Elastic CloudのElasticsearch Serviceでロギングやメトリックに使うHot-Warmアーキテクチャーのサイズ設計
Amazon Elasticsearch Serviceと、Elasticが提供するオフィシャルのElasticsearch Serviceの違いについて詳しくは、AWS Elasticsearch比較ページをご覧ください。
先日、Elastic Cloudで提供されるElasticsearch Serviceに幅広いハードウェアへのサポートやデプロイテンプレートが加わりました。ロギングやメトリックに関連するワークロードの処理を大幅に効率化することができます。フレキシブルになったことで、選択肢も増えました。ユースケースに最適なアーキテクチャーを選ぶ上で迷うこともあるかもしれません。もちろん心配は要りません。ブログをはじめ、Elasticは豊富な情報やサポートを提供しています。
本ブログ記事では、ロギングとメトリックのユースケースで一般的に使用されるさまざまなアーキテクチャーと、それぞれ特に適したケースを説明します。さらにアーキテクチャーを最大に活用するためのクラスターサイズの設計方法と、クラスターの管理方法もご紹介します。
ロギングクラスターに使える各種アーキテクチャー
Elasticsearchクラスターを最もシンプルに設定するやり方は、すべてのデータノードを同じ仕様にし、すべてのロールを扱わせるという方法です。このタイプのクラスターで規模を拡大する際、特定のタスク向けのノード(例:専用マスター/Ingest/機会学習ノード)を追加することがよくあります。追加によってデータノードの負荷が軽減され、より効率的に運用することができるようになります。このタイプのクラスターでは、すべてのノードがインデキシングとクエリの負荷を等しく共有します。すべてのノードが同じ仕様であることから、"ホモジニアスクラスターアーキテクチャー"、あるいは"ユニフォームクラスターアーキテクチャー"と呼ばれています。
もう1つ、人気のアーキテクチャーがHot-Warmアーキテクチャーです。特にログやメトリックの時系列データを扱う場合に多く採用されます。このアーキテクチャーは、データ全体が不変であり、かつ時系列でインデックスできるという原則に依存しています。各インデックスに特定の時期のデータを持たせることで、保持するか、削除するかというインデックス全体のライフサイクルを管理することが可能になります。このアーキテクチャーでは異なるハードウェアプロフィールを用い、"Hot"と"Warm"の2つの異なるデータノードを使用します。
"Hot"データノードは最も新しいインデックスを扱い、クラスターのすべてのインデキシング負荷を処理します。最新のデータは一般的に最もクエリされることが多く、このノードの処理量は非常に多くなります。Elasticsearchへのインデキシングは非常にCPUおよびI/Oインテンシブです。さらにクエリの負荷が加わることから、"Hot"データノードにはパワフルで非常に高速なストレージが必要です。一般的にはローカル接続のSSDが用いられます。
一方、"Warm"ノードはよりコスト効率に優れた方法で、クラスターの中でも読み取りのみのインデックスを長期ストレージで扱う場合に最適です。RAMとCPUは十分搭載しても、多くの場合はSSDに代えてローカル接続の回転式ディスクやSAN(ストレージエリアネットワーク)を使い、コストを抑えます。"Hot"ノードのインデックスが定められた保持期間に達すると、そのインデックスへの新たなインデキシングは行われなくなり、"Warm"ノードに移動します。
"Hot"ノードから"Warm"ノードへデータを移行させた場合、かならずしもクエリが遅くなるわけではありません。この点は重要です。"Warm"ノードは負荷の高いインデキシングを必要とするリソースを一切扱わないため、SSDベースのストレージを使わなくても古いデータへのクエリを遅延なく、効率的に処理できることが多くあります。
Hot-Warmアーキテクチャーのデータノードはデータ処理に特化し、高い負荷を負います。したがって専用マスター、Ingest、機械学習、およびCoordinatingの各ノードを併用されることをお勧めします。
アーキテクチャーの選び方
多くのユースケースではどのアーキテクチャーを選んでも問題なく動作し、これといった正解がないケースもあります。しかし、特定の状況や制約があって、特定のアーキテクチャーが他のアーキテクチャーよりもふさわしい、という場合もあります。
