Mise en place d’une architecture hot-warm-cold avec la gestion du cycle de vie des index
REMARQUE : Il n'est plus recommandé de mettre en œuvre des architectures hot-warm-cold avec des attributs de nœuds comme expliqué dans ce document (par exemple, -Enode.attr.data=hot). Les niveaux de données Data #tiers ont formalisé ce concept en utilisant le paramètre "node.roles" (par exemple, node.roles: ["data_hot", "data_content"]). Pour en savoir plus à ce sujet, lisez l'article https://www.elastic.co/blog/elasticsearch-data-lifecycle-management-with-data-tiers.
Si vous avez déjà mis en œuvre une architecture hot-warm-cold avec des attributs de nœuds, il est recommandé d'adopter le paramètre node.roles pour les niveaux de données, puis de migrer vers l'API de niveaux de données ou de convertir manuellement la configuration (c'est-à-dire les modèles, les paramètres et les politiques de gestion du cycle de vie des index) afin d'utiliser les préférences en matière de niveaux de données.
En outre, ce document fait référence aux modèles d'index existants (comme PUT _template) et à la nécessité de démarrer un index. Les modèles d'index existants ont été remplacés par des modèles d'index composables (comme PUT /_index_template). Si vous utilisez les flux de données, il est inutile de démarrer l'index.
La gestion du cycle de vie des index (ILM) est une fonctionnalité qui a été introduite dans Elasticsearch 6.6 (version bêta), puis mise à disposition dans 6.7. Elle fait partie intégrante d’Elasticsearch et a pour but de vous aider à gérer vos index.
Dans cet article de blog, nous allons voir comment mettre en place une architecture hot-warm-cold à l’aide de la fonctionnalité ILM. L’utilisation d’architectures hot-warm-cold est courante pour les données temporelles comme le logging ou les indicateurs. Par exemple, supposons qu’Elasticsearch serve à agréger les fichiers log de différents systèmes. Les logs d’aujourd’hui sont en cours d’indexation, tandis que les logs de cette semaine sont les plus recherchés (hot). Les logs de la semaine dernière peuvent également faire l’objet d’une recherche, mais pas de manière aussi récurrente que ceux de la semaine en cours (warm). Les logs du mois dernier, quant à eux, peuvent être ou ne pas être consultés très souvent (cold). Néanmoins, il est judicieux de les conserver à portée.
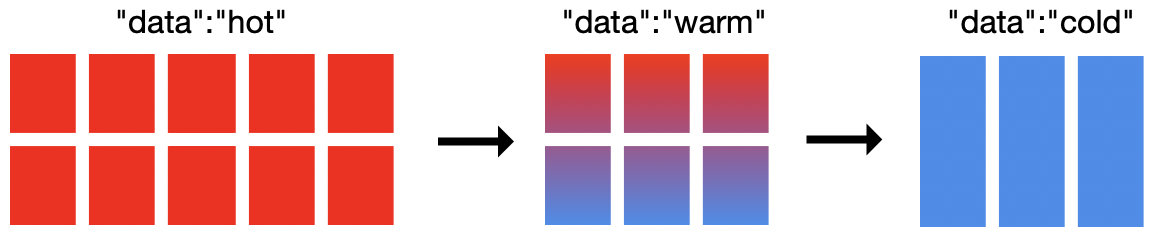
Dans l’illustration ci-dessus, il y a 19 nœuds dans le cluster : 10 nœuds hot, 6 nœuds warm et 3 nœuds cold. Vous n’avez pas besoin d’utiliser 19 nœuds pour mettre en place une architecture hot-warm-cold avec la fonctionnalité ILM, mais vous devez en avoir au moins deux. Le dimensionnement de votre cluster dépend de vos besoins. Les nœuds cold sont facultatifs. Ils ajoutent simplement un niveau de plus où placer vos données dans votre modèle. Elasticsearch vous permet de définir quels nœuds sont hot, warm ou cold. Avec la fonctionnalité ILM, vous déterminez quand passer d’une phase à l’autre et ce qu’il faut faire de l’index quand il entre dans une nouvelle phase.
