



Rapid anomaly detection via ransom note file classification
Editor’s Note: Elastic joined forces with Endgame in October 2019, and has migrated some of the Endgame blog content to elastic.co. See Elastic Security to learn more about our integrated security solutions.
Despite a decrease in deployment in 2018, ransomware remains a widespread problem on the Internet as malicious actors seek to shift towards more targeted campaigns (e.g. SamSam) and leverage more subtle methods of distribution rather than spear phishing messages. Over the last few years, static-based analysis of binaries prior to execution and dynamic detections that attempt to determine anomalous process activity as it occurs have emerged as the dominant approaches to mitigating ransomware.
While these solutions can be effective, they can sometimes take too long to determine if a process is truly malicious or miss certain processes due to focusing solely on executables. As an experimental approach to address these shortcomings, and for presentation at BSidesLV and DEF CON AI Village this year, we developed a machine learning model to classify forensic artifacts common to ransomware infections: ransom notes. Leveraging this model, we were able to prototype a dynamic ransomware detection capability that proved to be both effective and performant.
All related code and resources can be found at the noteclass project’s git repository: https://github.com/endgameinc/noteclass
Ransom Notes
The purpose of ransom notes is pretty straightforward:
- Notify victims they have been infected with ransomware and that their files are encrypted
- Instruct victims to provide a ransom payment (in the form of Bitcoin or other cryptocurrency) for the means to decrypt and restore access to the files
- Provide a deadline for the ransom payment
Ransom notes typically come in the form of TXT files, but there are also several instances of notes comprised of formatted/rich text (HTML, RTF) or images (JPG, PNG, BMP).
