Base vectorielle et base de données graphique : comprendre les différences


 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
La gestion du big data ne consiste pas à stocker le plus de données possible. Il s'agit d'être capable d'identifier des informations pertinentes, de découvrir des schémas cachés et de prendre des décisions documentées. Cette quête vers une analytique avancée a été le moteur de bon nombre d'innovations concernant les solutions de modélisation et de stockage des données, allant bien au-delà des bases de données relationnelles classiques.
Deux de ces innovations sont les bases vectorielles et les bases de données graphiques. Toutes deux constituent des avancées majeures dans la gestion des données, offrant des structures de données uniques dotées de leurs propres atouts. Toutefois, il est essentiel de comprendre leur fonctionnement et leurs différences avant de pouvoir choisir efficacement celle qui convient le mieux à votre projet et à vos objectifs.
Cet article de blog vous servira de guide, en décrivant leur fonctionnement, leurs points communs et leurs différences. Nous explorerons les structures de données contrastées, leurs cas d'utilisation idéaux, et vous aiderons à choisir entre les deux. Pour faciliter votre lecture, nous l'avons divisé en plusieurs sections :
Définition et concepts d'une base vectorielle
Qu'est-ce qu'une base de données graphique ?
Comparaison entre une base vectorielle et une base de données graphique
Cas d'utilisation des bases de données vectorielles et graphiques
Comment choisir entre une base vectorielle et une base de données graphique
À la fin de cet article, vous aurez toutes les informations nécessaires pour prendre une décision avisée et, de là, tirer le meilleur parti de vos données.
Définition et concepts d'une base vectorielle
Plutôt que d'organiser les données en lignes et en colonnes, une base vectorielle organise les données sous forme de points dans un vaste espace multidimensionnel. Chaque point représente une donnée, placée dans cet espace selon ses caractéristiques par rapport aux autres données. Pour illustrer notre propos, imaginez un univers où chaque planète représente une donnée, organisée de manière à être plus proche des planètes similaires et plus éloignée de celles présentant moins de similitudes.
Cela s'obtient en stockant les données sous forme de vecteurs à haute dimensionnalité, qui sont des représentations numériques des caractéristiques des données. Ces vecteurs capturent l'essence des données qu'ils représentent, ce qui permet de les encoder et de les organiser dans l'espace multidimensionnel. Plus deux points sont proches dans cet espace, plus leurs données sous-jacentes sont similaires.
C'est pourquoi les bases vectorielles excellent dans la recherche de similarités. En effet, comme les vecteurs sont structurés en fonction de leurs similitudes, vous pouvez rapidement identifier les points de données les plus proches de votre vecteur de requête. Cela les rend idéales pour un bon nombre d'applications importantes :
Recherche d'images et de documents : trouvez des images similaires à partir du contenu, et pas seulement des mots-clés.
Recommandations personnalisées : Recommandez des produits ou des contenus similaires à ceux avec lesquels un utilisateur a déjà interagi.
Détection des anomalies : identifiez des points de données inhabituels qui s'écartent de la norme, pouvant indiquer une fraude ou des erreurs système.
Machine learning : traitez et analysez efficacement des données à haute dimensionnalité pour des tâches telles que l'analyse de texte, la classification d'images et le traitement automatique du langage naturel.
Vous souhaitez un guide plus détaillé ? Consultez l'article Qu'est-ce qu'une base vectorielle ? pour une présentation complète.
Qu'est-ce qu'une base de données graphique ?
Bien qu'elles puissent paraître similaires au premier abord, les bases de données graphiques organisent les données de manière totalement différente. Au lieu d'utiliser des tables rigides comme une base de données relationnelle, ou d'organiser les données par similarité comme les bases vectorielles, elles stockent les données dans une structure de graphe. Les entités sont représentées par des nœuds et les relations par des arêtes. Pour illustrer notre propos, pensez à une carte mentale, où chaque nœud est un cercle représentant des personnes, des lieux ou des objets, et où les lignes qui les relient (les arêtes) montrent la façon dont ces cercles sont connectés.
