Machine Learning et cybersécurité : comment entraîner des modèles pour détecter l'activité des DGA
Qu'il est ennuyant de recevoir un appel publicitaire d'un numéro de téléphone aléatoire. Même si vous le bloquez, cela ne changera rien car le prochain appel sera passé à partir d'un tout autre numéro. Les cybercriminels se servent des mêmes astuces. À l'aide d'algorithmes de génération de noms de domaine (DGA), les créateurs de malware modifient la source de leur infrastructure de commande et de contrôle. Ils échappent ainsi aux outils de détection, ce qui frustre les analystes en sécurité qui tentent de les bloquer.
Dans cette série de deux articles, nous allons utiliser le Machine Learning Elastic pour créer un modèle qui détecte les DGA et nous verrons comment l'évaluer. Voici ce que nous allons voir dans ce premier article :
- La procédure d'extraction des fonctionnalités à partir des domaines bruts malveillants et sans risque
- Quelques explications concernant la procédure permettant d'identifier les fonctionnalités appropriées
- Une démonstration pour entraîner et évaluer un modèle de Machine Learning à l'aide de la Suite Elastic
Dans le second article, nous verrons comment déployer le modèle entraîné dans un pipeline d'ingestion pour enrichir les données Packetbeat au moment de l'ingestion. Les fichiers de configuration et les documents d'accompagnement seront disponibles dans le référentiel d'exemples.
Si vous souhaitez effectuer le test de chez vous, je vous recommande d'opter pour un essai gratuit de notre Elasticsearch Service. Vous aurez ainsi accès à l'ensemble de nos fonctionnalités de Machine Learning. C'est parti !
Un peu de contexte concernant les DGA
Après avoir infecté une machine cible, de nombreux malware tentent d'entrer en contact avec un serveur distant, appelé serveur de commande et contrôle (C&C ou C2). Le but : exfiltrer des données et recevoir des instructions ou des mises à jour. Cela signifie que le binaire malveillant doit connaître soit l'adresse IP du serveur C&C, soit le domaine. Si l'adresse IP ou le domaine est codé en dur dans le binaire, il est relativement simple pour les mécanismes de défense de contrecarrer cette communication en ajoutant le domaine à une liste noire.
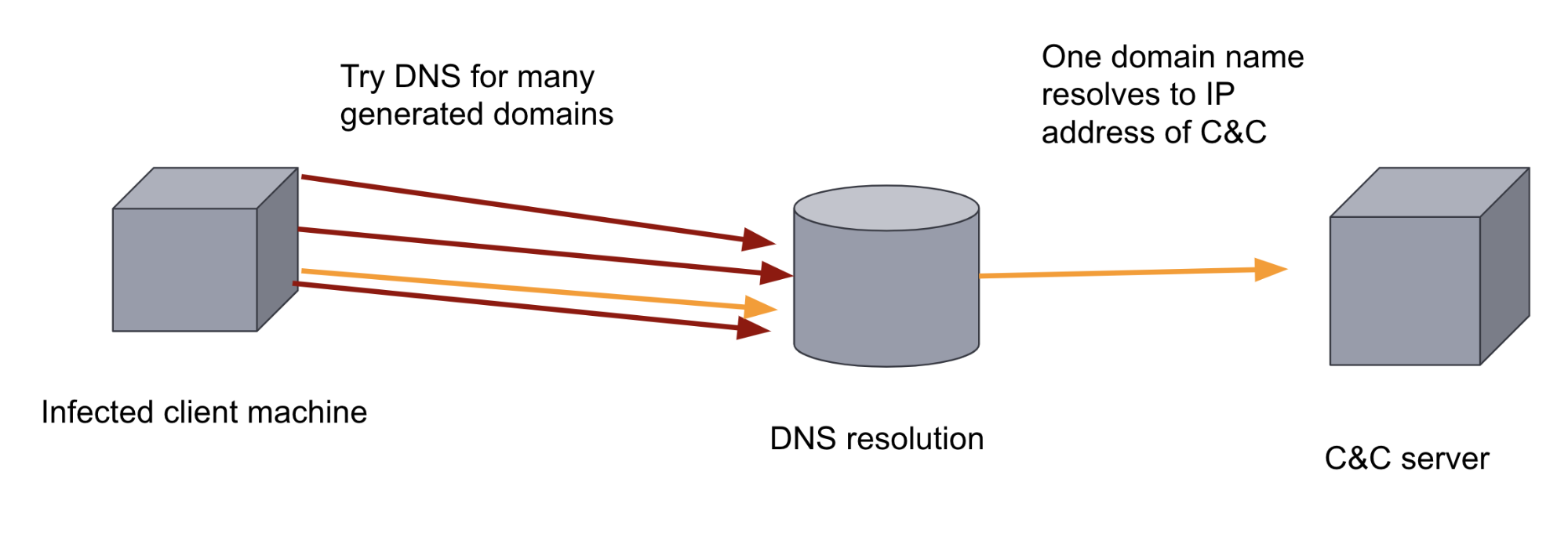
Pour saboter ce mécanisme de défense, les créateurs de malware peuvent ajouter un DGA. Les DGA génèrent des centaines, voire des milliers, de domaines d'apparence aléatoire. Le binaire malveillant se trouvant sur la machine infectée parcourt ensuite les domaines générés et essaye de faire correspondre les noms des domaines pour déterminer celui qui a été enregistré comme étant le serveur C&C. Au vu du volume et du caractère aléatoire des domaines, il est très compliqué de contrecarrer ce moyen de communiquer avec une défense basée sur des règles. De même, un analyste humain se verra vite submergé, étant donné que le trafic DNS est en général extrêmement élevé. C'est pourquoi, dans cette situation, le Machine Learning est l'approche idéale à adopter.