Provided below are three examples of ransom notes:
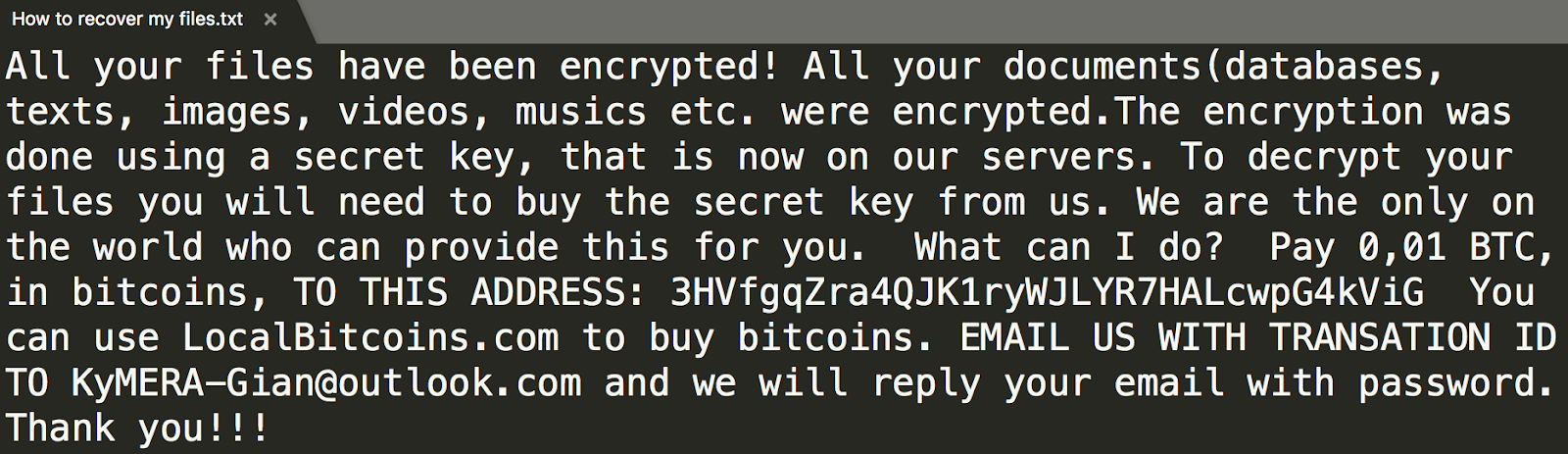
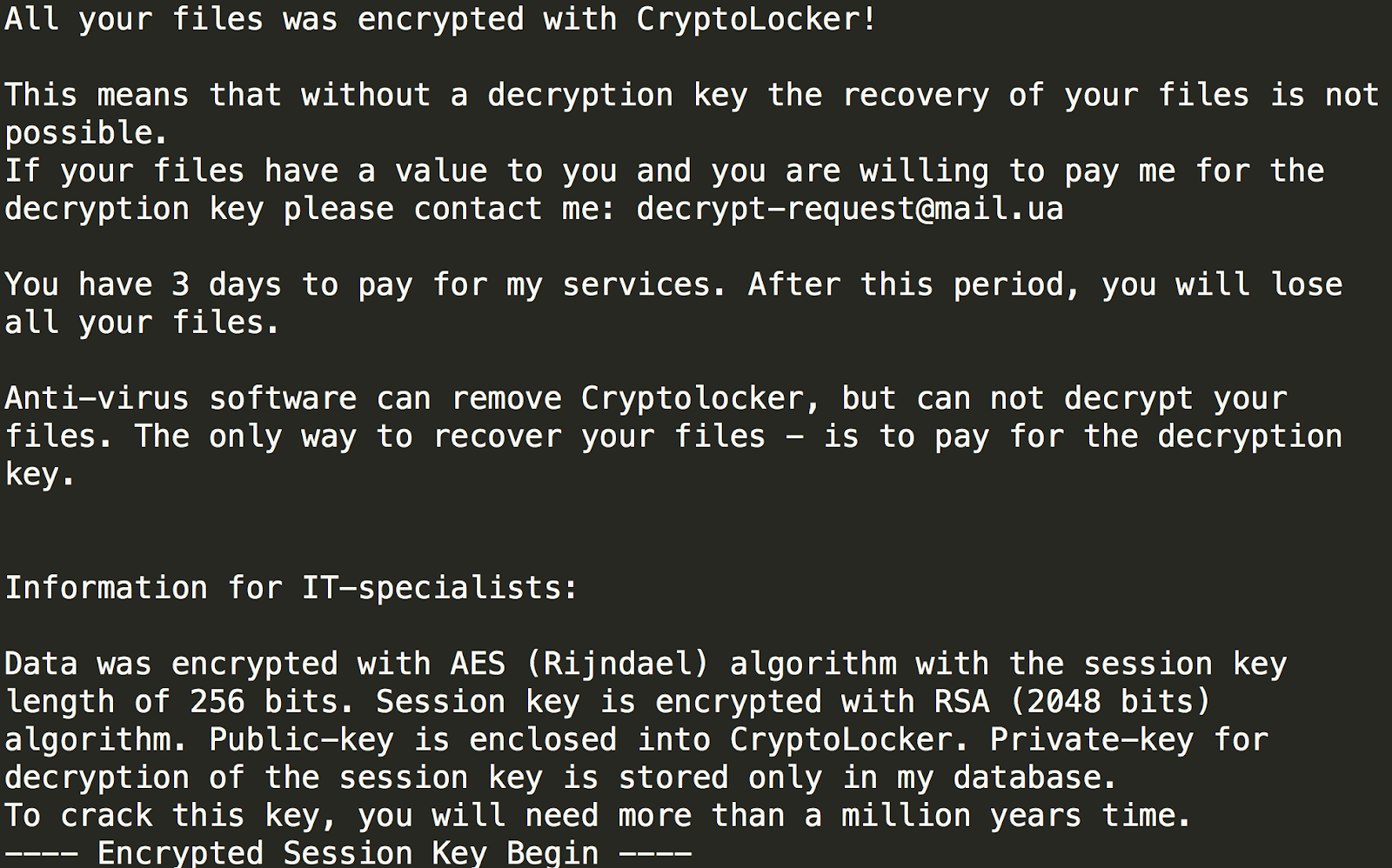

The three notes, despite pertaining to infections caused by three separate ransomware samples, share a similar vocabulary and carry out the first two or all three of the objectives previously mentioned. With this knowledge in hand, we set out to determine if ransom notes are suitable for automated classification.
Exploratory Research
To determine the suitability of ransom notes for classification, we used K-means clustering as our approach and compiled two datasets:
- Ransom notes
- 173 notes obtained from detonating ransomware and scouring research blogs and twitter
- Benign data
- 11314 samples (20 Newsgroups dataset)
With our clustering approach, we merged the two distinct datasets into one unlabeled dataset and configured scikit-learn to produce 21 clusters. In our case, 21 is derived from the ransom notes and each of the 20 newsgroups, as we hoped that the benign data from the newsgroups would cluster together according to their respective topics and that the ransom notes would form their own independent cluster.
To prepare the data for clustering, each document in the combined dataset was tokenized:
- Initial token preparation
- Newline characters stripped
- All text converted to lowercase
- Tokenization
- Non-alphanumeric characters stripped
- Stop words stripped
- e.g., the, for, your
- Lemmatization
- encryption → encrypt
The remaining tokenized data was then vectorized by counting word occurrences in each document (CountVectorizer) and then transforming those vectors to more heavily weigh less common (with respect to the entire overall text data corpus) words using term frequency-inverse document frequency (TfidfVectorizer).
To provide an initial overview of the data, we looked at the top 20 words according to the CountVectorizer results.