考慮する要素として重要となるのが、クラスターで利用するストレージの種類です。Hot-Warmアーキテクチャーでは、Hotノードに非常に高速なストレージが必要です。つまり、クラスターで使えるストレージが低速なものに限られる場合、このアーキテクチャーは適していません。その場合はユニフォームアーキテクチャーを採用し、インデキシングとクエリをできる限り多数のノードに分散させる方法が最適です。
多くのユニフォームクラスターでブロックストレージとしてローカル接続の回転ディスクやSANが使われていますが、SSDを用いることも増えています。低速のストレージでは、特にクエリ処理を伴う場合、高速なインデキシングレートをサポートしない可能性があります。したがってディスクが一杯になるまで時間がかかります。このため1ノードあたりが扱うデータが大きくなる条件として、長期の保持期間を設定できることが妥当な場合に限られる可能性があります。
ユースケースで非常に短い保持期間を定める(例:10日以下など)場合、インデックスされたデータはすぐにディスクから出て行かなくてはなりません。つまり、パフォーマンス性に優れたストレージが必要です。Hot-Warmアーキテクチャーの採用も不可能ではありませんが、Hotデータノードのみで構成するユニフォームクラスターの方がより適しており、管理も簡単になります。
必要なストレージサイズ
ロギングやメトリックのユースケースでクラスター数の決め手となる主な要素が、ストレージの大きさです。生のデータ量に対し、Elasticsearchへインデックスされて、レプリカ作成された後にディスクで占める容量の比率は、データタイプやインデックス方法によって大きく異なります。下の図は、データがインデキシング中に通過するステップを示したものです。
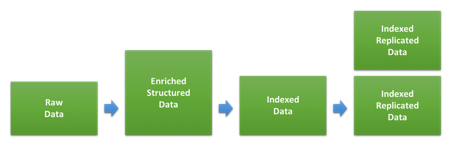
最初のステップで生データをElasticsearchにインデックスするJSONドキュメントに変換します。データサイズがどの程度変化するかは、元のデータ形式と追加されるストラクチャー、さらに各種のエンリッチで追加されるデータ量により異なります。とりわけデータタイプによる違いが顕著です。すでにJSON形式になっているログであれば追加されるデータが少ないため、サイズがほとんど変わらない可能性もあります。反対にテキストベースのWebアクセスログなどの場合、ユーザーエージェントとロケーションについて追加されるストラクチャーや情報の量が比較的大きくなります。
データをElasticsearchにインデックスした後は、インデックスの設定と使用するマッピングによりディスク上に占めるサイズが決まります。Elasticsearchで適用されるデフォルトの動的マッピングは、全体的にディスク上のストレージサイズよりも柔軟性を重視して設計されています。つまり、カスタムインデックステンプレートでマッピングを最適化することにより、ディスク容量を節約することも可能です。この手順について詳しくは、調整に関するドキュメントをご覧ください。
クラスターに入る特定のタイプのデータがディスク容量に占めるサイズをあらかじめ推測するには、運用中に使用すると思われるシャードサイズに達する程度まで、十分な量のデータをインデックスする必要があります。テストで不正確な結果が生じる一般的な原因として、使用するデータの量が少なすぎることがあります。
投入とクエリのバランス
クラスターのサイズを考える上で多くのユーザーがベンチマークに使用する要素が、クラスターにおけるインデキシングスループットの最高値です。設定と実行が非常に簡単なベンチマークであり、またデータがディスクに占めるサイズを判断する上でも参照できる値です。
クラスターと投入プロセスの調整が完了し、処理可能な最大のインデキシングレートを特定したら、このデータノードが最大のスループットを維持した場合、どの程度の期間でディスクが一杯になるかも計算できます。この計算結果から、利用できるディスク容量を最大化するにあたり、そのノードタイプの最短の保持期間を特定できます。
一見するとこの値は必要なサイズの判断にも使えそうですが、この計算ではすべてのシステムリソースがインデキシングに使用することが前提となっており、クエリの分が考慮されていません。多くのユーザーはどこかのタイミングでデータをクエリするために、そしてその際すぐれたパフォーマンスを実現するべくElasticsearchにデータを格納しているので、ここを無視するわけにはいきません。
さて、クエリに関してはどの程度見ておけばよいでしょうか。クエリの性質と、ユーザーが許容するレイテンシの程度によって大きく異なるため、この問いを考えるのは簡単ではありません。こちらのクラスターサイズの測定に関するElastic{ON}トークや、 Rallyを使ったクラスターのベンチマークとサイズに測定に関するウェビナーでもご紹介していますが、1つの優れたやり方として、現実的な水準でさまざまなデータボリュームでのクエリや、幅広いインデキシングレートをシミュレーションしてベンチマークテストを実行するという方法があります。
