Machine Learning et cybersécurité : comment détecter l'activité d'un DGA dans les données réseau
Dans le premier article de cette série, nous avons vu comment utiliser le Machine Learning de la Suite Elastic pour entraîner un modèle supervisé de classification afin de détecter les domaines malveillants. Dans ce second article, nous expliquerons comment nous pouvons exploiter le modèle que nous avons entraîné pour enrichir les données réseau avec des classifications au moment de l'ingestion. Cette procédure est utile pour détecter l'activité de DGA potentiels dans les données Packetbeat. Vous êtes intéressé ? Lisez la suite !
La détection des DGA avec la Suite Elastic
Un programme malveillant qui infecte une machine aura souvent besoin d'un moyen de communiquer avec un serveur contrôlé par le cybercriminel (on parle de serveur de commande et contrôle, serveur C&C ou encore serveur C2). Pour contrecarrer les mécanismes de défense qui bloquent les adresses IP ou les URL codées en dur, les cybercriminels utilisent des algorithmes de génération de noms de domaine (DGA). Lorsqu'un malware veut communiquer avec un serveur C&C, il se servira du DGA pour générer des centaines, voire des milliers de domaines candidats, et essayera d'associer une adresse IP à chacun d'eux. Ensuite, le cybercriminel n'aura plus qu'à ajouter un ou plusieurs domaines générés par le DGA pour pouvoir communiquer avec la machine infectée. Les DGA sont implantés et randomisés de différentes façons pour qu'ils soient encore plus difficiles à repérer et à bloquer.
L'activité des DGA implique habituellement des requêtes DNS. Aussi, cette activité se manifestera souvent dans les requêtes DNS effectuées par une machine infectée. Packetbeat peut collecter le trafic DNS et l'envoyer à Elasticsearch aux fins d'analyse. Dans cet article, nous allons voir comment vous pouvez enrichir les informations des requêtes DNS dans les données Packetbeat à l'aide d'un score, qui servira à évaluer le caractère malveillant d'un domaine.

Les processeurs d'inférence et le pipeline d'ingestion
Un modèle entraîné à faire la distinction entre domaines malveillants et domaines sans risques peut émettre des prédictions. Pour enrichir les données Packetbeat à l'aide de ces prédictions, nous devons configurer un pipeline d'ingestion avec des processeurs d'inférence appropriés. Les processeurs d'inférence permettent d'utiliser un modèle entraîné dans la Suite Elastic (ou dans une bibliothèque externe prise en charge) pour émettre des prédictions sur les nouveaux documents au moment où ils sont ingérés dans Elasticsearch. Pour comprendre comment tous ces éléments s'articulent et quelles sont les configurations nécessaires, faisons un petit rappel du premier article.
Dans le premier article, nous avons vu comment entraîner un modèle de classification afin qu'il prédise si un domaine spécifique est malveillant ou sans risques. Pour cela, nous réalisons une opération d'ingénierie des caractéristiques sur les données d'entraînement : notre modèle utilise un ensemble de domaines malveillants et sans risques connus pour apprendre à évaluer les domaines nouveaux et inconnus. Les domaines bruts doivent être manipulés pour en extraire les fonctionnalités (monogrammes, bigrammes, trigrammes) qui seront utiles au modèle. Cette même procédure d'ingénierie des caractéristiques doit être également appliquée aux domaines des données Packetbeat que nous voulons évaluer.
C'est pourquoi, en plus d'un processeur d'inférence, notre pipeline d'ingestion inclura aussi des processeurs de script painless pour extraire des monogrammes, des bigrammes et des trigrammes des données DNS Packetbeat au moment de l'ingestion. Vous trouverez un diagramme représentant l'ensemble du pipeline en figure 2.