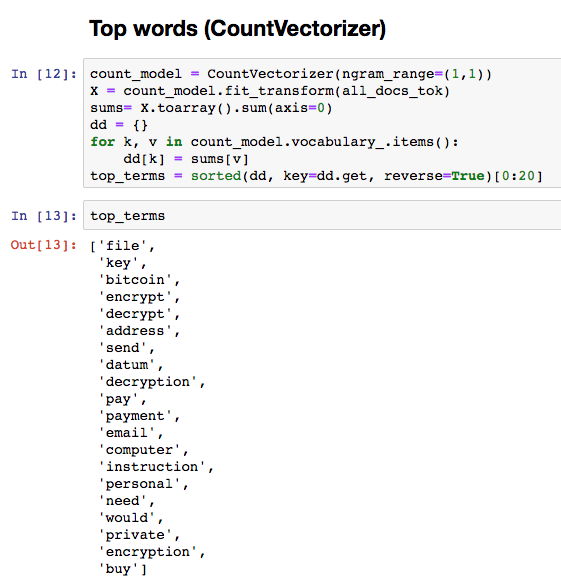
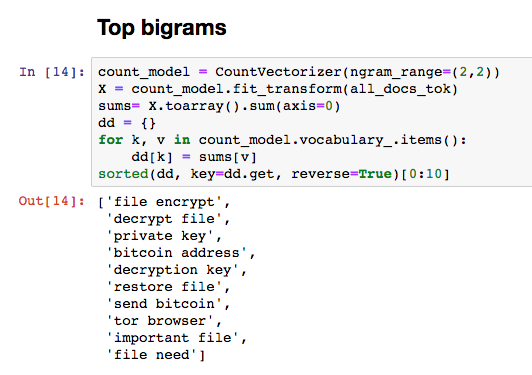
Even without any provided context, these words strongly relate to the previously seen ransom note samples. A quick look at the top bigrams provides additional context and helps to paint a more vivid picture of the data.
When the vectorized data was clustered, we ended up with the following results:
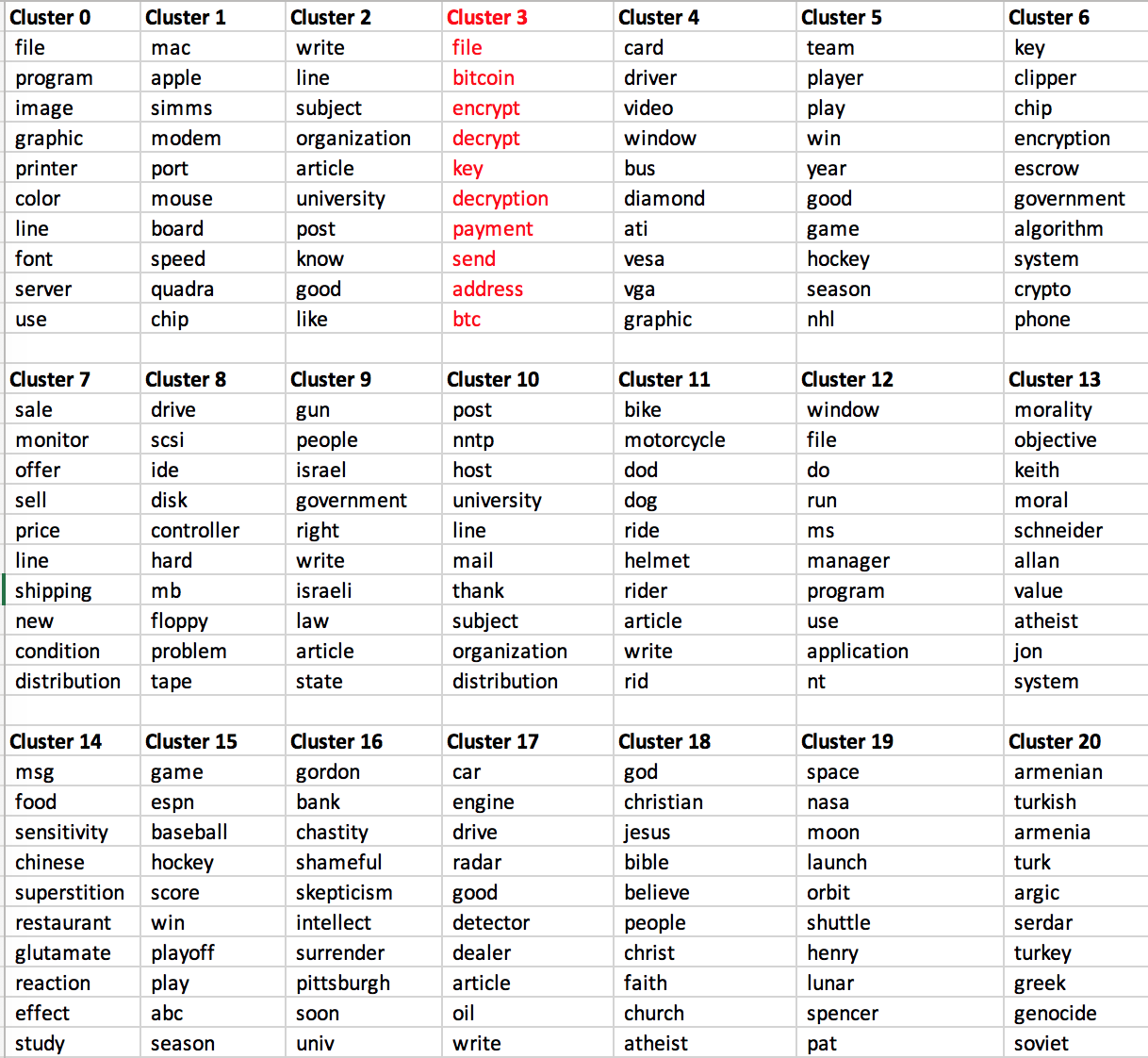
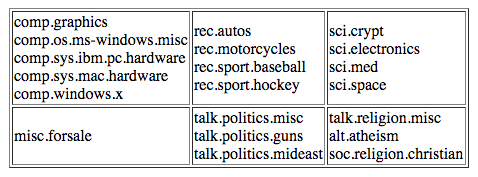
As highlighted above, the ransom notes appear to have been clustered into their own group in Cluster 3. A brief overview of the topics in the Newsgroups datasets provides additional context into the other clusters:
