Elasticsearch FreezeインデックスAPIでフローズンインデックスを作成
まずはコンテキストの説明
ハードウェアを最大限活用する場合によく使用されるのが、Hot-Warmアーキテクチャーです。これは特に、ログ、メトリック、APMデータなど、時間ベースのデータが存在する場合に便利です。このアーキテクチャーがセットアップされるのは、、それらのデータが読み取り専用(投入後)であり、インデックスが時間ベース(またはサイズベース)の可能性がある場合がほとんどです。このため、希望する保持期間に基づいて簡単にデータを削除することが可能です。このアーキテクチャーでは、Elasticsearchノードを「Hot」と「Warm」の2つのタイプに分けます。
Hotノードは、最も直近のデータを保持しているため、すべてのインデックス負荷を処理します。通常、最近のデータは最も頻繁にクエリされるため、Hotノードはクラスター内で最も強力なノード(高速ストレージ、高メモリ、高CPU)とします。そのような機能は高価なため、あまり頻繁にクエリされない古いデータを格納することは合理的ではありません。
一方、Warmノードは、よりコスト効果の高い方法による長期保存を目的としたものです。Warmノードに格納されるのはあまり頻繁にクエリされない可能性が高いデータであるため、クラスター内のデータは計画されている保持期間に基づいてHotノードからWarmノードへと移動させることになります(シャードの割り当てのフィルターによって可能になります)。Warmノードに移動してもそのデータはオンラインでのクエリが可能です。
Elastic Stack 6.3以降では、Hot-Warmアーキテクチャーを強化する新機能を構築しており、時間ベースのデータに関する作業が簡素化されています。
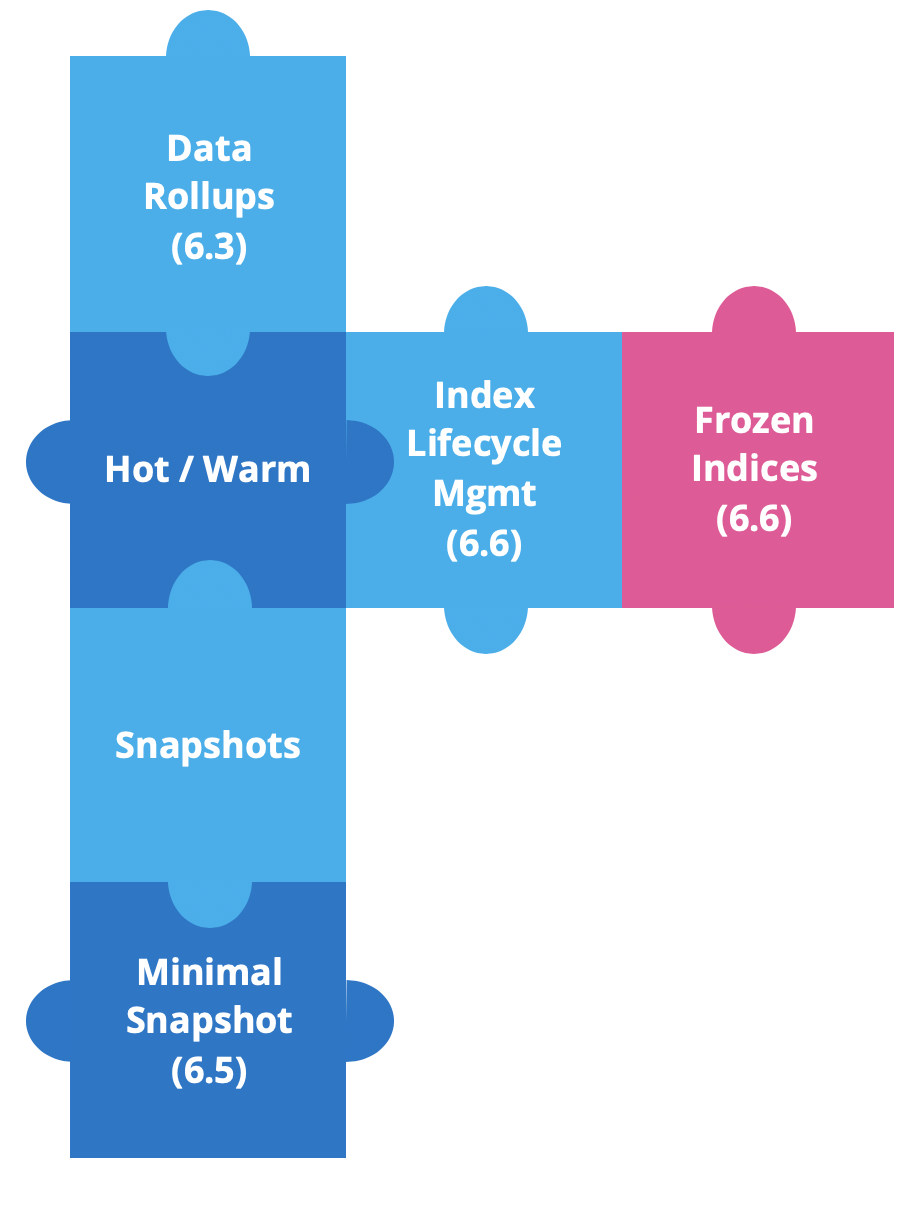
ストレージを節約するためにバージョン6.3で初めて導入されたのが、データのロールアップです。時系列のデータでは、直近のデータに関してきめ細かい詳細情報が必要になります。しかし、それが履歴データに必要になることはほぼありません。通常、履歴データはデータセット全体として見るからです。ここで必要になるのがロールアップです。バージョン6.5からはKibanaでロールアップデータを作成、管理、可視化することができるようになっています。
