File Data VisualizerでCSVとログデータをElasticsearchに取り込む
Elastic Stack 6.5よりFile Data Visualizer機能が登場しています。この機能を使用して"区切り"を含むファイル(例:CSV)やNDJSON、準構造化テキスト(例:ログファイル)をアップロードすると、Elastic Machine Learningのfind_file_structureエンドポイントがファイルを分析し、データに関する情報をレポートバックします。レポートバックされる情報には、UIからElasticsearchにファイルをインポートする際に使用する投入パイプラインとマッピングの提案も含まれます。
この機能の狙いは、KibanaやMachine Learningでデータを探索しようと考えるユーザーが複雑な投入プロセスで手間取る状況を回避し、少量のデータも気軽にElasticsearchに入れられるようにすることです。
わかりやすい例として、開発系の出身ではないElasticのマーケティングスタッフが書いたこちらのブログ記事があります。このスタッフはFile Data Visualizerを使って地震データを手軽にElasticsearchに取り込み、Kibanaのgeo_point可視化機能で地震の位置情報を探索・分析しています。
事例:CSVファイルをElasticsearchにインポートする
この機能は具体的な事例のデモンストレーションで説明するとよりわかりやすくなります。以下で、架空の飛行機のフライト予約Webサイトのデータを含むCSVファイルを使用するという事例を見てみましょう。このファイルの冒頭5行は次のようになっています。実際にどのようなデータなのか、おおよそのところを把握できます。
time,airline,responsetime 2014-06-23 00:00:00Z,AAL,132.2046 2014-06-23 00:00:00Z,JZA,990.4628 2014-06-23 00:00:00Z,JBU,877.5927 2014-06-23 00:00:00Z,KLM,1355.4812
File Data VisualizerにCSVのインポートを設定する
File Data Visualizer機能はKibanaメニューの[Machine Learning > データビジュアライザー]からアクセスできます。ユーザーは表示画面上でファイルを選択するか、ドラッグ&ドロップすることができます。バージョン6.5では、ファイルの最大サイズは100MBに制限されています。
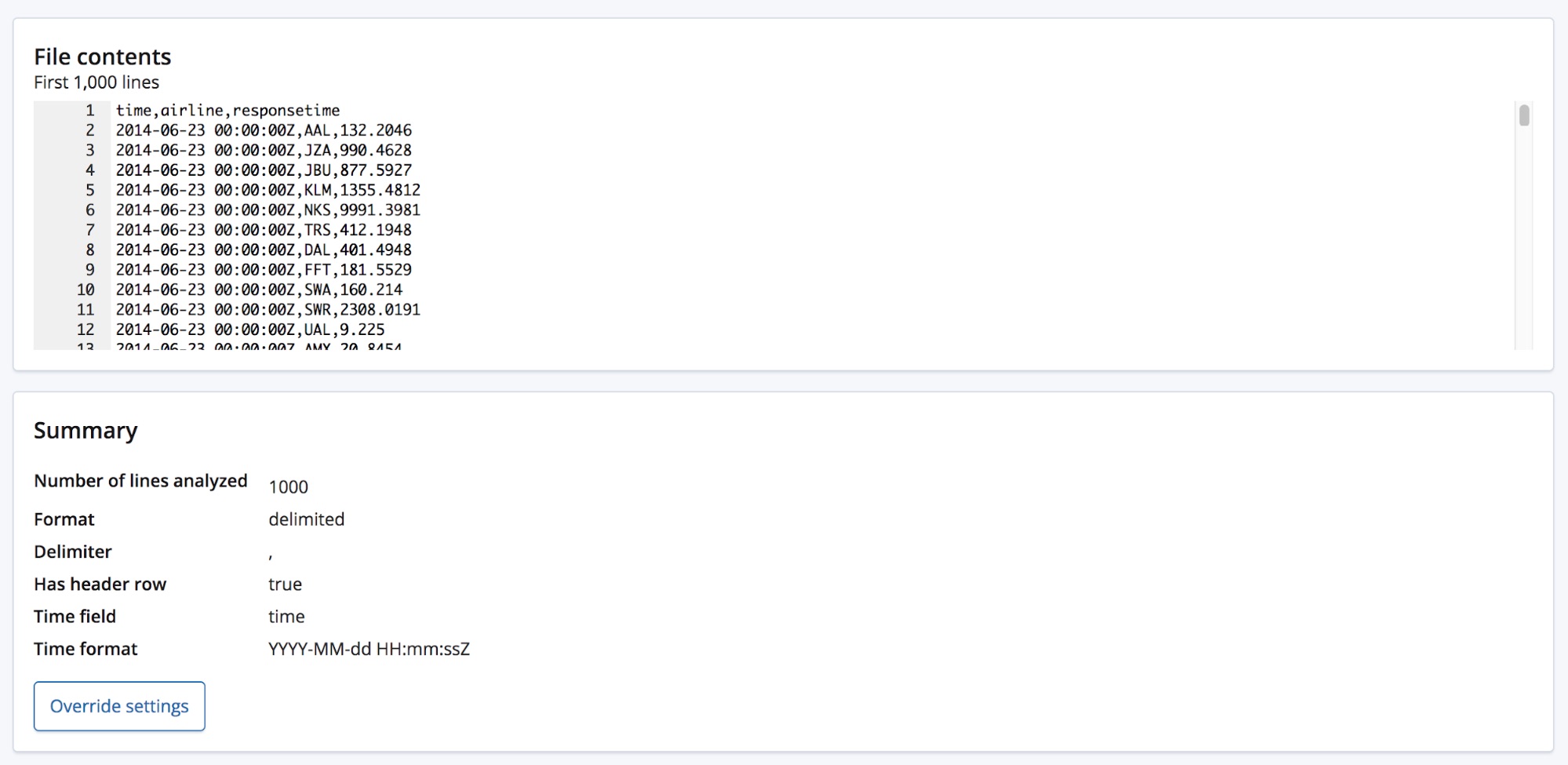
CSVファイルを選択すると、このページでファイルの最初の1,000行がfind_file_structureエンドポイントに送られ、エンドポイントは分析内容を返します。 この画面のSummary(サマリー)セクションを見ると、データが区切りフォーマットに入っていること、さらに区切り記号がカンマであることを正確に検出していることがわかります。
