



The Elastic Journey @ Mixmax
Mixmax is a platform for all your externally-facing communications. Just like you use Slack to talk within your team, you use Mixmax to talk to people outside of your immediate team, most notably folks in other organizations. One of our most popular features is the Mixmax Live Feed. It shows you how people interact with all the messages you and your team send, providing a chronological overview all email sends, opens, clicks, downloads, meeting confirmations, replies, and more. It’s searchable (using natural language queries across recipients and subject), filterable, live-updating, and provides top-level aggregate statistics.
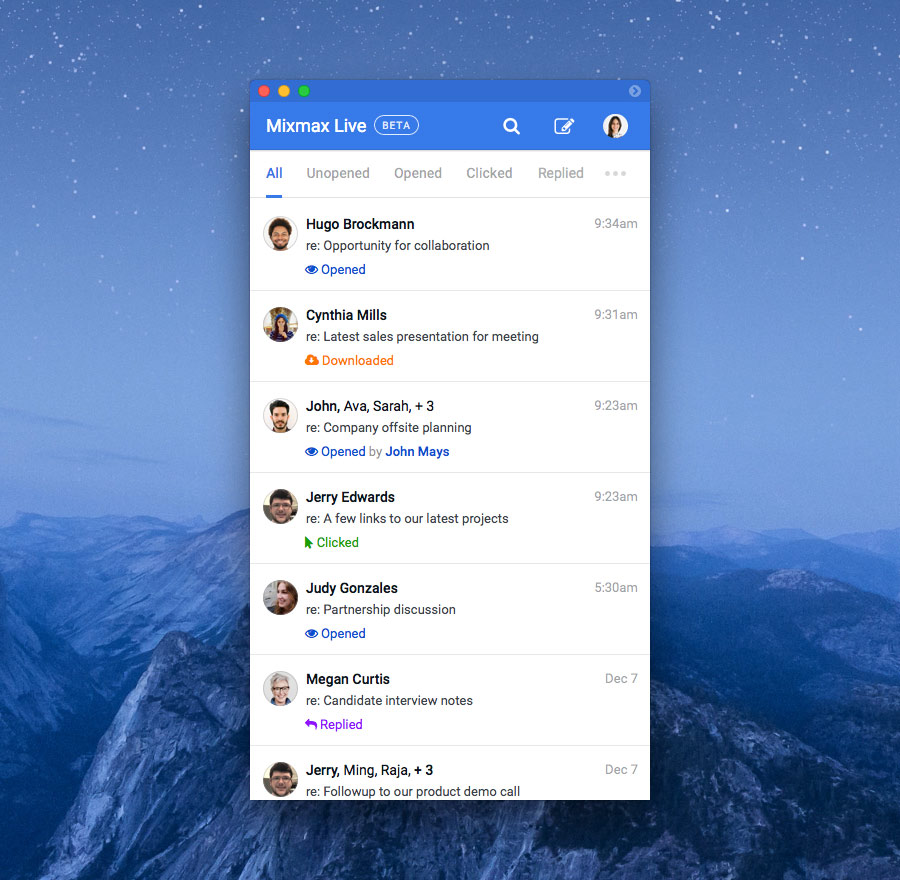
Our customers, such as Looker, Lever and Asana, rely on Mixmax as their primary communications platform, so you can imagine that the live feed crunches a lot of data. At last count, there were over a billion documents in the collections which make up the live feed, and our document storage grows at ~20% month-on-month.
In addition, our users expect their feed to load near-instantly, especially as it’s the entry point to our app.
Why not Mongo?
In May 2016, we began exploring how we’d build this feature. Our primary data store is Mongo, so our initial hope was that we’d be able to construct the feed directly from there. But that approach had a number of flaws: it would have required us to query documents from multiple collections, then interleave, sort and truncate them. That would obviously be inefficient, CPU-intensive and slow. Besides, Mongo couldn’t provide us with the natural language search features we wanted.
