words-filter": {
"type": "stop",
"stopwords": "_romanian_"
}
},
"analyzer": {
"i_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"front_ngram"
],
"tokenizer": "standard"
},
"iq_text_delimiter": {
"filter": [
"delimiter",
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter",
"ro-stem-filter"
],
"tokenizer": "whitespace"
},
"q_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding"
],
"tokenizer": "standard"
},
"iq_text_base": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter"
],
"tokenizer": "standard"
},
"iq_text_stem": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter",
"ro-stem-filter"
],
"tokenizer": "standard"
},
"i_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stem-filter",
"bigram_joiner",
"bigram_max_size"
],
"tokenizer": "standard"
},
"q_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stem-filter",
"bigram_joiner_unigrams",
"bigram_max_size"
],
"tokenizer": "standard"
}
}
}
}ここでは、ルーマニア語でのステミングのためにro-stem-filterを追加しています。これにより、ルーマニア語に固有の語形変化に対して検索の関連性が向上します。また、検索の目的でルーマニア語のストップワードを考慮しないように、ルーマニア語のストップワードフィルター(ro-stop-words-filter)を含めています。
次に、POST books/_openを実行して、インデックスを再び開きます。
3.アナライザーを使用するようにインデックスマッピングを更新する
分析設定が完了したら、インデックスのマッピングを変更できます。App Searchでは、動的なテンプレートを使用して、新しいフィールドに正しいサブフィールドとアナライザーが含まれるようにします。この例では、既存のtitleおよびauthorフィールドにのみサブフィールドを追加します。
PUT books/_mapping
{
"properties": {
"author": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
}
},
"title": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
}
}
}
}4.ドキュメントを再インデックスする
これで、booksインデックスをApp Searchで使用する準備がほぼ完了しました。