その後すぐに、ソースのみのスナップショットの機能が追加されました。この最小限のスナップショットにより、スナップショットのストレージの大幅な削減が可能になります。ただし、復元してクエリを実行する場合にはデータの再インデックスが必要になります。これはバージョン6.5以降で利用できます。
バージョン6.6では2つの強力な機能、インデックスライフサイクル管理(ILM)とフローズンインデックスがリリースされました。
ILMは、長期的なインデックス管理を自動化する手段です。HotノードからWarmノードへのインデックスの移動が簡素化され、インデックスが古くなった場合に削除されるように、または自動的にインデックスが1つのセグメントに強制的にマージされるように設定できます。
ここからはフローズンインデックスについて説明します。
インデックスを凍結する理由
「古い」データの最大の難点の1つは、その古さに関係なく、インデックスによってかなりのメモリ領域が消費されることです。それらのデータをColdノードに移動しても、ヒープが使用されます。
解決策となる可能性があるのは、インデックスを閉じることです。インデックスを閉じるとメモリは不要になりますが、検索を実行するためにはそのインデックスを再び開くことが必要になります。インデックスを再び開くと運用コストが発生し、また、そのインデックスが閉じられる前に使用していたヒープが必要になります。
各ノードには、ノードごとに使用できるストレージ容量を制限する、メモリ(ヒープ)対ストレージの比率があります。その比率は、メモリ負荷の高いシナリオに適した1対8(メモリ対データ)から、メモリ要求の低いユースケースに適した1対100に近いものまで、さまざまです。
ここで役立つのがフローズンインデックスです。インデックスを開いたままにしても(つまり検索可能な状態を維持しても)、ヒープを消費しないとしたらどうでしょうか?検索が遅くなる可能性があるという欠点を承知の上で、フローズンインデックスを保持するデータノードにさらにストレージを追加して、1対100の比率を破ることも可能です。
インデックスは、凍結すると読み取り専用となり、その一時的なデータ構造はメモリからドロップします。その代わり、フローズンインデックスにクエリを実行する場合は、そのデータ構造をメモリにロードする必要が生じます。フローズンインデックスの検索は必ずしも遅くなるとは限りません。Luceneはファイルシステムのキャッシュに大きく依存します。このキャッシュに、インデックスのかなりの部分をメモリに保持するのに十分な容量がある場合には、検索の速度はシャード使用時の速度と同程度になります。ただし、フローズンインデックスにはまだ制約があります。現状では、各ノードにおいて一度に1つのフローズンシャードにしか検索を実行できません。この点において、凍結されていないインデックスと比較すると、検索には時間がかかる可能性があります。