A couple of us had used Elasticsearch in the past and it seemed like a good fit here. We could dump relevant events into a single index, and it would provide super-fast searching (including the natural language search we wanted), filtering, paging, sorting and aggregation out-of-the-box. Over the course of about two weeks, we built a prototype which satisfied our performance SLAs (server response and page load times), and launched.
Schema Optimization
As we wrote here, we began to notice some of our queries performed quite poorly (300-500ms), particularly during periods of peak load.
While debugging on a sample cluster locally, we noticed that performance improved dramatically if we stored and queried upon our timestamps in seconds instead of milliseconds (our original choice of milliseconds was a reflection of our predominantly-JS stack). Across a test set of 500 million documents, we saw a 30x improvement.
Adrian Grand (Software Engineer at Elastic) helped explain the cause in more detail. The issue is isolated to Elastic versions pre-5.0. In those builds, Elastic indexed] numeric fields using prefix terms. In particular `long` values were indexed using 4 values - one that identified all bits, one that identified the first 48 bits, one that identified the first 32 bits and one that identifies the first 16 bits. These 16 bit precision steps meant there could be up to 2^16=65536 values on the edges. However, if we use seconds, our values were all multiples of 1000. Suddenly, there were only ~66 unique values at most on the edges, which made the queries much faster.
We implemented the schema change, which saw those 300-500ms queries drop to ~13ms. As we look to the future and the chance to upgrade to Elasticsearch 5.x, we expect faster queries without this workaround, due to the BKD tree in Elasticsearch.
Segment Bloat
Our Elastic cluster ticked along happily for a few more months, before we began to notice nodes dropping more frequently than they should (once every few days). Usually these were recovered automatically, but in one instance, the replica shards could not be moved back into the primary node and we experienced degraded performance that eventually led to a partial outage.
We host our Elastic cluster with Elastic Cloud (who better to provide support, right?). We contacted the team there and after some back-and-forth (which included running a diagnostic that made things worse, and turning off replication entirely) their ops team resolved the incident by removing the corrupted node and rebalancing manually.
The root cause was that our shards for the events index were enormous (~150GB each instead of the recommended ~32GB). Although we had a very large number of documents, that’s considerably more space than they should have required. After some investigation, we found that most of this space was segment bloat.
Documents in Elastic are immutable. Update operations actually create a whole new copy of the document, and leave the old copy in place until segments are merged. Unfortunately, one type of event in our feed requires frequent updating - ‘sents’. We use the ‘sent’ event to keep track of which recipients haven’t opened yet (our users love being able to see at a glance which recipients they may need to follow up with). To achieve this, we need to update the document every time a new recipient opens.
It’s not uncommon for messages in our system to have dozens of recipients, which results in a lot of update operations.
In our case, segment merges (which occur automatically in Elastic) weren't happening often enough and the result was that our large volume of updates were causing our shard size to grow unbounded, putting memory pressure on our nodes.
We haven’t yet implemented our solution for this, but our plan is twofold: firstly, we’re going to stop updating the ‘sent’ events. We’ll instead keep track of which recipients have not yet opened a message via a new collection in Mongo. Once all recipients have opened, we’ll remove the record from both Mongo and Elastic.
Using a hybrid Mongo/Elastic solution here does mean we’ll need to decorate the ‘sent’ events when we fetch the feed (by performing a Mongo query to obtain the read/unread status of the message recipients), but we think the slight performance loss is a good trade-off for stability.
Secondly, we’re moving to a multi-index architecture in Elastic, with a new index created for live feed events each week. When we need to fetch a feed, we’ll query from the most recent index first, then if not enough results have been found, query the previous week, stepping backward through weeks until we’ve found enough results or some horizon is reached. Almost all of the events we show in the live feed are from the current week, so in practice, we expect to query old indexes very infrequently. This will allow us to keep our shard size small.
Overall we’re happy with our experience with Elastic. The live feed will continue to be a big part of the Mixmax platform, and we expect to roll out more search-related features (fuzzy search, autocorrect, searching message bodies etc) in the near future.
Cameron Price-Austin is a Senior Software Engineer at Mixmax