許容できるパフォーマンスでユーザーがクエリを実行するのと並行して、提供可能なインデキシングスループットの最高値を特定したら、クエリ分を割り引き、調整したインデキシングレートに基づく保持期間を新たに算出することができます。インデックスのペースが落ちれば、ディスクが一杯になるまでの時間も長くなります。
この調整では、トラフィック中の小さなピークを扱うことはできるかもしれませんが、主として時間軸に対して安定した、コンスタントなインデキシングを想定しています。トラフィックの水準にピークの発生が見込まれる場合や、1日の中でトラフィックに変動がある場合、ピークの水準に応じてインデキシングレートを調整する必要があり、各ノードで処理できる平均インデキシングレートも引き下げる必要がある可能性もあります。トラフィックの変動を予測でき、かつピーク時間も特定できる(例:平日の営業時間内だけなど)という場合は、もう1つのやり方として、その時間だけHotゾーンのサイズを増やすという方法があります。
ストレージを最大に活用する
Hot-Warmアーキテクチャーは、Warmノードで大量のデータを保有できることを前提とします。これは、保持期間を長く定めるユニフォームアーキテクチャーのデータノードにもあてはまります。
あるノードにどの程度データを持たせられるかは、ヒープの使用量をどの程度うまく管理できるかにもよります。そしてヒープの使用量はしばしば、密集ノードによる制約の主な要因ともなります。Elasticsearchクラスターでヒープ使用量に影響する領域は数多くあります。たとえばインデキシング、クエリ、キャッシュ、クラスターの状態、フィールドデータ、シャードの負荷(オーバーヘッド)などです。したがって、ユースケースにより状況が大きく異なります。特定のユースケースで何が制約となっているか正確に判断するには、現実的なデータとクエリパターンに基づいたベンチマークテストを実行する必要があります。また、ロギングやメトリックのユースケースではデータノードを効率的に使う一般的なベストプラクティスが多数あります。
マッピングを最適化する
冒頭で触れたように、データで使用するマッピングもディスク上でどの程度圧縮できるかに影響します。さらにマッピングは使用するフィールドデータの量や、ヒープの使用量にも影響します。データのパースと投入にFilebeatモジュールまたはLogstashモジュールを使用している場合はすでに最適なマッピングになっており、マッピングについてそれほど気にする必要はありません。カスタムログをパースしている場合や、新規フィールドの動的なマップを広範囲でElasticsearchの機能に頼っているという場合は、引き続きこのセクションをお読みください。
Elasticsearchがある文字列を動的にマッピングする場合、デフォルトではマルチフィールドを使用し、データをテキストとキーワードの両方でマップするという挙動になっています。テキストはケースを問わないフリーテキスト検索に使用され、キーワードはKibanaでデータをアグリゲーションする際に使用されます。デフォルトの挙動はフレキシビリティという観点では優れていますが、ディスク上のサイズと、使用するフィールドデータ量が大きいという欠点があります。そのため可能な部分でマッピングを最適化することをお勧めしています。データを投入するにつれて大きく差がついていきます。
シャードをできる限り大きくする
Elasticsearch内の各インデックスには1つ以上シャードがあり、それぞれのシャードにヒープ領域を使用する負荷が生じます。こちらのシャーディングに関するブログ記事に詳しく説明していますが、シャードが小さいと、シャードが大きい場合に比べてデータ量あたりの負荷が増えます。大量のデータを扱うノードでヒープの使用量を最少にとどめるには、シャードをできる限り大きくすることが重要です。私の経験則では、長期保持データの平均シャードサイズは20GBから50GB程度です。
クエリやアグリゲーションはシャードごとにシングルスレッドで実行されるため、通常、クエリの最小レイテンシはシャードサイズに依存します。シャードサイズはデータとクエリにより異なり、同じユースケース内でもインデックスごとに異なる可能性もあります。特定のデータ量とデータタイプに対してサイズの小さいシャードを数多く設定する場合、1つの大きなシャードを設定するよりもパフォーマンスが高いとは限りません。
クエリの仕様や、負荷の最小化という観点で最適化するには、シャードサイズについてテストを行うことが重要です。