フローズンインデックス関連の仕組み
フローズンインデックスの検索には、専用のsearch_throttledスレッドプールが使用されます。シングルスレッド(デフォルト)によって、フローズンインデックスが一度に1つずつメモリにロードされます。同時検索が発生すると、それらはキューに入れられます。これは、ノードのメモリ不足を防止するための追加の保護機能です。
要するに、Hot-Warmアーキテクチャーでは、インデックスをHotノードからWarmノードへと移し、それらをアーカイブする前または削除する前に凍結させることができるようになっているのです。これによってハードウェア要件を軽減することができます。
フローズンインデックスが利用できるようになる以前には、データのスナップショットを取り、そのデータをアーカイブしてインフラコストを削減していましたが、これには相当なオペレーションコストが発生します。再び検索が必要になった場合は、それらのデータを復元する必要がありました。現在では、大きなメモリオーバーヘッドを発生させることなく、履歴データを検索可能な状態で維持することができます。また、フローズンインデックスに再度書き込みを行う必要がある場合は、それを解凍するだけで書き込めます。

Elasticsearchインデックスを凍結させる方法
フローズンインデックスはクラスター内で簡単に扱うことができます。ここからはFreezeインデックスAPIの使い方とフローズンインデックスの検索方法について見ていきましょう。
まず、テスト用のインデックスにサンプルデータを作成することから開始します。
POST /sampledata/_doc
{
"name":"Jane",
"lastname":"Doe"
}
POST /sampledata/_doc
{
"name":"John",
"lastname":"Doe"
}
そして、データが投入されたことを確認します。2つのヒット結果が返されるはずです。
GET /sampledata/_search