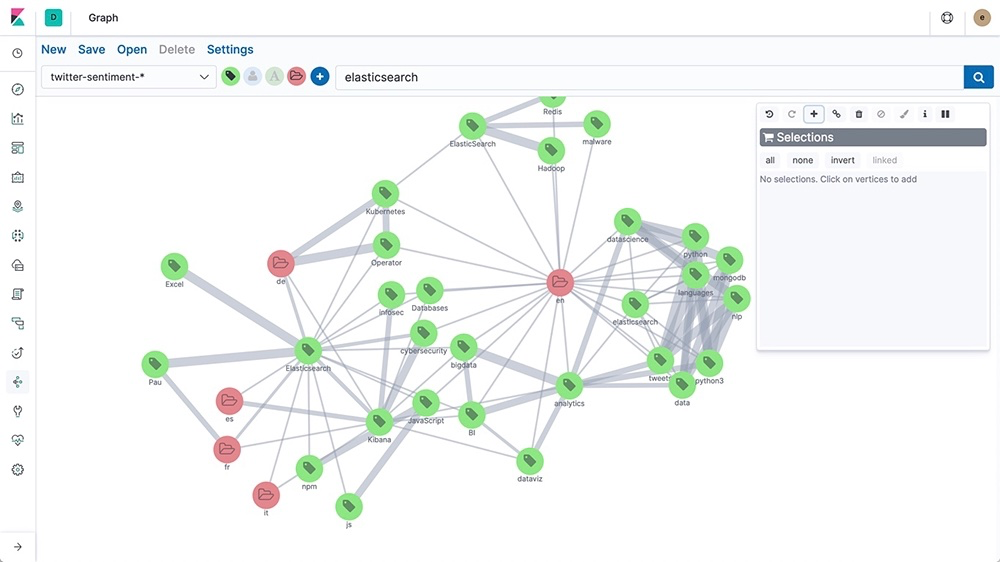
L'un des avantages de ce type de structure est qu'elle représente plus naturellement les relations complexes. Il est ainsi plus facile d'interpréter les connexions qu'avec d'autres types de bases de données. L'absence de schéma imposé dans les bases de données graphiques permet également d'ajouter facilement de nouveaux nœuds et arêtes à mesure que les données s'enrichissent, ce qui les rend à la fois flexibles et scalables. C'est pourquoi les bases de données graphiques sont idéales pour de nombreuses applications.
Analyse en temps réel : analysez les données de flux, prédisez les résultats futurs et optimisez les systèmes dynamiques en temps réel grâce aux bases de données graphiques.
Gestion des données de référence : créez une vue unifiée des entités, résolvez l'ambiguïté et suivez l'évolution des entités dans un seul graphe interconnecté.
Découverte du réseau : mettez au jour les connexions masquées, identifiez les anomalies et prédisez les échecs successifs en analysant les relations au sein des réseaux.
Construction de graphes de connaissances : créez des bases de connaissances intelligentes, répondez à des questions complexes et optimisez les applications intelligentes grâce à des entités et concepts interconnectés.