Entraînement d'un modèle de Machine Learning pour classer des domaines
Dans le cadre d'un Machine Learning supervisé, nous fournissons un ensemble de données d'entraînement avec des étiquettes, qui contient des domaines malveillants et des domaines sans risques. Un modèle peut ainsi apprendre de cet ensemble de données, puis mettre à profit les connaissances acquises pour classer les domaines inconnus soit comme étant malveillants, soit comme étant sans risques.
Il existe différents types de DGA, qui ne se ressemblent pas forcément. Certains DGA génèrent des domaines d'apparence aléatoire, tandis que d'autres utilisent des listes de mots. Pour les modèles de production, des fonctionnalités et des modèles différents peuvent être utilisés pour capturer les caractéristiques des différents algorithmes. Dans cet exemple, nous allons entraîner un modèle unique par rapport aux caractéristiques identifiées dans la plupart des algorithmes courants.
Pour cela, nous allons utiliser un ensemble de données composé de domaines venant de différentes familles de malware et de domaines sans risques.

cryptolocker, banjori et suppobox
Ingénierie des caractéristiques
Pour créer un modèle de Machine Learning efficace, il faut des fonctionnalités qui puissent capturer les caractéristiques des domaines générés par les DGA. Pour cela, nous devons indiquer au modèle les aspects de la chaîne qui sont importants pour faire la distinction entre un domaine malveillant et un domaine sans risques. On appelle cette opération "ingénierie des caractéristiques" ou "ingénierie des fonctionnalités".
La compréhension des fonctionnalités distinctives d'un domaine malveillant par rapport à un domaine sans risques passe par un processus itératif. Par exemple, nous avons commencé tout d'abord par des fonctionnalités simples, comme la longueur et l'entropie du nom de domaine. Mais les modèles qui en résultaient n'étaient pas particulièrement précis, par rapport à d'autres méthodes comme la mémoire à court terme. Ces modèles exploitent les caractéristiques séquentielles des chaînes. Nous nous sommes donc mis en quête d'autres fonctionnalités qui encoderaient les séquences plus efficacement.
Après avoir itéré à l'aide de plusieurs approches d'ingénierie des caractéristiques, nous sommes parvenus à la conclusion qu'il était plus pertinent d'exploiter des sous-chaînes de différentes longueurs pour mieux capturer la différence entre un domaine malveillant et un domaine sans risques dans le modèle.
