リーダーに従う:Elasticsearchでのクラスター横断レプリケーションの概要
多くの人が必要とするもの
Elasticsearchクラスター間でネイティブに複製できる機能は、最もリクエストが多かった機能であり、ユーザーの皆さんが長く待ち望んでいたものです。必要な基盤を築き、基本となる新しいテクノロジーをLuceneに構築し、初期の設計を繰り返すとともにさらに洗練するために、数年に渡ってエンジニアリングに取り組んだ結果、 Elasticsearch 6.7.0ではクラスター横断レプリケーション(CCR)がネイティブで利用できるようになり、本番環境で使えるようになりました。連載の第1回目となるこの記事では、実装内容の簡単な紹介とCCRの技術的背景について説明します。CCRの具体的なユースケースの詳細については、今後の記事で取り上げる予定です。
Elasticsearchのクラスター横断レプリケーションでは、ElasticsearchおよびElastic Stack内でミッションクリティカルなさまざまなユースケースが可能になります。
- 災害復旧(DR)/ 高可用性(HA):ミッションクリティカルなアプリケーションには、データセンターや地域の停電に対する耐性が必須です。この要件についてはすでに、Elasticsearchでは追加のテクノロジーを使用することで解決していますが、このやり方では複雑さが増し、管理オーバーヘッドが増大します。そこで今回、Elasticsearchで実現したのは、追加のテクノロジーを使わずに、CCRを使用することで複数のデータセンター全体のDR/HA要件をネイティブで満たすことです。
- データのローカル性:Elasticsearchのデータを複製し、ユーザーまたはアプリケーションサーバーに近い場所に配置することで、コストのかかるレイテンシを削減できます。たとえば、データとアプリケーションサーバーの間の距離を最小化するために、製品カタログまたは参照データセットを世界中の20以上のデータセンターに複製する場合が該当します。または、株を扱う企業で、ロンドンとニューヨークにオフィスを構えるのも、この例の1つです。ロンドンオフィスでのすべての取引がローカルに書き込まれ、ニューヨークオフィスに複製されます。そしてニューヨークオフィスでのすべての取引がローカルに書き込まれ、ロンドンオフィスに複製されます。こうすることで、両方のオフィスがすべての取引の全体像を把握できます。
- レポートの一元化:多数の小さいクラスターから、一元化されたレポートクラスターにデータを複製します。これは、大規模なネットワーク全体でクエリを効率的に実行できない可能性がある場合に便利です。たとえば、世界に展開している大手銀行の場合は、世界に100のElasticsearchクラスター(各支店に1つ)を持っている可能性があります。CCRを使用することで、世界中の100の支店すべてからイベントを複製することができ、それらのイベントをローカルで分析および集計できます。
Elasticsearch 6.7.0よりも前のバージョンでは、このようなユースケースにはサードパーティのテクノロジーによって部分的に対処することが可能でしたが、面倒な作業が必要であり、大幅な管理オーバーヘッドが生じるとともに多くの欠点がありました。クラスター横断レプリケーションはElasticsearchにネイティブで統合されているため、ユーザーは複雑なソリューションの管理に伴う負荷や欠点に悩まされることがなくなります。さらに、既存のソリューション以上の利点(包括的なエラー処理など)を活用できるようになり、Elasticsearch内でAPIを、またKibana内でUIを使用して、CCRを管理および監視できます。
