Annotations utilisateur pour le machine learning dans Elastic
Les annotations utilisateur sont une nouvelle fonctionnalité de machine learning dans Elasticsearch, proposées à partir de la version 6.6. Elles permettent de renforcer vos tâches de machine learning à l’aide de connaissances descriptives sur le domaine. Lorsque vous exécutez une tâche de machine learning, son algorithme essaye de repérer les anomalies. Néanmoins, il ne sait rien sur les données en tant que telles. La tâche ne sait pas, par exemple, si elle traite des informations sur l’utilisation du processeur ou sur le débit du réseau. C’est là que les annotations s’avèrent utiles. Elles viennent renforcer les connaissances sur les données, dont vous disposez en tant qu’utilisateur.
Dans cet article, nous allons nous pencher sur le fonctionnement des annotations utilisateur et sur leur application dans différents cas d'utilisation. Nous analyserons des données venant d’Hydro Online, un portail de données libre géré par le gouvernement local du Tyrol en Autriche. Hydro Online propose une interface pour examiner les données issues de capteurs météorologiques, tels que le volume des précipitations, le niveau des rivières ou la quantité de neige. Comme décrit dans l’un de nos articles précédents, File Data Visualizer (Visualiseur de données pour les fichiers) permet d’ingérer les données issues de fichiers CSV, comme c’est le cas ici.
Utilisation
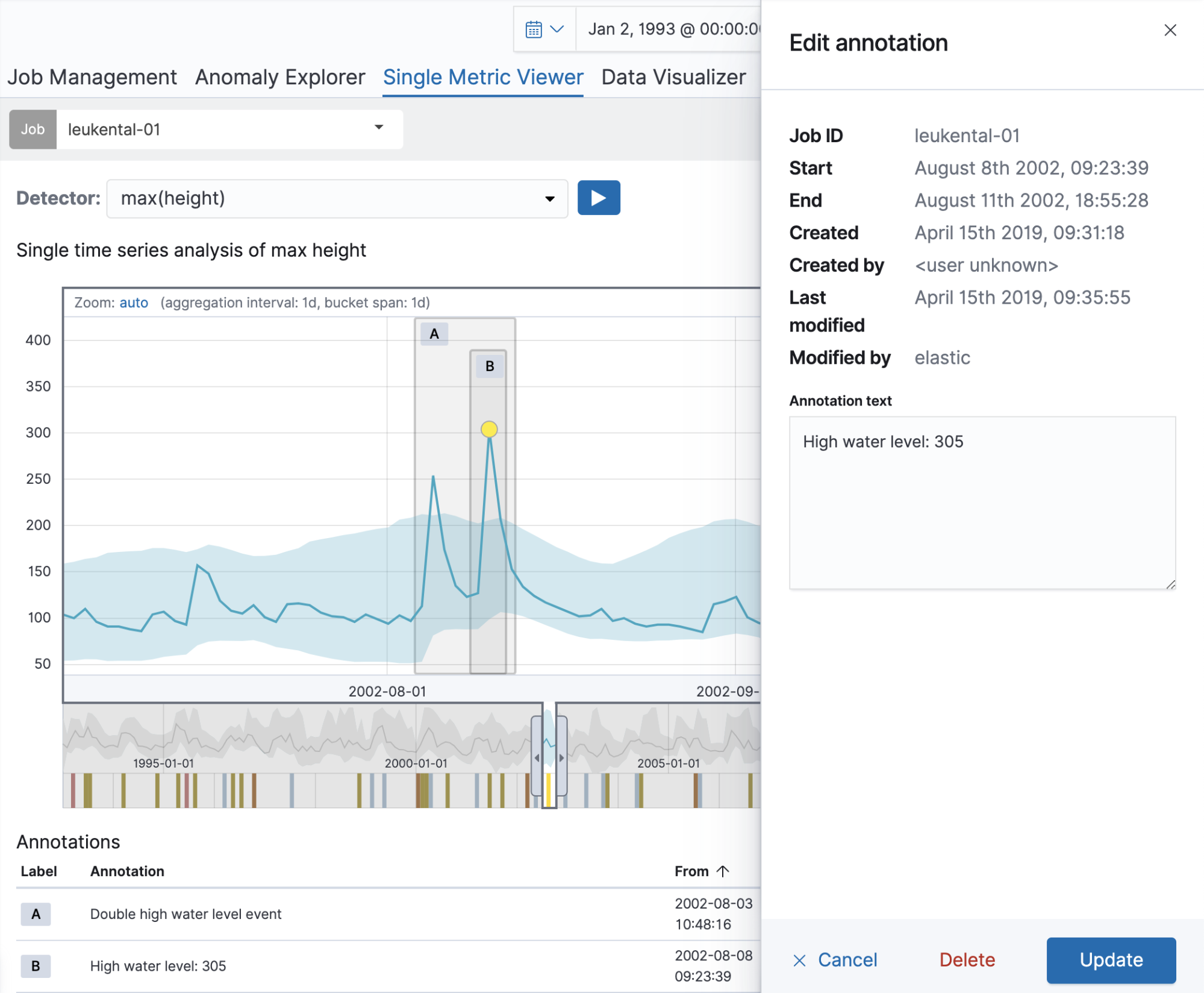
Démarrons avec une tâche à indicateur unique, qui analyse les mesures du niveau de la rivière Grossache qui traverse le village de Kössen. Une fois la tâche créée, Single Metric Viewer peut servir à ajouter des annotations aux résultats de l’analyse. Pour créer une annotation, faites tout simplement glisser une plage de temps dans le graphique. Un élément contextuel s’affiche à droite : vous pouvez y ajouter une description personnalisée. Dans l’exemple ci-dessous, nous créons une annotation pour un niveau inhabituel de la rivière (il y a eu une grave inondation à cette date). Avec cette annotation, vous partagez vos connaissances avec les autres utilisateurs.
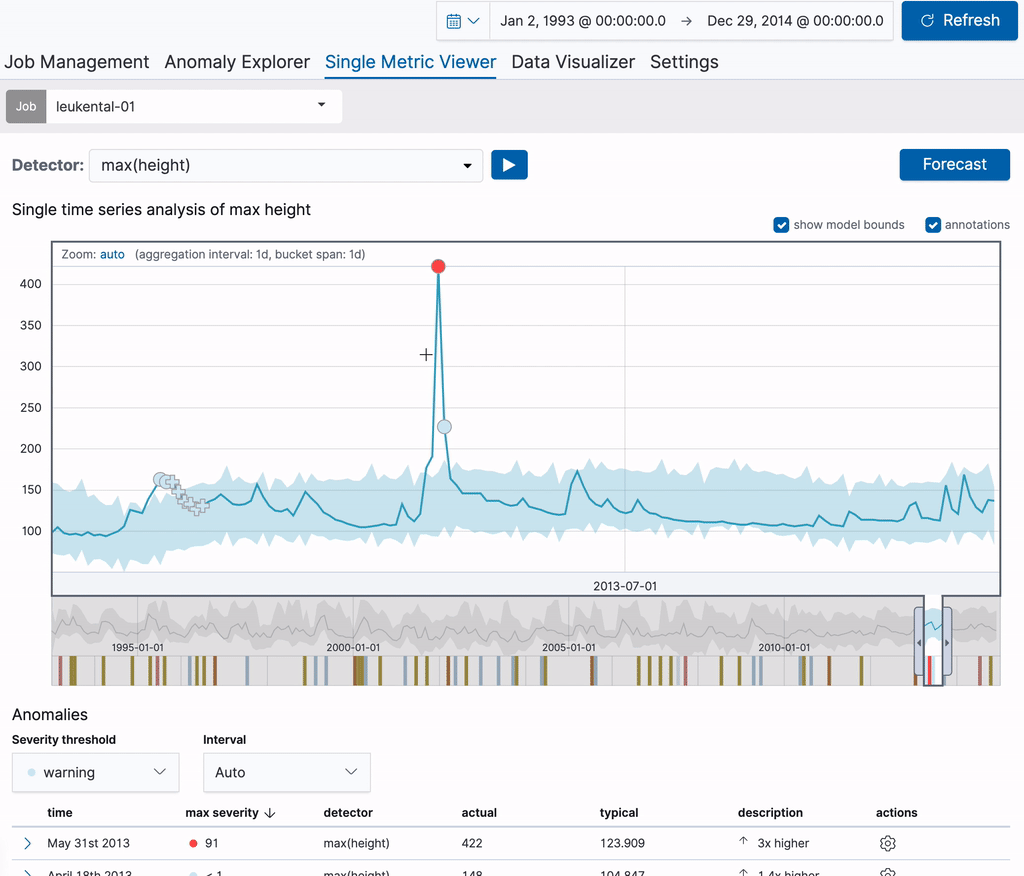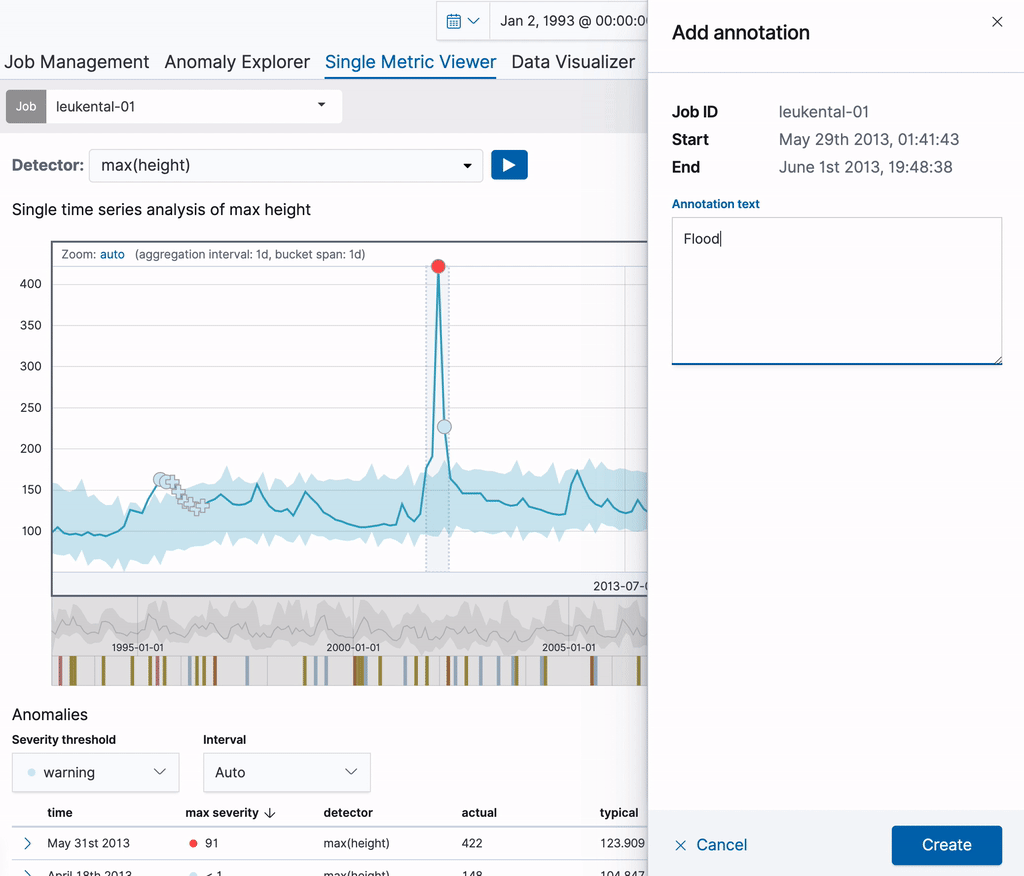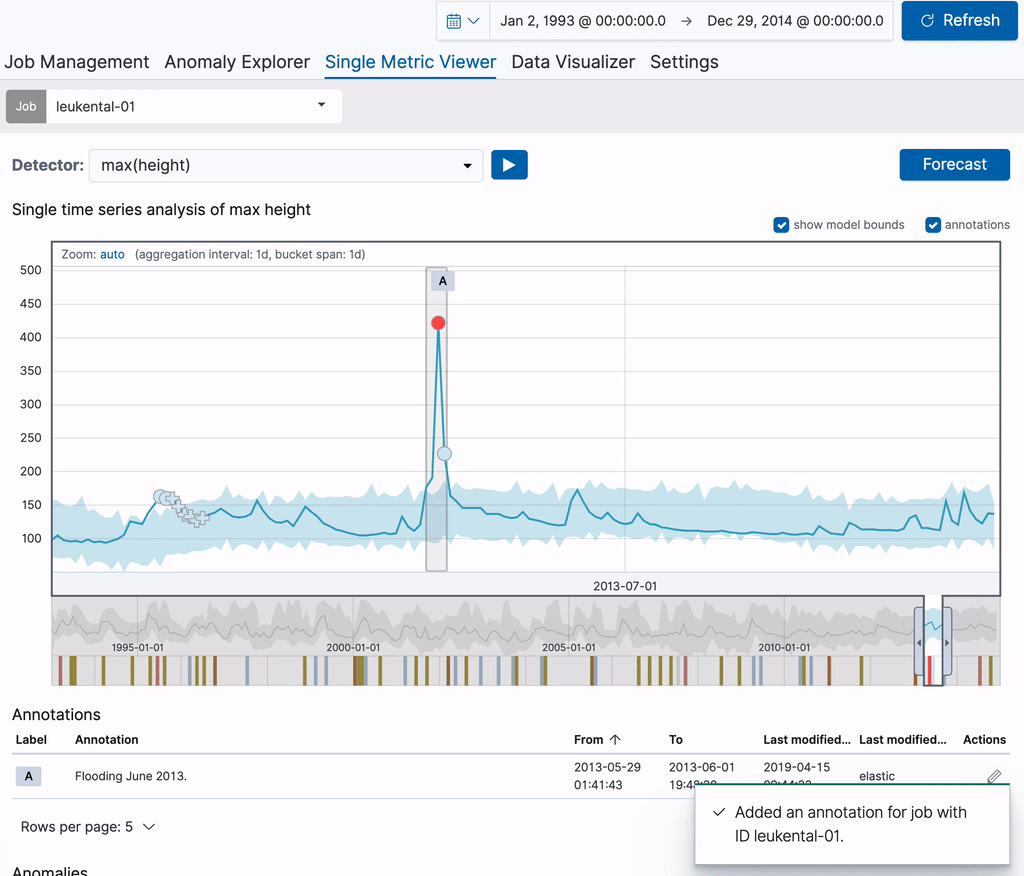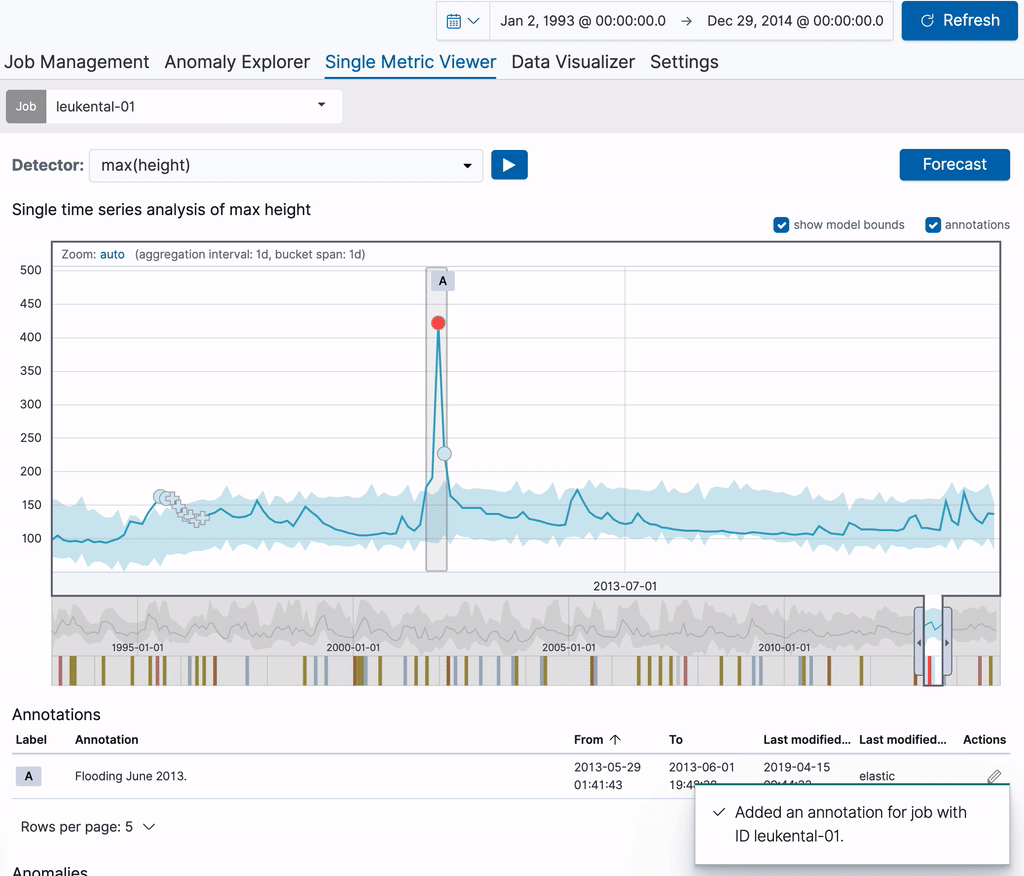
L’annotation est visible directement dans le graphique ainsi que dans le tableau des annotations en dessous. L’étiquette visible dans la première colonne du tableau permet d’identifier l’annotation dans le graphique. Ces étiquettes se créent de façon dynamique pour les annotations affichées. Lorsque vous survolez une ligne dans le tableau des annotations, l’annotation correspondante est mise en surbrillance dans le graphique.
Pour chaque tâche, les annotations créées sont également accessibles sur la page Job Management (Gestion des tâches). Pour cela, il faut développer la ligne correspondante dans la liste des tâches. Chaque annotation du tableau comprend un lien dans la colonne de droite, qui vous renvoie vers Single Metric Viewer, en ciblant la plage de temps couverte par l’annotation. Ces liens permanents peuvent être également partagés avec d’autres utilisateurs. Vous pouvez donc utiliser les annotations pour créer des signets sur des anomalies spécifiques afin d’y revenir ultérieurement.

S’il y a plusieurs annotations pour une même plage de temps, elles seront affichées verticalement dans le graphique pour ne pas se chevaucher. Pour modifier ou supprimer une annotation, cliquez tout simplement dans le graphique. L’élément contextuel s’ouvre à nouveau à droite. Vous pouvez y modifier le texte ou supprimer l’annotation. À partir de la version 6.7, vous pouvez également utiliser le bouton de modification du tableau des annotations. Cette fonctionnalité est disponible aussi sur la page Job Management (Gestion des tâches).
Maintenant que nous avons vu la théorie, passons à la pratique avec quelques cas d'utilisation.
Utilisation des annotations pour vérifier les anomalies prévues
Les annotations peuvent servir de référence pour vérifier si une tâche de machine learning génère les résultats attendus. Dans l’exemple suivant, nous étudions là encore les données sur le niveau de la rivière fournies par Hydro Online. Notre objectif est de superposer les événements historiques sous forme d’annotations dans les résultats des anomalies. En tant que data scientist, par exemple, vous pouvez être amené à recueillir et à préparer les données source que vous souhaitez analyser ainsi que l’ensemble de données pour vérifier les résultats.
Dans le cadre de notre analyse, nous avons besoin de l’ensemble de données intégral.
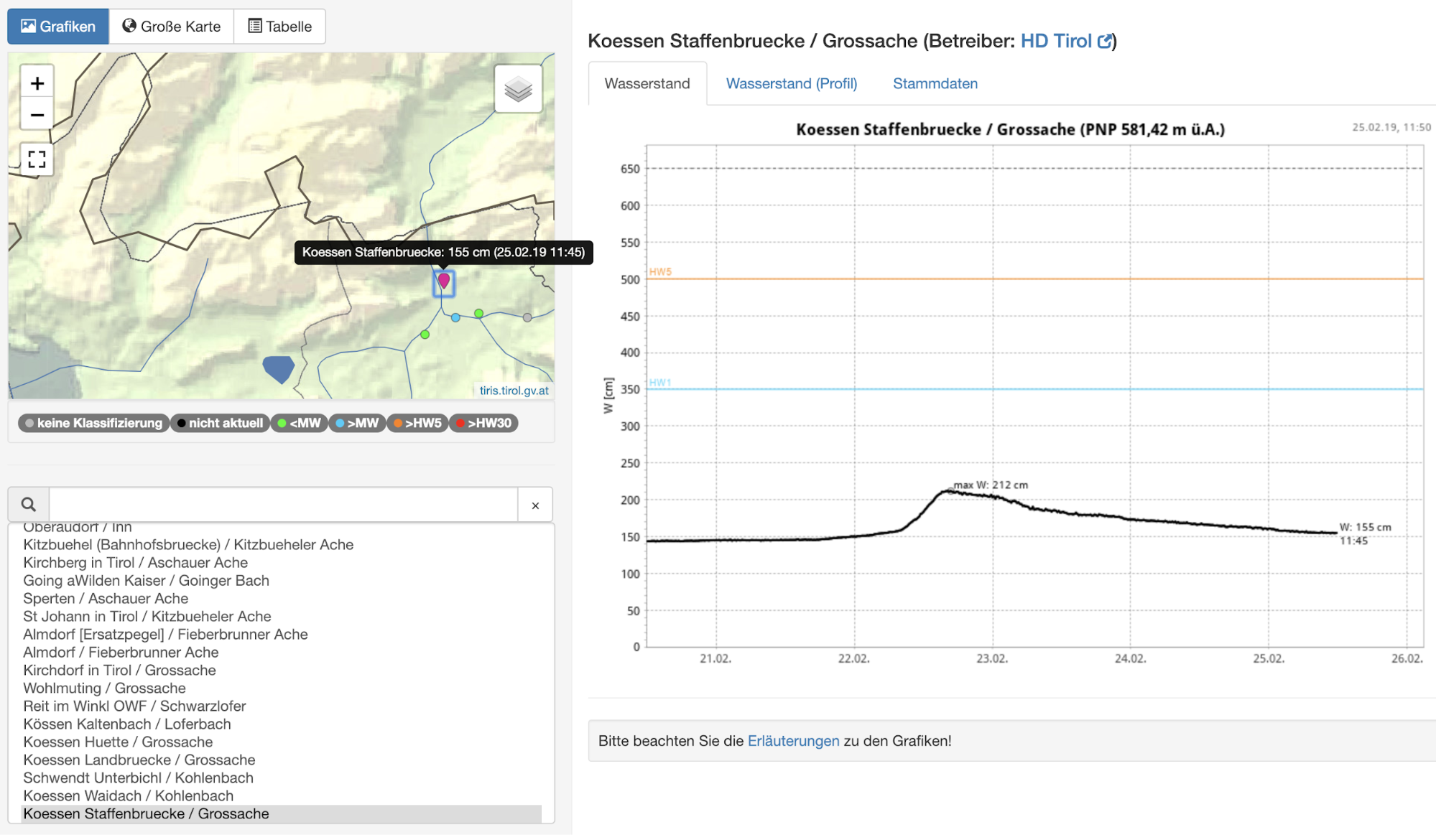
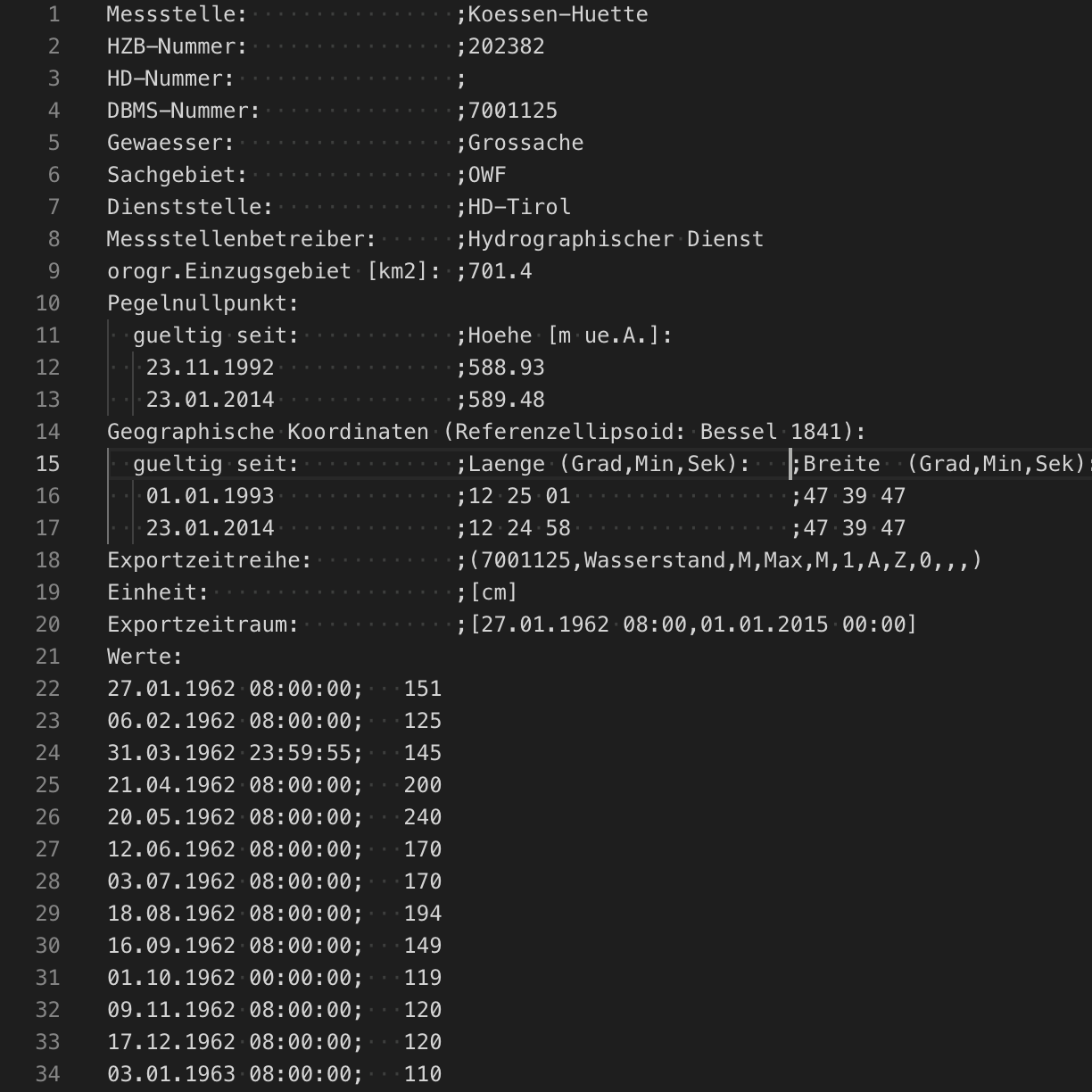
Heureusement, dans notre cas, en plus de pouvoir travailler sur les données via l’interface web, nous pouvons aussi télécharger les données historiques pour approfondir notre analyse. Pour cet exemple, nous utiliserons les données sur le niveau de la rivière Grossache mesurées au point « Huette ». Les annotations servant à déterminer la référence seront créées à partir d’un document décrivant les niveaux préoccupants de la rivière et les inondations.
|

|
Outre l’utilisation de l’interface utilisateur précédemment décrite, les annotations de machine learning sont stockées sous forme de documents dans un index Elasticsearch standard distinct. Les annotations peuvent être également créées par le biais d’un programme ou de façon manuelle à l’aide des API Elasticsearch standard. Les annotations sont stockées dans un index spécifique à la version, et accessibles avec les alias .ml-annotations-read et .ml-annotations-write. Pour cet exemple, nous allons ajouter des annotations afin d’indiquer les événements historiques que la rivière a connus avant de créer notre tâche de machine learning.
{
"_index":".ml-annotations-6",
"_type":"_doc",
"_id":"DGNcAmoBqX9tiPPqzJAQ",
"_score":1.0,
"_source":{
"timestamp":1368870463669,
"end_timestamp":1371015709121,
"annotation":"2013 June; 770 m3/s; 500 houses flooded.",
"job_id":"annotations-leukental-4d-1533",
"type":"annotation",
"create_time":1554817797135,
"create_username":"elastic",
"modified_time":1554817797135,
"modified_username":"elastic"
}
}
À présent, nous allons créer une tâche de machine learning pour repérer les anomalies par rapport au niveau maximal de la rivière. Nous utiliserons un nom qui corresponde au champ job_id de l’annotation ci-dessus, afin qu’il relève les annotations créées manuellement. Voici la façon dont se présente la tâche dans l’assistant Single Metric, après que nous avons ingéré les données historiques de la rivière dans un index Elasticsearch :
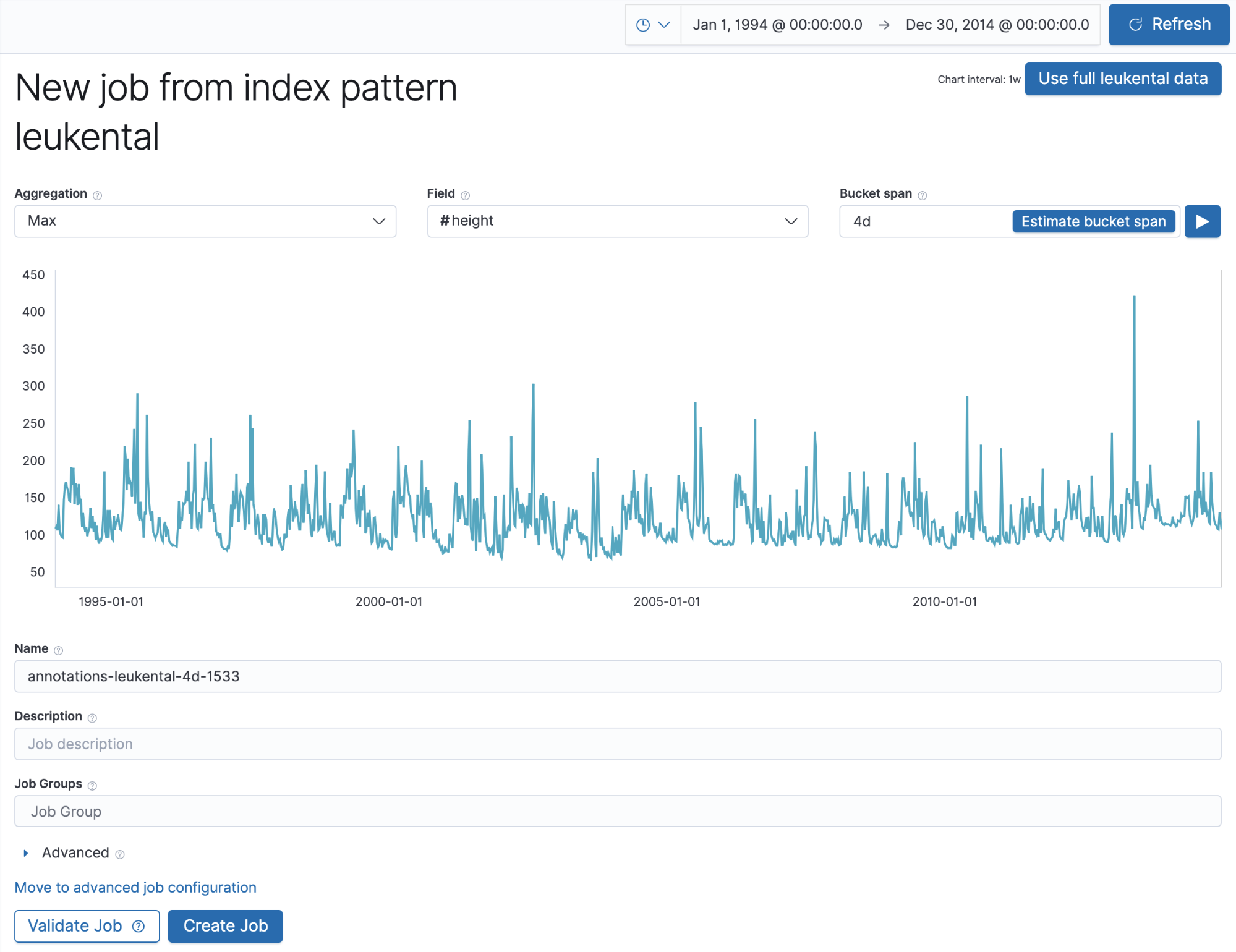
Ici, l’important, c’est que le nom de la tâche que nous choisissons corresponde à celui utilisé pour les annotations. Lorsque nous exécutons la tâche et que nous lançons Single Metric Viewer, nous devrions voir les annotations correspondant aux niveaux de rivière inhabituels que la tâche de machine learning a détectés :
