サイバーセキュリティと機械学習 ― 教師ありモデルでDGAアクティビティを検知する
たとえば、ランダムに生成された電話番号からセールスの電話がくる状況を考えてみましょう。どれほど厄介でしょうか?その番号をブロックしたところで、次は全く新しい番号からかかってくるので意味がありません。この汚い手口は現在、サイバー攻撃に使われているものと同じです。DGA(ドメイン生成アルゴリズム)を使うマルウェア作成者は、コマンド&コントロールインフラストラクチャーのソースを変更して検知を回避し、マルウェア攻撃の阻止に挑むセキュリティアナリストに挫折感を抱かせます。
このブログシリーズでは2回にわたり、Elasticの機械学習を使ったドメイン生成アルゴリズム検知モデルの構築と評価を実演します。パート1となる今回のコンテンツは、次の通りです。
- 生の悪意があるドメインと無害なドメインから特徴を抽出するプロセス
- 適切な特徴を見つけるプロセスについての解説
- Elastic Stackを使って機械学習モデルを教育、評価する手法の実演
パート2では、教育済みモデルをインジェストパイプラインにデプロイし、Packetbeatデータをインジェスト時にエンリッチする方法を解説します。設定ファイルとサポートマテリアルはこちらの事例レポジトリで取得していただくことができます。
ご自身で同じ手順を再現される場合は、Elasticsearch Serviceの無料トライアルをご利用いただくことをおすすめしています。このトライアルで、すべての機械学習にアクセスできます。それでは早速始めましょう。
DGA ― 背景
悪意あるプログラムの多くは、標的のマシンを感染させると、次にコマンド&コントロール(C&C、またはC2)サーバーと呼ばれるリモートサーバーへのアクセスを試みます。その目的は、こっそりとデータを抽出したり、指示やアップデートを受信したりすることです。そのため、悪意のあるバイナリはC&CサーバーのIPアドレスまたはドメインを把握しなければなりません。このIPアドレスまたはドメインがバイナリ内でハードコーティングされている場合、ドメインをブロックリストに追加して通信を妨害する防衛策を講じることはそれほど難しくありません。