今後の記事ではそれらの各ユースケースについて詳細に説明します。ぜひご注目ください。
クラスター横断レプリケーションの使用の開始
ダウンロードページにアクセスして、ElasticsearchおよびKibanaの最新リリースを入手し、 開始ガイドを参照して使用を開始しましょう。
CCRはプラチナレベルの機能であり、30日間のトライアルライセンスで利用可能です。このライセンスはトライアルAPIを使用して、またはKibanaから直接、有効化することができます。
クラスター横断レプリケーションの技術的概要
CCRはアクティブ/パッシブのインデックスモデルを中心に設計されています。Elasticsearchクラスターのインデックスは、別のElasticsearchクラスターのインデックスからの変更を複製するように設定できます。変更の複製先となるインデックスは「フォロワーインデックス」と呼ばれ、複製元となるインデックスは「リーダーインデックス」と呼ばれます。フォロワーインデックスはパッシブです。つまり、読み取りリクエストと検索には対応しますが、直接の書き込みはできません。直接の書き込みが可能なのはリーダーインデックスのみです。CCRはインデックスレベルで管理されるため、クラスターにはリーダーインデックスとフォロワーインデックスの両方を含めることができます。このようにして、一部のインデックスを一方向(例:米国のクラスターから欧州のクラスター)に複製し、その他のインデックスを逆方向(欧州のクラスターから米国のクラスター)に複製することで、一部のアクティブ/アクティブのユースケースを解決できます。
複製はシャードレベルで実行され、フォロワーインデックスの各シャードは、対応するリーダーインデックスの各シャードから変更を取得します。つまり、フォロワーインデックスのシャード数は、対応するリーダーインデックスのシャード数と同数ということになります。すべてのオペレーションがフォロワーによって複製されるため、ドキュメントの作成、更新、変更が複製されることになります。複製はほぼリアルタイムに実行されるため、シャードのグローバルチェックポイントの時点からさらにオペレーションが実行されるとすぐに、フォロワーシャードによる複製対象となります。オペレーションはフォロワーシャードによって一括で効率的に取得およびインデックスされるため、変更を取得するための複数のリクエストを同時に処理することが可能です。このような読み取りリクエストは、プライマリシャードまたはそのレプリカによって処理され、シャードからの読み取りを除いては、リーダーシャードに追加の負荷はかかりません。このような設計により、CCRは本番環境の負荷に合わせて拡張できるため、Elasticsearchで高く評価されている(そして期待されている)高スループットのインデックス作成スピードが継続的に維持されます。
CCRは、新たに作成されたインデックスと既存のインデックスの両方をサポートします。フォロワーを最初に設定する際、リーダーインデックスの基盤となるファイルをコピーすることで、フォロワーはリーダーインデックスからブートストラップされます。これは、レプリカがプライマリから復元されるのと同様のプロセスです。この復元プロセスが完了すると、CCRは追加のオペレーションをリーダーから複製します。マッピングおよび設定の変更は、必要に応じてリーダーインデックスから自動的に複製されます。
CCRがエラー状況(ネットワーク障害など)に陥ることがあります。CCRはそのようなエラーを、回復可能なエラーおよび致命的なエラーに分類します。回復可能なエラーが発生した場合、CCRは、障害の原因となった状況が解決されるとすぐに複製を再開できるようにリトライを繰り返します。