ストレージ量の調整
JSONソースの効率的な圧縮は、ディスク上に占めるデータの大きさに大きく影響します。デフォルトで、Elasticsearchはストレージとインデックススピードのバランスの良い圧縮アルゴリズムを使用します。しかし、オプションとしてbest_compressionコーデックのように、より積極的な方法も用意されています。
あらゆる新規のインデックスの仕様として使うことができますが、インデックス中のパフォーマンスはおよそ5-10%ほど低下します。それでもディスク容量節約の効果は大きいので、検討に値するオプションと言えます。
前出のセクションのアドバイスにしたがってインデックスを強制的にマージしている場合は、強制マージ操作の直前にこの圧縮方法を実施することもできます。
不要な負荷を排除する
ヒープの使用量に影響する要因として考慮すべき最後のポイントは、リクエスト処理です。Elasticsearchに送られるすべてのリクエストは、リクエスト先のノードで調整されます。それから作業は分割され、データがある場所へと拡散します。このプロセスは、クエリやインデキシングにも当てはまります。
リクエストをパースして調整し、回答するという処理で、かなりのヒープを使用します。調整やインデキシングの処理を行うノードには、その分のヒープの余力を確実に残しておく必要があります。
長期に保持するデータストレージ向けに調整する場合、ノードを専用データノードとして稼働させ、そこで実行する付加的な作業をできるだけ減らすことが合理的となることも多くあります。すべてのクエリをHotノードに送るか、あるいはCoordinatingだけに特化したノードに送るよう設定することで、負荷分散を実現できる可能性もあります。
Elasticsearch Serviceのデプロイで実践する
Elasticsearch Serviceは現在AWSとGCPで提供されています。インスタンスはどちらでも同じように構成でき、どちらのプラットフォームでもデプロイテンプレートを活用できますが、細かな仕様はやや異なります。このセクションではプラットフォームによるインスタンス構成の違いと、この記事の前半に登場したさまざまなアーキテクチャーを各プラットフォームに合わせて設定する方法をご説明します。事例となるユースケースをサポートするために必要なクラスターサイズを見積もる方法についても少し触れたいと思います。
利用できるインスタンス構成
Elasticsearch Serviceはサービス開始当初から、高速SSDストレージによるElasticsearchノードを提供しています。HighIOノードと呼ばれ、I/Oに非常に優れています。Hot-WarmアーキテクチャーのHotノードに最適ですが、ユニフォームアーキテクチャーのデータノードとして使うこともできます。後者は保持期間が短く、パフォーマンスに優れたストレージが必要な場合にお勧めです。
AWSとGCPのHighIOはディスク対RAMの比率が30:1です。つまり、RAM 1GBごとに30GBのストレージを使用することができます。AWSで使えるノードサイズは1GB、2GB、4GB、8GB、15GB、29GB、58GB、一方GCPでは1GB、2GB、4GB、8GB、16GB、32GB、64GBで使用することができます。
この他に、最近Elastic Cloudに導入されたのが、ストレージの最適化を図るタイプのhighstorageノードです。やや低速かつ大容量のストレージを搭載し、ディスク対RAMの比率は100:1です。GCPでは64GBのhighstorageノードを使用する場合6.2TB以上のストレージとなり、AWSでは58GBノードを使用して5.6TBがサポートされます。RAMサイズのラインナップは、どちらのプラットフォームを使用する場合もHighIOノードと同じです。
highstorageノードは一般的に、Hot-WarmアーキテクチャーのWarmノードに使用されます。各highstorageノードのベンチマークを見ると、サイズの違いを考慮してもなお、GCPのhighstorageノードのパフォーマンスはAWSに比べてはっきりと上回っています。
アベイラビリティゾーンは2つ、または3つ使う
多くの国や地域では、2つ、または3つのアベイラビリティゾーンを利用するオプションが提供されています。さらにクラスター内のゾーンごとに数を変えることができるようになっています。一定数のアベイラビリティゾーンを使用する場合、少なくともクラスターの規模が小さければ、使えるクラスターサイズはおおよそ2倍になります。2つ、あるいは3つのアベイラビリティゾーンでどちらかを選ぶ場合、手順の少ない方法を選ぶのもお勧めです。同じノードサイズでアベイラビリティゾーンを2つから3つに増やしても、キャパシティは50%しか増えないからです。