後は、マッピングの変更前にインデックスしたドキュメントに、すべての適切なサブフィールドが含まれるようにする必要があります。そのためには、update_by_queryを使用して、再インデックスを実行できます。
POST books/_update_by_query?refresh
{
"query": {
"match_all": {
}
}
}ここではmatch_allクエリを使用しているので、すべての既存のドキュメントが更新されます。
update by queryリクエストで、ドキュメントの更新方法を定義するスクリプトパラメーターを含めることもできます。
ドキュメントを変更するわけではないことに注意してください。既存のドキュメントをそのまま再インデックスして、テキストフィールドauthorおよびtitleが適切なサブフィールドを含むようにするだけです。したがって、クエリリクエストで更新にscriptを含める必要はありません。
これで、ElasticsearchエンジンとともにApp Searchで使用できる言語最適化されたインデックスが得られました。以下のスクリーンショットで、そのメリットを確認できます。
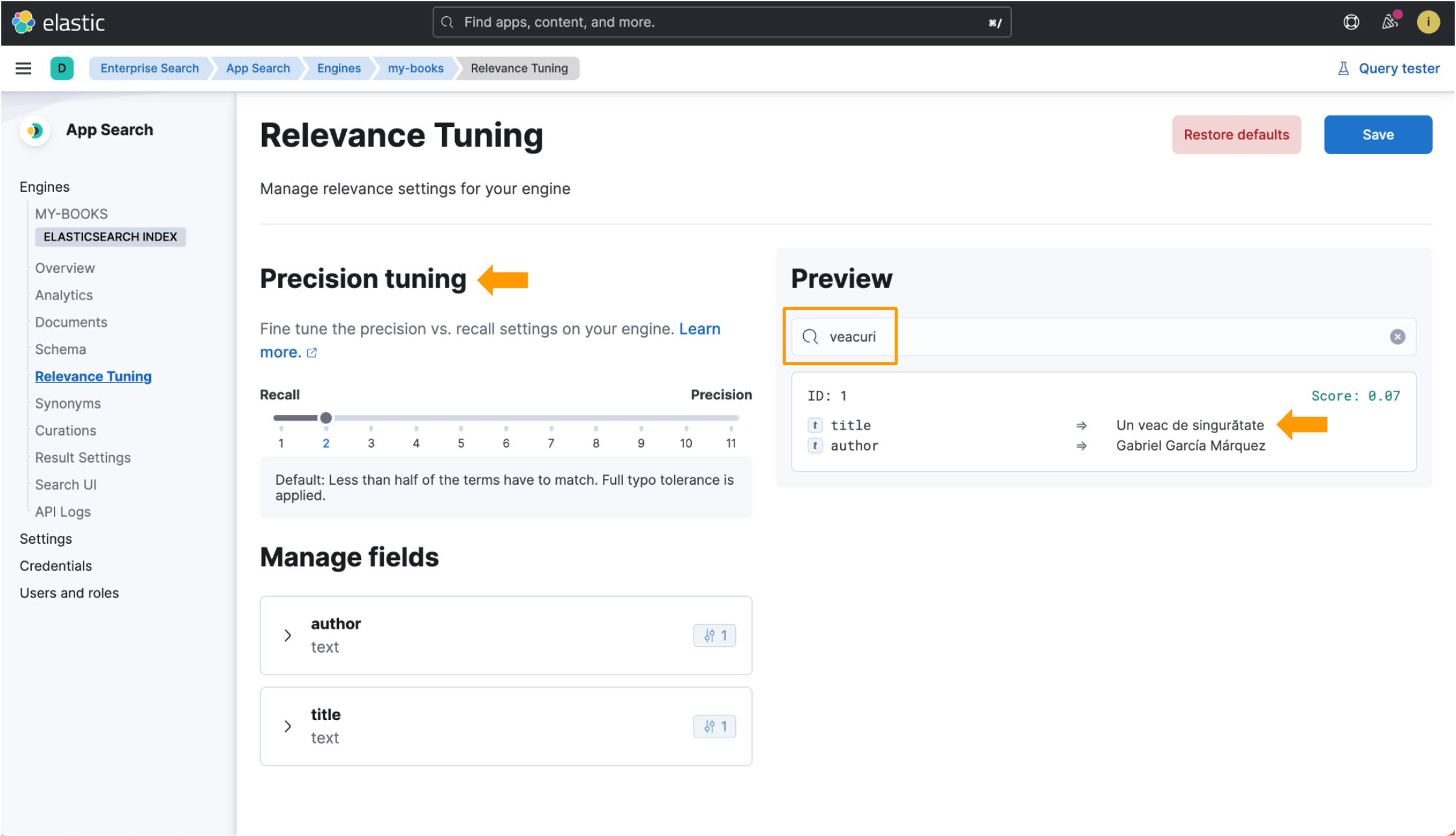
例として、One Hundred Years of Solitudeという本のタイトルを使用します。ルーマニア語に翻訳されたタイトルはUn veac de singurătateです。ここで、veacという単語に注目します。これは“century”に相当するルーマニア語です。 veacの複数形であるveacuriについて検索を実行します。以下に示す両方の例に、このデータレコードを取り込みました。
{
"title": "Un veac de singurătate",
"author": "Gabriel García Márquez"
}言語に対してインデックスが最適化されていないときには、ルーマニア語のタイトルUn veac de singurătateが標準アナライザーによってインデックスされます。これは、ほとんどの言語に対してはうまくいきますが、該当するドキュメントと常に一致するとは限りません。veacuriを検索すると、結果が何も表示されません。この検索入力はデータレコード内のどのプレインテキストとも一致しないからです。
しかし、言語最適化されたインデックスを使用すると、veacuriを検索したときに、Elastic App Searchはそれをルーマニア語の単語veacと一致させ、探しているデータを返します。適合率調整フィールドは、関連付け調整ビュー内でも利用可能です。この画像でハイライトされている部分をご覧ください。
このように、Elasticエンタープライズサーチに私の言語であるルーマニア語のサポートを追加しました。このガイドで説明したプロセスを使用して、Elasticsearchでサポートされる他の任意の言語に対して最適化されたインデックスを作成できます。Elasticsearchでサポートされているすべての言語アナライザーの一覧については、こちらのドキュメントページを参照してください。
Elasticsearchのアナライザーは、魅力的なトピックです。さらに詳しく知りたい方のために、他のリソースがいくつかあります。
- Elasticsearchのテキスト分析の概要ドキュメントページ
- Elasticsearchのビルトインアナライザーのリファレンスドキュメントページ(サポートされている言語アナライザーのリストは、このサブページを参照)
- ElasticエンタープライズサーチおよびElastic Cloudのトライアルの詳細
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