Création d'un tableau de bord personnalisé de rapport des incidents ServiceNow dans Canvas
Au risque de nous répéter, bienvenue... encore ! Nous allons attaquer la 3e et dernière partie de cette série d'articles sur la gestion des incidents avec la Suite Elastic et ServiceNow. Dans le premier article, nous avons présenté le projet et configuré ServiceNow de sorte que les modifications apportées à un incident soient automatiquement envoyées à Elasticsearch. Dans le deuxième article, nous avons implémenté la logique nécessaire pour "coller" ServiceNow et Elasticsearch au moyen d'alertes et de transformations, et nous avons procédé à la configuration générale d'Elasticsearch.
À ce stade, tout est fonctionnel. Mais il nous manque un élément : un tableau de bord pratique (et joli) que nous utiliserons pour la gestion des incidents ! Dans cet article, nous allons voir comment créer la présentation Canvas ci-dessous. Le but : exploiter toute la valeur que nous avons à notre disposition en la rendant facile à comprendre et à utiliser.
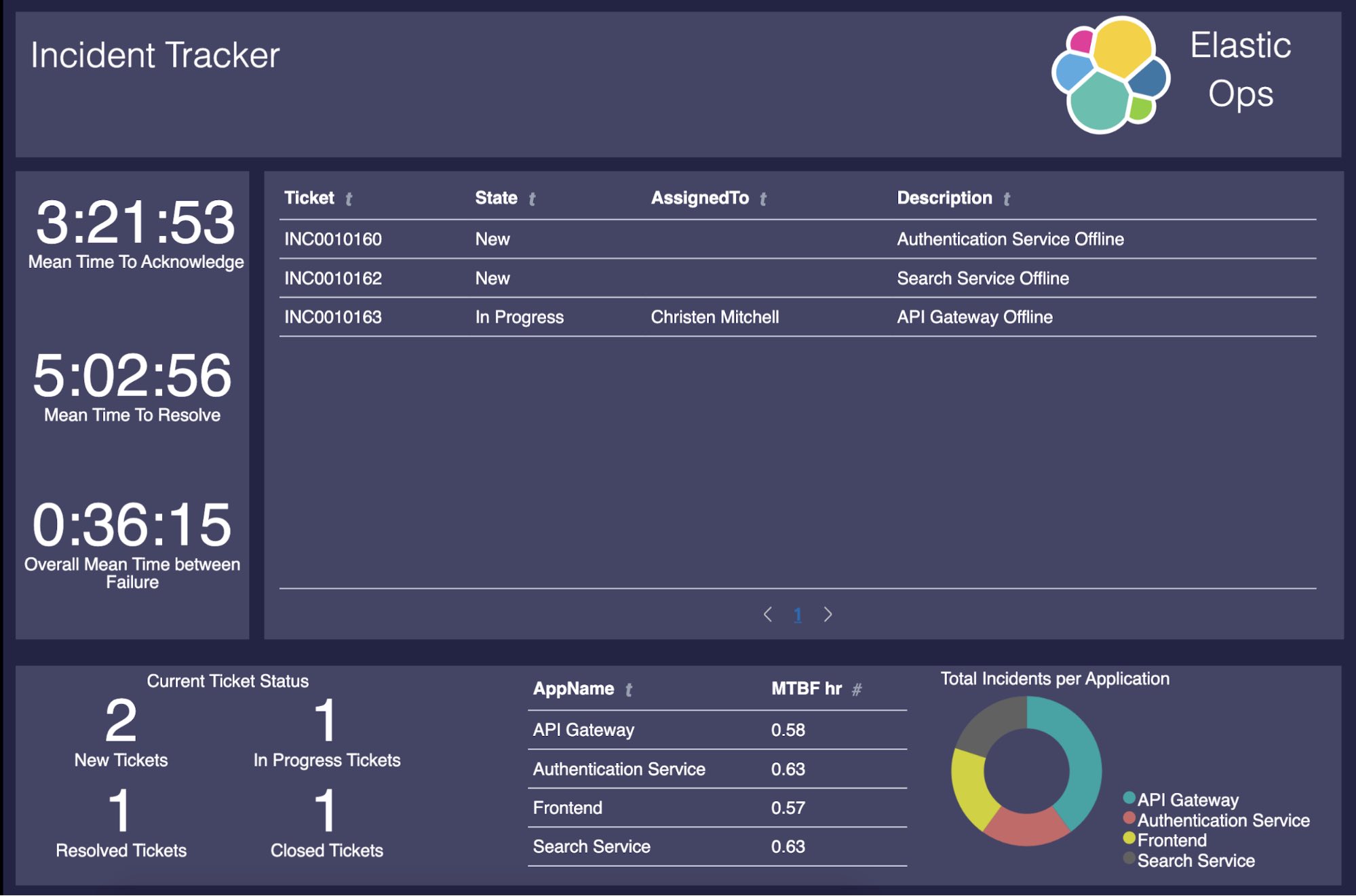
Voilà ce que nous allons afficher dans notre tableau de bord :
- Des tickets ouverts, clôturés, résolus et en cours
- Le MTTA des incidents
- Le MTTR des incidents
- Le MTBF général
- Le MTBF d'application
- Le nombre d'incidents par application
Entrons dans le vif du sujet.
Configuration d'une présentation Canvas
Dans cet article, nous allons recourir très souvent aux expressions Canvas, car elles sous-tendent les différents éléments d'une présentation. Cela sera le moyen le plus simple de vous montrer comment recréer des fonctionnalités.
À noter : si vous n'avez aucune donnée dans les index centrés sur les entités que les transformations remplissent, certains des éléments ci-dessous afficheront un message d'erreur du type "Table de données vide".
Avant de commencer, ouvrons Canvas :
- Développez la barre d'outils Kibana.
- Si vous utilisez la version 7.8 ou supérieure, vous pourrez accéder à Canvas directement sous Kibana. Sinon, cet outil sera indiqué dans la liste de toutes les autres icônes.
- Cliquez sur le bouton Create Workpad (Créer une présentation).
- Une fois la présentation créée, donnez-lui un nom. Pour cela, accédez à Workpad Settings (Paramètres de la présentation), à droite. Appelons-la "Incident Tracker". C'est également dans les paramètres que nous définirons la couleur de l'arrière-plan dans les étapes suivantes.
- Pour modifier l'expression Canvas d'un composant donné, cliquez sur ce composant, puis sur Expression editor (Éditeur d'expression ) en bas à droite.
Configuration du thème
La première étape dans la création de notre présentation Canvas est de définir l'apparence de l'arrière-plan :
- Définissez la couleur de l’arrière-plan sur #232344.
- Créez quatre rectangles, puis définissez leur couleur de remplissage sur #444465.
- Dans le rectangle supérieur, ajoutez le logo (par exemple celui de l'entreprise), le nom de l'entreprise et un titre.
Fonctionnement des tickets
Maintenant, nous devons créer le tableau du milieu, qui montrera le fonctionnement des tickets. Pour cela, nous allons utiliser une combinaison d'expressions Elasticsearch SQL et Canvas, ainsi qu'un élément "table de données". Pour créer un élément "table de données", copiez l'expression Canvas suivante dans l'éditeur, puis exécutez-la :
filters
| essql
query="SELECT incidentID as Ticket, LAST(state, updatedDate) as State, LAST(assignedTo, updatedDate) as AssignedTo, LAST(description, updatedDate) as Description FROM \"servicenow*\" group by Ticket ORDER BY Ticket ASC"
| filterrows fn={getCell "State" | any {eq "New"} {eq "On Hold"} {eq "In Progress"}}
| table
font={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="left" color="#FFFFFF" weight="normal" underline=false italic=false} paginate=true perPage=10
| render
Dans cette expression, nous exécutons la recherche, puis nous filtrons toutes les lignes, sauf celles dont le champ State (État) est défini sur "New" (Nouveau), "On Hold" (En suspens) ou "In Progress" (En cours).
Dans le cas présent, nous n'obtiendrons probablement aucun résultat car nous n'avons aucune donnée. En effet, notre règle métier n'a sans doute pas été exécutée. Il n'y a donc aucune donnée ServiceNow dans Elasticsearch. Si vous le souhaitez, vous pouvez créer ici quelques faux incidents. Veillez toutefois à avoir des tickets à des stades différents pour que la table paraisse réaliste.
Calcul du temps moyen de reconnaissance (MTTA)
Pour obtenir le MTTA d'un incident, nous allons ajouter un élément "indicateur" et utiliser l'expression Canvas ci-dessous.