またヘッダー(見出し)行があること、これらのフィールド名を各列のデータのラベルとして使用していることも検出しています。1列目が既知の日付フォーマットに一致していることから、Time fieldが存在することも特記しています。
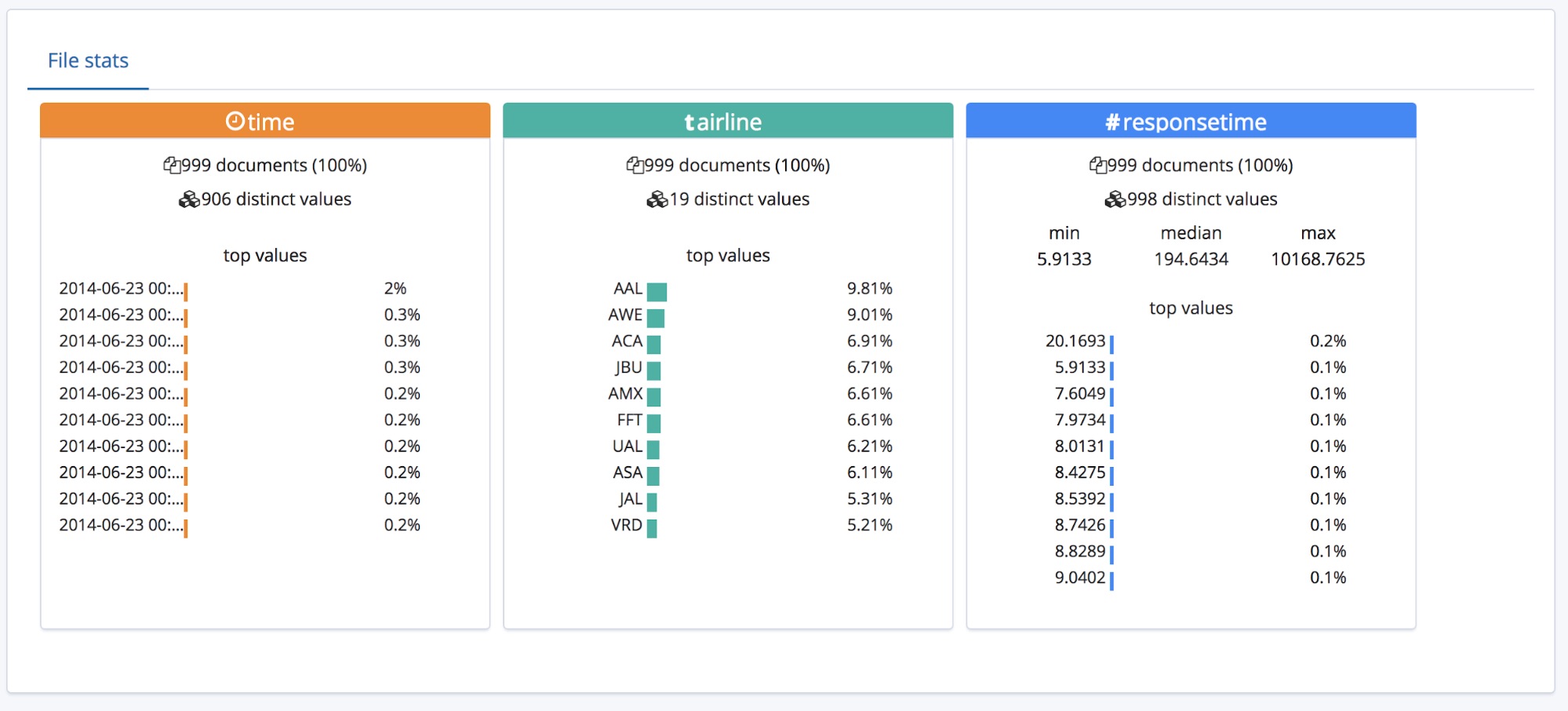
このサマリーセクションの下にはフィールドセクションがあります。以前のバージョンでData Visualizer機能を使ったことがあるユーザーにはおなじみの画面かもしれません。
ここでは3つのフィールドのタイプが正確に特定されています。各フィールドに関する高次の統計もあり、 上位10個の頻出値が各フィールドにリスト表示されています。responsetimeについては、数値のフィールドであることを判別し、min(最小値)、median(中央値)、max(最大値)を特定しています。
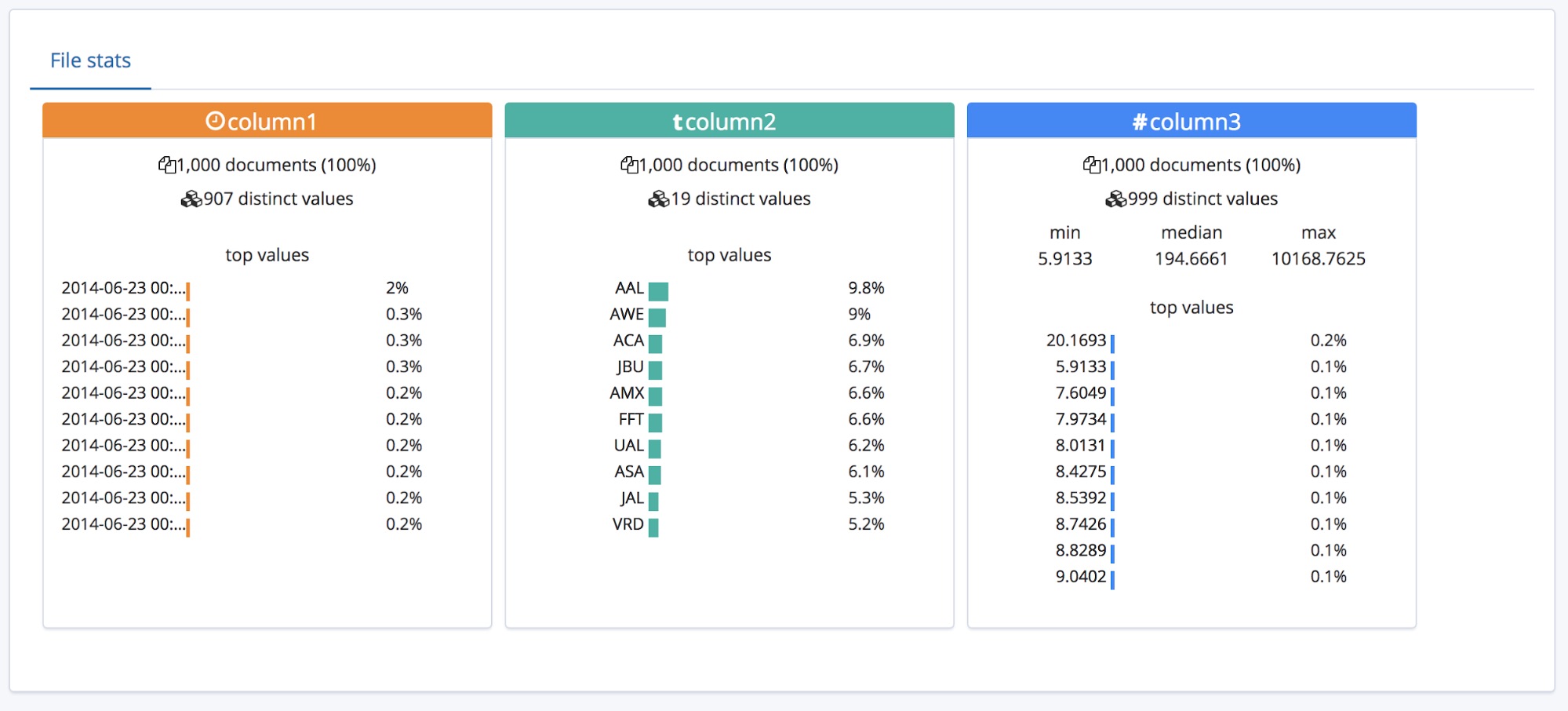
こうした挙動は、ヘッダー(見出し)行があるCSVに最適です。ところで、ヘッダー行がないデータの場合はどうなるのでしょうか。
そのような場合、find_file_structureエンドポイントは仮のフィールド名を使用します。この挙動を実演してお見せするために、先ほどのファイルから最初の行を削除し、もう一度アップロードします。今度は各フィールドが「column1」「column2」「column3」という一般的な名前で表示されました。
ファイルをアップロードしたユーザーはドメイン知識を持っていて、フィールド名をもっと適切なものに変えたいと考えるかもしれません。そんな時に使えるのが[Override settings(上書き設定)]ボタンです。