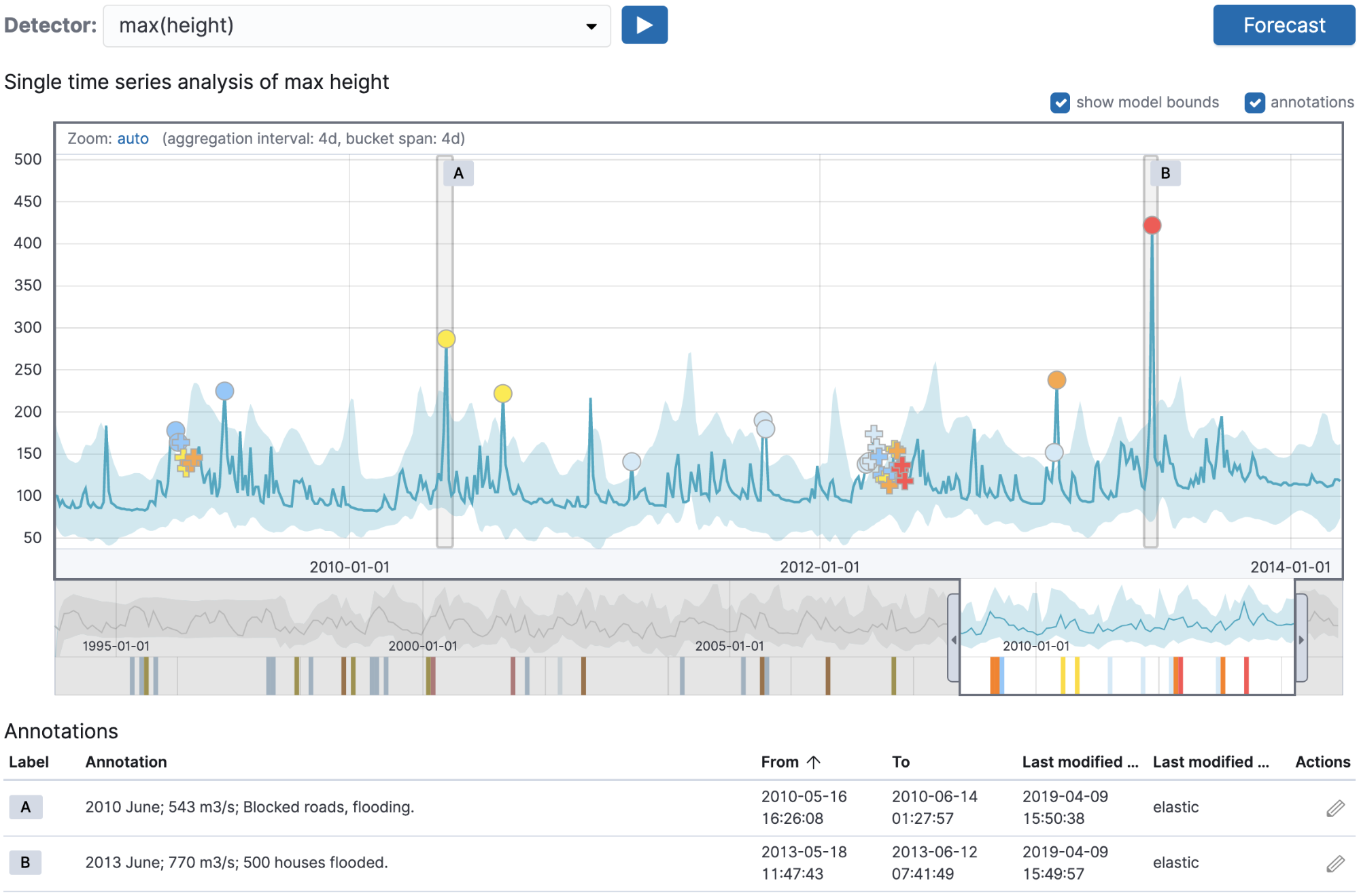
Cette technique est idéale pour vérifier si l’analyse que vous effectuez est valide lorsqu’on la compare aux données de validation pré-existantes stockées en tant qu’annotations.
Annotations pour les événements système
En plus des annotations générées par l’utilisateur, le système back-end du machine learning crée des annotations pour les événements système dans certaines circonstances.
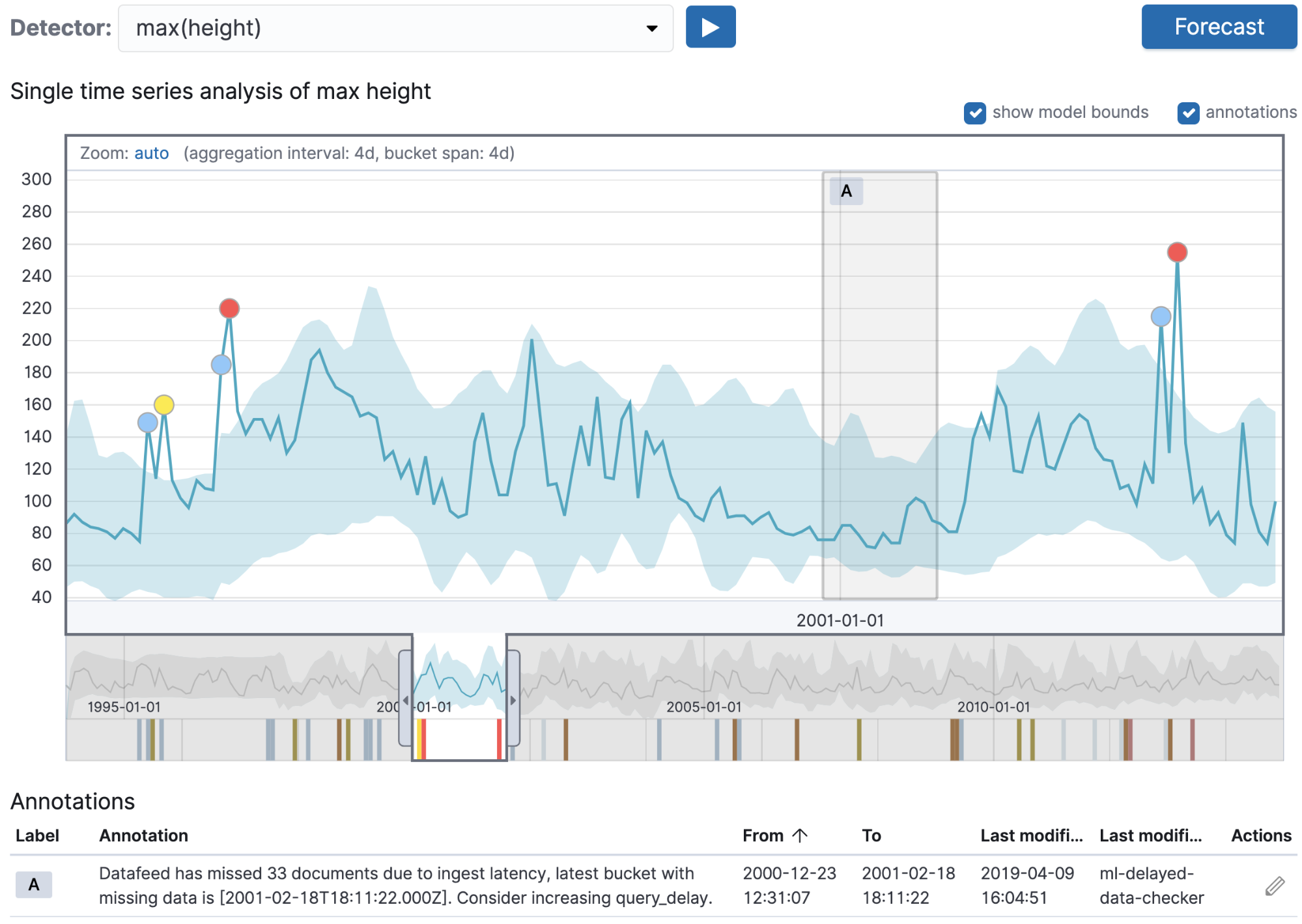
La capture d’écran ci-dessus présente un exemple d’annotation automatiquement créée. Dans ce cas, une tâche de machine learning en temps réel a été exécutée, mais l’ingestion de données n’a pas pu suivre le rythme demandé. De ce fait, les documents ont été ajoutés à l’index après que la tâche a exécuté son analyse sur la plage de temps. L’annotation automatiquement créée met en avant ce problème qui, jusque-là, était difficile à repérer et à déboguer. Les fonctionnalités de texte d’annotation détaillent le problème identifié et suggèrent des méthodes de résolution (dans ce cas, augmenter le paramètre query_delay).
Intégration de l’alerting
Avant que les annotations utilisateur soient mises en place pour le machine learning, vous pouviez utiliser Watcher pour créer des alertes en fonction des anomalies identifiées par les tâches de machine learning. Même s’il s’agit d’une grande amélioration par rapport à l’alerting basé sur des seuils, les alertes peuvent être trop granulaires pour le groupe cible qui les reçoit. En tant qu’utilisateur de tâches de machine learning, vous pouvez vous servir des annotations pour traiter les événements déclenchés en tant qu’alertes Watcher ou transférés à d’autres parties prenantes. Étant donné que les annotations sont stockées dans leur propre index Elasticsearch, vous pouvez utiliser Watcher pour simplement réagir aux documents venant d’être créés dans cet index et déclencher des notifications. Watcher peut être aussi configuré pour envoyer des alertes via Slack. La configuration suivante vous donne un exemple sur la façon d’appliquer un système de surveillance pour déclencher des messages Slack lorsqu’une nouvelle annotation est créée :
{
"trigger": {
"schedule": {
"interval": "5s"
}
},
"input": {
"search": {
"request": {
"search_type": "query_then_fetch",
"indices": [
".ml-annotations-read"
],
"rest_total_hits_as_int": true,
"body": {
"size": 1,
"query": {
"range": {
"create_time": {
"gte": "now-9s"
}
}
},
"sort": [
{
"create_time": {
"order": "desc"
}
}
]
}
}
}
},
"condition": {
"compare": {
"ctx.payload.hits.total": {
"gte": 1
}
}
},
"actions": {
"notify-slack": {
"transform": {
"script": {
"source": "def payload = ctx.payload; DateFormat df = new SimpleDateFormat(\"yyyy-MM-dd'T'HH:mm:ss.SSS'Z'\"); payload.timestamp_formatted = df.format(Date.from(Instant.ofEpochMilli(payload.hits.hits.0._source.timestamp))); payload.end_timestamp_formatted = df.format(Date.from(Instant.ofEpochMilli(payload.hits.hits.0._source.end_timestamp))); return payload",
"lang": "painless"
}
},
"throttle_period_in_millis": 10000,
"slack": {
"message": {
"to": [
"#<slack-channel>"
],
"text": "New Annotation for job *{{ctx.payload.hits.hits.0._source.job_id}}*: {{ctx.payload.hits.hits.0._source.annotation}}",
"attachments": [
{
"fallback": "View in Single Metric Viewer http://<kibana-host>:5601/app/ml#/timeseriesexplorer?_g=(ml:(jobIds:!({{ctx.payload.hits.hits.0._source.job_id}})),refreshInterval:(pause:!t,value:0),time:(from:'{{ctx.payload.timestamp_formatted}}',mode:absolute,to:'{{ctx.payload.end_timestamp_formatted}}'))&_a=(filters:!(),mlSelectInterval:(interval:(display:Auto,val:auto)),mlSelectSeverity:(threshold:(color:%23d2e9f7,display:warning,val:0)),mlTimeSeriesExplorer:(zoom:(from:'{{ctx.payload.timestamp_formatted}}',to:'{{ctx.payload.end_timestamp_formatted}}')),query:(query_string:(analyze_wildcard:!t,query:'*')))",
"actions": [
{
"name": "action_name",
"style": "primary",
"type": "button",
"text": "View in Single Metric Viewer",
"url": "http://<kibana-host>:5601/app/ml#/timeseriesexplorer?_g=(ml:(jobIds:!({{ctx.payload.hits.hits.0._source.job_id}})),refreshInterval:(pause:!t,value:0),time:(from:'{{ctx.payload.timestamp_formatted}}',mode:absolute,to:'{{ctx.payload.end_timestamp_formatted}}'))&_a=(filters:!(),mlSelectInterval:(interval:(display:Auto,val:auto)),mlSelectSeverity:(threshold:(color:%23d2e9f7,display:warning,val:0)),mlTimeSeriesExplorer:(zoom:(from:'{{ctx.payload.timestamp_formatted}}',to:'{{ctx.payload.end_timestamp_formatted}}')),query:(query_string:(analyze_wildcard:!t,query:'*')))"
}
]
}
]
}
}
}
}
}
Dans la configuration ci-dessus, remplacez simplement <slack-channel> et <kibana-host> par vos paramètres, puis utilisez cette configuration pour créer un système de surveillance avancé. Lorsque tout est bien défini, vous devriez recevoir une notification Slack à chaque fois que vous créez une annotation, contenant le texte de l’annotation et un lien de retour vers Single Metric Viewer.

Résumé
Dans cet article, nous avons abordé la nouvelle fonctionnalité des annotations pour le machine learning dans Elasticsearch. Cette fonctionnalité permet d’ajouter des annotations via l’interface utilisateur et peut être utilisée pour les annotations système déclenchées via les tâches de back-end. Ces annotations sont disponibles en tant que signets via la page Job Management (Gestion des tâches). Elles peuvent être partagées sous forme de liens avec d’autres utilisateurs. Les annotations peuvent être créées par des programmes à partir de données externes. Elles serviront alors de référence à laquelle comparer les anomalies détectées. Pour finir, avec Watcher et l’action de Slack dans Elasticsearch, nous avons vu comment utiliser les annotations pour prendre en charge l’alerting. Amusez-vous bien avec les annotations ! Et si vous avez des questions, rendez-vous sur nos forums de discussion.