ペアレント-チャイルドプロセス関係から、異常なパターンを発見
アンチウイルスソフトや機械学習ベースのマルウェア検知がすぐれた効果を発揮するようになったことで、攻撃者は最新のセキュリティソフトウェアを回避すべく、“Living Off the Land(環境寄生)”戦術に移行しています。このテクニックは、OSにプリインストールされたシステムツールや、IT管理者により導入された、タスクを自動化する、スクリプトを定期的に実行する、リモートシステムでコードを実行するといったツールを通して行われます。攻撃者はpowershell.exeやwmic.exe、schtasks.exeなどの信頼あるOSツールを使用するため、特定が難しくなる可能性もあります。このようなバイナリはそれ自体に問題があるわけではなく、多くの環境で一般的に使用されています。したがって、定期的に実行されるバイナリにノイズを注入するだけで、攻撃者はほとんどの防御策をやすやすと潜り抜けることができます。このような侵入のパターンを後から検知するには、明確な手掛かりなしに、何百万という数のイベントを厳密に調べなくてはなりません。
この課題に対して、複数のセキュリティ研究者が、疑わしいペアレント-チャイルドプロセスチェーンをターゲットとする検知器の開発に取り組んでいます。研究者はMITRE ATT&CK™のシナリオを、一定のコマンドライン引数を伴ったチャイルドプロセスをローンチする特定のペアレントについて警告を発する検知ロジックの記述に活用できます。わかりやすい例が、Base64エンコードの引数でpowershell.exeを生成するMS Officeへの警告です。しかしこの方法には過剰検知を調整するための領域専門家と明確なフィードバックループが必要であり、プロセスとしては非常に時間がかかります。
オープンソースの攻撃シミュレーションとして、セキュリティ担当者が検知器のパフォーマンス評価に利用できる“Red vs Blue”フレームワークは複数存在します。しかし、どれほど効果的な場合でも、検知器のロジックは特定の一つの攻撃しか解決できません。新たに出現しつつある攻撃について、検知器による一般化が困難なことを逆手に取り、機械学習を活用する独自の機会と捉えてみましょう。
グラフで考える
悪意のあるペアレント-チャイルドプロセスの検知について検討を開始したとき、筆者がまず考えたのは、これをグラフの問題に転換するというアイデアでした。あるホストにおけるロセスの実行はグラフとして表現できるからです。グラフ中のノードはプロセスID(PID)によって開始される個別のプロセスで、各エッジはノードに接続するprocess_creationイベントとなります。いずれのエッジにも、タイムスタンプやコマンドライン引数、ユーザーなど、イベントに由来する重要なメタデータが豊富に存在しているはずです。
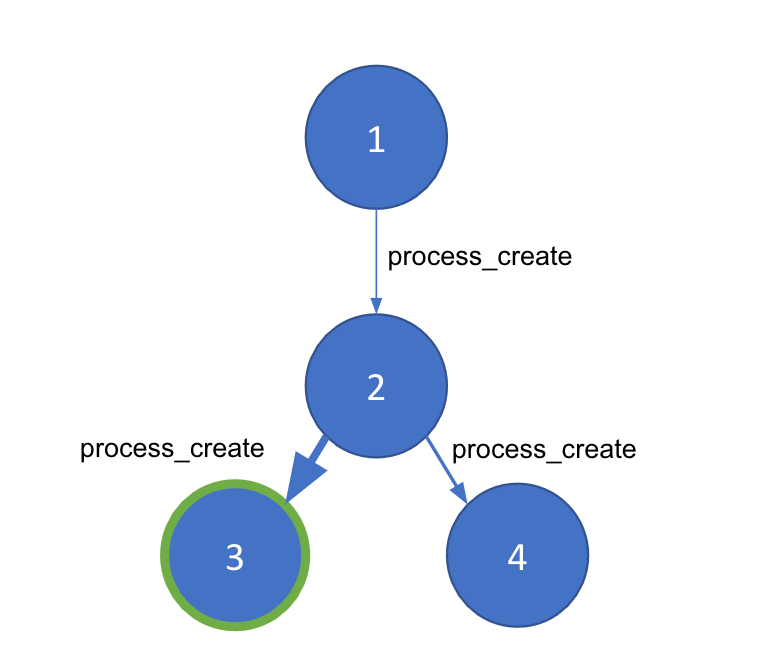
ホストマシンが処理したイベントをグラフに表現すると、このようになります。しかしLiving Off the Land(環境寄生)攻撃は、常時実行するプロセスと同じシステムレベルで引き起こされる可能性があります。つまり、あるグラフの中で、良いプロセスと悪いプロセスを分離する方法が必要です。コミュニティ検知という手法は、大規模なグラフをノード間のエッジの密度に基づいて小規模な“コミュニティ”に分割します。この手法を使うには、コミュニティ検知が適切に動作し、グラフの異常な部分を確実に検知するため、ノード間に重みを生成する方法が必要になります。私たちはここで、機械学習に着目しました。
機械学習
“エッジ重み付けモデル”を生成するにあたっては、教師あり学習を使用します。機械学習のアプローチの1つである教師あり学習には、モデルにフィードする分類済みデータが必要です。幸い、私たちは上述のオープンソースのRed vs Blueフレームワークを教育用データの生成に活用することができました。以下に、教育用資料として使用したオープンソースのRed vs Blueフレームワークの一部をご紹介します。
Redチームフレームワーク
- Atomic Red Team(Red Canary)
- Red Team Automation(Endgame/Elastic)
- Caldera Adversary Emulation(MITRE)
- Metta(Uber)
Blueチームフレームワーク
- Atomic Blue(Endgame/Elastic)
- Cyber Analytics Repository(MITRE)
- MSFT ATP Queries(Microsoft)
データ投入と正規化

