Importer des données CSV et de log dans Elasticsearch avec File Data Visualizer
La nouvelle fonctionnalité File Data Visualizer a fait son entrée avec la Suite Elastic 6.5. Avec elle, l'utilisateur peut importer un fichier comportant du texte délimité (par exemple au format CSV), NDJSON ou semi-structuré (comme les fichiers logs). Une fois le fichier importé vers le nouveau point de terminaison find_file_structure d'Elastic Machine Learning, celui-ci l'analyse et génère un rapport sur ces données. Cette fonctionnalité propose aussi un pipeline d'ingestion et des mappings que l'utilisateur peut exploiter pour importer son fichier dans Elasticsearch depuis l'interface utilisateur.
L'objectif de cette fonctionnalité ? Permettre aux utilisateurs désireux d'explorer leurs données via Kibana ou Machine Learning d'importer de petits volumes de données vers Elasticsearch, sans pour autant devoir maîtriser toutes les subtilités du processus d'ingestion.
Cet article de blog rédigé par un membre de l'équipe marketing d'Elastic illustre à merveille tout l'intérêt de cette fonctionnalité, même pour les non-développeurs. On y découvre la facilité déconcertante avec laquelle notre spécialiste du marketing a pu importer des données sismiques dans Elasticsearch grâce à File Data Visualizer, ce qui lui a ensuite permis d'analyser les zones sismiques via les visualisations geo_point de Kibana.
Exemple : importer un fichier CSV vers Elasticsearch
Rien de tel qu'un exemple concret pour mieux comprendre cette fonctionnalité. Dans cet exemple, nous allons utiliser les données factices d'un fichier CSV provenant d'un site web dédié à la réservation de vols. Voici les cinq premières lignes du fichier, afin de vous donner un petit aperçu des données :
time,airline,responsetime 2014-06-23 00:00:00Z,AAL,132.2046 2014-06-23 00:00:00Z,JZA,990.4628 2014-06-23 00:00:00Z,JBU,877.5927 2014-06-23 00:00:00Z,KLM,1355.4812
Configurer l'importation du fichier CSV dans File Data Visualizer
La fonctionnalité File Data Visualizer est accessible dans Kibana, sous la section Machine Learning > Data Visualizer. Une page s'affiche, qui vous permet de sélectionner un fichier ou de l'ajouter par glisser-déposer. Depuis la version 6.5, la taille maximale de fichier est limitée à 100 Mo.
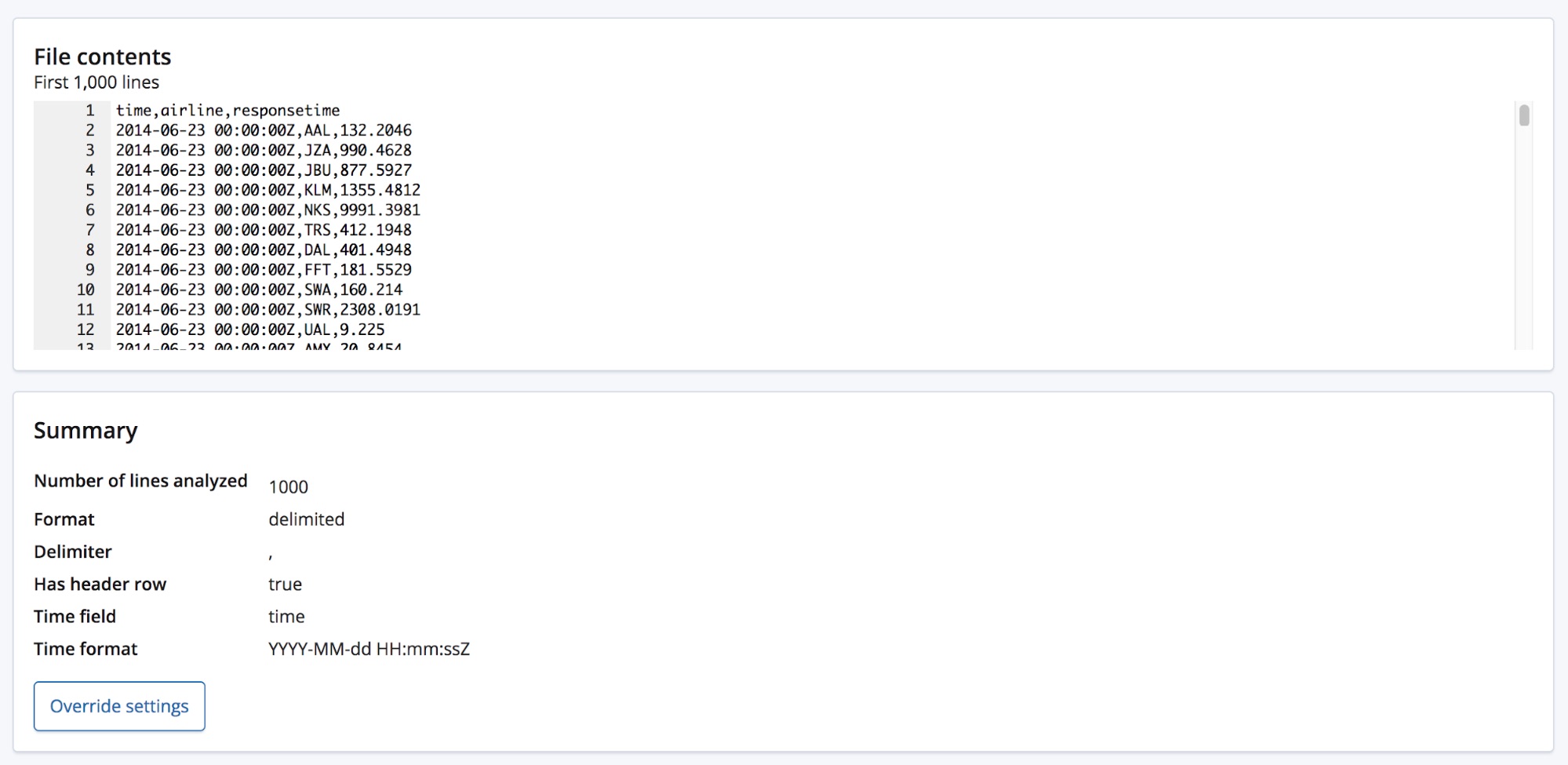
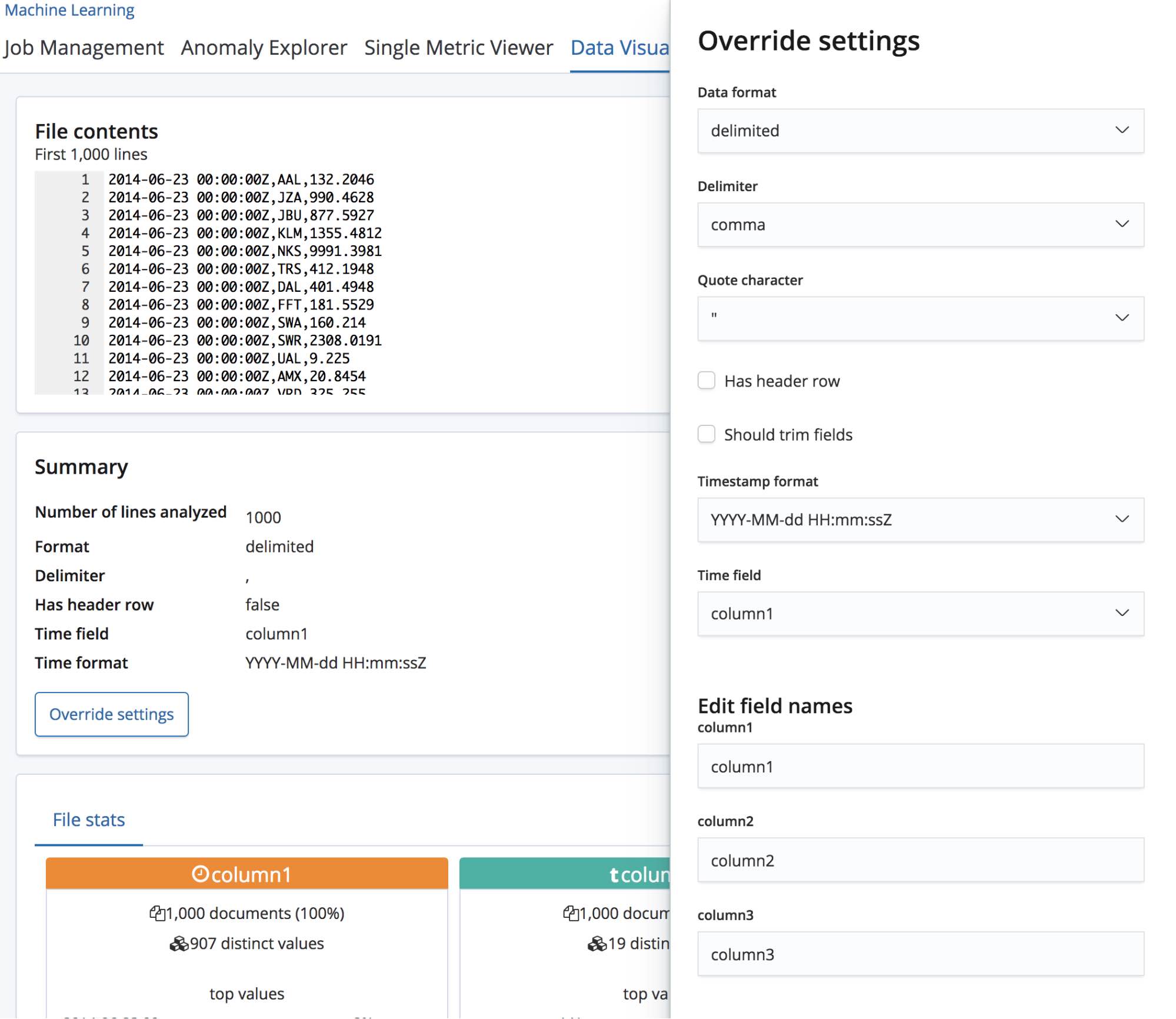
Une fois le fichier CSV sélectionné, la page envoie les 1 000 premières lignes du fichier vers le point de terminaison find_file_structure, qui les analyse et retourne ses résultats. Si on examine la section Summary (Synthèse) de l'interface utilisateur, on constate que le système a bien détecté que le format des données est délimité et que le séparateur est une virgule.
Il a aussi détecté la présence d'une ligne d'en-tête et a utilisé ces noms de champs pour libeller les données de chaque colonne. La première colonne correspond à un format de date connu : elle est donc associée au champ Time field (Date/Heure).
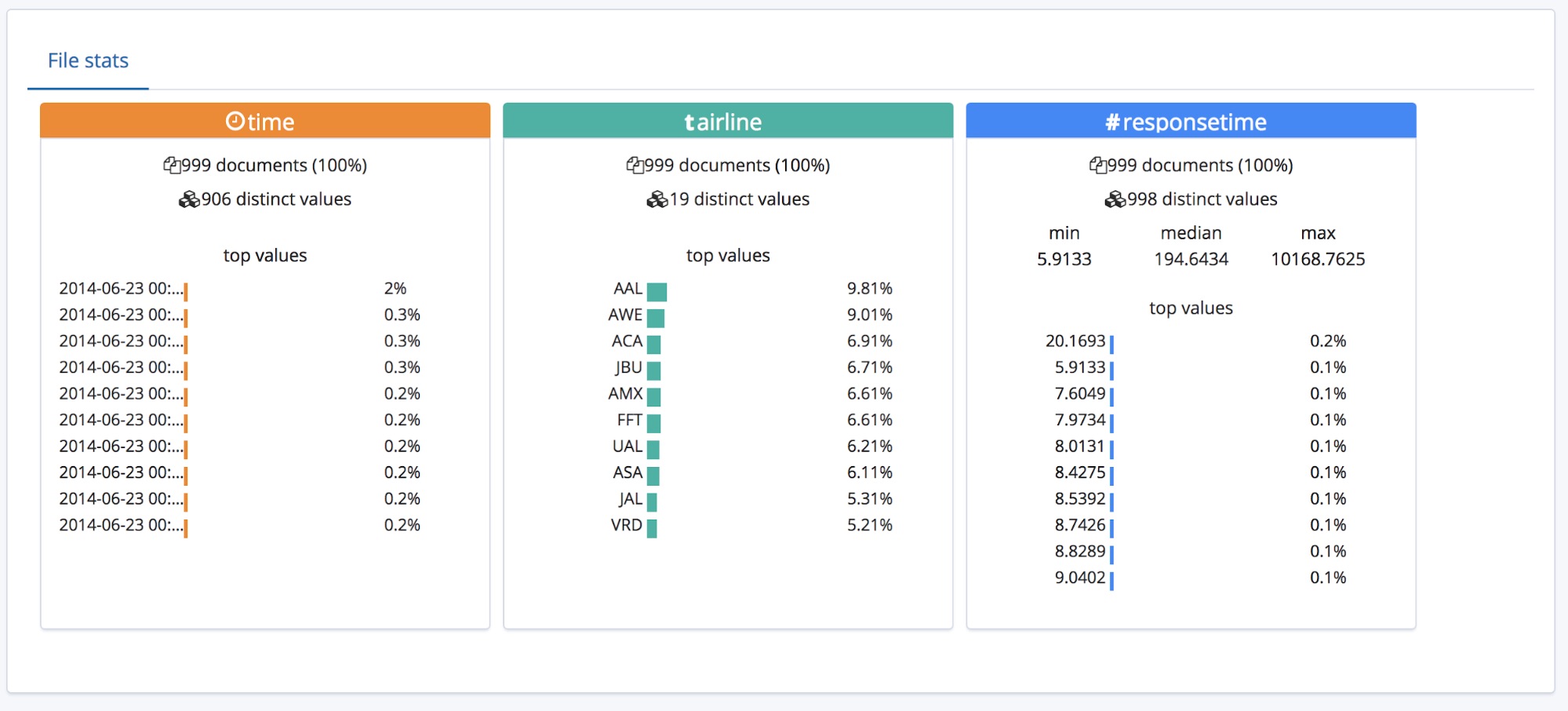
Sous cette section Summary (Synthèse), se trouve la section "Fields" (Champs). Celle-ci ne devrait avoir aucun secret pour vous si vous avez déjà utilisé la fonctionnalité Data Visualizer initiale.
Nous voyons que les trois types de champs sont correctement identifiés, et que des statistiques détaillées sont associées à chacun d'entre eux. La liste des 10 valeurs les plus fréquentes s'affiche pour chaque champ. Le champ responsetime a été identifié comme un champ numérique et affiche aussi les valeurs min, median et max (valeurs minimales, médianes et maximales).
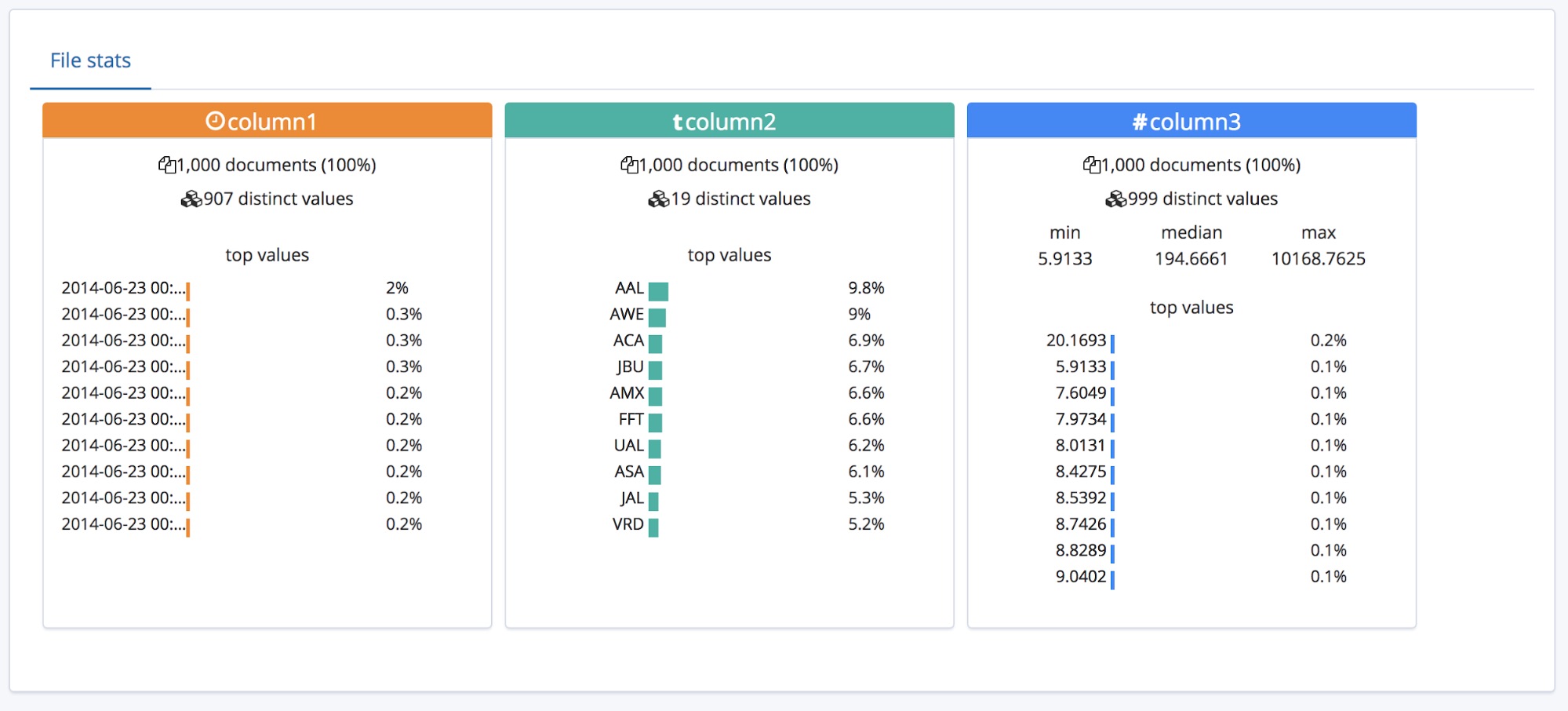
Tout cela est très bien quand le fichier CSV comporte un en-tête. Mais que se passe-t-il quand ce n'est pas le cas ?
Dans ce cas, le point de terminaison find_file_structure utilise des noms de champs temporaires. À des fins d'illustration, supprimons la première ligne du fichier d'exemple et réimportons-le. Nous voyons ci-dessous que les champs portent maintenant des noms génériques : column1, column2 et column3.
En général, l'utilisateur s'y connaît un peu et renommera ces champs pour leur donner un nom plus adapté. Pour ce faire, il suffit de cliquer sur le bouton Override settings (Remplacer les paramètres).
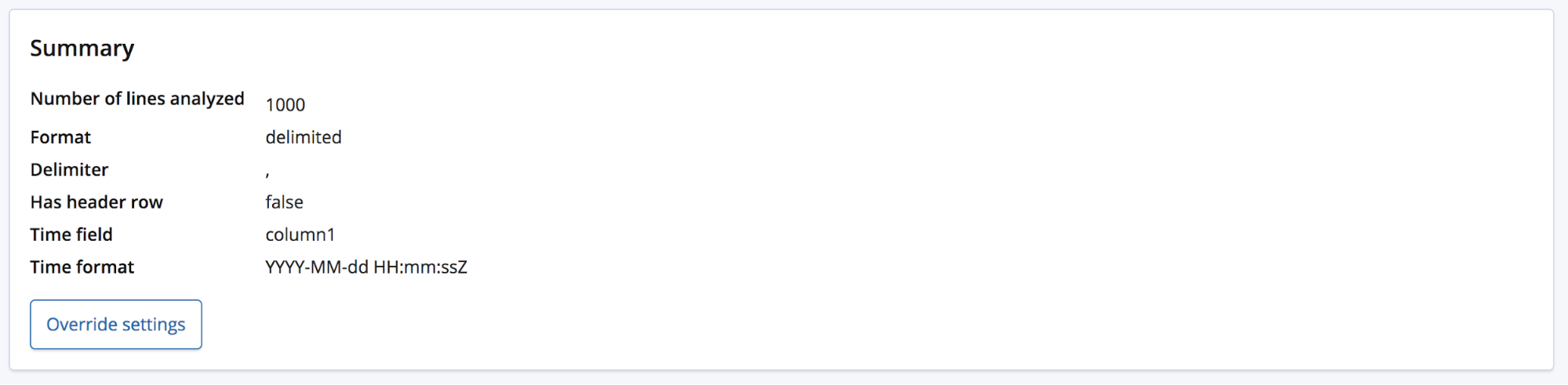
De même qu'il peut renommer ces champs, l'utilisateur peut aussi modifier d'autres paramètres, comme Data format (Format des données), Delimiter (Séparateur) et Quote character (Guillemet). Globalement, cette section vous permet de rectifier les hypothèses du point de terminaison find_file_structure au sujet des données. Par exemple, il est possible que votre fichier contienne plusieurs champs de date et que seul le premier ait été retenu. Il peut aussi arriver de vouloir complètement modifier les noms des champs, même si le fichier contient une ligne d'en-tête.
Une fois satisfait de vos paramètres, vous pouvez cliquer sur le bouton Import (Importer) situé en bas à gauche de la page.
Importer les données CSV vers Elasticsearch
Nous voici donc sur la page d'importation, qui nous permet d'importer les données vers Elasticsearch. Remarque : Cette fonctionnalité n'est pas destinée à être utilisée dans le cadre d'un processus de production répétitif. Elle sert seulement à l'exploration initiale des données. Pourquoi ? D'abord parce qu'elle ne propose pas d'options d'automatisation, mais aussi parce qu'il s'agit pour le moment d'une fonctionnalité expérimentale.
Vous avez le choix entre deux modes d'importation. En mode Simple, le seul élément à fournir est un nouveau nom unique pour l'index. Vous devrez aussi indiquer si vous voulez créer un modèle d'indexation.
Le mode Advanced (Avancé) vous donne quant à lui un plus grand contrôle sur les paramètres à utiliser pour créer votre index.
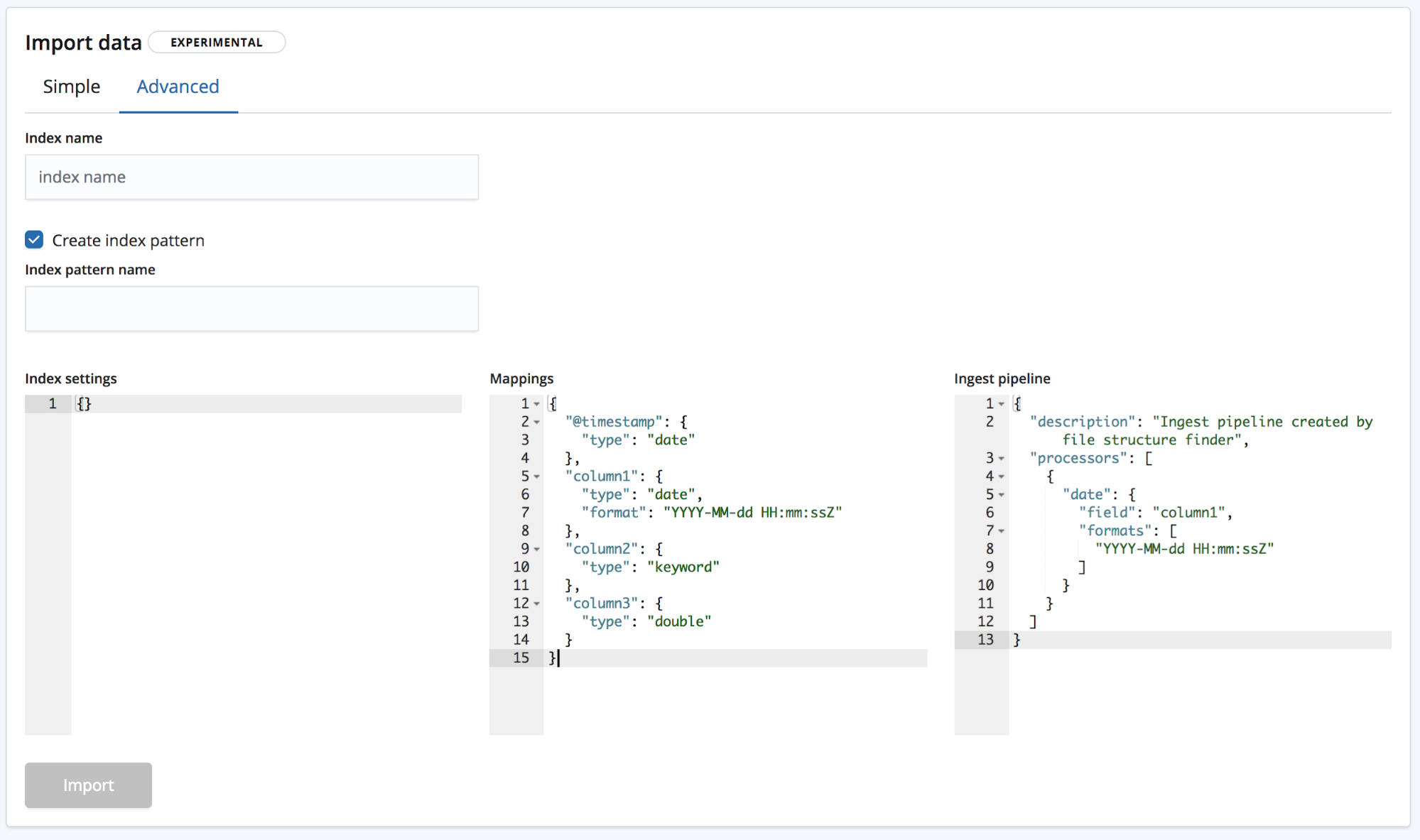
- Index settings (Paramètres d'indexation) : par défaut, la création de l'index et l'importation ne nécessitent aucun autre paramètre, mais nous vous laissons la possibilité de les personnaliser.
- Mappings : le point de terminaison