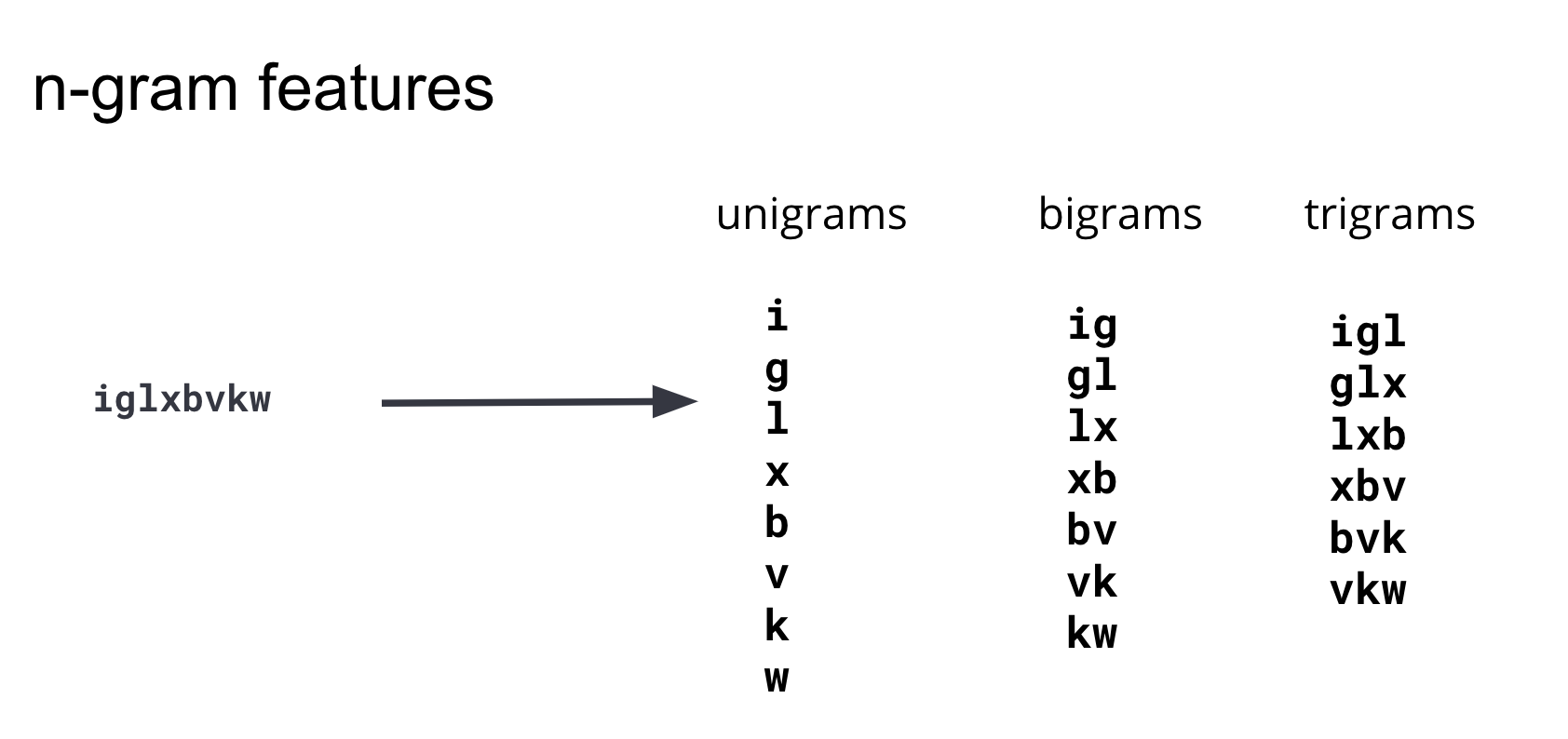
On appelle couramment ces sous-chaînes "n-grammes". Lorsqu'on développe des fonctionnalités, il est important d'équilibrer le nombre (la dimensionnalité de l'ensemble d'entraînement) et la complexité de calcul de ces fonctionnalités avec l'efficacité qu'elles apportent au modèle. Nous avons donc itéré et testé des n-grammes de différentes longueurs. Nous en avons déduit que les n-grammes d'une longueur égale ou supérieure à 4 n'ajoutaient pas d'informations prédictives pertinentes au modèle. C'est pourquoi nous avons restreint notre ensemble de fonctionnalités aux monogrammes, bigrammes et trigrammes. Le diagramme présenté à la figure 3 montre comment ces fonctionnalités sont générées à partir d'un exemple de domaine.