イベントデータの投入が完了したら、次にデータを数値表現に変換する必要があります(図2)。数値で表現することで、モデルが攻撃範囲にある広範なペアレント-チャイルド関係を学習することが可能になり、単にシグネチャーを覚える作業にならずに済みます。
はじめに、プロセス名とコマンドライン引数について特徴エンジニアリング(図3)を実施します。TF-IDFベクトル化により、データセット全体の1つのイベントに対する、単語ごとの統計的な重要性を捉えます。タイムスタンプを整数に転換することにより、ペアレントプロセスの開始時間と、チャイルドプロセスがローンチされた時間の間のデルタ値を測定することができます。その他の特徴は、もともとバイナリ(1か0、YesかNoなど)です。典型的な特徴のタイプとして、次のような例があります。
- プロセスに署名はあるか?
- 署名者を信頼できるか?
- プロセスは昇格しているか?

数値表現に変換したら、そのデータセットを使って教師あり学習モデルを教育します(図4)。このモデルは、プロセス作成イベントごとに、0(正常)から1(異常)の範囲で“異常スコア”を提供します。つまり、この異常スコアがエッジの重み付けに使えるというわけです。
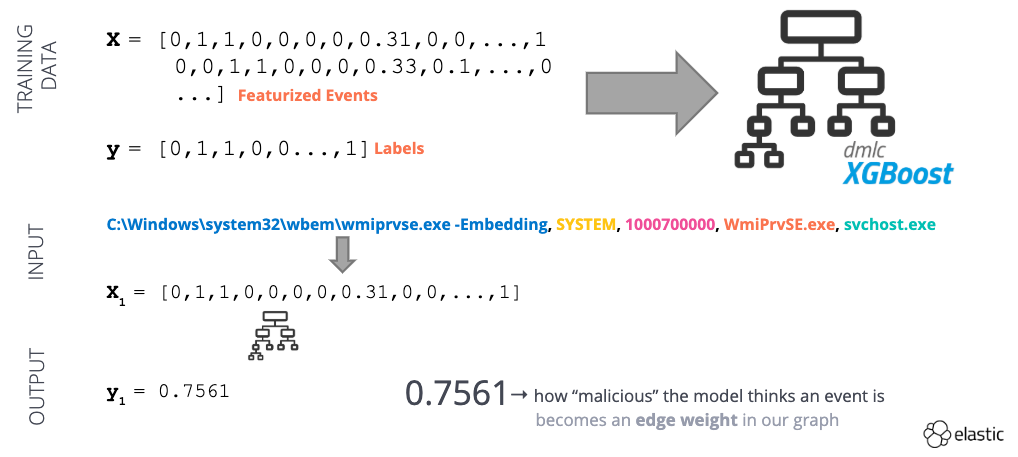
図4 - 教師あり機械学習のワークフローの例
出現率サービス


図5 - 出現率エンジンに使用した条件付き確率
重み付けグラフが完成しました。機械学習モデルに感謝です。これで任務は完了でしょうか?今回教育したモデルは、善悪について私たちが持つ包括的な理解に基づき、ペアレント-チャイルドチェーンごとに、良し悪しの適切な判断を下すことができます。しかし実際には、すべての顧客環境は異なっています。私たちがこれまで観測したことのないプロセスや、PowerShellを使うシステム管理者など、さまざまな状況が存在するはずです。
要するに、もしこのモデルを単独で使用すると、誤検知が大量発生し、アナリストの調査を必要とするデータ量も増える可能性が高いのです。この潜在的な問題を回避するため、私たちは特定のペアレント-チャイルドプロセスが、その環境内でどの程度“よくある”ものかを示す出現率サービスを開発しました。環境のローカルな差異を考慮することで、一層確信をもって疑わしいイベントを昇格、あるいは抑制でき、その結果、真に異常なプロセスチェーンをあぶり出すことができます。
出現率サービス(図5)は、条件付き確率で算出される2つの統計に依拠します。この統計は次のように記述できます:“このペアレントで、このチャイルドは、他のチャイルドプロセスよりX%多く見られる”、かつ“このプロセスで、このコマンドラインは、このプロセスに関連する他のコマンドラインよりX%多く見られる”。 この出現率サービスを構築すれば、中核となる検知ロジックの“find_bad_communities”の完成度を高めることができます。
“悪い”コミュニティを見つける

図6 - 異常なコミュニティの発見に使ったPythonコード
上のスクリーンショット(図6)は、悪いコミュニティを生成するために使われたPythonコードを示しています。“find_bad_communities”のロジックは、非常にストレートです。
- ホストマシンに対し、各process_createイベントを分類してノードペア(ペアレントノードとチャイルドノードのペア)と、関連性の重み(機械学習モデルが出力した値)を生成する
- 有向グラフを構築する
- コミュニティ検知を実行して、グラフ内にコミュニティのリストを生成する
- 各コミュニティ内で、ペアレント-チャイルドの出現率(各関係)を算出する最終的なanomalous_scoreに、ペアレント-チャイルドイベントの一般性を考慮する
- anomalous_scoreが閾値と同一、または閾値を超える場合、そのコミュニティ全体をアナリストにレビューさせる
- 各コミュニティの分析完了後、anomalous_scoreを降順でソートした“悪い”コミュニティリストを返す
結果
今回、最終モデルの教育には、現実のデータと、シミュレーションによる無害なデータおよび、悪意あるデータの組み合わせを用いました。無害なデータは、社内ネットワークから収集した3日分のWindowsプロセスイベントデータで構成されます。小規模な組織を再現できるよう、データのソースとして、ユーザーワークステーションとサーバーを組み合わせました。悪意あるデータの生成には、Endgame RTAフレームワーク経由で、利用できるすべてのATT&CKテクニックを発動させたほか、FIN7やEmotetなど、高度な敵のマクロおよびバイナリベースのマルウェアをローンチしています。
主たる実験には、ロベルト・ロドリゲス氏のMordor projectが提供するMITRE ATT&CK Evaluationのイベントデータを使用しました。このATT&CK Evaluationは、PSEmpireやCobaltStrikeといったFOSS/COTSツールを使用し、APT3アクティビティのエミュレートを試みます。これらのツールで、環境寄生手法は実行、持続、または防御回避のタスクを連鎖的に実行することができます。
このフレームワークは、プロセス作成イベントのみを使用し、複数のテクニックからなるいくつかの攻撃チェーンを特定することができました。開示(図7)とラテラルムーブメント(図8)が見つかり、アナリストレビューが必要としてハイライトされています。

図7 - “開示”テクニックを実行するプロセスチェーン

図7 - ラテラルムーブメントを実行するプロセスチェーン
データ量削減
今回のアプローチの副産物として、異常なプロセスチェーンを発見するロジックにとどまらず、誤検知の抑制における出現率エンジンの有用性を示すことができました。出現率エンジンを組み合わせることにより、アナリストによるレビューを必要とするイベントデータの数を劇的に減らすことができました。具体的な数字は、次の通りです。
- APT3シナリオで、1エンドポイント当たり最大10,000のプロセス作成イベントを一致させた(合計5エンドポイント)。
- 1エンドポイント当たり最大6の異常なコミュニティを特定した。
- 各コミュニティはそれぞれ6から8のイベントで構成された。
今後の展開
現在、この研究を概念検証からElasticセキュリティの機能に統合されたソリューションへと進展させる取り組みを行っています。特に出現率エンジンは有望です。ファイルの発生頻度をハイライトする出現率エンジンは珍しくありません。しかし、イベント同士の関係の出現率を算出するエンジンがあれば、企業内で何が“稀”で、何が“よくある”かを調べ、かつ最終的にグローバルな環境において“稀な関係”の指標で補うことにより、セキュリティ担当者に役立つ新しい脅威検知手法となります。
まとめ
私たちは昨年のVirusBulletinとCAMLISで、このグラフベースのフレームワーク(名称はProblemChild)についてプレゼンテーションを行いました。この領域のエキスパートが検知器を記述する必要性の軽減を図るためです。プレゼンテーションでは教師あり機械学習を適用して重み付けグラフを作成することにより、一見してかけ離れたイベントから大規模な攻撃シーケンスを発動するコミュニティを特定する能力を実演して見せることができました。私たちが開発したフレームワークは、条件付きの確率を適用することで異常なコミュニティを自動で順位付けし、また、頻発するペアレント-チャイルドチェーンの順位を抑制します。2つの目的に適用されることで、このフレームワークは検知器を作成、あるいは調整するアナリストの負担軽減に役立ち、また時間とともに誤検知も減少します。