ベストプラクティスとして推奨されるのは、インデックスを凍結する前にまずforce_mergeを実行することです。これにより、ディスク上の各シャードには1つのセグメントのみが存在していることを保証できます。また、圧縮効率が高まり、フローズンインデックスに対してアグリゲーションまたはソート検索のリクエストを実行するときに必要なデータ構造が簡素化されます。複数のセグメントがあるフローズンインデックスに検索を実行すると、最大で数百倍ものパフォーマンスオーバーヘッドが生じる可能性があります。
POST /sampledata/_forcemerge?max_num_segments=1
次に、FreezeインデックスAPIエンドポイントを使用してインデックスを凍結させます。
POST /sampledata/_freeze
フローズンインデックスの検索
インデックスが凍結され、フローズンインデックスとなりました。こうなると通常の検索は実行できません。ノードごとのメモリ消費が制限されており、フローズンインデックスには制約があるからです。 誤ってフローズンインデックスを検索対象としてしまうこともあるため、リクエストに明示的に ignore_throttled=falseを追加することで、予想外のスローダウンを避けることができます。
GET /sampledata/_search?ignore_throttled=false
{
"query": {
"match": {
"name": "jane"
}
}
}
ここで、下記のリクエストを実行することで、新しいインデックスのステータスをチェックできます。
GET _cat/indices/sampledata?v&h=health,status,index,pri,rep,docs.count,store.size
下記に類似した結果が返されます。インデックスのステータスが「open」となっています。
health status index pri rep docs.count store.size
green open sampledata 5 1 2 17.8kb
先に述べたとおり、メモリ不足にならないようにクラスターを保護する必要があるため、検索のためにノードに同時にロードできるフローズンインデックスの数は制限されています。search_throttledスレッドプール内のスレッド数はデフォルトで1、キューの数はデフォルトで100です。つまり、2つ以上のリクエストを実行すると、最大100までキューに入れられることになります。スレッドプールのステータスは監視できます。以下のリクエストで、キューや拒否についてチェックできます。
GET _cat/thread_pool/search_throttled?v&h=node_name,name,active,rejected,queue,completed&s=node_name