Pour générer un index Elasticsearch dont lequel chaque domaine DGA est fractionné en monogrammes, bigrammes et trigrammes, vous pouvez réindexer l'index source d'origine via un pipeline d'ingestion à l'aide d'un processeur de script painless. Un exemple est illustré à la figure 4 ci-dessous. Pour obtenir des configurations complètes, des instructions et des options de personnalisation, consultez le référentiel d'exemples.
POST _scripts/ngram-extractor-reindex
{
"script": {
"lang": "painless",
"source": """
String nGramAtPosition(String fulldomain, int fieldcount , int n){
String domain = fulldomain.splitOnToken('.')[0];
if (fieldcount+n>=domain.length()){
return ''
}
else
{
return domain.substring(fieldcount, fieldcount+n)
}
}
for (int i=0;i<ctx['domain'].length();i++){
ctx[Integer.toString(params.ngram_count)+'-gram_field'+Integer.toString(i)] = nGramAtPosition(ctx['domain'], i, params.ngram_count)
}
"""
}
}
En temps normal, il y aurait besoin d'effectuer un prétraitement plus conséquent pour convertir les sous-chaînes de longueur 1, 2 et 3 en vecteurs numériques pour l'algorithme de Machine Learning. Dans notre cas, c'est le Machine Learning Elastic qui s'occupera d'effectuer cette conversion en valeurs numériques. C'est ce qu'on appelle l'encodage. Le Machine Learning examinera également les fonctionnalités et sélectionnera celles qui véhiculent le plus d'informations.
Création d'une tâche avec Data Frame Analytics
La prochaine étape consiste à utiliser l'interface utilisateur Data Frame Analytics pour créer une tâche de classification. J'ai mis en évidence certains aspects de cette procédure dans les captures d'écran ci-dessous.
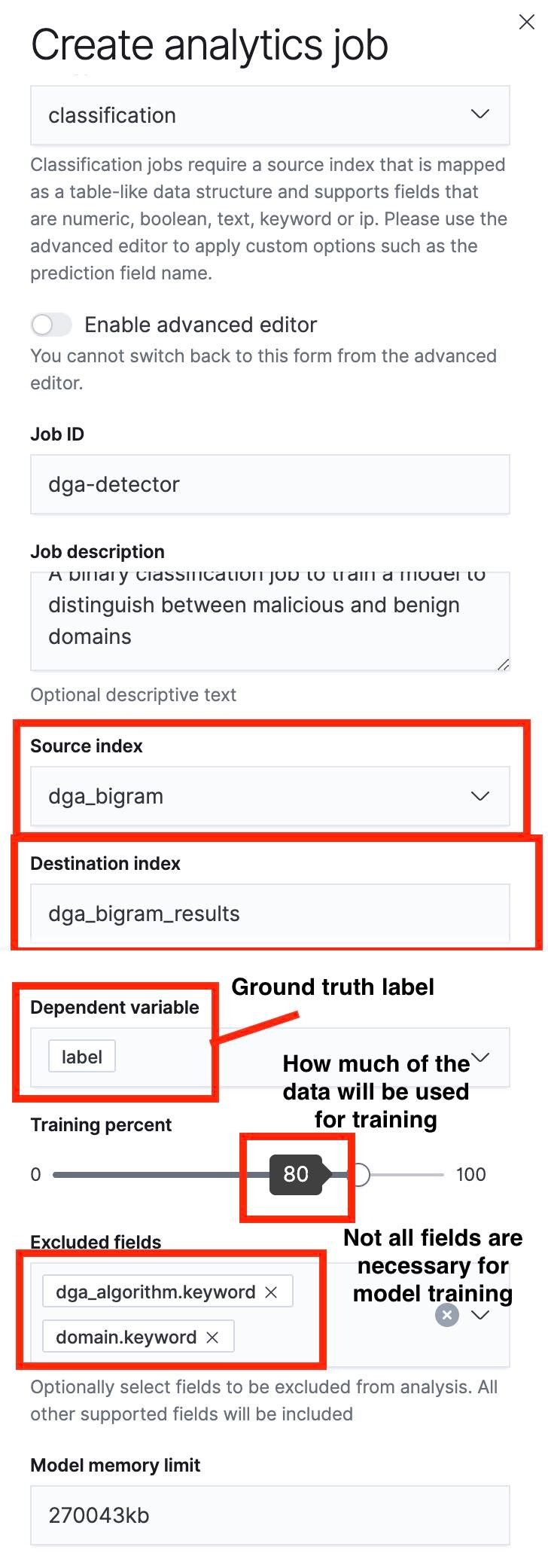
Un point important à faire remarquer : nous pouvons définir un fractionnement entraînement/test à l'aide du curseur. Dans la figure 5, le fractionnement entraînement/test est de 80 %, ce qui veut dire que 80 % des documents contenus dans l'index source serviront à entraîner le modèle, tandis que les 20 % restants seront utilisés aux fins de test.
Une fois le processus d'entraînement terminé, nous pouvons naviguer jusqu'à l'interface utilisateur contenant les résultats de Data Frame Analytics afin d'évaluer les performances du modèle. Étant donné que nous fractionnons notre index source en deux ensembles, un pour l'entraînement et un pour le test, nous pourrons voir les performances du modèle sur chacun d'eux. Les performances en matière d'entraînement et en matière de test offrent des informations précieuses. Dans le cas présent, ce qui nous intéresse particulièrement, ce sont les performances du modèle avec l'ensemble de test. Celles-ci nous donneront en effet une idée de l'erreur de généralisation du modèle. Cette erreur indique la façon dont le modèle traitera des points de données qu'il n'a jamais rencontrés auparavant.
Évaluation d'un modèle de Machine Learning
Une fois l'entraînement terminé, nous pouvons cliquer pour afficher les résultats dans la page de gestion des tâches de l'interface utilisateur de Machine Learning Elastic.
La page des résultats (figure 6) nous donne deux informations précieuses : une "confusion matrix" (matrice de confusion), qui récapitule les performances de notre modèle, et un tableau de résultats, que nous pouvons examiner pour déterminer comment le modèle a classé les points de données. Pour basculer de la matrice de confusion au tableau récapitulatif des ensembles d'entraînement et de test (et vice-versa), il suffit d'utiliser les filtres correspondants en haut à droite du tableau.
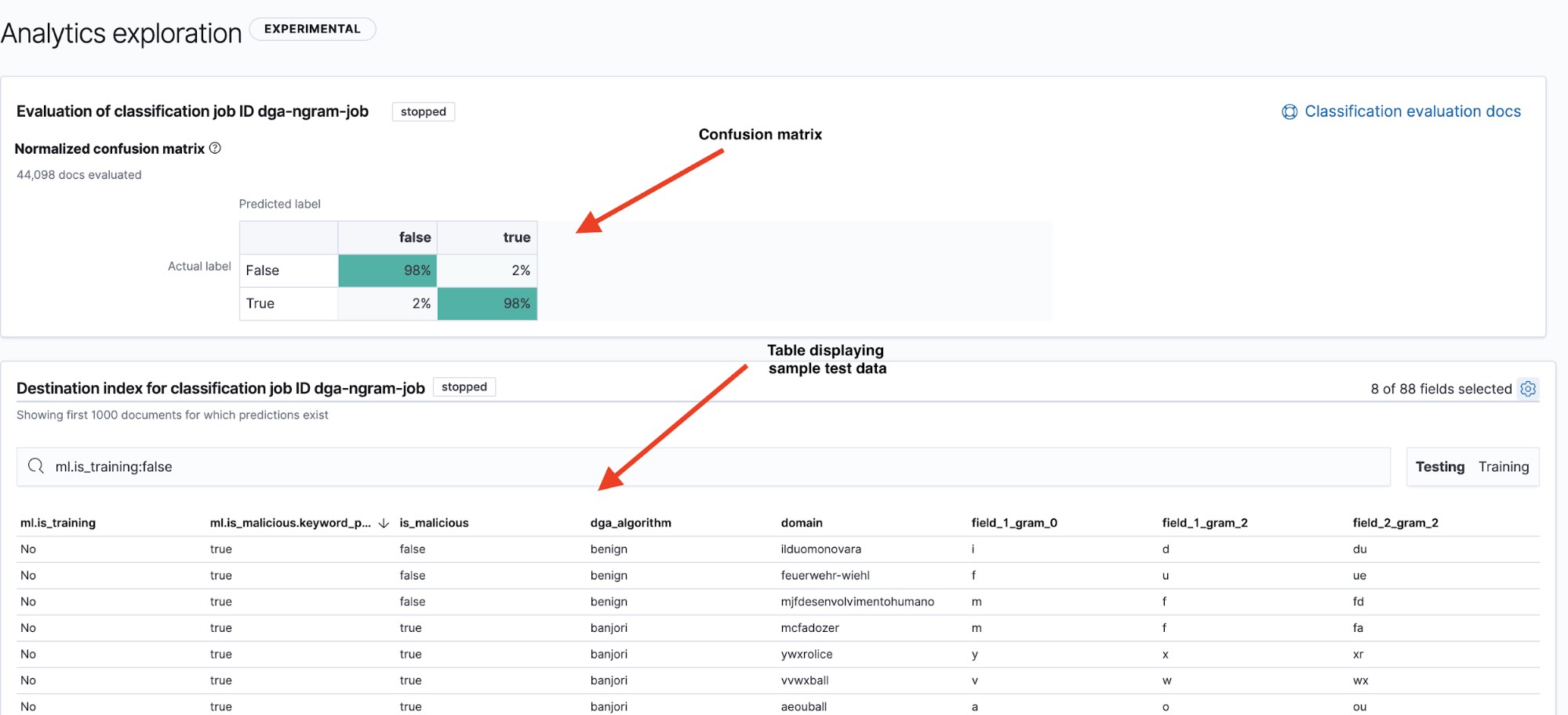
Pour voir les performances d'un modèle, une méthode courante consiste à utiliser une visualisation connue sous le nom de matrice de confusion. Cette matrice affiche le pourcentage des points de données classés comme true positives (vrais positifs, c'est-à-dire les domaines malveillants que le modèle a identifié comme tels et qui sont réellement malveillants) et comme true negatives (vrais négatifs, c'est-à-dire les domaines sans risques que le modèle a identifié comme tels), ainsi que le pourcentage des documents pour lesquels le modèle a confondu un domaine sans risques avec un domaine malveillant (false positives, les faux positifs) ou inversement (false negatives, les faux négatifs).