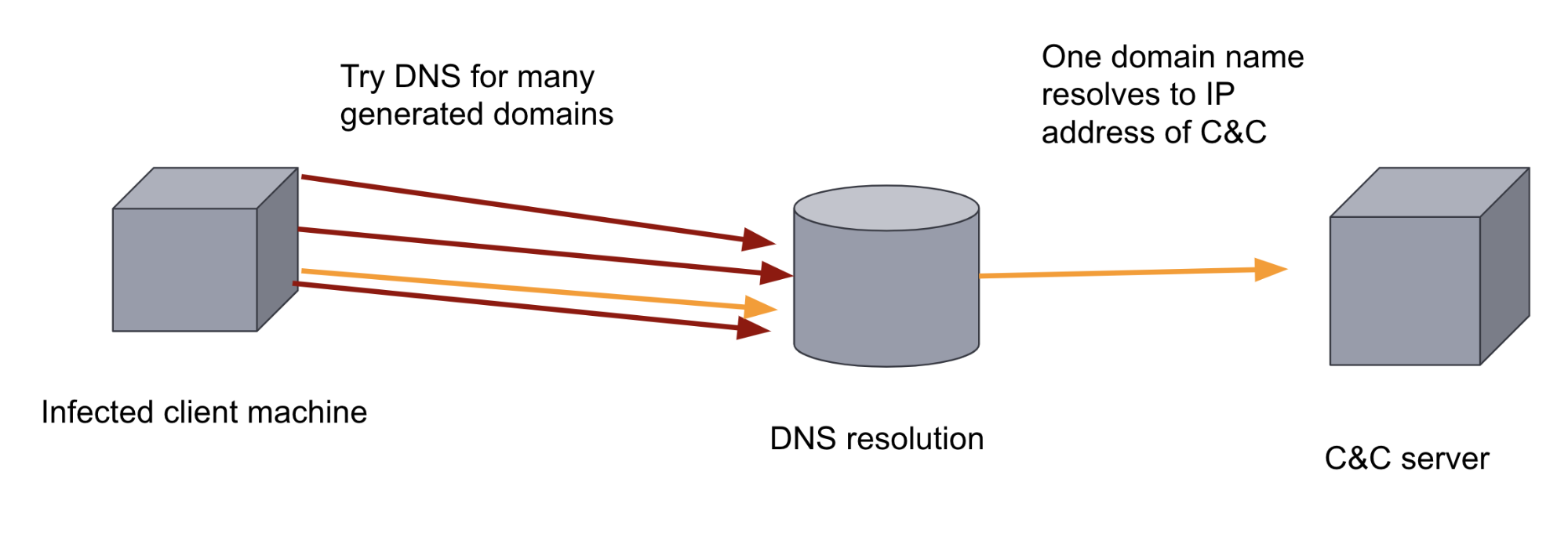
マルウェアの作成者は、その防衛策に対抗する目的で、マルウェアにDGAを追加する可能性があります。DGAは、ランダムに見えるドメインを数百、あるいは数千も生成します。マルウェアバイナリは、感染したマシン上で生成した各ドメインを順繰りに使用し、C&Cサーバーとして登録されたドメインを見つけ、ドメイン名を解決しようと試みます。ドメインは膨大なボリュームとランダム性を備えており、ルールベースの防御アプローチでこの通信チャネルを妨害するのは容易ではありません。また、DNSトラフィックは通常大量のデータであるため、人間のアナリストには困難な作業となります。裏を返せば、この2つのファクターは機械学習を適用する状況として理想的です。
機械学習モデルを教育し、ドメインを分類させる
教師ありの機械学習では、悪意あるドメインと無害なドメインで構成される分類済みの教育用データセットを用意します。このデータセットを使ってモデルを教育した後、見たことのないドメインを悪意があるものとそうでないものに分類させます。
DGAには多種多様なバリエーションがあり、それぞれメカニズムも異なります。ランダムに見えるドメインを生成するDGAもあれば、単語リストを使用するものもあります。モデルの構築にあたっては、多様なアルゴリズムの特徴を捉えることができるよう、特徴とモデルもさまざまなものを使う方法が考えられます。今回は解説用の事例なので、最も一般的なアルゴリズムで発見された特徴をベースに、1つのモデルを教育します。
モデルの教育には、多様なマルウェアファミリーのドメインと、無害なドメインで構成されたデータセットを使用します。