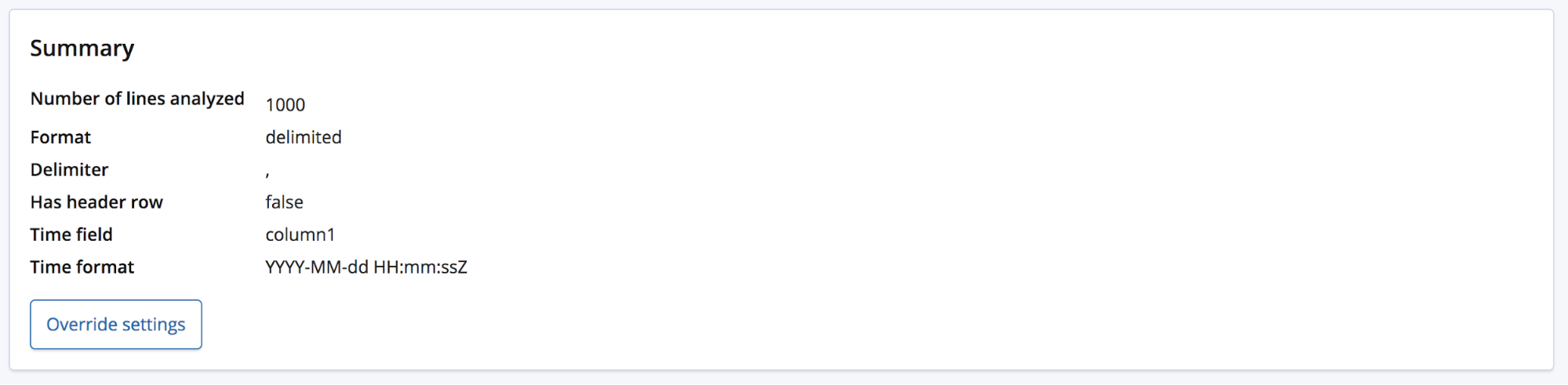
フィールド名の変更だけでなく、データフォーマットや区切り記号、引用記号などの設定も変更できます。find_file_structureエンドポイントはデータについて経験に基づいた推測を実施しますが、このセクションはその内容を修正する手段として使うことができます。複数の日付フィールドがあり、最初の1つだけが選択されている可能性もあります。ファイルにヘッダー行があっても、フィールド名を変更したいと思うことがあるかもしれません。
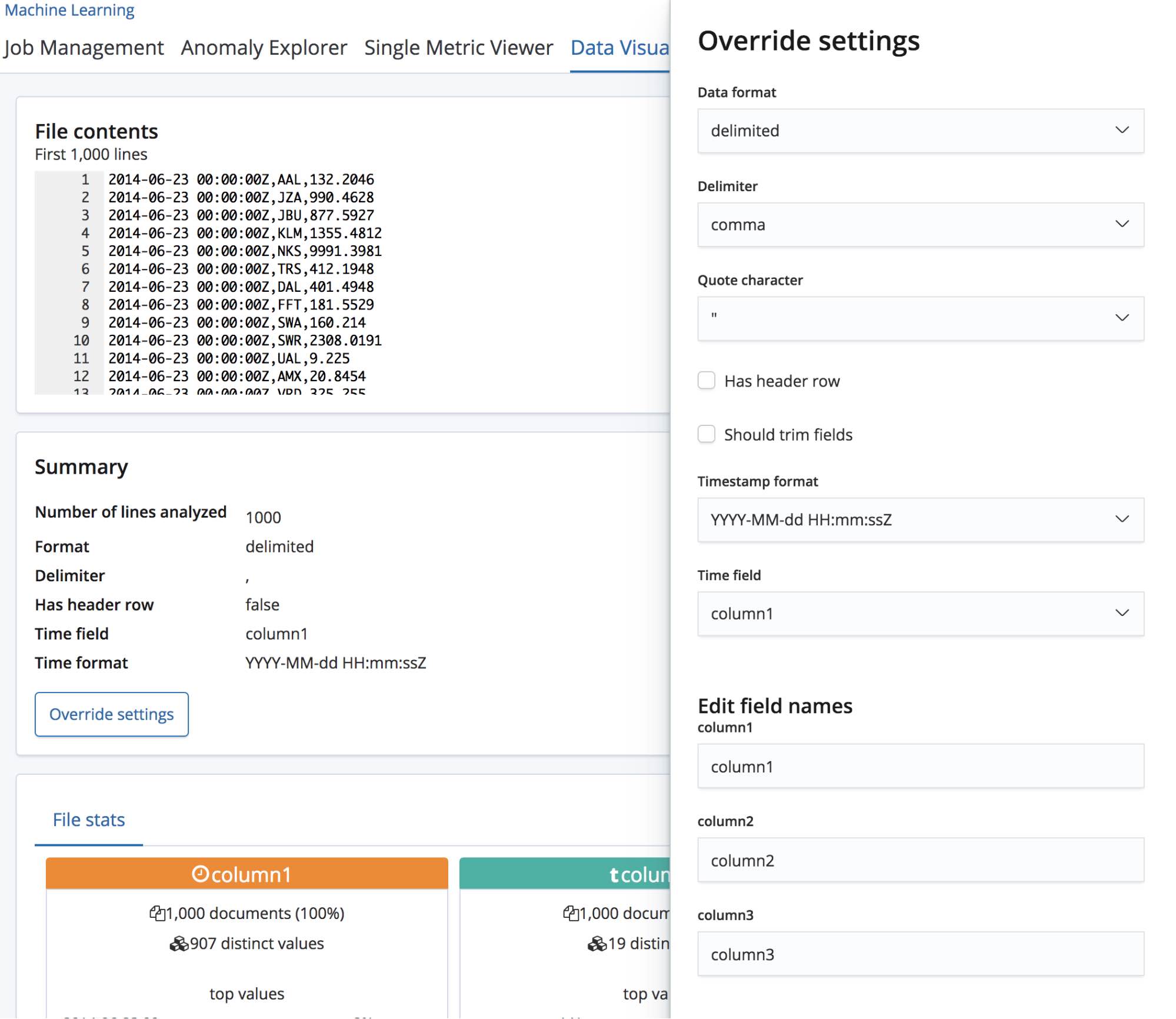
修正ですべての設定が満足できる内容になったら、ページ左下の[Import(インポート)]ボタンを押します。
CSVデータをElasticsearchにインポートする
[インポート]ボタンを押すと[インポート]ページが開き、ここでデータをElasticsearchに取り込むことができます。この機能は反復的なプロダクションプロセスとして使用されることを想定していませんので、留意してください。単なるデータの初回探索を想定しています。このことは自動化オプションが提供されていない主な理由にもなっています。別の理由としては、この機能が現在試験段階にあることがあります。
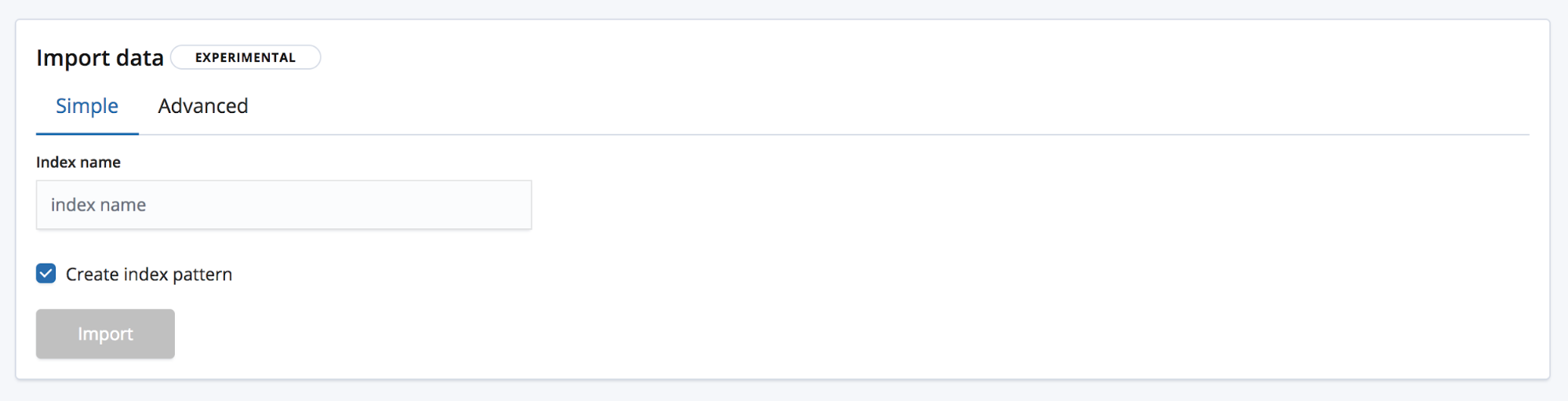
インポートには2つのモードがあります。Simple(シンプル)モードでは、ユーザーが新しい一意のインデックス名を提供し、インデックスパターンを作成する場所を選択します。