find_file_structurefournit un objet mappings en fonction des champs et des types de champs qu'il a identifiés. Pour en savoir plus, la documentation Elasticsearch consacrée au mapping vous propose une liste des mappings possibles. - Ingest pipeline (Pipeline d'ingestion) : le point de terminaison
find_file_structurefournit un objet pipeline d'ingestion par défaut. Il sert à l'ingestion des données et vous permet d'importer des données supplémentaires, le cas échéant.
La version 6.5 ne permet que la création de nouveaux index. En effet, il n'est plus possible d'ajouter des données à un index existant, afin d'éviter de l'endommager.
Pour lancer l'importation, il suffit de cliquer sur le bouton "Import" (Importer). Celle-ci se fait en plusieurs étapes, numérotées de 1 à 5 :
- Processing file (Traitement du fichier) : conversion des données en documents NDJSON en vue de leur ingestion via l'API Bulk.
- Creating index (Création de l'index) : création de l'index grâce aux paramètres et aux objets mappings.
- Creating ingest pipeline (Création du pipeline d'ingestion) : création du pipeline d'ingestion grâce à l'objet pipeline d'ingestion.
- Uploading the data (Importation des données) : chargement des données dans le nouvel index Elasticsearch.
- Creating index pattern (Création du modèle d'indexation) : création d'un modèle d'indexation Kibana (si l'utilisateur a choisi cette option).