Comparaison entre une base vectorielle et une base de données graphique
Vous devriez maintenant comprendre ce qu'est chaque type de base de données et comment il structure les données. Cependant, il est également essentiel de comprendre les différences subtiles entre les bases de vectorielles et les bases de données graphiques. La manière la plus simple d'y parvenir est de les comparer côte à côte :
| Base vectorielle | Base de données graphique | |
| Représentation des données | Les données sont structurées sous forme de points dans un vaste espace à plusieurs dimensions. Les points situés à proximité les uns des autres représentent un contenu similaire. Idéal pour capturer les similarités au sein des données elles-mêmes, quelles que soient leurs connexions ou leurs relations. | Les données sont structurées sous forme de réseau de nœuds interconnectés (entités) liés par des arêtes (relations). Ce type de base de données se concentre sur la représentation des connexions et des hiérarchies entre les points de données, offrant de précieuses informations sur la façon dont les entités sont liées les unes aux autres. |
| Recherche et récupération | Excelle dans la recherche de similarités en trouvant efficacement des points de données semblables à un vecteur de requête. Idéal pour des tâches comme la recherche d'images ou de documents, où la compréhension de la similarité du contenu est cruciale. | Puissante pour explorer les relations et les connexions. Permet une navigation efficace dans les structures de réseau, idéal pour l'analyse des réseaux sociaux, les systèmes de recommandation et l'exploration des graphes de connaissances. |
| Performances et scalabilité | Scale généralement bien avec des ensembles de données volumineux grâce à des algorithmes optimisés de recherche de similarités. Toutefois, toute modification apportée au schéma peut nécessiter de procéder à un nouveau plongement des données, ce qui peut avoir un impact sur les performances. | Extrêmement flexible en raison de l'absence de schéma prédéfini, ce qui permet d'ajouter et de modifier facilement des données. Cependant, les requêtes complexes ou les réseaux étendus peuvent altérer les performances, ce qui nécessite une optimisation rigoureuse. |
Cas d'utilisation
Pour mieux comprendre les différences entre les bases vectorielles et graphiques, comparons leurs applications respectives au sein d'un même secteur. Cela permettra non seulement de mettre en évidence leurs différences, mais aussi d'illustrer comment elles pourraient être combinées pour obtenir d'excellents résultats.
Détection de la fraude
Bases vectorielles : Identifiez les transactions frauduleuses en analysant les schémas de transaction et les informations sur les utilisateurs. Détectez les anomalies dans les habitudes de dépenses, les lieux d'achat ou les empreintes digitales des appareils en vous basant sur les profils de similarité appris.
- Bases de données graphiques : détectez les réseaux suspects d'individus ou de transactions interconnectés. Identifiez les activités frauduleuses en analysant les relations entre les entités impliquées dans des tentatives de fraude potentielles.
Recherche scientifique
Bases vectorielles : analysez des structures de données complexes telles que les séquences protéiques, l'expression génique ou les composés chimiques. Comparez divers ensembles de données et identifiez des similarités à partir de fonctionnalités multidimensionnelles, menant à de nouvelles découvertes scientifiques.
- Bases de données graphiques : modélisez les réseaux biologiques ou les interactions moléculaires. Explorez les relations complexes entre entités et visualisez des systèmes complexes, menant à une compréhension plus profonde des processus biologiques.
E-commerce
Bases vectorielles : analysez les attributs du produit tels que les images, les descriptions textuelles et les spécifications techniques. Recommandez des produits similaires en fonction de la similarité de contenu, ce qui produit des suggestions plus pertinentes et attrayantes.
- Bases de données graphiques : capturez les interactions utilisateur-produit telles que les achats, l'historique de navigation et les listes de souhaits. Recommandez des produits en fonction des similitudes des utilisateurs avec d'autres personnes aux goûts similaires, créant ainsi une expérience d'achat plus personnalisée.
Médias et divertissement
Bases vectorielles : analysez les caractéristiques du contenu, telles que les genres musicaux, les sujets d'articles ou les thèmes de films. Recommandez des chansons, des films ou des articles similaires en fonction de la similarité intrinsèque du contenu, en tenant compte des préférences individuelles.
- Bases de données graphiques : explorez les relations entre utilisateurs et contenus, comme l'historique de visionnage, les listes de lecture ou les partages sur les réseaux sociaux. Recommandez des contenus en fonction des liens entre utilisateurs aux intérêts similaires, favorisant ainsi l'engagement et la découverte.
Comment choisir entre une base vectorielle et une base de données graphique
Même en disposant des informations présentées dans cet article, choisir la base de données idéale peut s'avérer complexe. Pour vous faciliter la tâche, voici un framework qui vous aidera à prendre la meilleure décision pour atteindre votre objectif.
Étape 1. Comprendre vos données
Pour commencer, vous devez déterminer la complexité de vos données. Sont-elles principalement structurées ou non structurées ? Impliquent-elles des relations complexes ou des entités indépendantes ?
Il vous faut également tenir compte du volume de vos données et de leur vitesse de croissance prévue. Ensuite, vous devez déterminer les caractéristiques ou attributs spécifiques qui définissent vos points de données, et préciser s'il s'agit de données numériques ou catégorielles.
