Elasticsearchの機械学習でオンデマンド予測を実行する
オンデマンド予測は、X-Pack 6.1に登場した最新の機械学習機能です。これまでElasticの機械学習は「履歴データを使用して、"現在"の正常な値の範囲を予測し、実際のデータと比較しながら異常をリアルタイムに検出する」という設計でした。6.1の機械学習はさらに、データをモデル化して未来の複数の期間を予測することができます。
この機能が"オンデマンド予測"と呼ばれるのは、ユーザーが既存の機械学習ジョブを使い、機械学習に搭載された予測モデルを用いて、予測日時までのモデルの成長を反映した予測を行うことができるためです。予測結果はElasticsearchのインデックスに書きこまれ、ユーザーは予測モデルと実際の結果を比較することができます。
機械学習と予測を用いたキャパシティープランニング
過去のパフォーマンスが未来の結果を示すわけではない、という指摘は少なくありません。しかし、キャパシティープランニングの結果を予測する上ではやはり、過去の指標を使うことが最も優れた方法と言えます。
特定のリソースがキャパシティーの上限に達するタイミングは、どのようにして判断できるでしょうか?たとえばサーバーのディスク容量を監視している場合、容量がいつ不足するかあらかじめ予測しておく必要があるかもしれません。こうした時、Elasticの機械学習が提供する予測モデルを使用すれば未来の状況を予測し、システムにストレージの追加が必要となる時期を特定することができます。
キャパシティープランニングを活用する別のシナリオとして、未来の特定の時点の量的メトリックを予測する、というものもあります。たとえばある事業において、月曜の午後にお客様からかかってくる電話の本数を予測する、といったことです。過去のデータを分析し、複雑な機械学習モデルを使って予測を行えば、配置するスタッフの人数やリソースの判断に必要な情報を得ることができます。
予測機能を使いはじめる
予測は、既存の機械学習ジョブにある[Single Metric Viewer]から実行できます。バージョンが6.1以降にアップグレードされている場合、画面右上に予測ジョブに使用する新しいオプションボタンが表示されます。
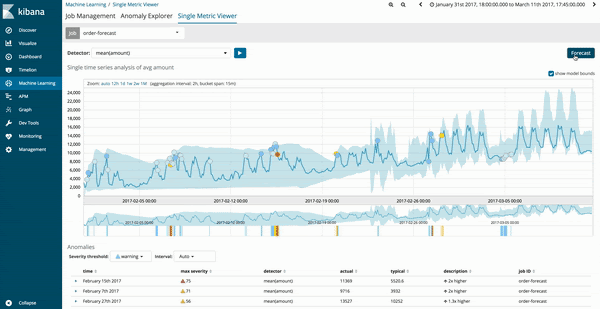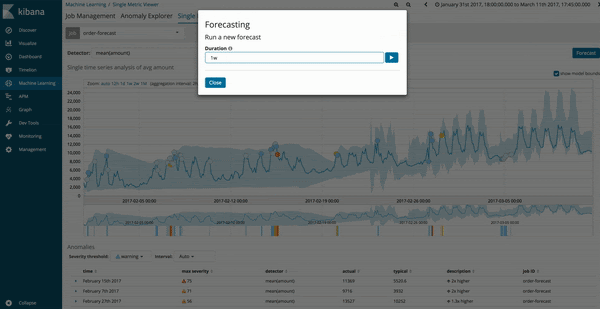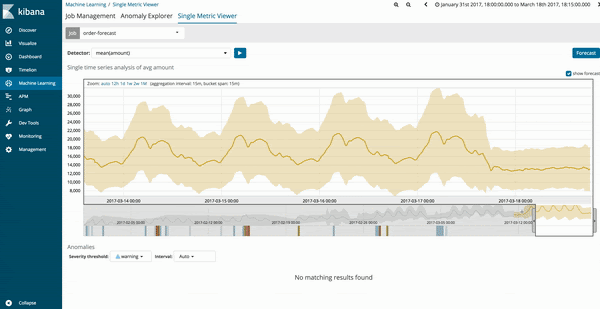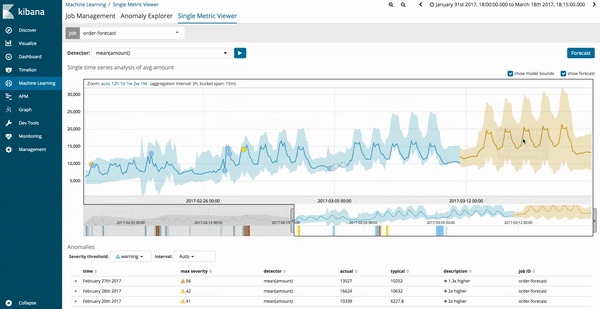