cryptolocker、banjori、suppoboxマルウェアファミリーで生成されたドメインの例
特徴エンジニアリング
効果的な機械学習モデルを構築するためには、DGAが生成するドメインの特性を捉えた特徴をインプットする必要があります。モデルに対し、悪意あるドメインと無害なドメインを区別するにあたって、文字列のどの側面が重要なのかを教えなくてはなりません。機械学習の領域ではこの作業を“特徴エンジニアリング”と呼びます。
無害なドメインを悪意あるドメインから適切に区別する特徴を理解するプロセスは、反復的です。具体的には、私たちは当初ドメイン名の長さやドメイン名のエントロピーといったシンプルな特徴で開始しましたが、できあがったモデルはLSTMなどの他のメソッドのモデルに比べて特に精度が良くはなりませんでした。LSTMモデルは文字列のシーケンス上の特徴を利用します。そこで私たちはシーケンスをより効果的にエンコードする別の特徴を探し求めました。
いくつかの特徴エンジニアリングアプローチを反復した結果、さまざまな長さの部分文字列が、悪意あるドメインと無害なドメインの違いを最もよく捉えるという結論にいたりました。
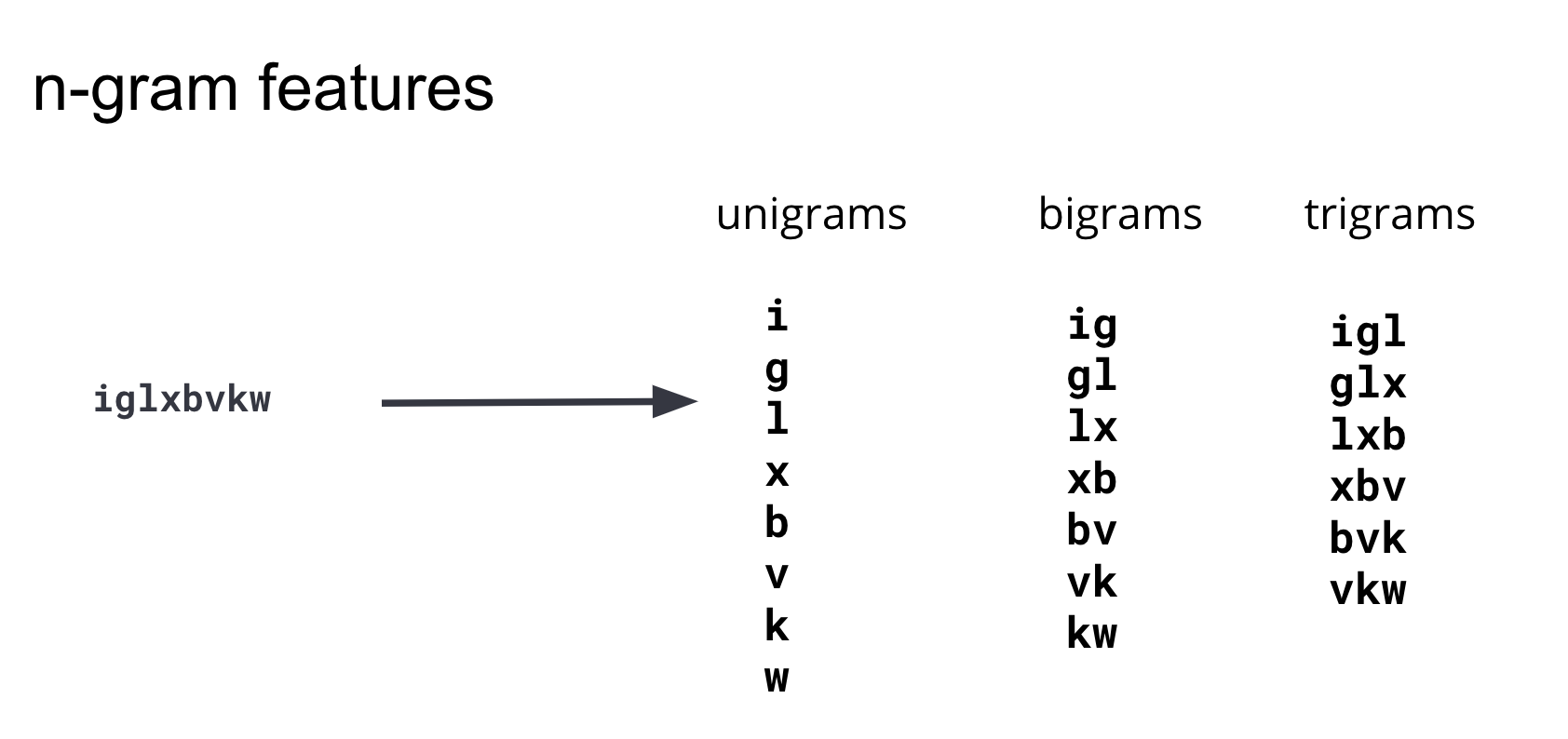
この部分文字列はn-gramとして広く知られています。機能を採用する際、モデルにもたらされるメリットを考慮して、機能の数(教育用データセットの次元数)と、その機能の演算処理の複雑さのバランスを保つことが大切です。さまざまな長さのn-gramを反復的にテストした結果、私たちは4以上の長さのn-gramはモデルに有意な予測情報をもたらさないという結論を導き、特徴セットにはユニグラム、バイグラム、トライグラムに限って採用することにしました。図3は、サンプルドメインからこれらの特徴を生成する仕組みを図解したものです。