Il n’y a pas d’architecture hot-warm-cold "standard". Toutefois, les utilisateurs souhaitent généralement disposer d’un plus grand nombre de ressources CPU ainsi que d’E/S plus rapides pour les nœuds hot. Les nœuds warm et cold nécessitent habituellement plus d’espace disque par nœud, mais fonctionnent néanmoins avec un nombre plus restreint de ressources CPU et des E/S plus lentes.
Maintenant, entrons dans le vif du sujet.
Configuration des opérations d’allocation des partitions
Une architecture hot-warm-cold s’appuie sur des opérations d’allocation des partitions. Nous commençons donc par baliser les nœuds en fonction de leur nature : hot, warm et cold (s’il y en a). Pour cela, nous utilisons des paramètres de démarrage ou le fichier de configuration elasticsearch.yml. Par exemple :
bin/elasticsearch -Enode.attr.data=hot
bin/elasticsearch -Enode.attr.data=warm
bin/elasticsearch -Enode.attr.data=cold
(Si vous utilisez Elasticsearch Service sur Elastic Cloud, vous devrez choisir le modèle hot/warm avec Elasticsearch 6.7+)
Configuration d’une politique ILM
Ensuite, nous devons définir une politique ILM. Une politique ILM peut être réutilisée sur autant d’index que vous le souhaitez. Elle se compose de quatre phases principales : hot, warm, cold et suppression. Vous n’êtes pas obligé de définir chacune de ces phases dans une politique. Sachez cependant que la fonction ILM exécutera systématiquement les phases dans cet ordre, en ignorant celles qui ne sont pas définies. Pour chaque phase, vous devrez déterminer le moment auquel y passer et sélectionner un ensemble d’actions appropriées pour gérer vos index. Pour des architectures hot-warm-cold, vous pouvez configurer l’action d’allocation pour déterminer quand faire passer vos données des nœuds hot à des nœuds warm, et des nœuds warm à des nœuds cold.
Il y en a bien d’autres ! La substitution sert à gérer la taille ou l’ancienneté de chaque index. La fusion forcée peut servir à optimiser vos index. Le gel permet de réduire la pression en termes de mémoire dans le cluster. Voici quelques exemples parmi d’autres. Pour en savoir plus sur les autres actions disponibles, consultez la documentation correspondant à votre version d’Elasticsearch.
Politique ILM de base
Jetons un œil à une politique ILM très basique :
PUT /_ilm/policy/my_policy
{
"policy":{
"phases":{
"hot":{
"actions":{
"rollover":{
"max_size":"50gb",
"max_age":"30d"
}
}
}
}
}
}
D’après cette politique, il est nécessaire de substituer l’index et de commencer à en écrire un nouveau au bout de 30 jours ou lorsque l’index atteint une taille de 50 Go.
ILM et modèles d’index
Ensuite, nous devons associer cette politique ILM avec un modèle d’index :
PUT _template/my_template
{
"index_patterns": ["test-*"],
"settings": {
"index.lifecycle.name": "my_policy",
"index.lifecycle.rollover_alias": "test-alias"
}
}
Remarque : Lors d’une substitution, il est impératif d’indiquer une politique ILM dans le modèle d’index (et non pas directement dans l’index).
Pour les politiques incluant l’action de substitution, vous devez également démarrer l’index avec un alias d’écriture après avoir créé le modèle d’index.
PUT test-000001
{
"aliases": {
"test-alias":{
"is_write_index": true
}
}
}
En partant du principe que toutes les exigences sont respectées en ce qui concerne la substitution, alors tout nouvel index commençant par test-* se verra automatiquement substituer après 30 jours ou s’il atteint 50 Go. L’utilisation d’index gérés par substitution avec max_size peut réduire dans une large mesure le nombre de partitions (et donc la surcharge).
