KibanaでのVegaビジュアライゼーションの基本
Vegaは宣言型の文法で、データの可視化をパワフルに実現します。Kibana 6.2の新機能により、Elasticsearchデータを使用してVegaおよびVega-Liteでリッチなビジュアライゼーションを作成できるようになりました。いくつかのシンプルな例を参考にしながら、Vega言語についての学習を始めましょう。
始めるには、Vega Editorを開きます。これは、Vega言語そのもの(Elasticsearchのカスタム機能はありません)を使用して試すことができる便利なツールです。以下のコードをコピーすると、右側のパネルに「Hello Vega!」と表示されます。

{
"$schema": "https://vega.github.io/schema/vega/v3.json",
"width":100, "height":30,
"background": "#eef2e8",
"padding":5,
"marks": [
{
"type": "text",
"encode": {
"update": {
"text": { "value":"Hello Vega!" },
"align": { "value": "center"},
"baseline": { "value": "middle"},
"stroke": { "value": "#A32299" },
"angle": { "value":15 },
"x": { "signal": "width/2" },
"y": { "signal": "height/2" }
}
}
}
]
}
marksブロックでは、テキスト、円、四角など、基本的な描画要素を使用できます。各markでは、エンコーディングセット内でパラメーターを多数設定することができます。各パラメーターは定数(値)、または "update" ステージでの計算結果(シグナル)のどちらかとして設定します。 テキストマークについては、文字列を指定します。任意の座標に対して適切な位置を決め、回転を設定し、テキストの色を指定します。xおよびy座標は、グラフの幅と高さを基に計算され、テキストがその中央に置かれます。 他にも多くのテキストマークパラメーターがあります。また、テキストマークを使用したグラフのインタラクティブなデモもありますので、異なるパラメーター値を試してみてください。
$schemaは単に、必要なVegaエンジンバージョンのIDであり、backgroundでグラフを非透明にできます。widthとheightは、最初の描画のキャンバスサイズを設定します。最終的なグラフのサイズは、内容やautosize(自動サイズ調整)のオプションに基づいて変更される場合があります。Kibanaのデフォルトのautosize(自動サイズ調整)は、pad(余白)ではなくfit(サイズに合わせて調整)であるため、heightとwidthは任意となります。 paddingパラメーターは、幅と高さに加えて、グラフの周りにスペースを追加します。
データドリブン型のグラフ
次のステップでは、四角形マークを使用してデータドリブン型のグラフを描画します。 データセクションでは、ハードコードまたはURLを使用して複数のデータソースの指定が可能です。Kibanaでは、直接Elasticsearchクエリを使用することもできます。ここでのvalsデータ表は、4行と2列(categoryおよびcount)です。 categoryをx軸に表示し、countをバーの高さで示します。 ここで注意が必要なのは、y軸は上が0になっており、下に向かって数値が増えていることです。
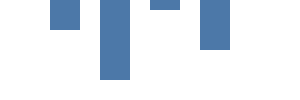
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width":300, "height":100,
"data": [ {
"name": "vals",
"values": [
{"category":50, "count":30},
{"category":100, "count":80},
{"category":150, "count":10},
{"category":200, "count":50}
]
} ],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"field": "category"},
"width": {"value":30},
"y": {"field": "count"},
"y2": {"value":0}
}
}
} ]
}
rect(四角)マークは、データのソースとしてvalsを指定します。このマークは、ソースデータの値(つまり表の行またはdatum(データ))ごとに一度だけ描画されます。先ほどのグラフとは異なり、xとyのパラメーターはハードコードされておらず、データのフィールドから取得されています。
スケーリング
スケーリングは最も重要な項目の1つであり、その概念はVegaでは少し難しいものとなっています。先の例では、画面の画素座標はデータ内でハードコードされていました。この方法はシンプルではありますが、実際のデータがそのような形式で得られることはまずありません。代わりに、ソースデータはそれぞれ固有の単位(イベント数など)で与えられ、ソースの値をピクセル単位で望ましいグラフサイズにスケールすることはグラフの役割です。
この例ではリニアスケールを使います。これは基本的に、ソースデータのドメイン(このグラフでは1000~8000およびcount=0のcount値)から、希望する範囲(ここではグラフの高さとなる0~99)に値を変換する数学的関数です。 "scale": "yscale"をyとy2パラメーターの両方に追加すると、yscaleスケーラーを使用してcountを画面の座標に変換することになります(0が99になり、ソースデータの最大値である8000が0になります)。 ただし、heightの範囲パラメーターは特殊であり、0がグラフの最下部に表示されるように変換されることに注意してください。
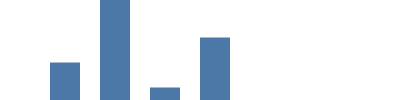
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width":400, "height":100,
"data": [ {
"name": "vals",
"values": [
{"category":50, "count":3000},
{"category":100, "count":8000},
{"category":150, "count":1000},
{"category":200, "count":5000}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"field": "category"},
"width": {"value":30},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value":0}
}
}
} ]
}
バンドスケーリング
このチュートリアルでは、15以上あるVegaスケールタイプのうち、もう1つ説明します。それはバンドスケールです。値のセット(カテゴリーなど)があり、その各セットをグラフの各バーとして表す必要がある場合に、このスケールを使用するとグラフの全幅から等分した幅でそれぞれのバーを表示することができます。ここではバンドスケールによって、4つの一意のカテゴリーに等分の幅が割り当てられています(約400/4、各バーの間と両端に5%の余白)。 {"scale": "xscale", "band":1}により、マークのwidthパラメーターとして、全幅で100%となります。