In order to validate our clustering, we conducted additional tests with varying data. For our first test, we wanted to determine if a ransom note that was not in our dataset would be placed into the correct cluster:
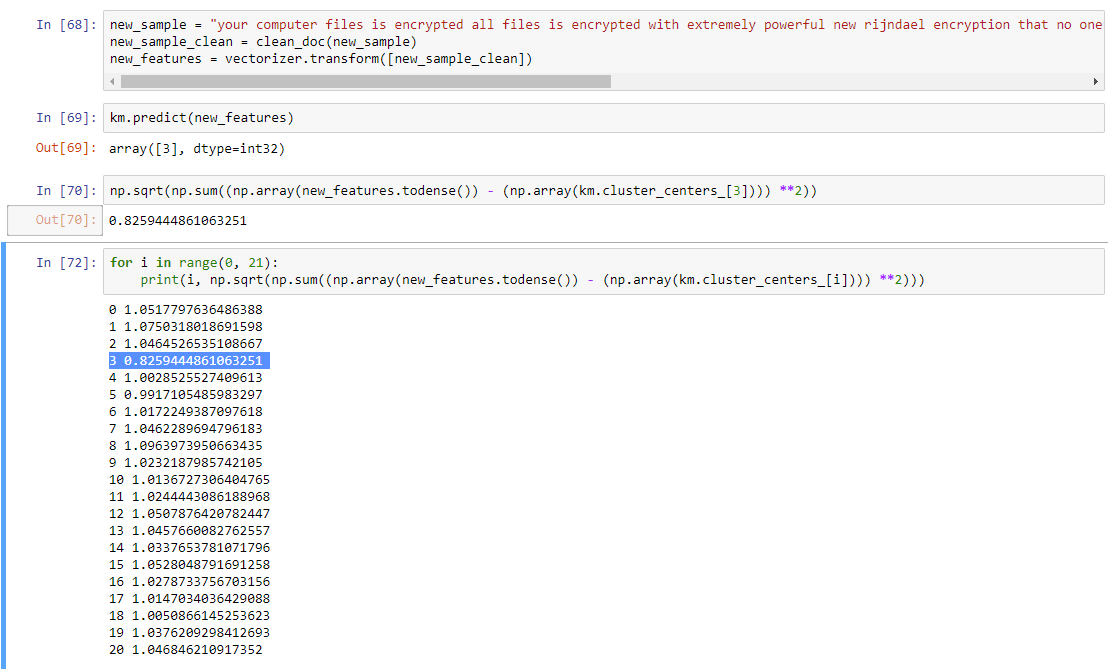
We calculated the distance from the centroid for each of the clusters, and the closest cluster came out to be Cluster 3, as desired.
For our second test, we provided a block of text that contains terms relevant to ransom notes, but without the necessary context or phrasing to comprise an actual ransom note:
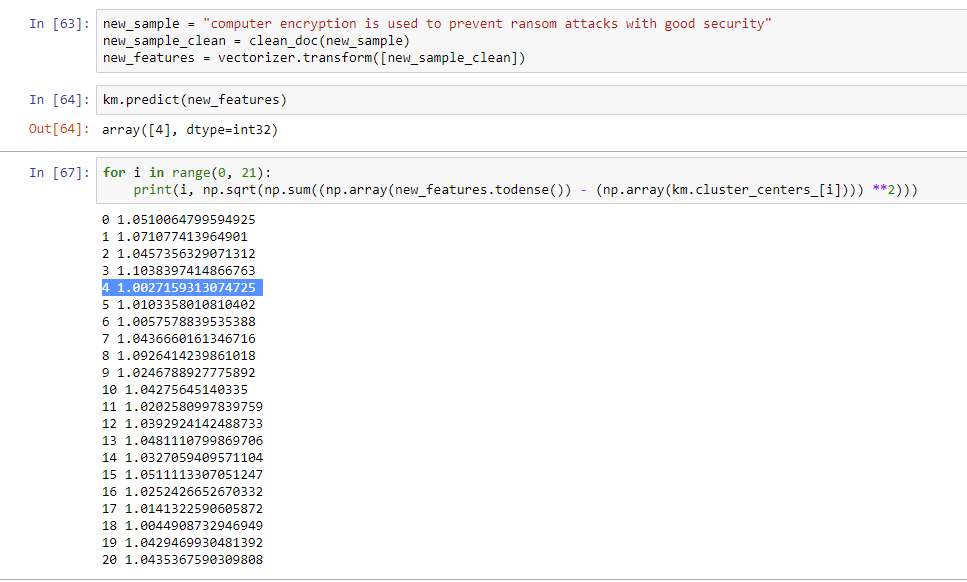
According to our results, this text block was placed into Cluster 4, which contains messages from the comp.graphics newsgroup.