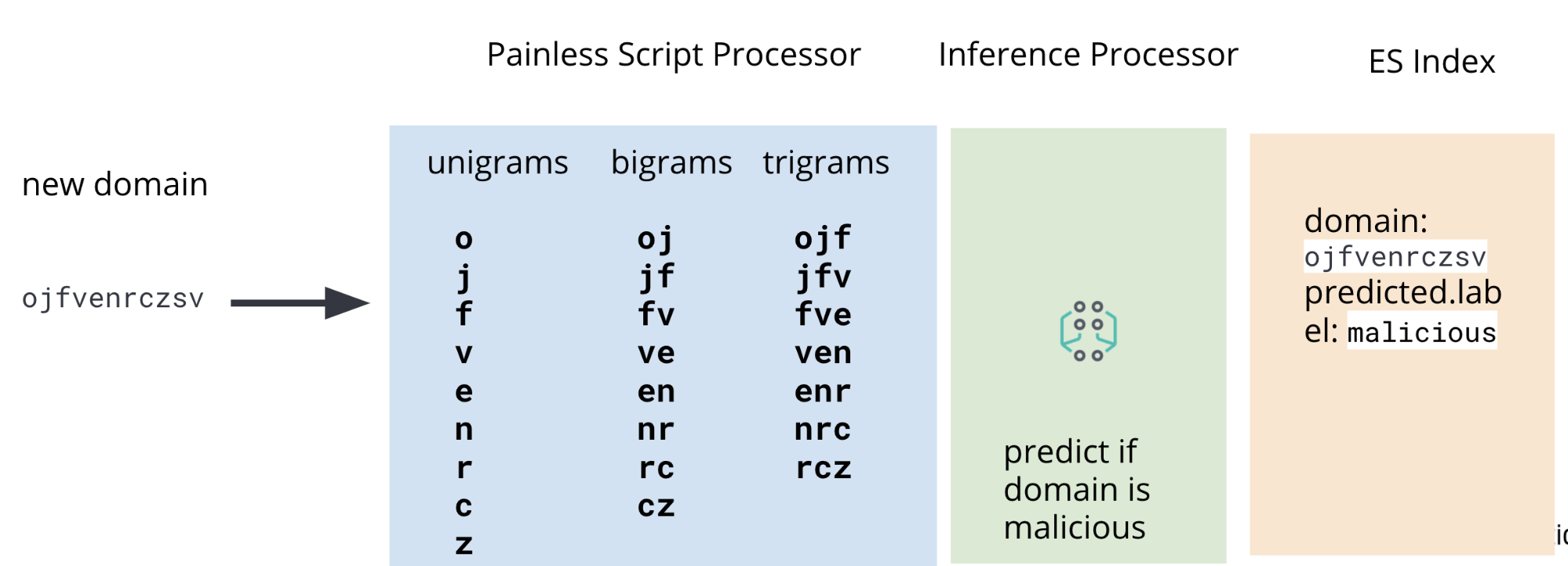
Dans les données Packetbeat, le champ qui nous intéresse est le domaine enregistré DNS. Même si dans certains cas, ce champ ne contiendra pas de domaine intéressant, il est suffisamment pertinent pour illustrer le cas d'utilisation dans cet article. La figure 3 montre les champs intéressants dans un exemple de document Packetbeat.

dns.question.registered_domainPour extraire les monogrammes, bigrammes et trigrammes de dns.question.registered_domain, nous aurons besoin d'un script painless comme celui indiqué à la figure 4.
POST _scripts/ngram-extractor-packetbeat
{
"script": {
"lang": "painless",
"source": """
String nGramAtPosition(String fulldomain, int fieldcount, int n){
String domain = fulldomain.splitOnToken('.')[0];
if (fieldcount+n>=domain.length()){
return ''
}
else
{
return domain.substring(fieldcount, fieldcount+n)
}
}
for (int i=0;i<ctx['dns']['question']['registered_domain'].length();i++){
ctx['field_'+Integer.toString(params.ngram_count)+'_gram_'+Integer.toString(i)] = nGramAtPosition(ctx['dns']['question']['registered_domain'], i, params.ngram_count)
}
"""
}
}
Une fois les fonctionnalités nécessaires extraites, le document, qui se trouve toujours dans le pipeline d'ingestion, passera par le processeur d'inférence. Le modèle de classification que nous avons entraîné précédemment utilisera les fonctionnalités extraites pour émettre une prédiction. Pour terminer, comme nous ne souhaitons pas encombrer notre index avec toutes les fonctionnalités nécessaires à notre modèle, nous ajouterons une série de processeurs de script painless pour supprimer les champs contenant des monogrammes, des bigrammes et des trigrammes.
Ce qui fait que, à la fin du pipeline d'ingestion, nous ingérerons donc un document Packetbeat avec les nouveaux champs supplémentaires qui contiennent le résultat des prédictions du Machine Learning. Un exemple de configuration de pipeline d'ingestion est proposé à la figure 5. Pour obtenir plus de détails, consultez le référentiel d'exemples.