複製のステータスは専用のAPIで監視できます。このAPIを使用することで、フォロワーがリーダーのどのくらい近くまで追跡できているかを監視し、CCRのパフォーマンスに関する詳細な統計を確認できるとともに、注意が必要なエラーを追跡できます。
私たちは、CCRをKibana内の監視および管理アプリケーションと統合しました。監視UIにより、CCRの進捗およびエラーレポートに関するインサイトを得ることができます。

Kibana内のElasticsearch CCR監視UI
管理UIにより、リモートクラスターとフォロワーインデックスの構成が可能になり、自動フォロワーパターンの管理によってインデックスの自動複製が可能になります。
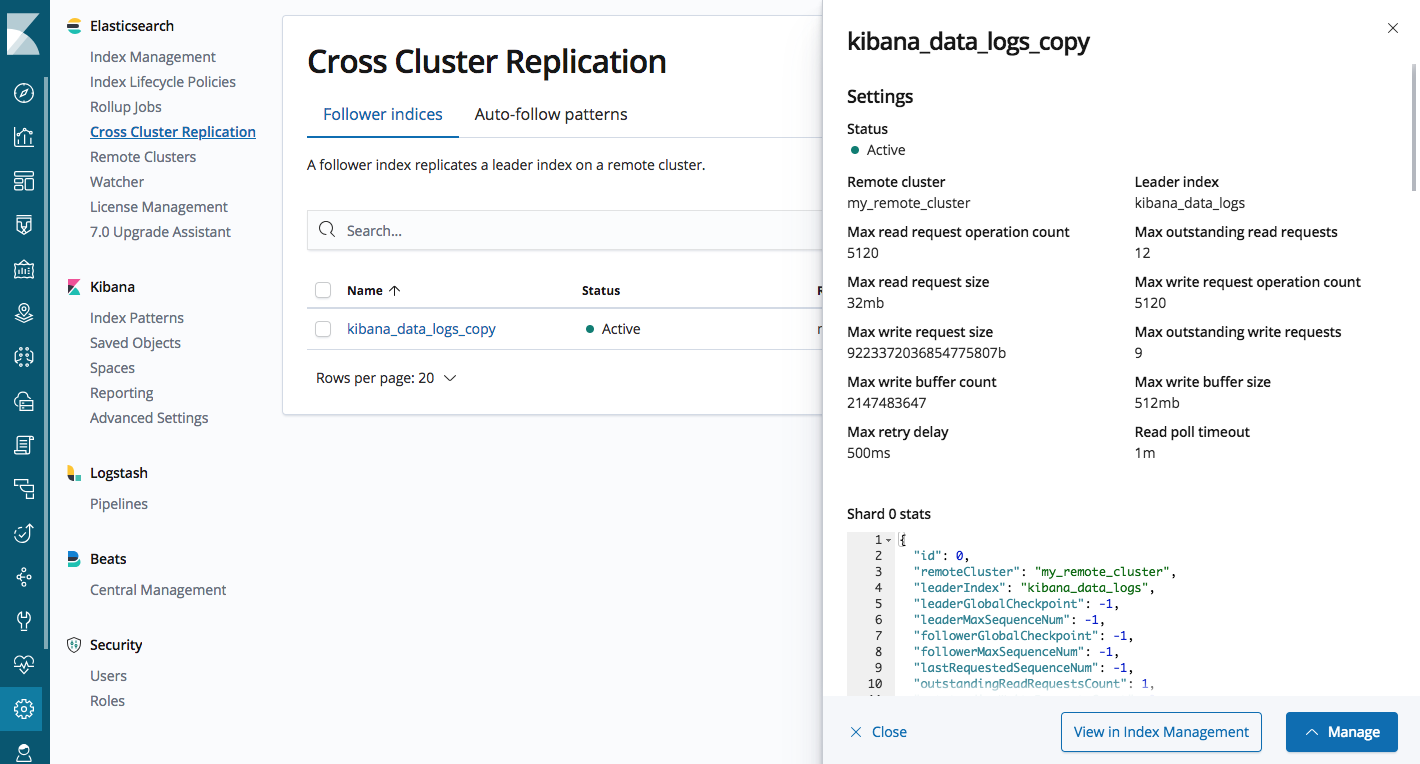
Kibana内のElasticsearch CCR管理UI
船長さんの命令:現在のインデックスに従いましょう
ユーザーの多くは、定期的に新しいインデックスを作成するというワークロードを抱えています。たとえば、Filebeatからプッシュされるログファイル、またはインデックスライフサイクル管理によるインデックスの自動ロールオーバーを基に、インデックスを日々作成しています。それらのインデックスをソースクラスターから複製するために手動でフォロワーインデックスを作成するのではなく、CCRに直接、自動フォロー機能を構築しました。この機能を使用してインデックスパターンを設定し、ソースクラスターから自動的に複製されるようにすることができます。CCRがソースクラスターを監視してそれらのパターンに一致するインデックスを検出します。そして、一致するリーダーインデックスを複製するフォロワーインデックスを作成します。
また、CCRとILMを統合しました。これにより、時間ベースのインデックスをCCRで複製し、ILMによってソースクラスターとターゲットクラスターの両方で管理できます。たとえば、ILMはCCRがリーダーインデックスを複製するタイミングを把握しているため、CCRが複製を完了するまで、インデックスの縮小や削除などの破壊的なオペレーションを慎重に管理することが可能です。
履歴を把握できない場合
CCRが変更を複製するためには、リーダーインデックスのシャードのオペレーション履歴が必要です。また、複製対象のオペレーションを把握するためのポインターが各シャードに必要です。オペレーション履歴はシーケンスIDによって管理されており、ポインターは グローバルチェックポイントと呼ばれているものです。ここで注意が必要なのは、複雑な要素が関係してくる場合があることです。ドキュメントが更新または削除される場合、Luceneでは、ドキュメントが削除されたことを記録するためにビットがマークされます。その後のマージオペレーションによってマージされるまで、その削除対象のドキュメントはディスク上に維持されます。削除がマージされる前に、CCRがこのオペレーションを複製した場合は問題ありません。しかし、マージは固有のライフサイクルによって実行されるため、CCRがオペレーションの複製を実行する前に、削除ドキュメントのマージが実行される可能性があります。削除ドキュメントがマージされるタイミングを制御できる機能がないと、CCRがオペレーションを複製する機会を逃してしまう可能性があり、完全なオペレーション履歴をフォロワーインデックスに複製できない場合があります。CCRの初期設計時には、それらのオペレーション履歴のソースとしてElasticsearch Translogを使用しようと計画していました。これによって問題を回避できると考えていたのです。しかし、TranslogはCCRの効果的な実行に必要なアクセスパターンを検出するために設計されたものではないということに、すぐに気づきました。