Despite the small size of our set of ransom notes (especially in comparison to the overall size of the combined dataset), the data clustered together very well and our two tests demonstrated some nuance in how the data was clustered. Satisfied with the results, we deemed the dataset appropriate for classification and began building out our prototype.
POC Framework
Since the ultimate goal is to detect the presence of a ransom note on a live system as quickly as possible after it is written to disk, we came up with the following high-level requirements:
- Obtain file change events in near real-time
- Obtain paths of newly created text files
- Read in file contents and determine if data consists of a ransom note
- If file is a ransom note, suspend the source process and notify user of activity
Provided below is a diagram that describes how the framework operates and responds to a ransomware process dropping a ransom note to disk:
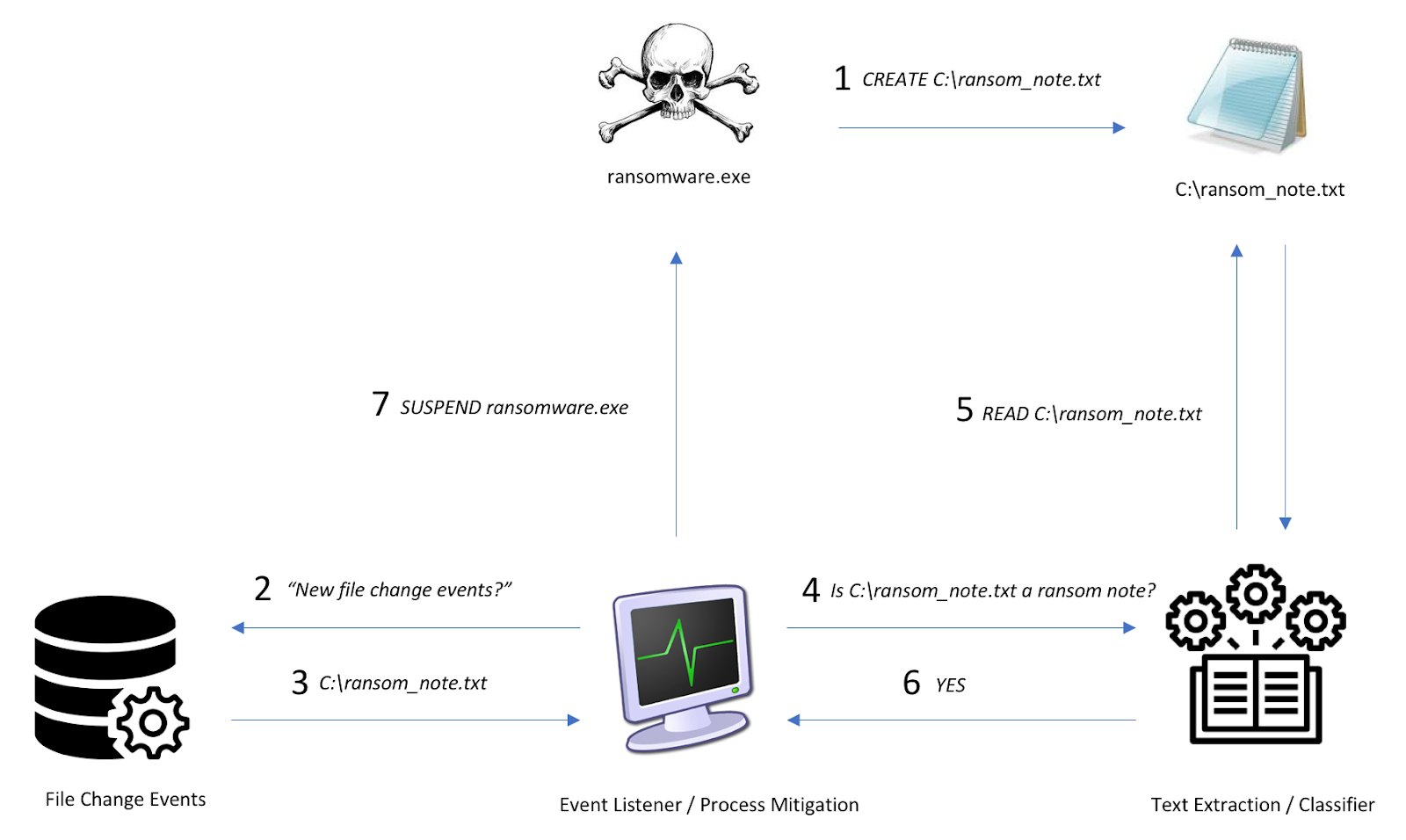
Since this was developed as a POC, we decided to restrict our data to English TXT files less than 20 KBs in size. For our purposes, though, these restrictions still cover a majority of ransom note samples that have been surveyed by researchers over the last few years, while helping our framework avoid other potential noise.