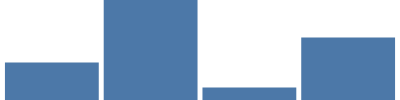
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width":400, "height":100,
"data": [ {
"name": "vals",
"values": [
{"category":"Oranges", "count":3000},
{"category":"Pears", "count":8000},
{"category":"Apples", "count":1000},
{"category":"Peaches", "count":5000}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
},
{
"name": "xscale",
"type": "band",
"domain": {"data": "vals", "field": "category"},
"range": "width",
"padding":0.05
}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"scale": "xscale", "field": "category"},
"width": {"scale": "xscale", "band":1},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value":0}
}
}
} ]
}
軸
通常のグラフを完成させるには、軸にラベルが必要です。 軸の定義 では、先ほど定義したのと同じスケールを使用します。スケールはその名前を入力することで追加でき、配置する位置を指定するだけなので簡単です。 次のコードを、つい先ほどのコード例の最上部に追加します。
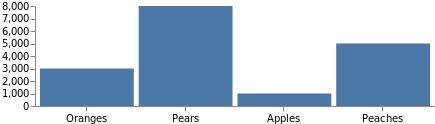
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
これらの軸を完全に表示できるようにするために、グラフ全体のサイズが自動的に拡大されています。 このグラフを強制的に元のサイズのままにするには、コードの上部に"autosize": "fit"を追加します。
データの変換と条件文
データを描画に使用できるようにするためには、多くの場合データに対する追加操作が必要になります。Vegaには、それらに役立つ多数の変換機能があります。そのうち、最もよく使用される式変換を使用して、ランダムなcount値フィールドを各ソースデータに動的に追加してみましょう。また、このグラフでバーの塗りつぶしの色を操作し、値が333より下の場合は赤で、666より下の場合は黄で、666以上の場合は緑で表示されるようにします。この操作は、スケールを使用して行うこともできます。ソースデータのドメインを色のセットまたはカラースキームにマッピングします。
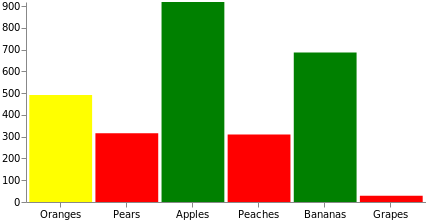
{
"$schema":"https://vega.github.io/schema/vega/v3.json",
"width":400, "height":200,
"data": [ {
"name": "vals",
"values": [
{"category":"Oranges"},
{"category":"Pears"},
{"category":"Apples"},
{"category":"Peaches"},
{"category":"Bananas"},
{"category":"Grapes"}
],
"transform": [
{"type": "formula", "as": "count", "expr": "random()*1000"}
]
} ],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "count"},
"range": "height"
},
{
"name": "xscale",
"type": "band",
"domain": {"data": "vals", "field": "category"},
"range": "width",
"padding":0.05
}
],
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
"marks": [ {
"type": "rect",
"from": { "data": "vals" },
"encode": {
"update": {
"x": {"scale": "xscale", "field": "category"},
"width": {"scale": "xscale", "band":1},
"y": {"scale": "yscale", "field": "count"},
"y2": {"scale": "yscale", "value":0},
"fill": [
{"test": "datum.count < 333", "value": "red"},
{"test": "datum.count < 666", "value": "yellow"},
{"value": "green"}
]
}
}
} ]
}
ElasticsearchおよびKibanaでのダイナミックデータ
ここまでで基本を理解できたと思いますので、ランダムに生成された Elasticsearchデータを使用して、時間ベースの折れ線グラフを作成してみましょう。 そのグラフは、Kibanaで新しいVegaグラフを作成したときに最初に見るものと類似していますが、異なる点は、Vega-Lite(簡素化された、Vegaの軽量バージョン)のKibanaのデフォルトではなく、Vega言語を使用することです。
ここでの例では、urlを使用して実際にクエリするのではなく、valuesを使用してデータをハードコードします。こうすることで、KibanaでのElasticsearchクエリをサポートしていないVega Editorで引き続きテストできます。 下記に示すように、valuesをurlセクションに置き換えることで、グラフはKibana内で完全に動的になります。
ここでのクエリでは、ダッシュボードユーザーが選択する時間範囲とコンテキストフィルターを基に、各期間のドキュメント数をカウントします。 詳細については、 KibanaでElasticsearchからクエリを実行する方法をご覧ください。
"url": {
"%context%": true,
"%timefield%": "@timestamp",
"index": "_all",
"body": {
"aggs": {
"time_buckets": {
"date_histogram": {
"field": "@timestamp",
"interval": {"%autointerval%": true},
"extended_bounds": {
"min": {"%timefilter%": "min"},
"max": {"%timefilter%": "max"}
},
"min_doc_count":0
}
}
},
"size":0
}
これを実行すると、結果は次のようになります(簡潔にするために無関係なフィールドは削除しています)。
"aggregations": {
"time_buckets": {
"buckets": [
{"key":1528061400000, "doc_count":1},
{"key":1528063200000, "doc_count":45},
{"key":1528065000000, "doc_count":49},
{"key":1528066800000, "doc_count":17},
...