Configuration d’une politique ILM pour une ingestion
Beats et Logstash prennent en charge la fonctionnalité ILM qui, une fois activée, définira une politique par défaut similaire à celle présentée dans l’exemple ci-dessus. Beats et Logstash prendront également en charge toutes les exigences applicables à la substitution. Concrètement, cela signifie que, lorsque la fonctionnalité ILM sera activée pour Beats et Logstash, le facteur principal pour déterminer à quel moment créer un index sera probablement la taille (ce qui représente un atout), à moins que vous ne disposiez au quotidien d’index volumineux (> 50 Go/jour). À compter de la version 7.0.0, la fonctionnalité ILM avec substitution sera proposée par défaut pour Beats et Logstash.
Toutefois, étant donné qu’il n’y a pas d’architecture hot-warm-cold standard, Beats et Logstash ne disposeront pas de politiques adaptées. Nous pouvons établir une nouvelle politique qui fonctionne pour l’architecture hot-warm-cold et y apporter des optimisations au fur et à mesure.
Nous pourrions mettre à jour la politique par défaut de Beats et Logstash. Néanmoins, cela créerait une confusion entre les éléments par défaut et les éléments personnalisés. Par ailleurs, le fait de mettre à jour la politique par défaut augmenterait le risque que les versions futures n’aient pas la bonne politique appliquée (les paramètres par défaut du modèle Beats changent à partir de 7.0+). Nous pourrions nous servir des configurations de Beats et Logstash pour définir des politiques personnalisées qui leur seraient propres. Ce serait une possibilité, par contre, vous n’aurez probablement pas envie de vous embêter à changer la configuration pour des centaines (voire des milliers) de Beats pour modifier la politique ILM. La troisième approche décrite ici s’appuie sur la correspondance entre plusieurs modèles pour permettre à Elasticsearch de garder un contrôle complet sur la politique ILM.
Optimisation de votre politique ILM pour une architecture hot-warm-cold
Tout d’abord, créons une politique ILM qui soit optimisée pour une architecture hot-warm-cold. Comme nous l’avons déjà indiqué, il n’y a pas d’architecture standard et vos besoins peuvent être différents.
PUT _ilm/policy/hot-warm-cold-delete-60days
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size":"50gb",
"max_age":"30d"
},
"set_priority": {
"priority": 50
}
}
},
"warm": {
"min_age": "7d",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"shrink": {
"number_of_shards": 1
},
"allocate": {
"require": {
"data": "warm"
}
},
"set_priority": {
"priority": 25
}
}
},
"cold": {
"min_age": "30d",
"actions": {
"set_priority": {
"priority": 0
},
"freeze": {},
"allocate": {
"require": {
"data": "cold"
}
}
}
},
"delete": {
"min_age": "60d",
"actions": {
"delete": {}
}
}
}
}
}
Hot
Dans cette politique ILM, nous commencerons par définir la priorité des index sur une valeur élevée pour que les index hot soient restaurés avant les autres index. Après 30 jours ou une fois la taille de 50 Go atteinte (selon ce qui survient en premier), une substitution aura lieu et un nouvel index sera créé. Ce nouvel index appliquera la politique depuis le début, et l’index en cours (celui venant d’être substitué) attendra jusqu’à sept jours pour passer à la phase warm, le temps que la substitution soit complète.
Warm
Lorsque l’index est en phase warm, la fonctionnalité ILM réduit l’index à une partition, effectue une fusion forcée de l’index en un segment, définit la priorité de l’index sur une valeur inférieure à celle d’un index hot (mais supérieure à celle d’un index cold) et transfère l’index aux nœuds warm grâce à l’action d’allocation. Une fois toutes ces actions effectuées, l’index attend 30 jours (après sa substitution) avant de passer en phase cold.
Cold
Une fois l’index en phase cold, la fonctionnalité ILM abaisse davantage la priorité de l’index pour garantir que les index hot et warm soient restaurés en premier. Elle gèle ensuite l’index et le transfère vers les nœuds cold. Une fois toutes ces actions effectuées, l’index attend 60 jours (après sa substitution) avant de passer en phase de suppression.
Suppression
Nous n’avons pas encore abordé la phase de suppression. Mais elle est très simple ! C’est la phase où l’action de suppression est réalisée pour supprimer l’index. Une durée minimale, min_age, vous permettra de déterminer le temps pendant lequel votre index restera dans la phase hot, warm ou cold avant d’être supprimé.