To improve the accuracy of the classifier, we made some changes to our dataset. For the benign data, we reduced the number of messages from the Newsgroups 20 dataset down to a little over 8000 and then added over 3000 Windows TXT files (primarily README and log files). We procured more ransom notes and more than doubled the size of the set. Finally, we leveraged SMOTE (Synthetic Minority Oversampling Technique) to address the significant dataset imbalance of the number of notes versus the size of the benign dataset.
CLASSIFIER
Before we built the framework, we needed to build and test our model. As with our exploratory research, we carried out the same data sanitization and tokenization routine and feature selection was performed via TF-IDF. In contrast to our earlier research, we labeled each document as benign or ransom note data with the end goal of employing binary classification to any text and answering a simple question: “Is this text a ransom note or benign data?” We based our classifier on a Naïve Bayes model due to its relative ease of training, use, and speed.
At a high-level, our data processing pipeline abides by the following workflow diagram:
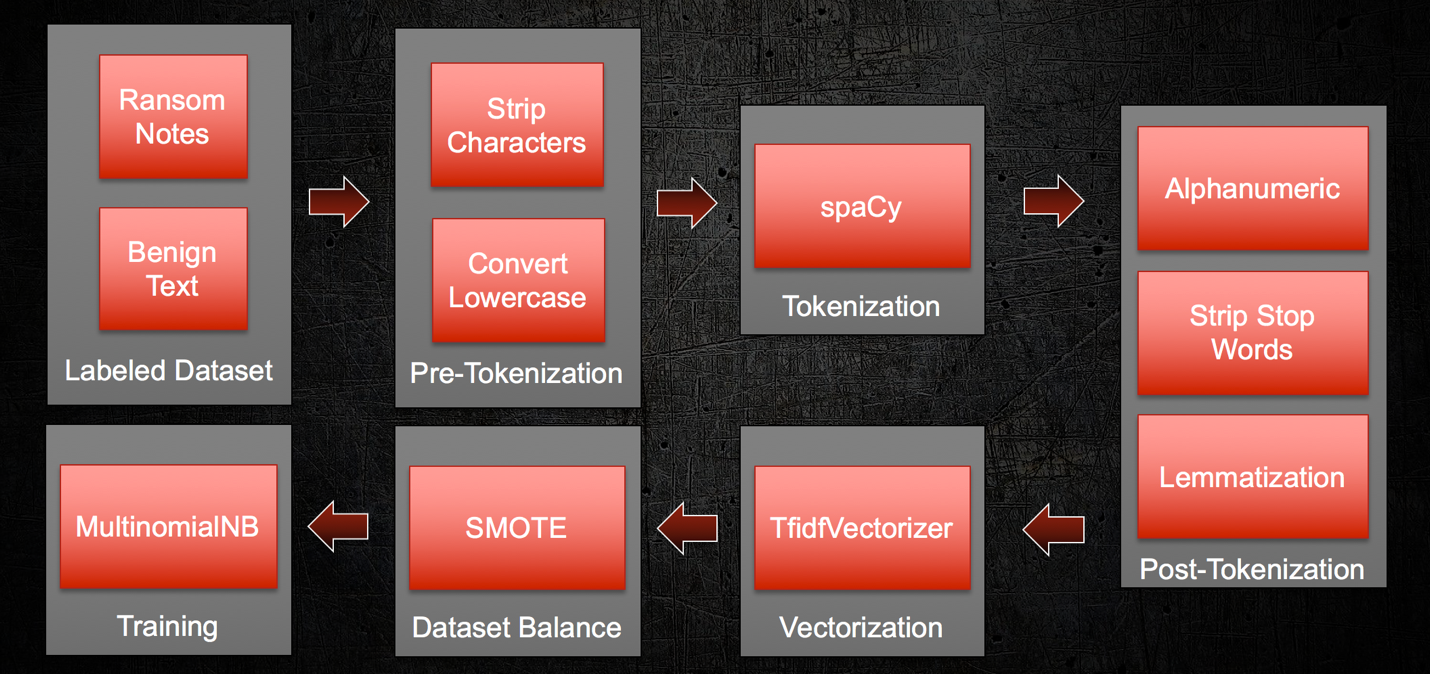
We utilized scikit-learn’s train_test_split to randomly partition our complete dataset into training (80%) and test (20%) subsets in order to fully test our model and get a more clear picture of its accuracy.