Advanced(アドバンスト)モードでは、インデックス作成に使用する設定をユーザーがより細かく制御できます。
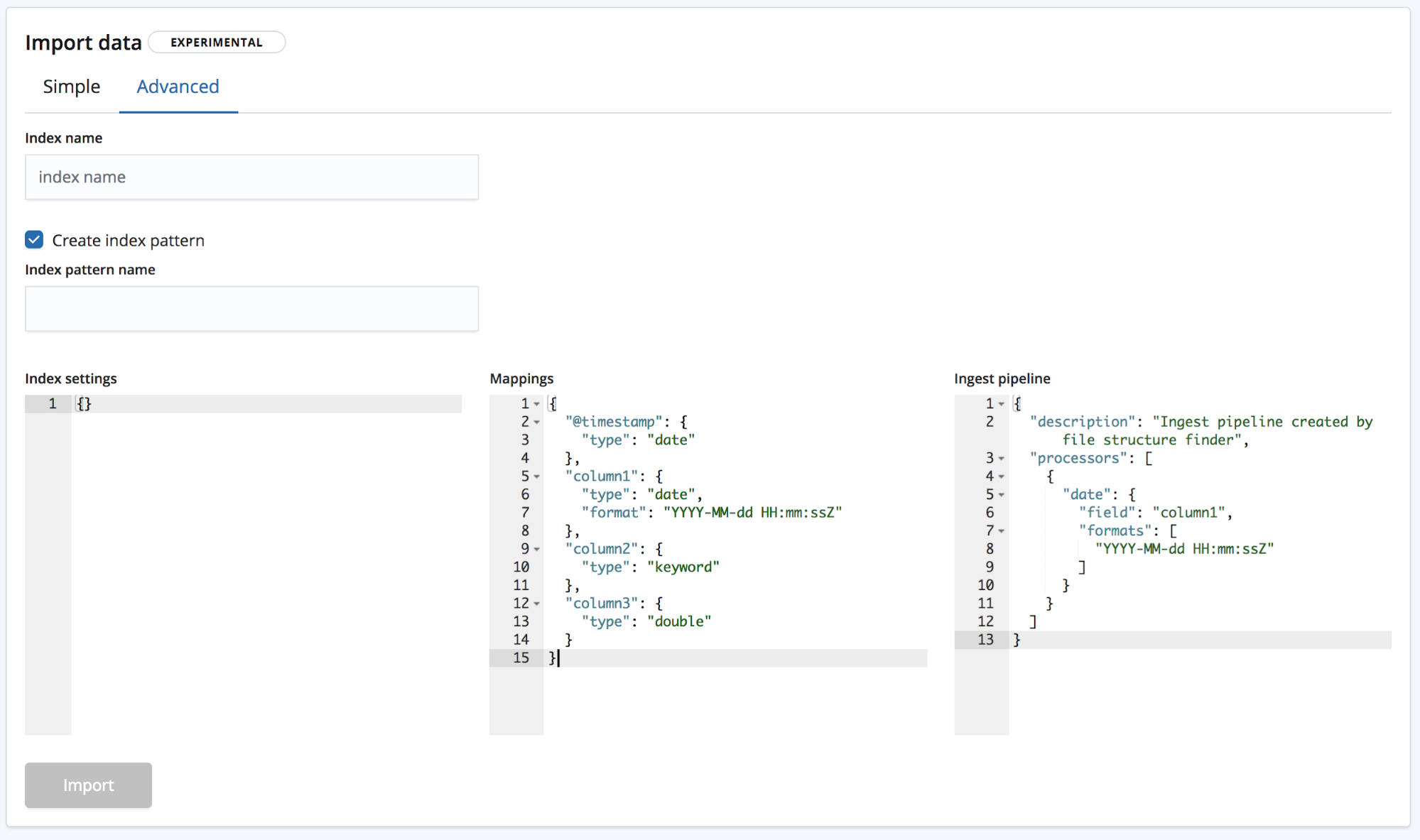
- Index settings(インデックス設定) - 基本的に、インデックスの作成とインポートに際して設定を追加する必要はありません。必要な場合は、ここでインデックス設定をカスタマイズすることができます。
- Mappings(マッピング) -
find_file_structureは、検出したフィールドとタイプに基づいてマッピングオブジェクトを提供します。検出できるマッピングは、Elasticsearchのマッピングに関するドキュメントに一覧で掲載されています。 - Ingest pipeline(投入パイプライン) - The
find_file_structureは、デフォルトの投入パイプラインオブジェクトを提供します。データ投入時や、追加のデータをアップロードする際に使用します。
6.5の時点では、新規インデックスの作成のみ対応しています。インデックスを損傷させるリスクを考慮し、既存のインデックスにデータを追加する機能は提供されていません。
[Import(インポート)]ボタンを押すとインポートプロセスがはじまります。このプロセスは、複数のステップで構成されます。
- ファイルの処理(Processing file) - バルクAPIを使用して投入できるよう、データをNDJSONドキュメントに変換します