Étape 2. Identifier vos principaux cas d'utilisation
En clair, quelles informations espérez-vous tirer de votre analyse de données ? Cherchez-vous à identifier des points de données similaires en fonction de leur contenu ou à explorer des liens complexes entre les entités ? Quel type de requêtes exécuterez-vous fréquemment ?
Étape 3. Besoins en performances et en scalabilité
La troisième étape consiste à déterminer l'importance de la vitesse et de la scalabilité par rapport à votre objectif. Dans quelle mesure les réponses en temps réel sont-elles critiques pour votre application ? Quelle est la taille de vos ensembles de données et la complexité des requêtes que vous prévoyez ? Vous devez également tenir compte de vos contraintes budgétaires et de vos ressources disponibles.
Étape 4 : Évaluer les avantages spécifiques de chaque technologie
Chacun de ces types de bases de données a ses propres avantages et inconvénients. Les bases vectorielles sont idéales pour la recherche de similarités, gèrent efficacement les données à plusieurs dimensions et manipulent de grands ensembles de données. Les bases de données graphiques excellent dans la gestion des relations, sont puissantes pour l'analyse de réseaux complexes, et disposent d'un schéma très flexible.
Libérez tout le potentiel de vos données
Naviguer dans l'univers du big data exige des outils performants, et les bases de données vectorielles et graphiques se distinguent comme des acteurs novateurs dans ce domaine. Cependant, choisir le modèle adapté à vos besoins peut s'avérer complexe.
Étudiez attentivement les facteurs mentionnés ci-dessus et comprenez les atouts spécifiques de chaque technologie. Vous obtiendrez ainsi une liste de facteurs qui éclaireront votre décision et vous aideront à choisir le modèle de base de données le plus adapté pour exploiter pleinement le potentiel de vos données.
Prochaines étapes conseillées
Lorsque vous êtes prêt, voici quatre méthodes qui vous aideront à mettre en place de meilleures expériences de recherche :
Démarrez un essai gratuit et découvrez l'aide qu'Elastic peut apporter à votre entreprise.
Explorez nos produits. Découvrez le fonctionnement d'Elasticsearch Platform et comment nos solutions s'adaptent à vos besoins.
Découvrez comment les bases vectorielles alimentent la recherche optimisée par l'IA.
Partagez cet article par e-mail ou via LinkedIn, X ou Facebook avec les personnes de votre réseau qui pourraient être intéressées par son contenu.
Envie d'aller plus loin sur l'analyse des données et les bases de données ?
La publication et la date de publication de toute fonctionnalité ou fonction décrite dans le présent article restent à la seule discrétion d'Elastic. Toute fonctionnalité ou fonction qui n'est actuellement pas disponible peut ne pas être livrée à temps ou ne pas être livrée du tout.
Dans cet article, nous sommes susceptibles d'avoir utilisé ou mentionné des outils d'IA générative tiers appartenant à leurs propriétaires respectifs qui en assurent le fonctionnement. Elastic n'a aucun contrôle sur les outils tiers et n'est en aucun cas responsable de leur contenu, de leur fonctionnement, de leur utilisation, ni de toute perte ou de tout dommage susceptible de survenir à cause de l'utilisation de tels outils. Veuillez faire preuve de prudence lorsque vous utilisez des outils d'IA avec des informations personnelles, sensibles ou confidentielles. Toute donnée que vous soumettez peut être utilisée pour entrainer l'IA ou à d'autres fins. Vous n'avez aucune garantie que la sécurisation ou la confidentialité des informations renseignées sera assurée. Vous devriez vous familiariser avec les pratiques en matière de protection des données personnelles et les conditions d'utilisation de tout outil d'intelligence artificielle générative avant de l'utiliser.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine et les marques associées sont des marques commerciales, des logos ou des marques déposées d'Elasticsearch N.V. aux États-Unis et dans d'autres pays. Tous les autres noms de produits et d'entreprises sont des marques commerciales, des logos ou des marques déposées appartenant à leurs propriétaires respectifs.
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer