

 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Pourquoi s'agit-il d'une anomalie ? Pourquoi le score n'est-il pas plus élevé ? La détection des anomalies est une fonctionnalité de Machine Learning très précieuse qui est utilisée dans Elastic Security et Elastic Observability. Mais les scores qui en ressortent peuvent paraître confus. Si seulement quelqu'un pouvait les traduire en langage clair. Ou même les représenter sous forme de dessin...
Dans Elastic 8.6, nous affichons plus de détails sur les anomalies enregistrées. Ces détails permettent de comprendre ce qui se cache derrière l'algorithme d'attribution des scores.
Nous avons déjà abordé l'attribution des scores des anomalies et la normalisation dans d'autres articles. L'algorithme de détection des anomalies analyse la série temporelle des données de manière chronologique. Il identifie les tendances et les schémas périodiques sur différentes échelles de temps, par exemple sur un jour, une semaine, un mois ou une année. En général, les données combinent à la fois des tendances et des schémas périodiques sur différentes échelles de temps. De plus, ce qui peut sembler être au premier abord une anomalie peut s'avérer être un schéma récurrent émergent.
La tâche de détection des anomalies s'accompagne d'hypothèses qui expliquent les données. Elle pondère ces hypothèses et les associe aux preuves fournies. Les hypothèses ne sont ni plus ni moins que des distributions de probabilités. De ce fait, nous pouvons déterminer un intervalle de confiance qui définit la "normalité" des observations. Les observations qui s'écartent de cet intervalle de confiance sont considérées comme anormales.
Facteurs qui influencent le score d'anomalie
Vous vous dites probablement : OK, la théorie est simple, mais comment quantifier le degré d'anormalité lorsque nous sommes confrontés à des comportements inattendus ?
Il y a trois facteurs qui nous permettent de calculer le score d'anomalie initial que nous attribuons aux enregistrements :
- Impact sur un intervalle
- impact sur plusieurs intervalles
- Impact des caractéristiques d'anomalie
Pour rappel, les tâches de détection des anomalies divisent les données temporelles en intervalles de temps. Les données qui se trouvent dans un intervalle sont agrégées à l'aide de fonctions. La détection des anomalies se fait sur les valeurs des intervalles. Pour en savoir plus sur les intervalles et notamment sur l'importance de choisir un intervalle approprié, lisez cet article.
Tout d'abord, pour toute valeur réelle, nous regardons sa probabilité dans l'intervalle en fonction de différentes hypothèses. Cette probabilité dépend du nombre de valeurs similaires que nous avons rencontrées par le passé. Souvent, elle se rapporte à la différence entre la valeur réelle et la valeur type. La valeur type est la valeur médiane de la distribution des probabilités pour un intervalle donné. Cette probabilité conduit à l'impact sur un intervalle. Elle domine généralement le score d'anomalie initial d'un pic court ou d'une baisse courte.
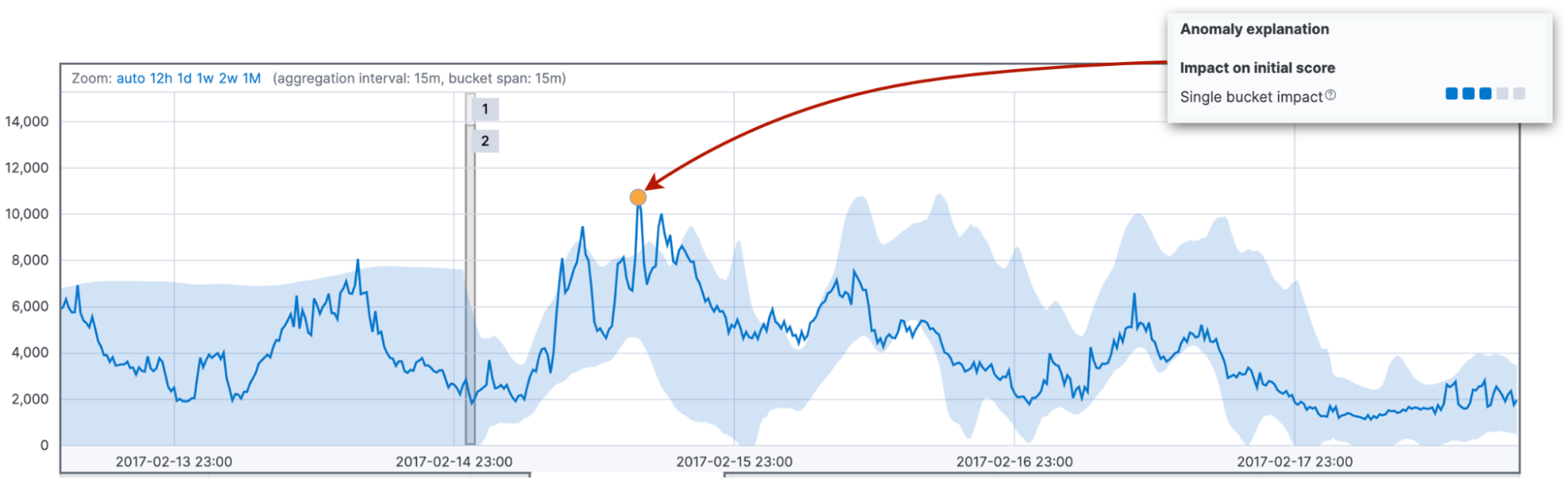
Ensuite, nous examinons les probabilités que nous avons d'observer les valeurs parmi celles de l'intervalle en cours par rapport aux 11 intervalles précédents. Les différences accumulées entre les valeurs réelles et les valeurs types entraînent un impact sur plusieurs intervalles par rapport au score d'anomalie initial de l'intervalle en cours.
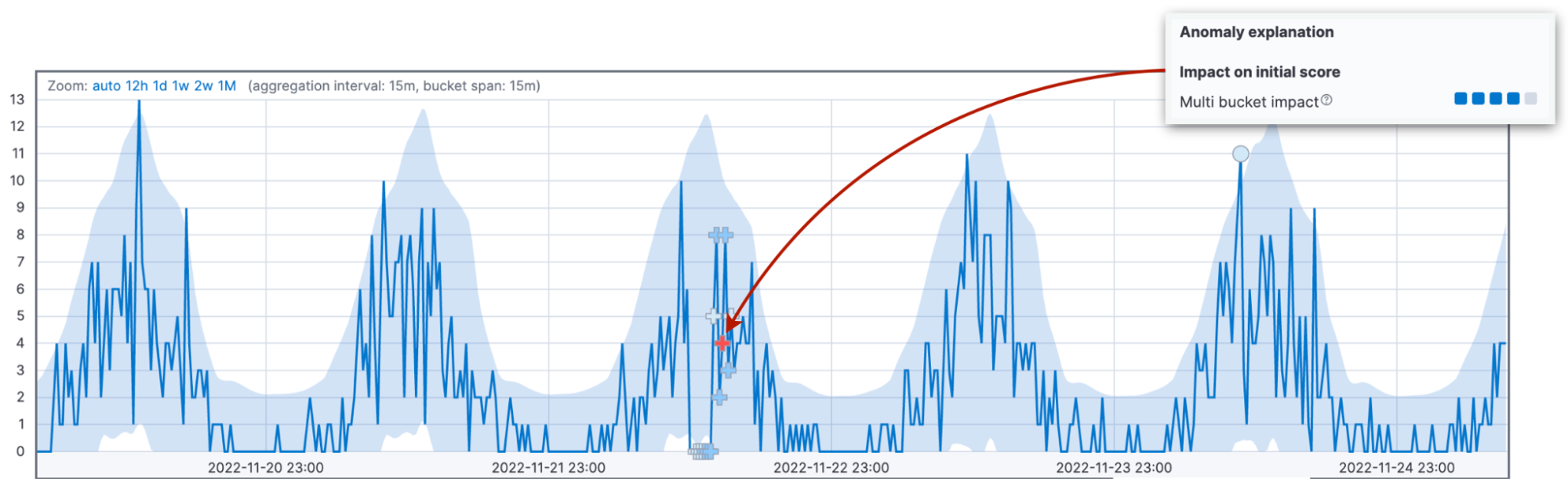
Attardons-nous sur cette notion, étant donné que l'impact sur plusieurs intervalles est la deuxième grande cause de confusion concernant les scores d'anomalie. Nous étudions les écarts rencontrés dans 12 intervalles et attribuons l'impact à l'intervalle en cours. Un impact sur plusieurs intervalles élevé est symptomatique d'un comportement inhabituel dans l'intervalle qui précède l'intervalle en cours. N'oubliez pas que, entre-temps, la valeur de l'intervalle en cours peut être revenue dans l'intervalle de confiance de 95 %.
Pour faire ressortir cette différence, nous utilisons différents marqueurs pour les anomalies ayant un impact sur plusieurs intervalles élevé. Si vous regardez plus attentivement l'anomalie sur plusieurs intervalles qui est illustrée dans la figure ci-dessous, vous verrez qu'elle est marquée d'une croix rouge "+" au lieu d'un cercle.
Enfin, nous considérons l'impact des caractéristiques d'anomalie, comme la longueur et la taille. Ici, nous prenons en compte la durée totale de l'anomalie jusqu'à maintenant, et non pas un intervalle fixe comme ci-dessus. Elle peut concerner un seul intervalle comme elle peut en concerner trente. Le fait de comparer la longueur et la taille de l'anomalie aux moyennes historiques permet de s'adapter au domaine du client et aux schémas des données.
De plus, le comportement par défaut de l'algorithme consiste à attribuer un score plus élevé aux anomalies longues qu'aux pics courts. En pratique, les anomalies courtes sont souvent des bugs dans les données, tandis que les anomalies qui durent traduisent généralement des problèmes que vous devez traiter.
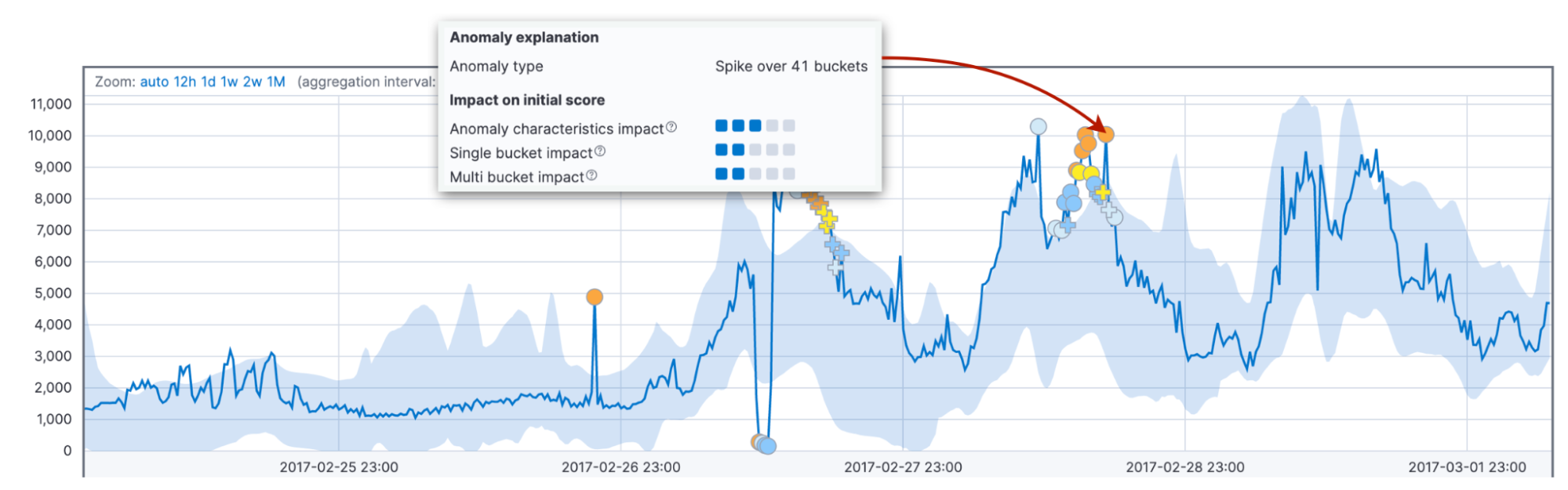
Pourquoi avons-nous besoin de ces facteurs avec des intervalles fixes et variables ? En combinant ces facteurs, vous bénéficiez d'une détection fiable des comportements anormaux sur différents domaines.
Réduction du score d'un enregistrement
L'heure est venue d'aborder la source de confusion la plus courante en ce qui concerne l'attribution des scores : il s'agit de la renormalisation des scores. Les scores d'anomalie sont normalisés dans une fourchette allant de 0 à 100. Les valeurs qui s'approchent de 100 représentent les plus grandes anomalies que la tâche ait rencontrées à ce jour. Concrètement, qu'est-ce que cela implique ? Que, lorsque nous constatons une anomalie plus importante que ce que nous avons vu jusqu'à présent, nous devons réduire les scores des anomalies précédentes.