- インデックスの作成(Creating index) - オブジェクトの設定とマッピングを使用してインデックスを作成します
- Ingestパイプラインの作成(Creating ingest pipeline) - 投入パイプラインオブジェクトを使用して投入パイプラインを作成します。
- データのアップロード(Uploading the data) - データを新規のElasticsearchインデックスに読み込みます
- インデックスパターンの作成(Creating index pattern) - (ユーザーが選択した場合)Kibanaインデックスパターンを作成します

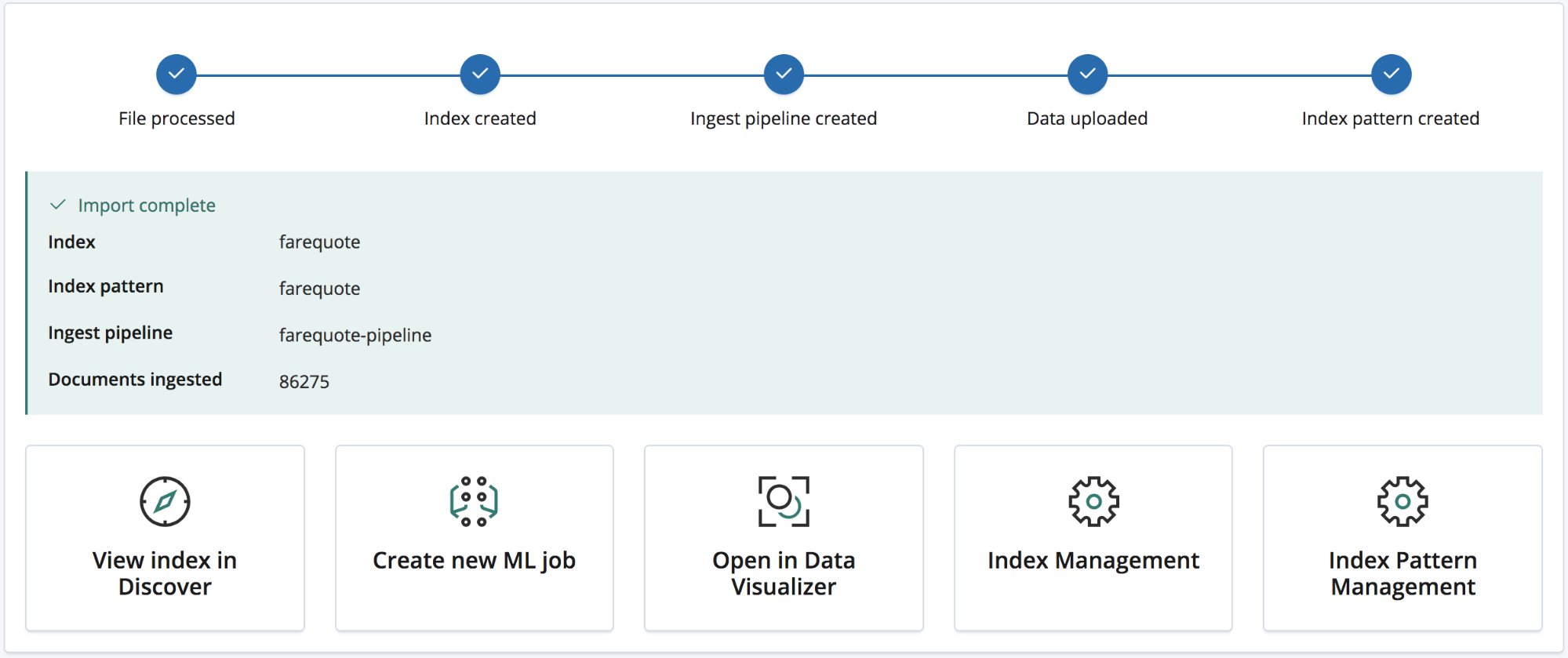
インポートプロセスが完了すると、画面にインデックス名、インデックスパターン名、投入パイプライン名、投入されたドキュメントの数、さらに
新規にインポートされたデータを探索できるKibanaのリンク数が表示されます。プラチナおよびトライアルサブスクリプションでは、このデータですばやくMachine Learningジョブを作成できるリンクも画面に表示されます。
事例:ログファイルと、その他の準構造化テキストファイルをElasticsearchにインポートする
ここまではCSVデータと、インポートの処理のシンプル化に必要となるNDJSONの取り扱いについて説明してきました。次に、準構造化テキストファイルについても見てみましょう。CSVデータと典型的なログファイルデータ(準構造化テキスト)の分析がどう違うか考えます。
以下は、ルーターが生成したログファイルから3行抜粋したものです。