下記に類似した結果が返されるはずです。
node_name name active rejected queue completed
instance-0000000000 search_throttled 0 0 0 25
instance-0000000001 search_throttled 0 0 0 22
instance-0000000002 search_throttled 0 0 0 0
フローズンインデックスに関するプロセスは遅くなる可能性がありますが、事前にきわめて効率的にフィルタリングすることが可能です。リクエストのパラメーターの pre_filter_shard_sizeを1にすることも推奨されます。
GET /sampledata/_search?ignore_throttled=false&pre_filter_shard_size=1
{
"query": {
"match": {
"name": "jane"
}
}
}
こうすることで、クエリに相当なオーバーヘッドが生じることはなく、通常のシナリオと同様の作業ができます。たとえば、時系列のインデックスで特定の日付範囲を検索する場合は、すべてのシャードが一致するわけではありません。
凍結されたElasticsearchインデックスに書き込む方法
すでに凍結されているインデックスに書き込もうとするとどうなるでしょうか?試してみましょう。
POST /sampledata/_doc
{
"name":"Janie",
"lastname":"Doe"
}
どうなったでしょうか?フローズンインデックスは読み取り専用のため、書き込みはブロックされます。これはインデックス設定で確認できます。
GET /sampledata/_settings?flat_settings=true
以下が返されます。
{
"sampledata" : {
"settings" : {
"index.blocks.write" : "true",
"index.frozen" : "true",
....
}
}
}
UnfreezeインデックスAPIを使用して、インデックスの解凍エンドポイントを呼び出す必要があります。
POST /sampledata/_unfreeze
ここで、3つ目のドキュメントを作成して検索することができます。
POST /sampledata/_doc
{
"name":"Janie",