ユニグラム、バイグラム、トライグラムに分割された各DGAドメインを格納したElasticsearchインデックスを作成するには、インジェストパイプラインでpainless script processorを使い、オリジナルのソースインデックスを再インデックスします。下の図4は、このスクリプトの例を示しています。 すべての設定、手順、様々なカスタマイズのオプションについては、事例レポジトリをご参照ください。
POST _scripts/ngram-extractor-reindex
{
"script": {
"lang": "painless",
"source": """
String nGramAtPosition(String fulldomain, int fieldcount , int n){
String domain = fulldomain.splitOnToken('.')[0];
if (fieldcount+n>=domain.length()){
return ''
}
else
{
return domain.substring(fieldcount, fieldcount+n)
}
}
for (int i=0;i<ctx['domain'].length();i++){
ctx[Integer.toString(params.ngram_count)+'-gram_field'+Integer.toString(i)] = nGramAtPosition(ctx['domain'], i, params.ngram_count)
}
"""
}
}
一般的に、長さ1、2、3の部分文字列を機械学習アルゴリズム向けに数的ベクトルに変換するには、さらに事前処理を行う必要があります。しかしElasticの機械学習は、数的ベクトルへの変換(すなわち、エンコーディング)も行ってくれます。さらに、Elasticの機械学習は特徴を調べ、最も多く情報を持つ特徴を自動的に選択します。
データフレーム分析ジョブを作成する