PUT _ingest/pipeline/dga_ngram_expansion_inference
{
"description": "Expands a domain into unigrams, bigrams and trigrams and make a prediction of maliciousness",
"processors": [
{
"script": {
"id": "ngram-extractor-packetbeat",
"params":{
"ngram_count":1
}
}
},
{
"script": {
"id": "ngram-extractor-packetbeat",
"params":{
"ngram_count":2
}
}
},
{
"script": {
"id": "ngram-extractor-packetbeat",
"params": {
"ngram_count":3
}
}
},
{
"inference": {
"model_id": "dga-ngram-job-1587729368929",
"target_field": "predicted_label",
"field_mappings":{},
"inference_config": { "classification": {"num_top_classes": 2} }
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params":{
"ngram_count":1
}
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params":{
"ngram_count":2
}
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params": {
"ngram_count":3
}
}
}
]
}
Certains documents Packetbeat n'enregistreront pas de requête DNS. De ce fait, nous devons configurer le pipeline d'ingestion de sorte qu'il s'exécute uniquement si les champs DNS requis sont présents et renseignés dans le document ingéré. Pour cela, nous nous servirons d'un processeur de pipeline (voir la configuration dans la figure 6) pour vérifier si les champs requis sont présents et renseignés, puis pour rediriger le traitement du document vers le pipeline dga_ngram_expansion_inference défini à la figure 5. Attention : la configuration ci-dessous convient bien à un prototype. En revanche, pour un cas d'utilisation de production, vous devez prendre en compte la gestion des erreurs dans le pipeline d'ingestion. Pour obtenir des configurations et des instructions complètes, consultez le référentiel d'exemples.
PUT _ingest/pipeline/dns_classification_pipeline
{
"description": "A pipeline of pipelines for performing DGA detection",
"version": 1,
"processors": [
{
"pipeline": {
"if": "ctx.containsKey('dns') && ctx['dns'].containsKey('question') && ctx['dns']['question'].containsKey('registered_domain') && !ctx['dns']['question']['registered_domain'].empty",
"name": "dga_ngram_expansion_inference"
}
}
]
}
Utilisation de la détection des anomalies comme outil d'analyse complémentaire sur les résultats de l'inférence