Création d’une politique ILM depuis Kibana
Vous n’avez pas envie d’écrire un pavé en JSON ? Ça tombe bien, moi non plus ! Utilisons l’interface utilisateur Kibana pour étudier ou créer la politique :
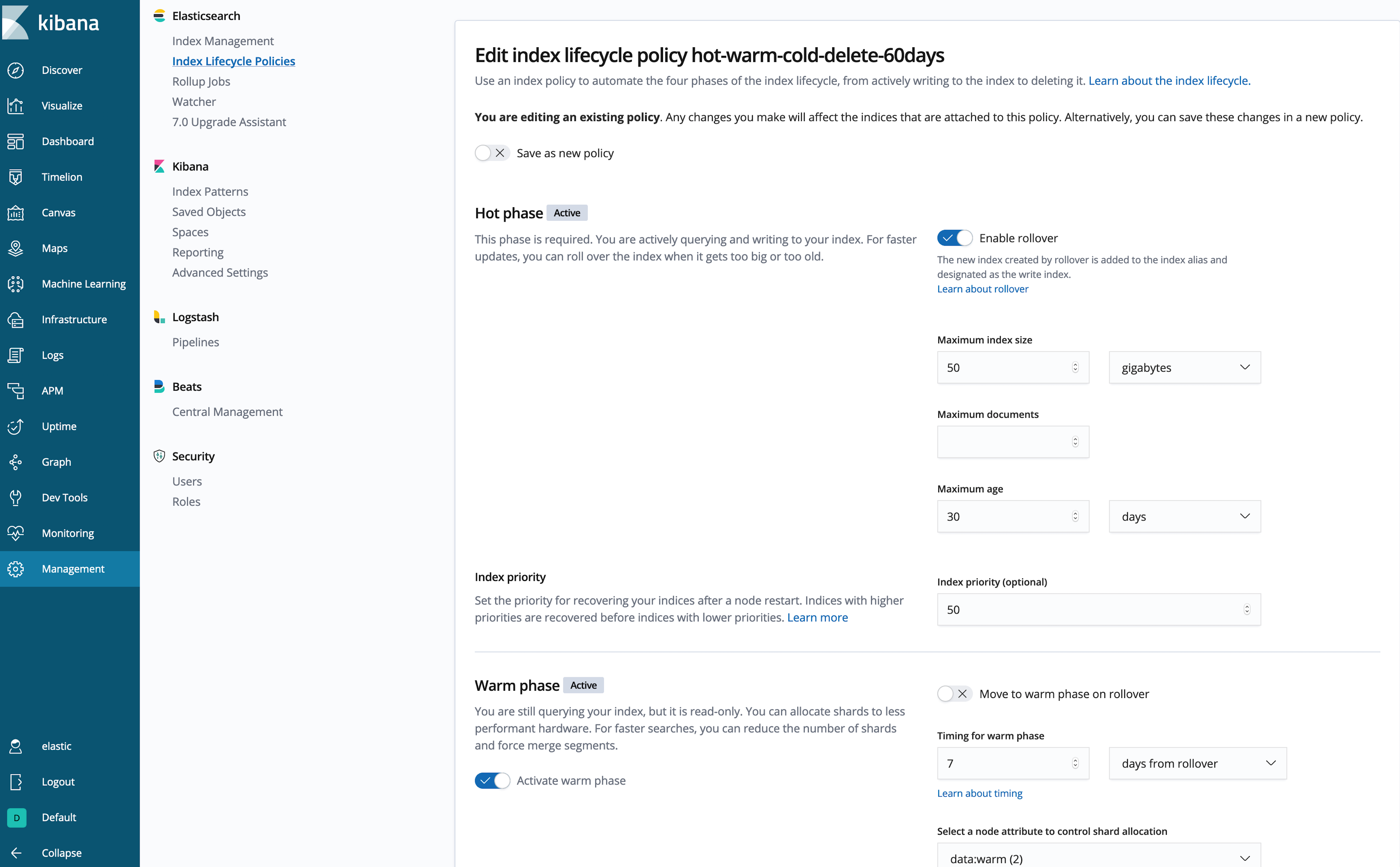 C’est mieux !