見てのとおり、必要な実際のデータはaggregations.time_buckets.bucketsアレイ内にあります。データ定義内に「"format": {"property": "aggregations.time_buckets.buckets"}」と入力することで、そのアレイのみを参照するようVegaに指示することができます。
ここでのx軸はカテゴリーを基にしておらず、時間を基にしています(keyフィールドは、Vegaが直接使用できるUNIX時刻です)。したがって、xscaleタイプを時間に変更し、keyとdoc_countを使用するようにすべてのフィールドを調整します。また、マークタイプをlineに変更し、xとyパラメーターチャネルのみを含めるようにする必要があります。 すると、折れ線グラフができます。また、format、labelAngle、およびtickCount[パラメーター]https://vega.github.io/vega/docs/axes/)を使用して、x軸のラベルをカスタマイズすることも可能です。
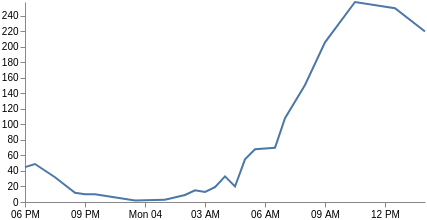
{
"$schema": "https://vega.github.io/schema/vega/v3.json",
"width":400, "height":200,
"data": [
{
"name": "vals",
"values": {
"aggregations": {
"time_buckets": {
"buckets": [
{"key":1528063200000, "doc_count":45},
{"key":1528065000000, "doc_count":49},
{"key":1528068600000, "doc_count":32},
{"key":1528072200000, "doc_count":12},
{"key":1528074000000, "doc_count":10},
{"key":1528075800000, "doc_count":10},
{"key":1528083000000, "doc_count":2},
{"key":1528088400000, "doc_count":3},
{"key":1528092000000, "doc_count":9},
{"key":1528093800000, "doc_count":15},
{"key":1528095600000, "doc_count":13},
{"key":1528097400000, "doc_count":19},
{"key":1528099200000, "doc_count":33},
{"key":1528101000000, "doc_count":20},
{"key":1528102800000, "doc_count":55},
{"key":1528104600000, "doc_count":68},
{"key":1528108200000, "doc_count":70},
{"key":1528110000000, "doc_count":108},
{"key":1528113600000, "doc_count":151},
{"key":1528117200000, "doc_count":206},
{"key":1528122600000, "doc_count":258},
{"key":1528129800000, "doc_count":250},
{"key":1528135200000, "doc_count":220}
]
}
}
},
"format": {"property": "aggregations.time_buckets.buckets"}
}
],
"scales": [
{
"name": "yscale",
"type": "linear",
"zero": true,
"domain": {"data": "vals", "field": "doc_count"},
"range": "height"
},
{
"name": "xscale",
"type": "time",
"domain": {"data": "vals", "field": "key"},
"range": "width"
}
],
"axes": [
{"scale": "yscale", "orient": "left"},
{"scale": "xscale", "orient": "bottom"}
],
"marks": [
{
"type": "line",
"from": {"data": "vals"},
"encode": {
"update": {
"x": {"scale": "xscale", "field": "key"},
"y": {"scale": "yscale", "field": "doc_count"}
}
}
}
]
}
Vegaに関する今後のブログにご注目ください。 Elasticsearchの結果の扱い方、特に集約とネストデータについてのブログを投稿する予定です。