filters
| essql
query="SELECT * FROM (SELECT incidentID, updatedDate, state FROM \"servicenow-incident-updates\") PIVOT (MIN(updatedDate) FOR state IN ('New' as New, 'In Progress' as \"InProgress\"))"
| mapColumn "New" fn={getCell "New" | formatdate "X" | math "value"}
| mapColumn "InProgress" fn={getCell "InProgress" | formatdate "X" | math "value"}
| filterrows fn={getCell "InProgress" | gt 0}
| mapColumn "Duration" expression={math expression="InProgress - New"}
| math "mean(Duration)"
| metric "Mean Time To Acknowledge"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="00:00:00"
| render
Cette expression utilise des fonctions Elasticsearch SQL plus avancées, notamment la fonction PIVOT. Pour calculer le MTTA, nous déterminons la durée totale qui s'écoule entre la création et la reconnaissance, puis nous divisons cette durée par le nombre d'incidents. Nous devons utiliser la fonction PIVOT car nous stockons chaque mise à jour apportée à un ticket dans ServiceNow. Cela signifie qu'à chaque fois qu'un utilisateur met à jour l'état, les notes de travail, l'utilisateur à qui la tâche est attribuée, etc., cette mise à jour est envoyée à Elasticsearch. C'est là un atout de taille lorsque l'on souhaite analyser les résultats. Nous devons donc pivoter les données de sorte à obtenir une ligne par incident, qui indique la première fois où l'incident a été "New" (Nouveau), et la première fois où il est passé à "In Progress" (En cours).
À partir de là, nous pouvons donc calculer le temps de reconnaissance en soustrayant l'heure à laquelle l'incident a été créé de l'heure à laquelle l'incident a été reconnu. Le MTTA est calculé en effectuant la moyenne de cette fonction de champ de durée.
Calcul du temps moyen de résolution (MTTR)
Pour obtenir le MTTR d'un incident, nous allons ajouter un élément "indicateur" et utiliser l'expression Canvas ci-dessous :
filters
| essql
query="SELECT * FROM (SELECT incidentID, updatedDate, state FROM \"servicenow-incident-updates\") PIVOT (MIN(updatedDate) FOR state IN ('New' as New, 'Resolved' as \"Resolved\"))"
| mapColumn "New" fn={getCell "New" | formatdate "X" | math "value"}
| mapColumn "Resolved" fn={getCell "Resolved" | formatdate "X" | math "value"}
| filterrows fn={getCell "Resolved" | gt 0}
| mapColumn "Duration" expression={math expression="Resolved - New"}
| math "mean(Duration)"
| metric "Mean Time To Resolve"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="00:00:00"
| render
Comme pour le MTTA, nous utilisons la fonction PIVOT car nous devons étudier une vue récapitulative de chaque incident. Néanmoins, la différence ici est que nous obtenons l'heure à laquelle nous voyons un état pour la première fois lorsque celui-ci est nouveau ET résolu. C'est parce que le MTTR est le temps moyen nécessaire à la résolution d'un ticket. Il a de grandes similitudes avec le MTTA, mais nous n'allons pas y revenir pour ne pas perdre de temps.
Calcul du temps moyen global entre les défaillances (MTBF)
Maintenant que nous connaissons le MTTA et le MTTR, il est temps de calculer le MTBF de chaque application. Pour cela, nous allons nous servir de deux transformations : app_incident_summary_transform and calculate_uptime_hours_online_transfo. Avec ces transformations, il est très simple de calculer le MTBF global. Étant donné que le MTBF est mesuré en heures et que notre transformation le calcule en secondes, nous calculons la moyenne sur l'ensemble des applications, puis nous multiplions le résultat par 3 600 (c.-à-d. le nombre de secondes dans une heure).
Créons maintenant un autre élément "indicateur" en utilisant l'expression Canvas ci-dessous :
filters
| essql query="SELECT AVG(mtbf) * 3600 as MTBF FROM app_incident_summary"
| math "MTBF"
| metric "Overall Mean Time between Failure"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="00:00:00"
| render
Calcul du temps moyen entre les défaillances (MTBF) d'une application
Maintenant que nous avons calculé le MTBF global, nous pouvons facilement déterminer le MTBF de chaque application. Pour cela, il nous suffit de créer un nouvel élément "table de données" et afficher les données dans une table à l'aide de l'expression Canvas suivante. Pour faciliter la lecture, nous avons arrondi le MTBF de chaque application à deux décimales.
filters
| essql
query="SELECT app_name as AppName, ROUND(mtbf,2) as \"MTBF hr\" FROM app_incident_summary"
| table paginate=false
font={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="left" color="#FFFFFF" weight="normal" underline=false italic=false}
| render
Calcul des tickets résolus
Ce que nous avons envie de voir, ce sont des réussites. Nous veillerons donc à intégrer un nombre de tickets "clôturés" dans notre présentation. Il s'agit d'un élément "indicateur" simple qui regroupe tous les incidents dont l'état est "Resolved" (Résolu). La fonction mathématique compte ensuite le nombre d'ID uniques d'incidents.
filters
| essql query="SELECT state,incidentID FROM \"servicenow*\" where state = 'Resolved'"
| math "unique(incidentID)"
| metric "Resolved Tickets"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="0,0.[000]"
| render
Calcul du nombre d'incidents par application
Maintenant, nous allons créer un graphique en anneau qui compte le nombre d'incidents uniques par application. Nous recommandons d'ajouter un élément Markdown au-dessus de ce graphique, avec le texte "Nombre total d'incidents par application", pour apporter du contexte.