In our first test, we achieved the following results:
Accuracy: 99.54%
F1 Score: 91.86 (scaled to 100)
Confusion Matrix:
TN=2934 | FP=14 |
FN=0 | TP=79 |
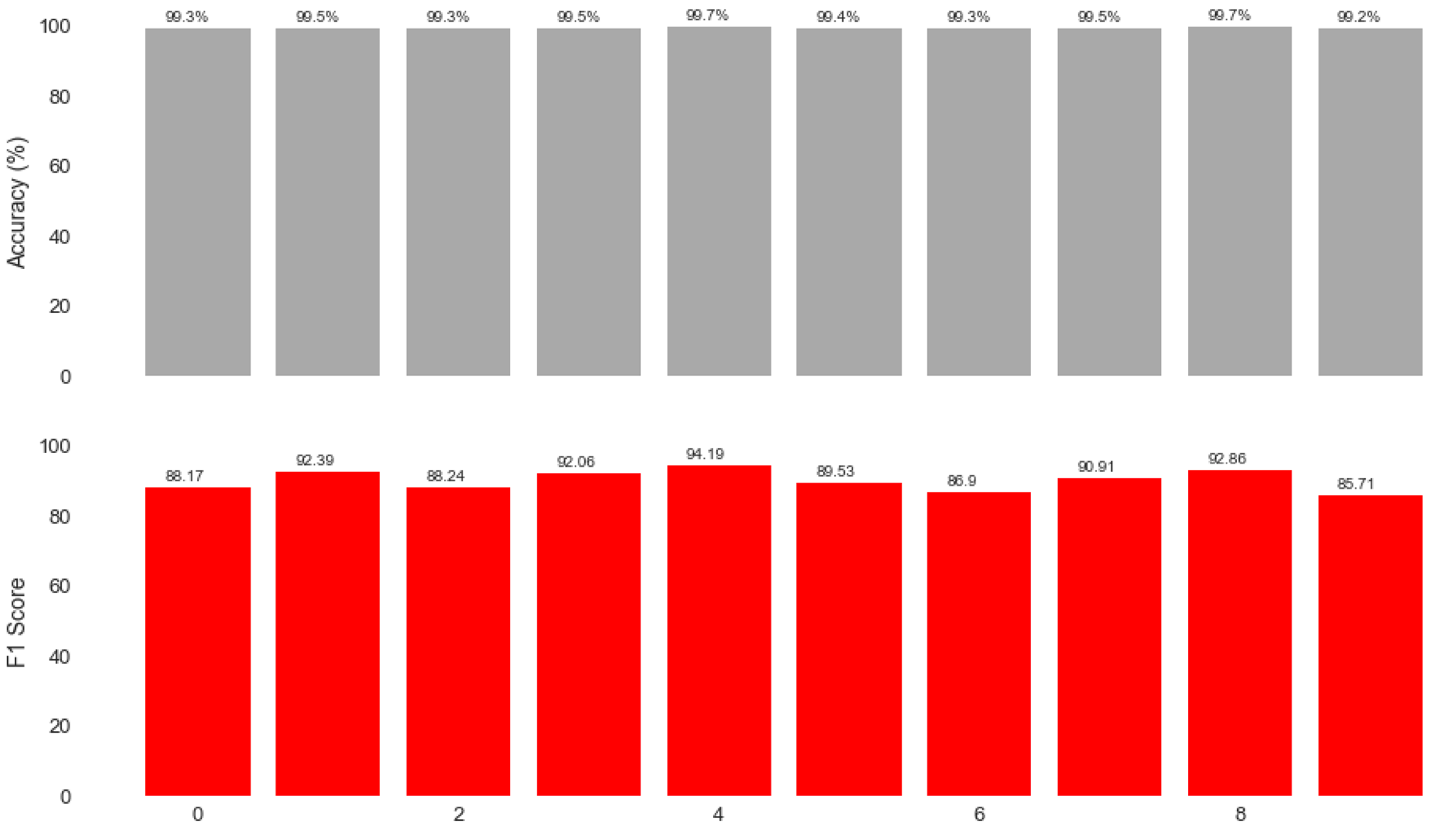
While promising, one test only provides a glimpse into the model, and thus cross validation is required. To achieve this, we used ShuffleSplit to conduct a total of ten separate runs with varying training and test data sets for each run. As the results and graphs below demonstrate, the model remained robust to the additional tests.
While promising, one test only provides a glimpse into the model, and thus cross validation is required. To achieve this, we used ShuffleSplit to conduct a total of ten separate runs with varying training and test data sets for each run. As the results and graphs below demonstrate, the model remained robust to the additional tests.
Average Accuracy: 99.44%
Average F1 Score: 90.1
Average Confusion Matrix:
TN=2933.3 | FP=16.5 |
FN=.5 | TP=76.7 |
EVENT LISTENER
After training an effective model, our next step was to develop an event listener. Before we started, we defined two basic requirements for our listener:
- Monitor events from all active processes on the host
- In particular, create events
- Limit to TXT files
- Map each event to a source process
Since our goal was to quickly build a prototype framework, we used a pre-built tool that would do most of the heavy lifting in terms of gathering events. Luckily for us, the Windows SysInternals tool suite provides one application that filled that need for us: Sysmon. Newer versions of Sysmon provide a custom Event ID for file creation activity:
With this, we built a configuration file optimized to only capture file creation events for .txt files:

While installing Sysmon with a configuration file is straightforward, a registry key needs to be added to open up access to reading the event logs from external applications.