次に、[Data Frame Analytics UI](データフレーム分析UI)を使って分類ジョブを作成します。下のスクリーンショットで、このプロセスの重要な項目が強調表示されています。
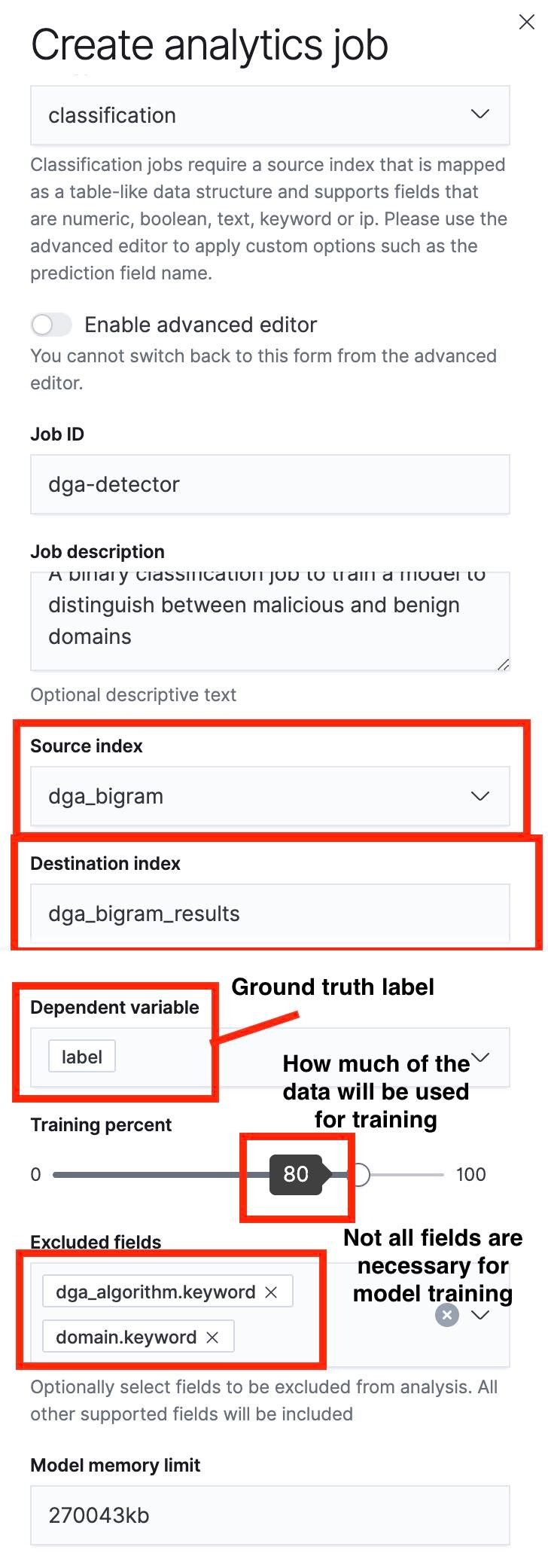
まず注目したいのは、スライダーを使って教育とテストに使うドキュメントの割合を指定できることです。図5のスクリーンショットでは、教育/テストの割合が80%に指定されています。これは、ソースインデックスのドキュメントの80%がモデルの教育に使用され、残りの20%がモデルのテストに使われるという意味です。
教育のプロセスが完了したら、[Data Frame Analytics Results UI](データフレーム分析結果UI)に戻り、モデルのパフォーマンスを評価します。ソースインデックスはすでに教育用セットとテスト用セットに分割されているので、それぞれに対してモデルのパフォーマンスを確認できます。教育パフォーマンスとテストパフォーマンスはいずれも貴重な情報です。ただ、今回のケースではモデルがテストデータセットで発揮するパフォーマンスが特に重要です。というのも、テストパフォーマンスはモデルの汎化誤差を示すからです。この誤差は、モデルの初見のデータポイントに対するパフォーマンス指標になります。
機械学習モデルを評価する
教育プロセスが完了したら、Elasticの機械学習UIジョブ管理ページをクリックしてビューを開き、結果を確認します。
結果ページ(図6参照)には、2つの重要な情報が表示されます。1つ目、混同行列は、モデルのパフォーマンス概要を示しています。2つ目の結果の表は、ドリルダウンすることでモデルが個々のデータポイントをどのように分類したか確認できます。表の右上にある[Testing]と[Training]のフィルターをクリックして、テストデータセットと教育データセットの混同行列と概要の表を切り替えることができます。
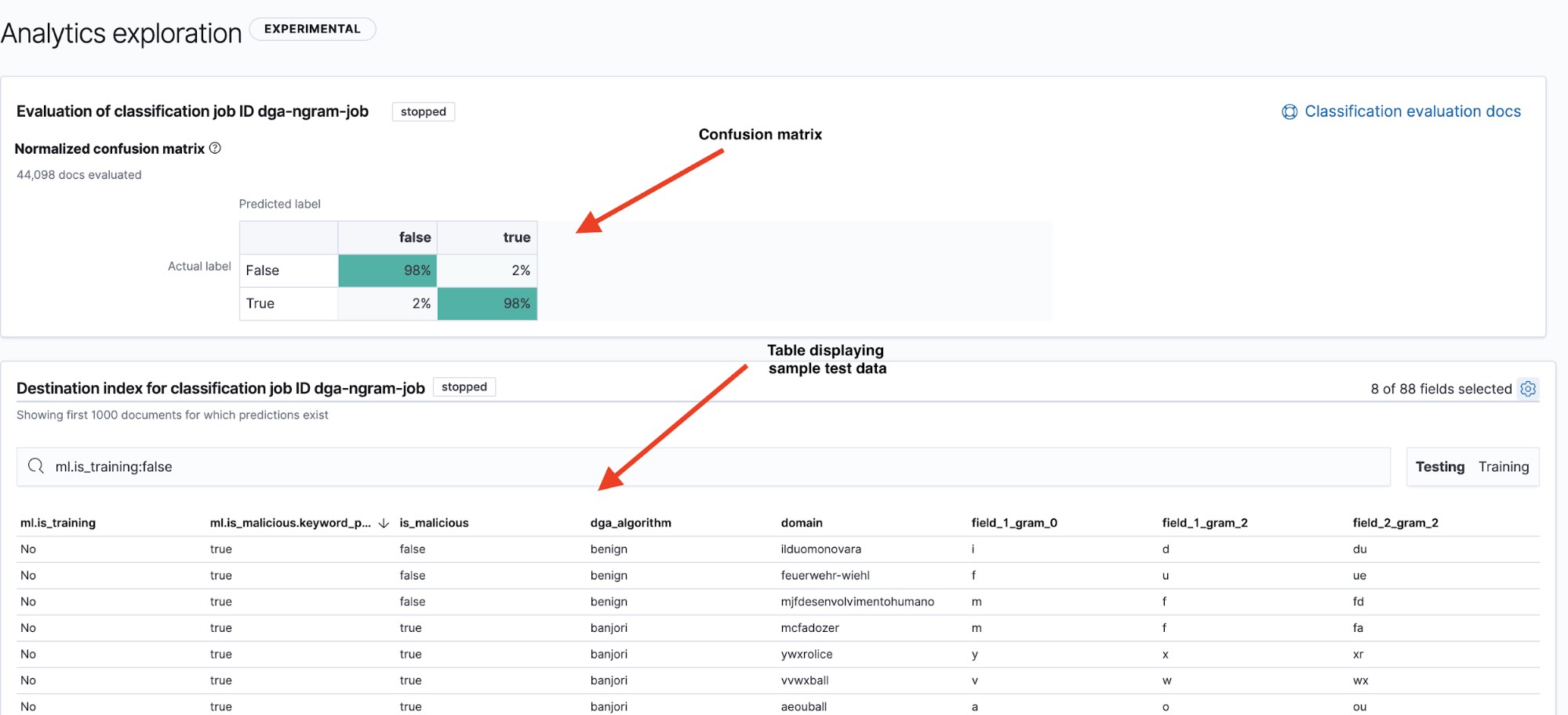