Le modèle que nous avons entraîné dans le premier article renvoyait un taux de faux positifs de 2 %. Même si ce chiffre paraît relativement faible, il faut bien garder à l'esprit que le trafic DNS génère énormément de volume. De ce fait, même un taux de faux positifs de 2 % entraînera un nombre substantiel de requêtes considérées comme malveillantes. Pour réduire le nombre de faux positifs, une méthode consisterait à approfondir les schémas d'ingénierie des caractéristiques. Une autre consisterait à appliquer la détection des anomalies sur les résultats de notre classification. C'est ce que nous allons tout de suite voir dans la Suite Elastic.
La première chose à observer est que, si nous prenons les documents Packetbeat enrichis et que nous effectuons un décompte du nombre de documents évalués comme malveillants au fil du temps, nous obtenons alors une série temporelle (figure 7).
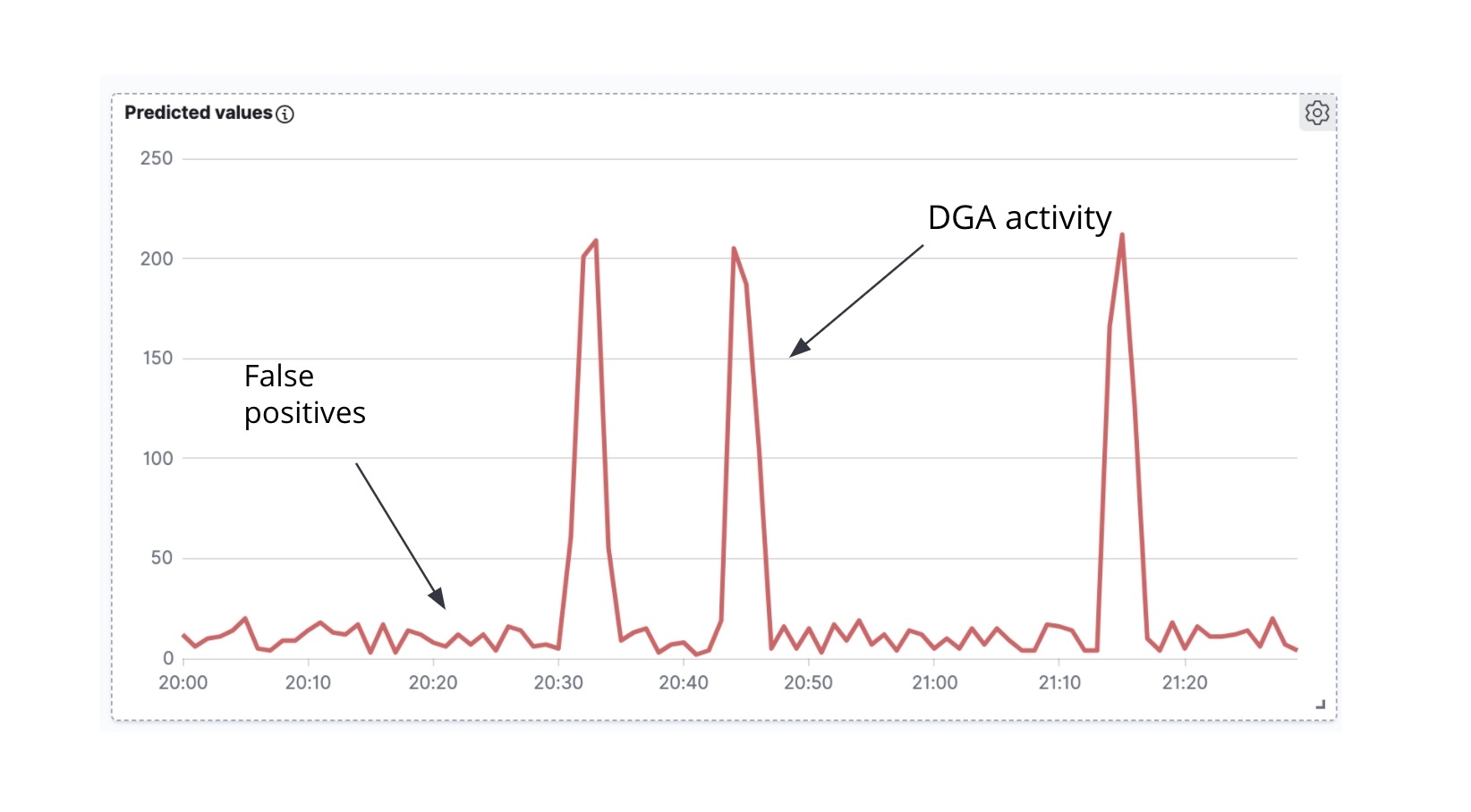
La deuxième chose à noter, c'est que bien souvent (même si ce n'est pas systématique), lorsqu'un malware à DGA essaye de communiquer activement avec le serveur C&C, il a tendance à générer une vague de requêtes DNS en une seule fois (c'est-à-dire que le malware parcourt de nombreux domaines générés par l'algorithme en essayant d'associer l'adresse IP à chaque domaine). Dans l'analyse temporelle des domaines prédits comme étant malveillants au fil du temps (figure 6), nous constatons qu'il y a des pics d'activité et peu de bruit entre les pics. Les pics indiquent que notre modèle de classification a classé de nombreux domaines comme étant malveillants dans un laps de temps très court, ce qui nous laisse penser que nous avons affaire à un véritable DGA. Par opposition, le bruit en arrière-plan entre les pics est vraisemblablement le résultat de faux positifs. C'est précisément cette intuition que nous cherchons à encoder dans une tâche de détection des anomalies high_count pour cette série temporelle.
Si nous combinons la tâche de détection des anomalies à la série temporelle de la figure 7, nous remarquerons que les alertes que nous recevons correspondent aux pics de la série temporelle (l'activité d'un authentique DGA) et qu'aucune alerte n'est générée entre deux pics (le bruit en arrière-plan de faux positifs).