サイズ設定例:Hot-Warmアーキテクチャー
この事例では、1日に生のWebアクセスログ100GBの投入を処理することができ、保持期間が30日間というHot-Warmクラスターのサイズ設定を考えます。AWSとGCPで、Elastic Cloudへのデプロイを比較してみます。
使用するデータは一例です。ご利用のユースケースのデータとは大きく異なる可能性がありますので、ご注意ください。
手順1:総データ量を見積もる
この事例では、投入にFilebeatモジュールを使用しており、マッピングは最適化されていると仮定します。また簡易化のため、1つのデータタイプのみ扱うものとします。インデキシングのベンチマークから、生のデータサイズに対するインデックス後のディスク上のサイズの比率が約1.1であることがわかっています。つまり生のデータ100GBから、110GBのインデックス済みデータがディスクに格納されると予測できます。レプリカ分を加えると、サイズは倍の220GBです。
30日を経過すると、インデックス済みデータとレプリカデータの合計量は6,600GB。この値が、このクラスターで処理しなければならない量です。
この事例では、すべてのゾーンで1つのレプリカシャードを使用すると仮定します。パフォーマンスとアベイラビリティからみてベストプラクティスと考えられる数字です。
手順2:Hotノードのサイズを計算する
手順1に登場したデータセットでHotノードに対し、最高レートでインデキシングするベンチマークテストを実行したところ、AWSとGCPの両方で、highIOノードのディスクが一杯になるまで約3.5日かかることがわかりました。
トラフィック中のクエリや多少のピークに対処する余地を残すため、最高値の50%以下のインデキシングレートしか保持できないと仮定します。このノードのストレージを最大に活用するには、より長期間ノードにインデックスを行う必要があります。したがってノードの保持期間もそのように調整しなくてはなりません。
またElasticsearchでは動作の効率性を確保するディスクウォーターマークを超えないようにディスク容量に余裕をもたせる必要があります。ここではディスク容量に15%の余分を保つことにします。下の表で「必要なディスク容量」の列にある値です。ここまでの条件に基づいて、AWSとGCPでそれぞれ必要なRAMの合計量を計算した結果が下の表です。
| プラットフォーム | ディスク対RAM比率 | 一杯になるまで(日) | 有効な保持期間(日) | 保有データ量(GB) | 必要なディスク容量(GB) | 必要なRAM(GB) | ゾーンの仕様 |
| AWS | 30:1 | 3.5 | 7 | 1440 | 1656 | 56 | 29GB、2アベイラビリティゾーン |
| GCP | 30:1 | 3.5 | 7 | 1440 | 1656 | 56 | 32GB、2アベイラビリティゾーン |
手順3:Warmノードのサイズを計算する
Hotノードで保持期間を超過したデータはWarmノードに移動します。高いウォーターマークも考慮に入れながら、ノードで保有する必要のあるデータ量を計算することにより、Warmノードに必要なサイズを予測できます。
| プラットフォーム | ディスク対RAM比率 | 有効な保持期間(日) | 保有データ量(GB) | 必要なディスク容量(GB) | 必要なRAM(GB) | ゾーンの仕様 |
| AWS | 100:1 | 23 | 5060 | 5819 | 58 | 29GB、2アベイラビリティゾーン |
| GCP | 100:1 | 23 | 5060 | 5819 | 58 | 32GB、2アベイラビリティゾーン |
手順4:その他のノードタイプを加える
一般的にはデータノードのほかに、クラスターのレジリエンスや高可用性を保つために3つの専用マスターノードを併用します。専用マスターノードにはトラフィックが生じないため、サイズは大きくなりません。使いはじめる際は、3つのアベイラビリティゾーン全体で1GBから2GB程度割り当てれば十分です。管理するクラスターの増加に応じて専用マスターノードをスケールさせる場合も、3つのアベイラビリティゾーンで最大16GB程度です。
使いはじめる
Elasticsearch Serviceをまだ使ったことがない、という方はぜひ14日間の無料トライアルでお試しください。設定から管理までとても簡単です。Elastic CloudのElasticsearch Serviceに関するご質問やご相談は、お気軽にElasticへお問い合わせください。公開型のディスカッションフォーラムもあります。