混同行列は、視覚的にモデルのパフォーマンスを表示する一般的な方法として知られています。混同行列は、真陽性(モデルにより“悪意がある”と特定され、かつ実際に悪意があるドメイン)および真陰性(モデルにより“無害”と特定され、かつ無害なドメイン)と分類されたデータポイントのパーセンテージを示すほか、モデルにより“悪意がある”と混同(誤解)された無害なドメイン(偽陽性)とその逆(偽陰性)のパーセンテージも示します。
名前の通り、混同行列はモデルが1つのインスタンスクラスを他のクラスと頻繁に混同するかどうかを簡潔に表示します。
図6からは、モデルがテストデータで98%の真陽性率を出したことが分かります。つまり、このモデルを本番環境にデプロイして流入するDNSデータを分類させた場合、偽陽性率はおよそ2%となると期待されます。極めて低い数字のように見えますが、DNSトラフィックは非常に大量であるため、これでもアラート率はかなり高くなる可能性があります。パート2となる次回は、異常検知を使って偽陽性のアラート数を減らす方法を解説します。
まとめ
この記事では、Elasticの機械学習を使ってDGAを検知する機械学習モデルを構築、および評価する手法を概観しました。具体的には、生の悪意があるドメインと無害なドメインから特徴を抽出するプロセスを解説したほか、適切な特徴を見つけるプロセスについても触れました。また後半では、Elastic Stackを使って機械学習モデルを教育、および評価する方法をご紹介しました。
シリーズ後編となる次回は、インジェストパイプラインに推論プロセッサーを使ってこのモデルをデプロイし、流入するPacketbeatデータをドメインの悪意度の予測でエンリッチする方法と、異常検知を使って偽陽性のアラート数を減らす方法を解説します。次回までにElasticの機械学習機能を無料でご試用いただくこともできます。データ中のノイズを見分けることによって得られるインサイトを、ぜひ実際に体感してください。