filters
| essql
query="SELECT incidentID as IncidentCount, app_name as AppName FROM \"servicenow*\""
| pointseries color="AppName" size="unique(IncidentCount)"
| pie hole=41 labels=false legend="se" radius=0.72
palette={palette "#01A4A4" "#CC6666" "#D0D102" "#616161" "#00A1CB" "#32742C" "#F18D05" "#113F8C" "#61AE24" "#D70060" gradient=false} tilt=1
font={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="left" color="#FFFFFF" weight="normal" underline=false italic=false}
| render
Calcul du statut des tickets en cours
Cette section se compose de quatre éléments "indicateur". Les expressions Canvas de ces éléments se ressemblent beaucoup et ne comportent que de légères différences. En gros, nous allons récupérer la dernière mise à jour des incidents, puis nous allons nous servir de la fonction d'expression Canvas "filterrows" pour ne garder que les incidents qui nous intéressent en fonction de leur statut. Ainsi, nous compterons simplement le nombre d'incidents uniques.
Utilisez l'expression ci-dessous et mettez l'état à jour selon vos souhaits. Par ailleurs, pensez à mettre à jour le texte de l'indicateur.
filters
| essql
query="SELECT incidentID, LAST(state, updatedDate) as State FROM \"servicenow*\" group by incidentID" count=1000
| filterrows fn={getCell "State" | eq 'New'}
| math "unique(incidentID)"
| metric "New Tickets"
metricFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=48 align="center" color="#FFFFFF" weight="normal" underline=false italic=false}
labelFont={font family="'Open Sans', Helvetica, Arial, sans-serif" size=14 align="center" color="#FFFFFF" weight="normal" underline=false italic=false} metricFormat="0,0.[000]"
| render
Produit fini
Maintenant que nous avons créé les différents éléments de notre présentation Canvas, nous obtenons ce tableau de bord de gestion des incidents extrêmement utile :
À vous de jouer maintenant !
Et voilà ! Notre aventure touche à sa fin. Nous avons utilisé un certain nombre de composants de la Suite Elastic pour calculer le MTTA, le MTTR et le MTBF en fonction des incidents ServiceNow, puis nous avons présenté ces informations de manière pertinente dans un joli tableau de bord. Ce qu'il faut retenir ici, c'est que ces informations évoluent en parallèle de vos données réelles, et non pas dans un autre outil. Ces indicateurs posent des bases que l'on peut exploiter pour comprendre l'intégrité d'une application par rapport aux incidents rapportés. Par exemple, si le MTBF est très faible, cela signifie que votre application échoue très souvent. Si le MTTA est élevé, cela signifie qu'il faut beaucoup de temps avant que l'étude d'un échec ne démarre.
Si vous n'avez pas eu l'occasion de tester cette procédure par vous-même lors de la lecture de cet article, nous vous recommandons de vous retrousser les manches et de mettre la main à la pâte. Vous pouvez essayer gratuitement Elastic Cloud et l'utiliser conjointement avec votre instance de ServiceNow ou avec une instance de développeur personnelle.
De plus, si vous souhaitez effectuer une recherche parmi les données de ServiceNow avec d'autres sources comme GitHub, Google Drive, etc., Elastic Workplace Search possède un connecteur ServiceNow intégré. Workplace Search vous offre une expérience de recherche unifiée pour vos équipes, avec des résultats pertinents dans l'ensemble des sources de contenu. Et la bonne nouvelle, c'est qu'il est inclus dans votre essai Elastic Cloud.
Cet article vous apporte les bases pour utiliser vos données afin de surveiller ces indicateurs. Si vous souhaitez approfondir le sujet, vous pouvez par exemple créer des incidents en fonction de vos logs, de vos indicateurs d'infrastructure, de vos traces APM et de vos anomalies de Machine Learning. Pour apporter davantage de valeur aux utilisateurs de tableau de bord Canvas, vous pouvez ajouter des liens vers les applications dans Kibana (Logs, APM, etc.) ou vers vos propres tableaux de bord pour leur donner des idées sur la façon de découvrir la cause première du problème auquel ils sont confrontés.
Si cette série d'articles vous a plu, voici quelques liens qui peuvent vous intéresser :
- Quand utiliser des transformations de données
- Premiers pas avec le Machine Learning
- Canvas, ou l'art de raconter des histoires visuelles dans Kibana
- Utilisation des éléments Metric et Markdown de Canvas pour ajouter des liens
Bonne découverte !