Comme son nom l'indique, la matrice de confusion nous montrera rapidement si un modèle confond régulièrement les deux types de domaines.
Dans la figure 6, nous constatons que notre modèle a un taux de vrais positifs de 98 % sur les données de test. Cela signifie que, si nous déployions ce modèle en production pour classer les données DNS entrantes, nous devrions nous attendre à un taux de faux positifs d'environ 2 %. Même si ce chiffre paraît relativement faible, si on l'applique à l'énorme volume de trafic DNS, nous aurions un taux d'alertes qui resterait plutôt élevé. Dans le second article de la série, nous allons voir comment la détection des anomalies peut nous aider à réduire le nombre d'alertes dues à des faux positifs.
Conclusion
Dans cet article de blog, nous avons vu comment utiliser le Machine Learning Elastic pour créer et évaluer un modèle de Machine Learning afin de détecter les DGA. Nous avons étudié la procédure d'extraction des fonctionnalités à partir des domaines malveillants et sans risques, et expliqué brièvement comment identifier des fonctionnalités appropriées. Pour finir, nous avons vu comment entraîner et évaluer un modèle de Machine Learning à l'aide de la Suite Elastic.
Dans le second article de la série, nous expliquerons comment utiliser les processeurs d'inférence dans les pipelines d'ingestion pour déployer ce modèle afin d'enrichir les données Packetbeat entrantes avec des prédictions sur le caractère malveillant des domaines. Et nous verrons également comment utiliser la détection des anomalies pour réduire le nombre d'alertes dues à des faux positifs. En attendant, profitez-en pour essayer gratuitement nos fonctionnalités de Machine Learning et voir quelles informations exploitables vous pouvez dégager lorsque vous réussissez à nager dans votre océan de données.