そこで、必要なパフォーマンスを達成するために、Translog自体に、およびTranslogと併用できるように、追加のデータ構造を構築することを考えました。しかし、このアプローチには制約があります。その制約の1つは、システムの最もクリティカルなコンポーネントの1つの複雑さが増すことです。これは単純に、私たちのエンジアリング哲学に反します。さらに、私たちの今後の変更に縛りをかけるものになってしまいます。つまり、オペレーション履歴の上に構築することで、オペレーション履歴に対して実行可能な検索のタイプを制限すること、またはTranslogの上にLuceneのすべてを再実装すること、これらのどちらかが強制されることになります。このインサイトを基に、私たちはLuceneの機能としてネイティブで組み込む必要があることに思い至りました。そうすることで、削除ドキュメントのマージのタイミングを制御でき、オペレーション履歴をLuceneに効果的にプッシュできます。私たちはこの技術を「Soft Deletes(ソフトな削除)」と呼んでいます。Luceneへのこの投資は、この先何年にも渡って効果をもたらすことになります。それを基にCCRを構築しただけでなく、現在、Soft Deletesを基にして複製モデルを構築するように取り組んでいます。また、今後の変更API もこれらをベースとすることになります。このSoft Deletesはリーダーインデックス上で有効化される必要があります。
あとは、リーダー上でSoft Deleteが実行されたドキュメントのマージのタイミングに対して、フォロワーが影響を与えることができるようにすることです。そのために、シャード履歴維持リースを導入しました。これにより、フォロワーは現在履歴上のどこにいるかについて、リーダー上のオペレーション履歴にマークすることができます。これにより、そのマーカーの下にあるオペレーションについてはマージしても問題ないこと、およびマーカーの上にあるオペレーションについてはフォロワーに複製する機会が与えられるまで維持する必要があることを、リーダーは認識できます。このマーカーにより、リーダーはフォロワーが一時的にオフラインになっても、まだ複製されていないオペレーションを維持することができます。この履歴を維持するにはリーダーに追加のストレージが必要になるため、これらのマーカーは限られた期間のみ有効となります。 その期間が終了するとマーカーは期限切れとなり、リーダーシャードは履歴をマージできるようになります。この期間の長さは、フォロワーがオフラインになったときに備えてその維持のためにどの程度のストレージを割いても良いかに基づいて、またフォロワーのオフライン時間(リーダーから再度ブートストラップする必要が生じるまでの時間)の許容範囲に基づいて調整できます。
まとめ
皆様にはぜひCCRを試用していただき、その機能についてフィードバックをいただければと思います。皆様の役に立つことを願いながらこの機能を構築いたしました。このシリーズの今後の記事もぜひご覧ください。CCRの機能およびCCRの使用を想定しているユースケースの詳細について、分かりやすく説明する予定です。CCRについてご質問がある場合は、ディスカッションフォーラムをご活用ください。
この記事で使用されているサムネイル画像の著作権はNASAに帰属しており、CC BY-NC 2.0ライセンスによってその使用が許可されています。この基準で使用されているバナー画像の著作権はRawpixel Ltdに帰属しており、 CC BY 2.0ライセンスによってその使用が許可されています。この記事では、オリジナルのものからトリミングされています。