<190>38377:GOW45-AR002:Apr 18 08:44:02.434 GMT: %JHG_MS-6-ROUTE_EVENT_INFO:Route changed Prefix 10.156.26.0/23, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired <190>38378:GOW45-AR002:Apr 18 08:44:07.538 GMT: %JHG_MS-6-ROUTE_EVENT_INFO:Route changed Prefix 10.156.72.0/23, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired <190>38379:GOW45-AR002:Apr 18 08:44:08.818 GMT: %JHG_MS-6-ROUTE_EVENT_INFO:Route changed Prefix 10.156.55.0/24, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired
find_file_structureエンドポイントで分析すると、ファイルのフォーマットが準構造化テキストであることを認識し、Grokパターンを作成して各行のフィールドとタイプを抽出しています。さらに複数のフィールドのうち、どれが時間フィールドか、どのようなフォーマットかも認識しました。
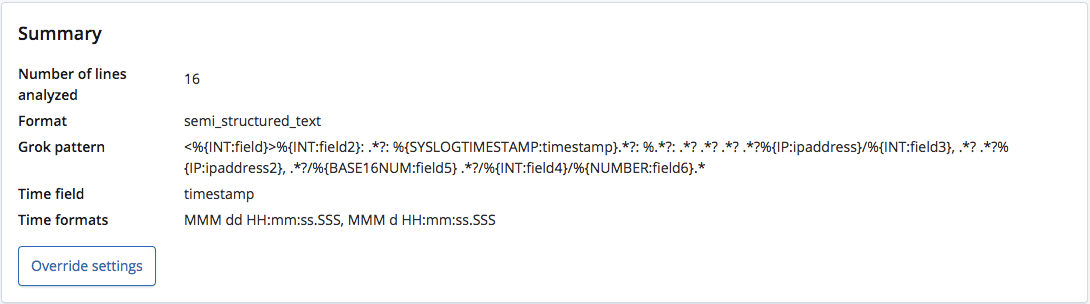