Les trois facteurs que nous avons vus précédemment influencent la valeur du score d'anomalie initial. Le score initial joue un rôle important, car c'est cette valeur qui servira à alerter l'opérateur en cas d'anomalie. Au fur et à mesure que de nouvelles données arrivent, l'algorithme de détection des anomalies ajuste les scores des anomalies des enregistrements passés. Le paramètre de configuration renormalization_window_days précise l'intervalle de temps pour cet ajustement. De ce fait, si vous vous demandez pourquoi une anomalie extrême affiche un score peu élevé, c'est probablement parce que la tâche a rencontré des anomalies encore plus importantes par la suite.
Dans Kibana 8.6, la visionneuse d'indicateur seul met en évidence ce changement.
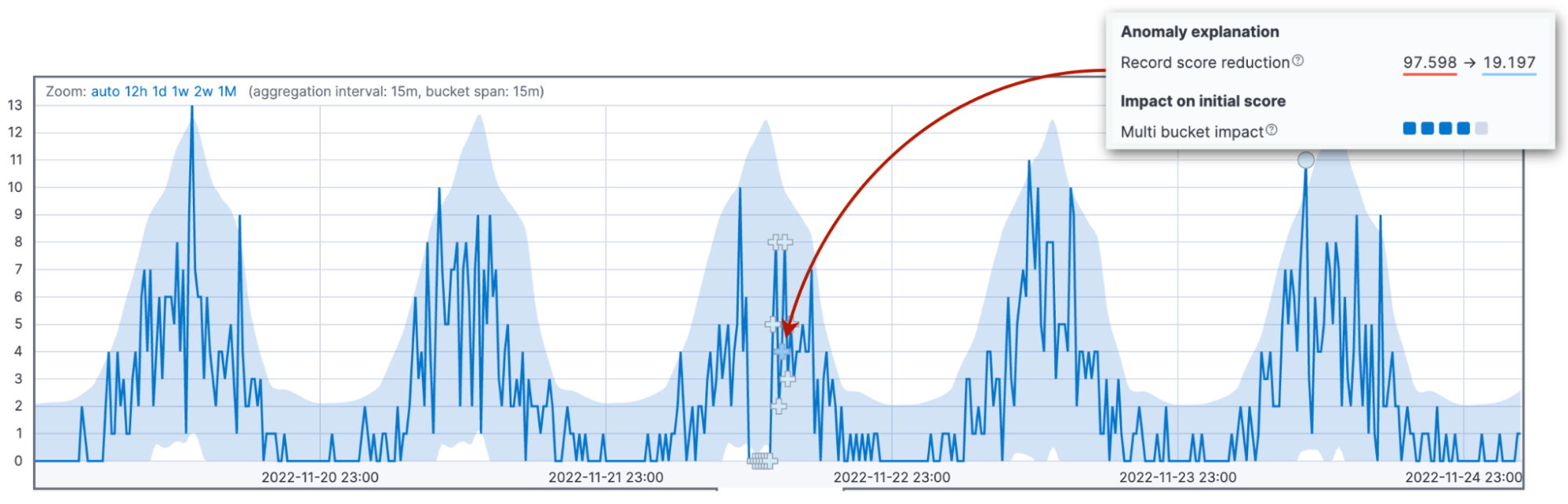
Autres facteurs contribuant à la réduction des scores
Deux autres facteurs peuvent conduire à une réduction du score initial : l'intervalle de variance élevé et l'intervalle incomplet.
La détection des anomalies est moins fiable si l'intervalle en cours fait partie d'un schéma saisonnier dans lequel les données varient énormément. Supposons par exemple que des tâches de maintenance du serveur s'exécutent chaque nuit à minuit. Ces tâches peuvent conduire à une fluctuation importante de la latence du traitement des requêtes.
De façon similaire, la détection sera plus fiable sur l'intervalle en cours si celui-ci a reçu un nombre d'observations similaire à celui attendu par rapport aux enregistrements historiques.
Mise en commun
Souvent, les anomalies réelles découlent de l'impact de plusieurs facteurs. Lorsque tous ces éléments sont mis en commun, la nouvelle vue détaillée de la visionneuse d'indicateur seul ressemble à ce qui suit.