"lastname":"Doe"
}
GET /sampledata/_search
{
"query": {
"match": {
"name": "janie"
}
}
}
解凍は、例外的な状況においてのみ実行するべきです。また、インデックスを再度凍結する前には必ず「force_merge」を実行して、最適なパフォーマンスを確保するようにしてください。
Kibanaでのフローズンインデックスの使用
まずは、サンプルのフライトデータをロードする必要があります。
「Sample flight data」の[Add]ボタンをクリックします。
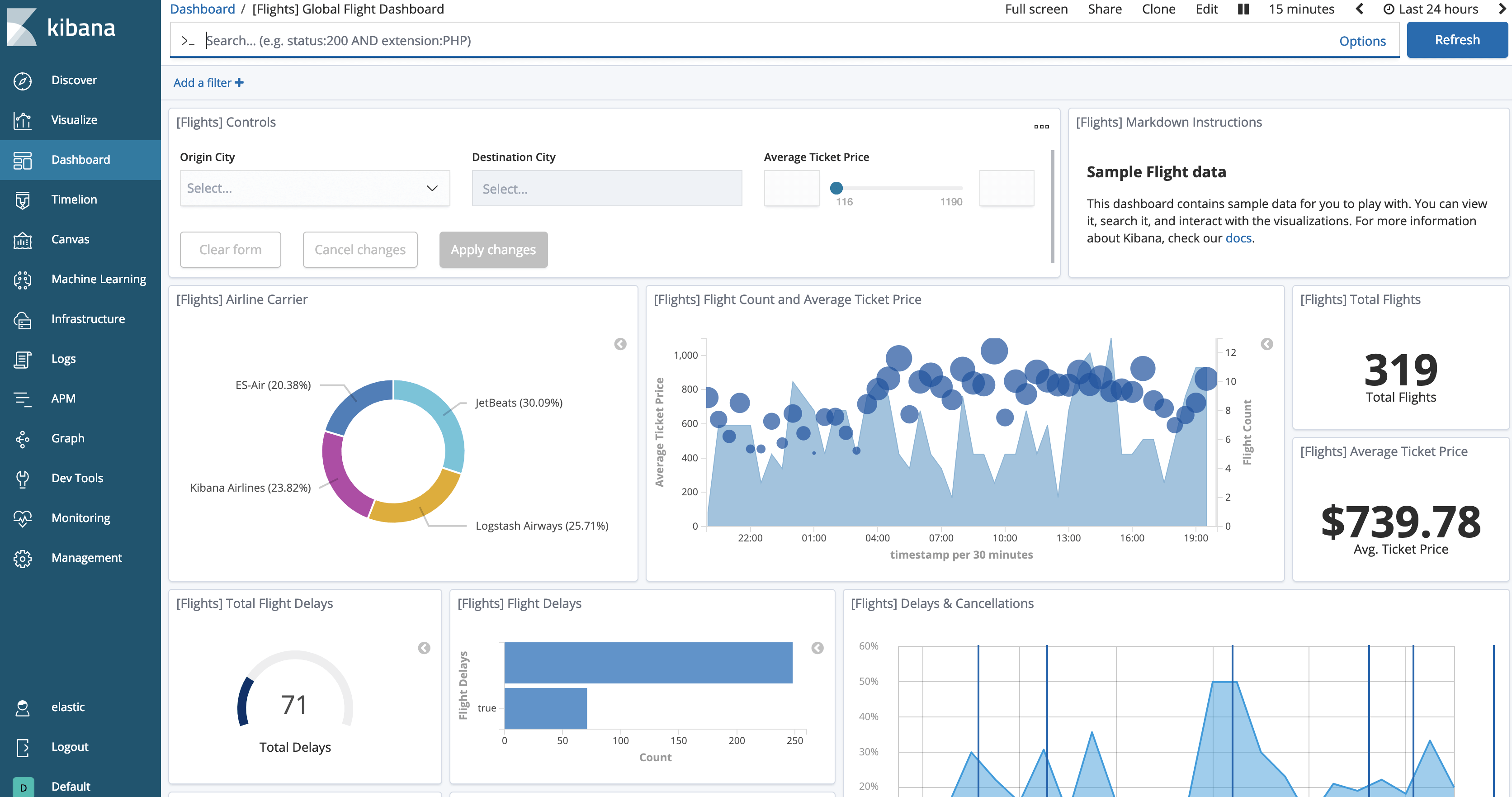
[View data]ボタンをクリックすると、ロードされたデータを見ることができるはずです。下記に類似したダッシュボードが表示されます。
これでインデックスの凍結をテストできます。
POST /kibana_sample_data_flights/_forcemerge?max_num_segments=1
POST /kibana_sample_data_flights/_freeze
ダッシュボードに戻ると、データが「消えた」ように見えます。
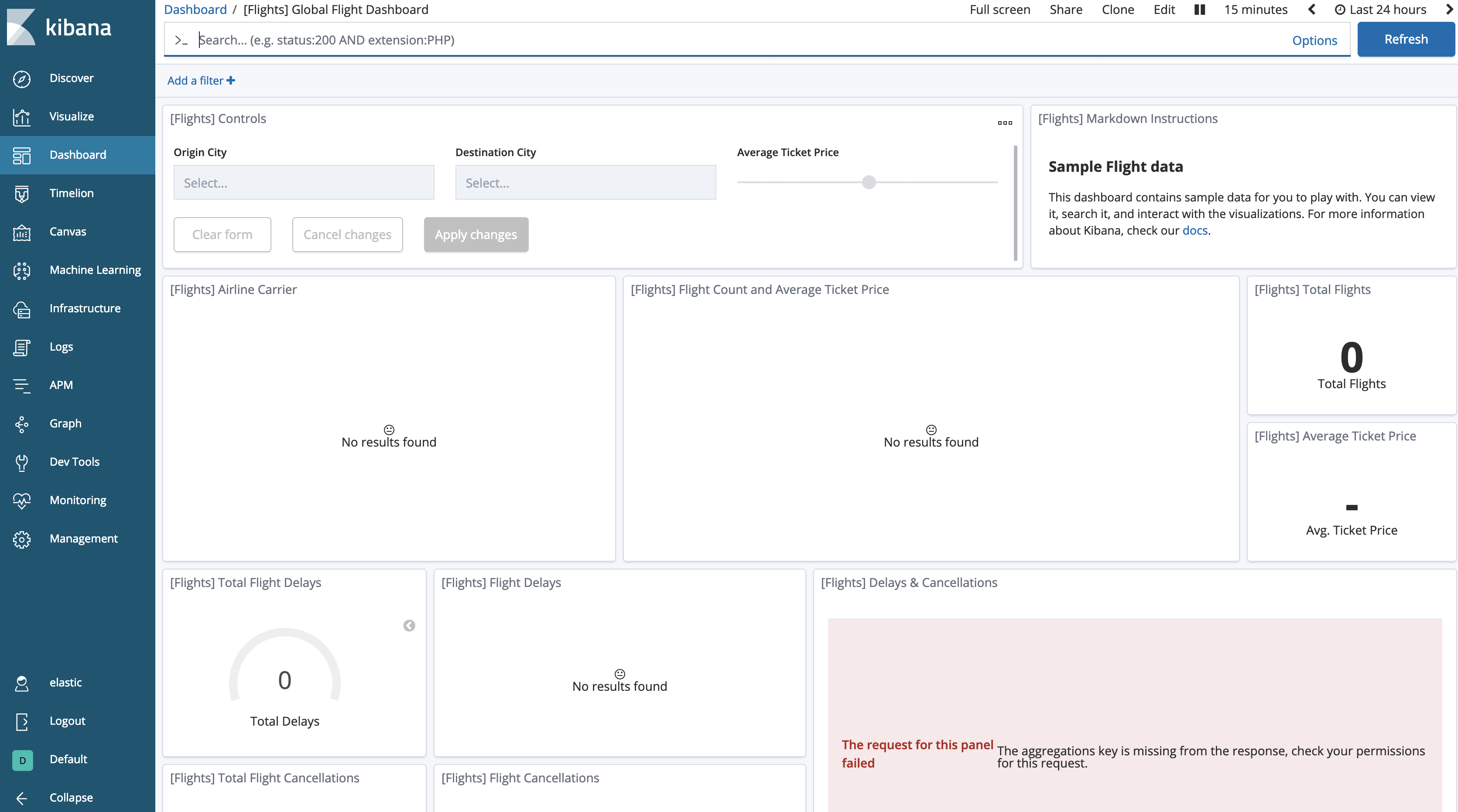
フローズンインデックスに対する検索を許可するようにKibanaに指示する必要があります。これはデフォルトでは無効化されています。
[Kibana Management]にアクセスし、[Advanced Settings]を選択します。[Search]セクションで「Search in frozen indices」が無効化されています。[On]にして、この変更を保存します。

フライトのダッシュボードでは再度、そのデータが表示されます。
まとめ
フローズンインデックスは、Hot-Warmアーキテクチャーでの非常に強力なツールです。これによって、オンライン検索ができる状態を維持しながら保持期間の延長に対応できる、コスト効果の高い解決策が実現します。フローズンインデックスの最適なサイジングと検索レイテンシを知るために、ハードウェアおよびデータを使用して検索レイテンシをテストすることをお勧めします。
FreezeインデックスAPIの詳細については、Elasticsearchのドキュメントをご確認ください。そしていつものとおり、ご質問がある場合はDiscussフォーラムをご活用ください。フローズンインデックスのご利用をお勧めします。