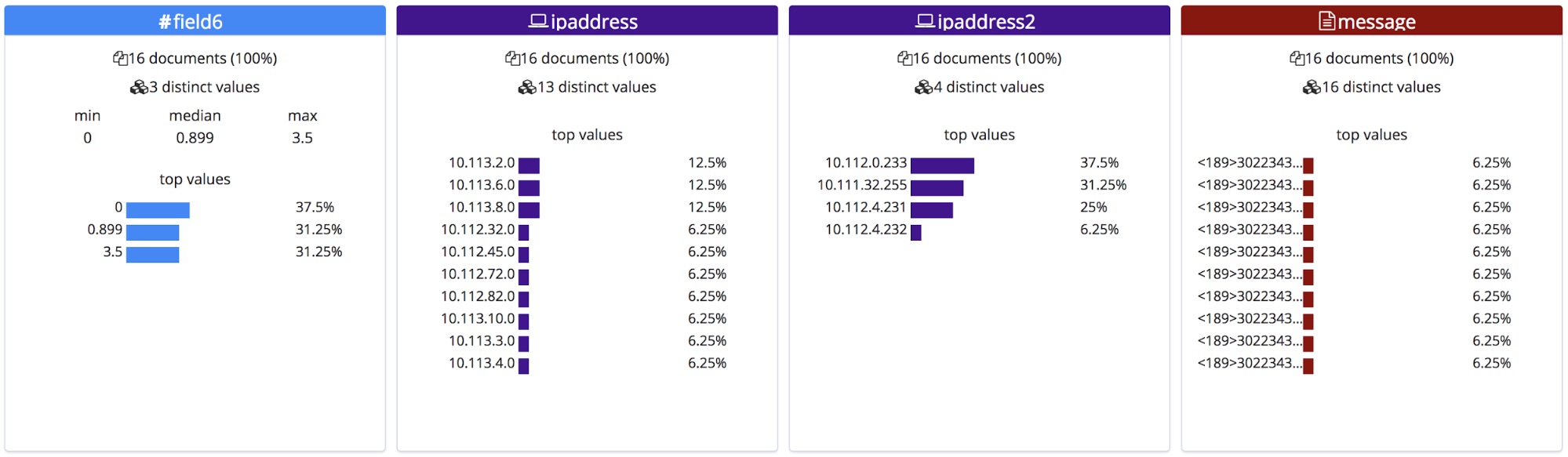
ヘッダーを含むCSVファイルやNDJSONファイルとは異なり、各フィールドの正しい名称は判別できません。そこで、このエンドポイントは各タイプに基づいて一般的な名前を付けています。
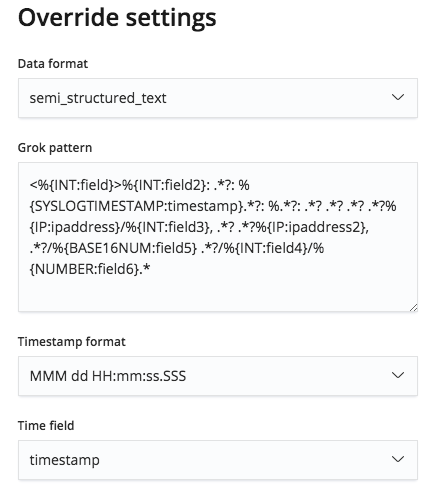
このGrokパターンは[Override settings(上書き設定)]ボタンで編集でき、必要に応じて正しいフィールド名やタイプに修正することが可能です。
フィールド名を修正すると、[File(ファイル)]統計セクションにも反映されます。このセクションはアルファベット順に表示されます。先ほどと少し順序が変わりました。
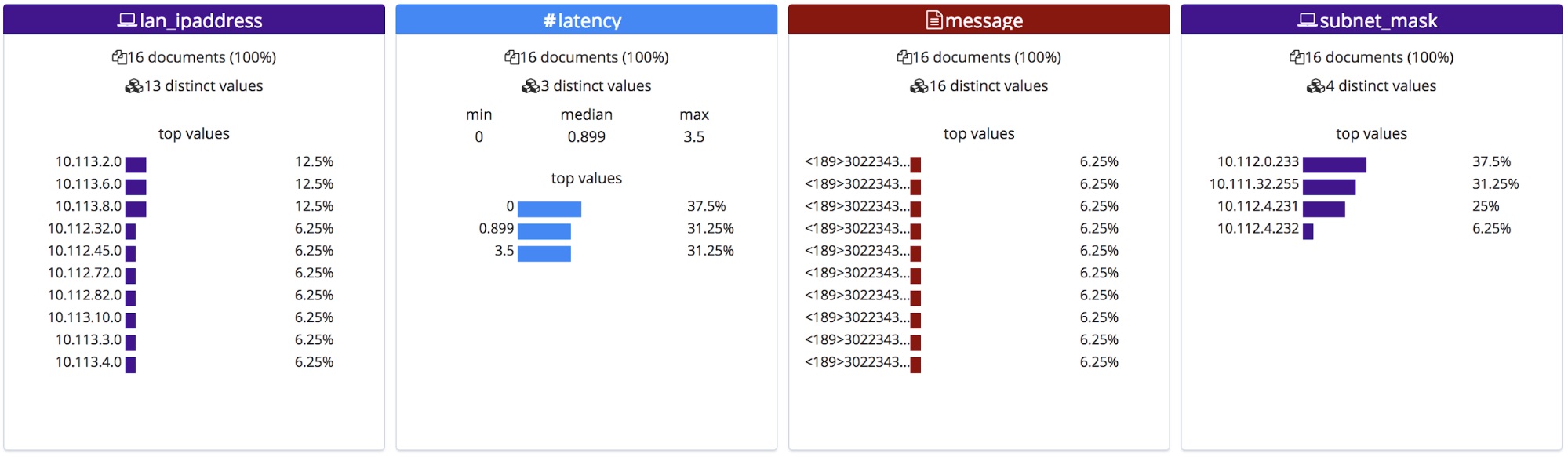
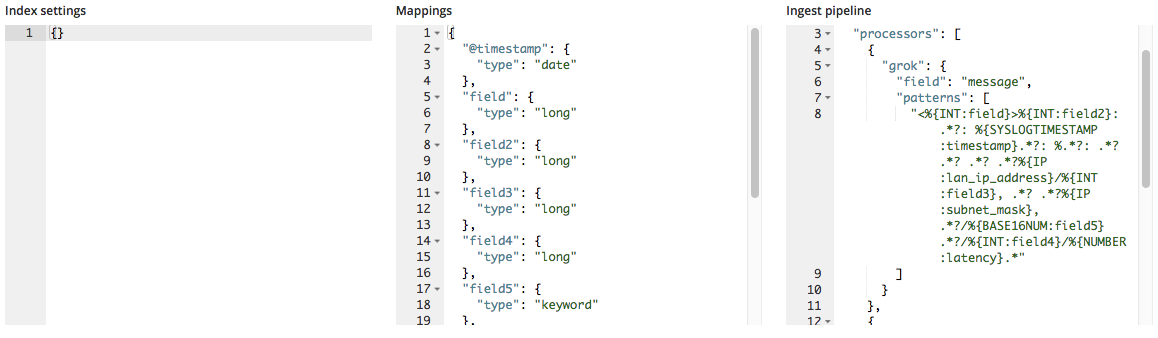
インポートすると新規のフィールド名がマッピングに追加され、Grokパターンが投入パイプラインのプロセッサーリストに加わります。
まとめ
この記事を読んで「6.5のFile Data Visualizer機能を使ってみようかな」と思ってもらえたら、それほど嬉しいことはありません。File Data Visualizerは6.5で試験的な機能としてリリースされており、すべてのファイルフォーマットに適切に一致するとは限りません。気軽にお試しいただき、お気づきの点がありましたらフィードバックをお寄せください。多くのフィードバックが集まることで、早期にGA(一般公開)へ移行できます。