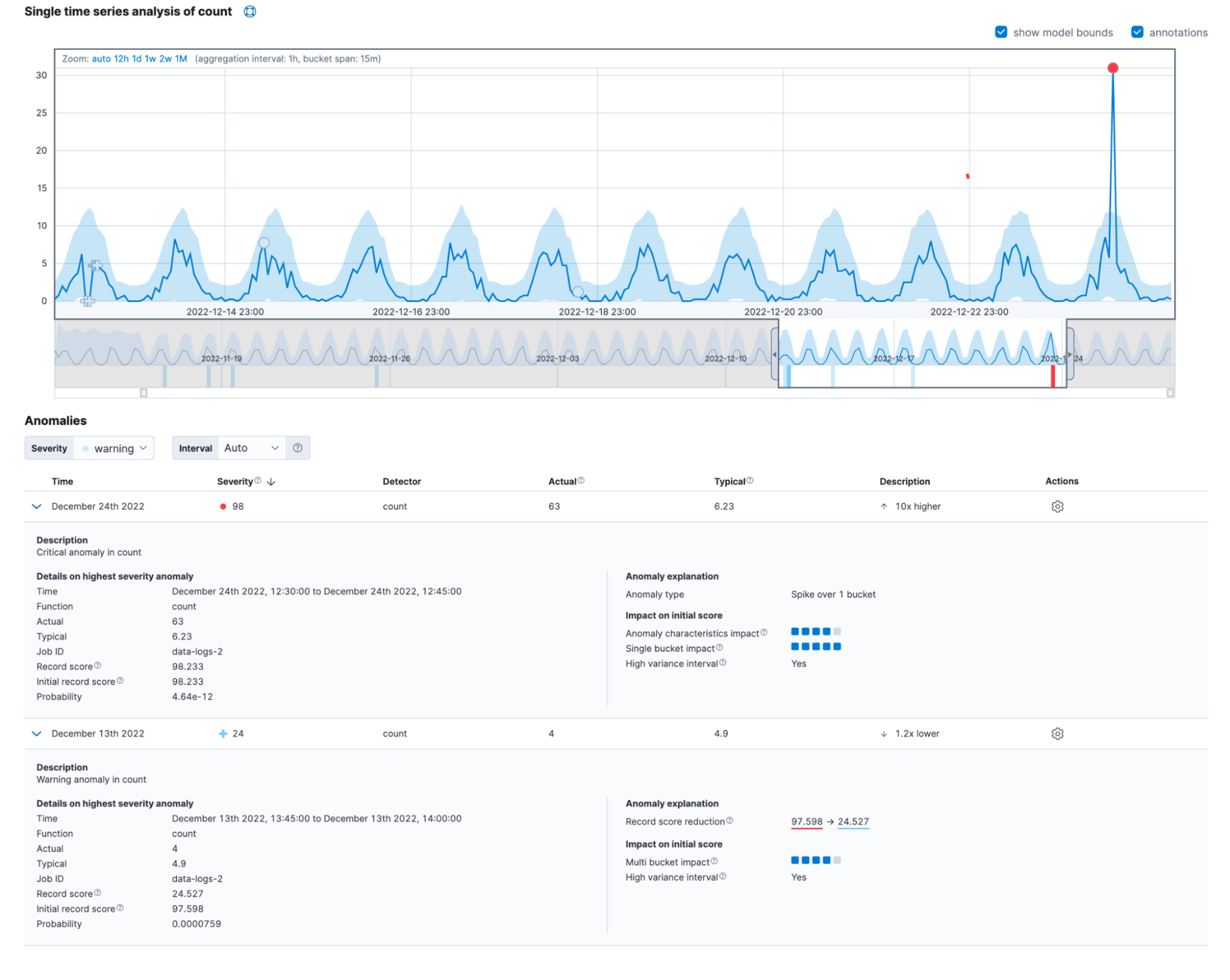
Vous pouvez également retrouver ces informations dans le champ anomaly_score_explanation de l'API get record.
Conclusion
Nous vous invitons à tester la dernière version d'Elasticsearch Service sur Elastic Cloud pour découvrir la nouvelle vue détaillée des enregistrements d'anomalie. Pour accéder à la plateforme, démarrez un essai gratuit d'Elastic Cloud dès aujourd'hui. Bonne expérimentation !
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer
Comment expliquer les scores des anomalies détectées par le Machine Learning Elastic ?