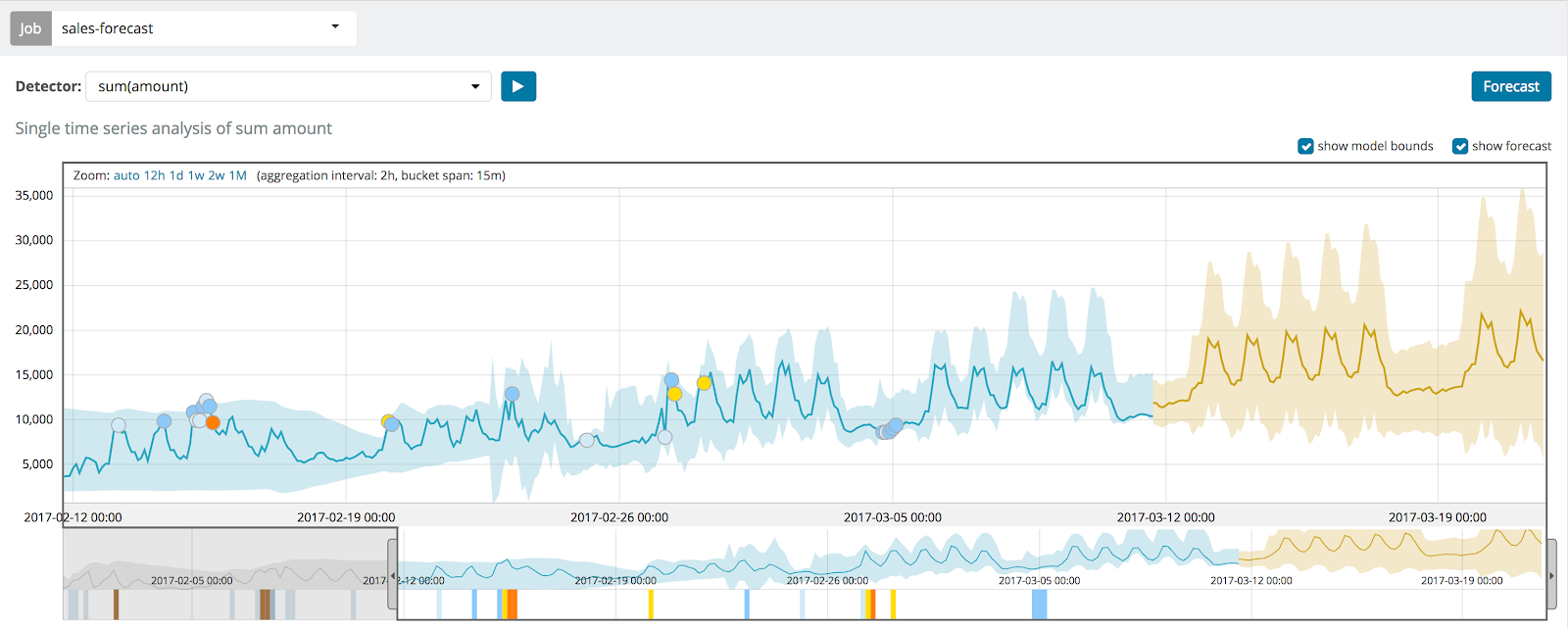
機械学習ジョブの予測結果は、傾向のグラフが暗めの黄色で表示され、信頼度モデルが明るい薄黄色の帯域で表示されます。明るい黄色の帯域の幅が狭ければ、予測の信頼性が高いことを意味します。明るい黄色の帯域の幅が広い部分では、予測の信頼性が低いことを意味します。
予測を立てる上で考慮すること
結果を正しく理解するために、予測モデルを構築する際にいくつか考慮すべき要素があります。予測結果は、期待値から大きく外れたように見える結果となることもあり、またすべてのデータセットで動作するとは限りません。
機械学習ジョブで予測を行う場合は、はじめに十分な履歴データを収集してから開始することをお勧めしています。最も良い結果を出すには、一般的に周期的なデータで約3週間分、あるいは約3周期分が必要です。学習段階でモデルが確立される前に予測を開始してしまうと、多くの場合は不確かな結果が表示されます。
予測信頼度のレベルが合理的な範囲に収まらない場合、予測モデルは早い段階で停止します。 予測ジョブが停止すると、次のようなメッセージを表示して、信頼度レベルが許容範囲にないことを伝えます。

モデルプロット機能を有効化しておくと、予測結果はさらにわかりやすくなります。この機能はオプションで、シングルメトリックのジョブではデフォルトで有効化されています。マルチメトリックのジョブでモデルプロットのオプションを有効化するには、機械学習ジョブコンフィグ内の‘model-plot-config’オプションを設定します。
[Single Metric Viewer]以外の場所でも特定の予測結果を追跡できるよう、各予測にはforecast_IDとよばれる一意のIDが付与されています。したがって、すべての予測を個別にクエリすることができます。同じメトリックに対して複数の予測を実行することも可能ですが、UIではシングルメトリックについて直近の5つの予測しか表示されません。表示されない場合も予測データ自体は利用でき、対応するインデックススペースに保存されています。UIから実行した場合、予測結果は14日後に自動的に削除されますが、APIを使用してデータの有効期間を指定することもできます。詳しくは、こちらから予測に関するドキュメントをご覧ください。
機械学習は現在プラチナサブスクリプションで提供されていますが、X-Packの無料トライアルでもお試しいただくことができます。