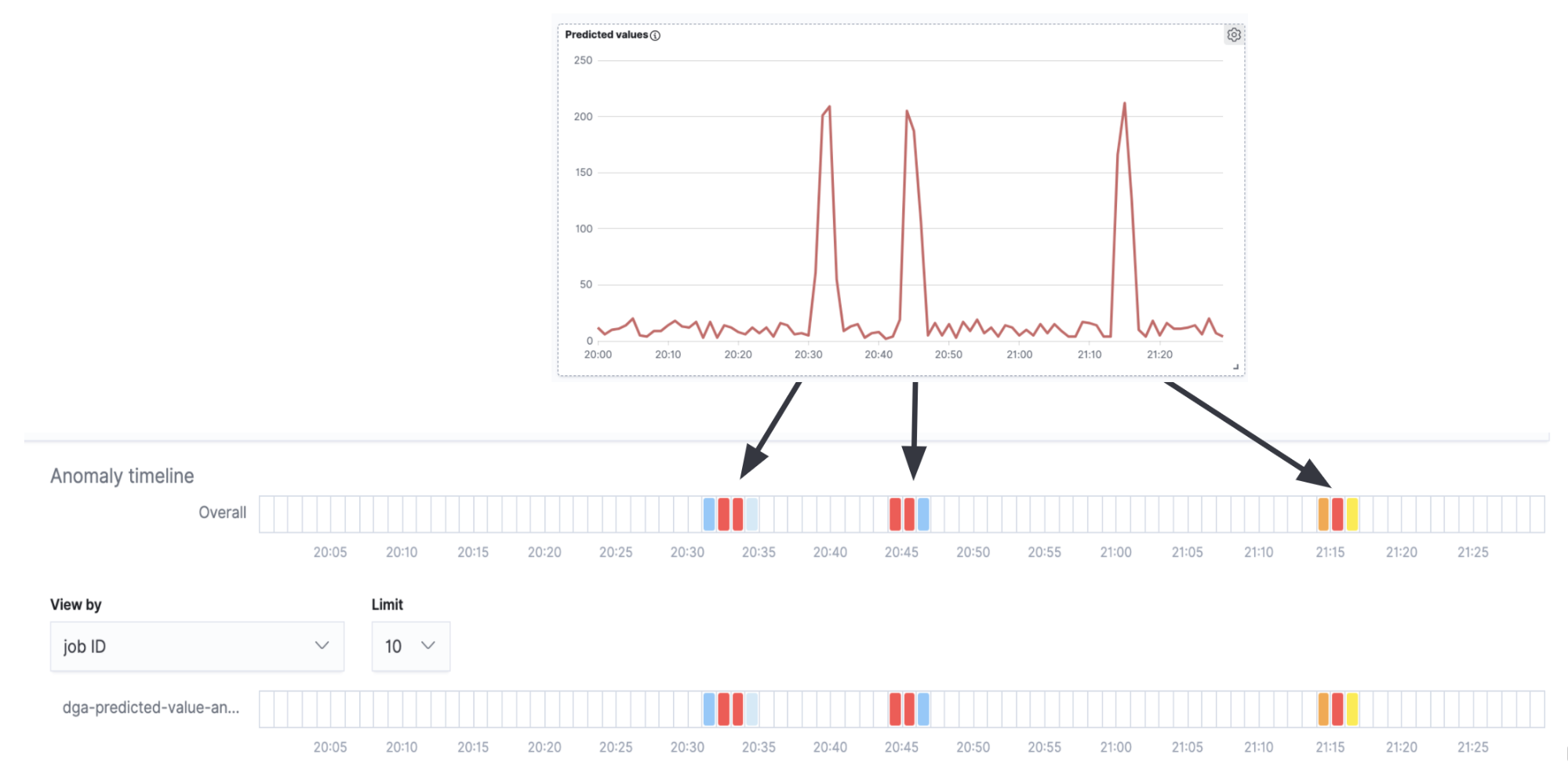
Il va sans dire qu'il s'agit d'un exemple très simple et qu'il faudrait probablement pousser davantage la configuration pour un cas d'utilisation en production. Néanmoins, on voit bien que les tâches de détection des anomalies peuvent apporter une aide efficace en tant qu'outil d'analyse complémentaire sur les résultats de l'inférence.
Conclusion
Dans cet article, nous nous sommes servis d'un modèle de classification entraîné pour enrichir les données réseau (documents Packetbeat) au moment de l'ingestion. Le processus d'enrichissement, facilité par le processeur d'inférence et les pipelines d'ingestion, ajoute une prédiction à chaque domaine interrogé lors d'une requête DNS. Celle-ci indique la probabilité qu'un domaine soit malveillant. Par ailleurs, nous avons également vu comment utiliser une tâche de détection des anomalies sur les résultats de l'inférence pour réduire le nombre de faux positifs. Nous prévoyons aussi de fournir une configuration et des modèles organisés pour détecter les DGA dans Elastic SIEM.
Vous avez envie d'en juger par vous-même sur vos propres données réseau ? Optez pour un essai gratuit de 14 jours d'Elasticsearch Service pour commencer à ingérer et analyser vos données. Vous pouvez également tester le Machine Learning gratuitement pendant 30 jours en téléchargeant une version d'évaluation de la Suite Elastic en local. Ou, si vous préférez, lancez-vous avec Elastic SIEM, une solution ouverte et gratuite, pour commencer à protéger vos données dès aujourd'hui.