C’est mieux !
Maintenant, nous devons associer la nouvelle politique hot-warm-cold-delete-60days aux index Beats et Logstash, et nous assurer qu’ils écrivent dans les nœuds de données hot. Étant donné que Beats et Logstash gèrent tous deux (par défaut) leurs propres modèles, nous nous servirons de la correspondance entre plusieurs modèles pour ajouter les règles de politique et d’allocation aux modèles d'indexation que vous souhaitez appliquer à la politique ILM. Comme ce modèle correspond aux modèles d'indexation Beats et Logstash, vous devez déterminer les modèles d'indexation avec lesquels effectuer la correspondance. Dans notre cas, nous utilisons logstash-, metricbeat- et filebeat-*. Mais vous pouvez en ajouter autant que vous le souhaitez, en supposant que la fonction ILM soit activée pour Beats et Logstash dans leur configuration. Si vous ajoutez ici des modèles d'indexation pour les générateurs de données qui ne prennent pas en charge la fonctionnalité ILM, vous devrez intervenir manuellement pour que les exigences soient respectées dans le cadre de la substitution pour cette politique.
PUT _template/hot-warm-cold-delete-60days-template
{
"order": 10,
"index_patterns": ["logstash-*", "metricbeat-*", "filebeat-*"],
"settings": {
"index.routing.allocation.require.data": "hot",
"index.lifecycle.name": "hot-warm-cold-delete-60days"
}
}
Activation de la fonctionnalité ILM dans Beats et /ou Logstash
Pour terminer, activons la fonctionnalité ILM pour Beats et Logstash.
Pour Beats 6.7 :
output.elasticsearch:
ilm.enabled: true
Pour Logstash 6.7 :
output {
elasticsearch {
ilm_enabled => true
}
}
Veuillez consulter la documentation correspondant à la version dont vous disposez pour savoir comment activer la fonctionnalité dans Beats et Logstash étant donné que cette procédure peut être différente dans les versions plus récentes.
À présent, tout nouvel index correspondant au modèle d'indexation créera de nouveaux index sur les nœuds hot et la fonctionnalité ILM appliquera la politique hot-warm-cold-delete-60days.
Mise à jour de votre politique ILM
Vous pouvez mettre à jour la politique ILM à tout moment… Néanmoins, les modifications que vous apporterez à la politique seront appliquées uniquement au changement de phase. Par exemple, si votre index se trouve actuellement en phase hot (et attend de passer en phase warm), les éventuelles modifications que vous aurez apportées pendant la phase hot ne seront pas appliquées à cet index. En revanche, les modifications que vous aurez apportées à la phase warm entreront en vigueur dès qu’il entrera dans la phase warm. Ceci, pour éviter de répéter les actions pour une phase donnée. Vous pouvez consulter l’état de l’ILM de l’index avec l’API d’explication.
La plupart des informations préalables concernant la mise en place d’une architecture hot-warm avant ILM restent valables étant donné qu’elle utilise la même mécanique sous-jacente. Toutefois, avec l’ILM, Curator n’est plus nécessaire pour obtenir ce modèle.
Et pour la suite ?
À compter de la version 7.0, Beats et Logstash utilisent la gestion du cycle de vie des index par défaut lorsqu’ils se connectent à un cluster qui prend cette fonction en charge. Beats a également fait évoluer la majorité des paramètres ILM de l’espace de nom output.elasticsearch.ilm à l’espace de nom setup.ilm. Par exemple, consultez la documentation sur Filebeat 7.0. Également à compter de la version 7.0, les index système comme .watcher-history-* peuvent être gérés par la fonctionnalité ILM.
La fonctionnalité ILM facilite la mise en place d’une architecture abordable, de type hot-warm-cold, pour vos index temporels. Essayez-la aujourd’hui, et dites-nous ce que vous en pensez sur nos forums de discussion. Bonne découverte !