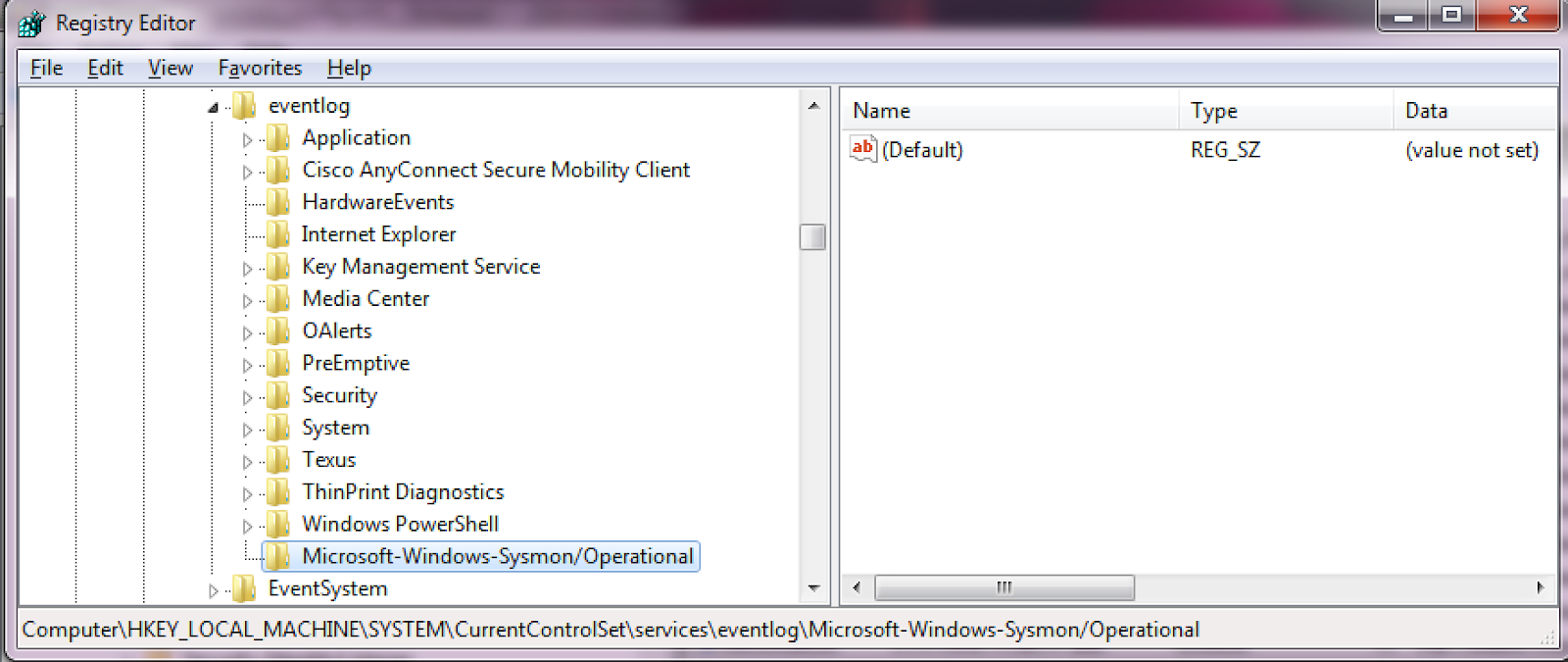
After setting up and configuring the environment properly, we proceeded to develop a python script to poll the event log for file creation events using WMI Query Language. The query ended up being the following:
SELECT * FROM Win32_NTLogEvent
WHERE LogFile = 'Microsoft-Windows-Sysmon/Operational’
AND EventCode = 11
AND RecordNumber > MaxRecordNumber
Any events that popped up in the event log would be parsed then inserted into a work queue for the classifier to process.
After integrating the classifier with the event logging component, the final piece of the framework that needed to be completed was process mitigation. The requirements we sketched were fairly straightforward:
- Determine if the process ID and process name (parsed from event log output) exist
- Suspend process if it is currently active
- Alert user of ransom note detection
- Allow user to decide to terminate or resume process
- Maintain whitelist of resumed processes
After limited testing against ransomware samples that we know generate TXT file-based ransom notes, we were able to detect samples from the following families:
- TQV
- Globelimposter
- BTCWare
- Everbe
- Volcano
- Rapid
- Gandcrab
- Painlocker
- Sigrun (note in training set)
- Josepcrypt (note in training set)
- WhiteRose (note in training set)
As with most prototype applications, there are some limitations to this framework and approach. Ransomware samples that don’t drop ransom notes, and specifically TXT ransom notes, would not be detected. Samples that drop notes later in the process life cycle would also degrade any quick detection capabilities afforded by this approach. Also, the model was only trained on English-based text, so any non-English ransom notes would likely not be detected.
Ransomware that attacks systems in other ways (e.g. MBR, raw disk/full disk encryption, screen locking) are likely not covered by this approach.
Conclusion
Current ransomware detection approaches focus largely on static and dynamic malware detection, ignoring the ransom note itself to inform detection. Our research into applying machine learning classification demonstrated that ransom notes share enough features to be properly classified. With the classifier as the core component of a prototype framework, we demonstrated great potential for detecting ransomware earlier in the process lifecycle with this approach over typical dynamic detection frameworks. We will continue to evolve this new approach and explore novel means to apply machine learning to provide the best and most innovative protections possible.