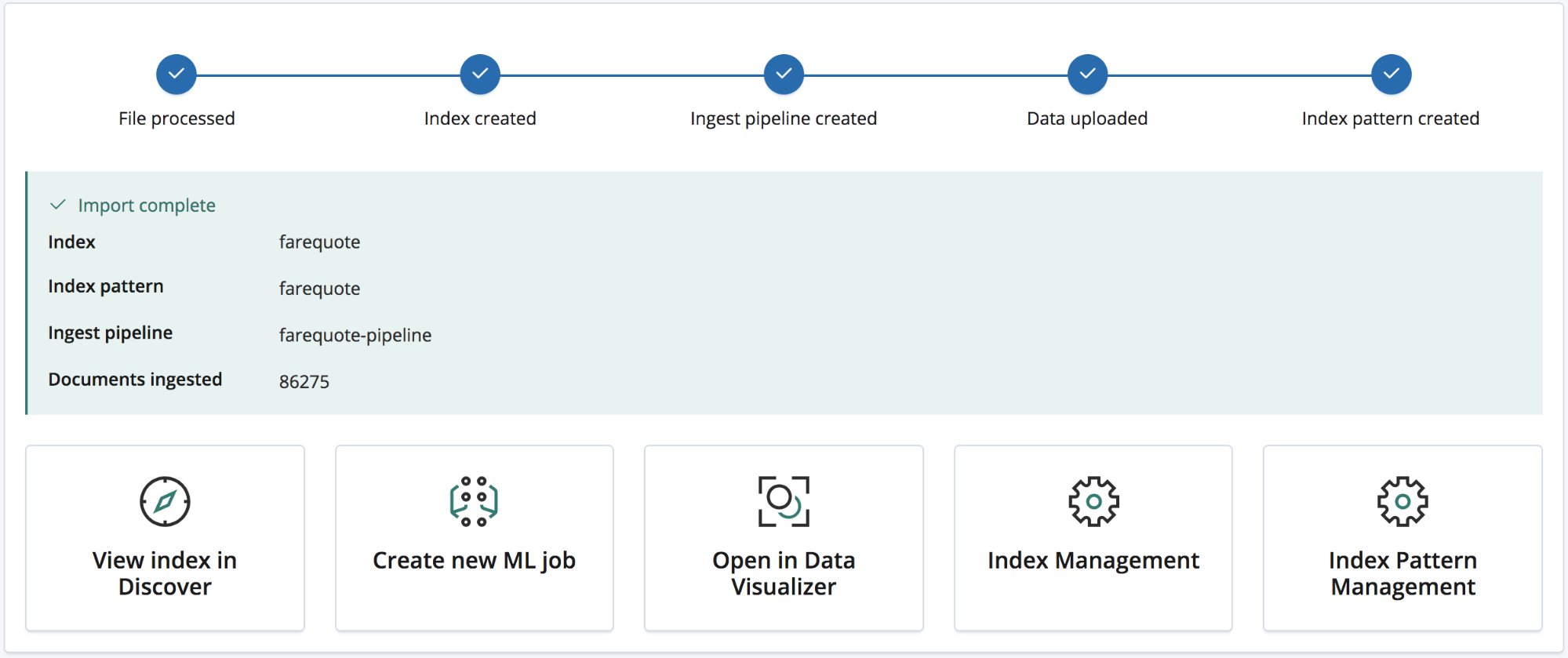
Une fois l'importation terminée, une synthèse s'affiche et répertorie les noms de l'index, du modèle d'indexation et du pipeline d'ingestion créés, ainsi que le nombre de documents ingérés.
Elle propose aussi des liens Kibana vous permettant d'explorer les données que vous venez d'importer. Si vous avez opté pour un abonnement Platinum ou une version d'essai, un lien vous permet de créer rapidement une tâche de machine learning à partir de ces données.
Exemple : importer des fichiers logs et autres textes semi-structurés vers Elasticsearch
Nous venons de voir l'importation de données au format CSV. Celle des données NDJSON est encore plus simple et nécessite très peu de traitement. Mais quid des textes semi-structurés ? Voyons en quoi l'analyse de données CSV diffère de celle des données de fichiers logs habituels, autrement dit, de celle du texte semi-structuré.
Voici trois lignes d'un fichier log généré par un routeur.
<190>38377: GOW45-AR002: Apr 18 08:44:02.434 GMT: %JHG_MS-6-ROUTE_EVENT_INFO: Route changed Prefix 10.156.26.0/23, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired <190>38378: GOW45-AR002: Apr 18 08:44:07.538 GMT: %JHG_MS-6-ROUTE_EVENT_INFO: Route changed Prefix 10.156.72.0/23, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired <190>38379: GOW45-AR002: Apr 18 08:44:08.818 GMT: %JHG_MS-6-ROUTE_EVENT_INFO: Route changed Prefix 10.156.55.0/24, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired
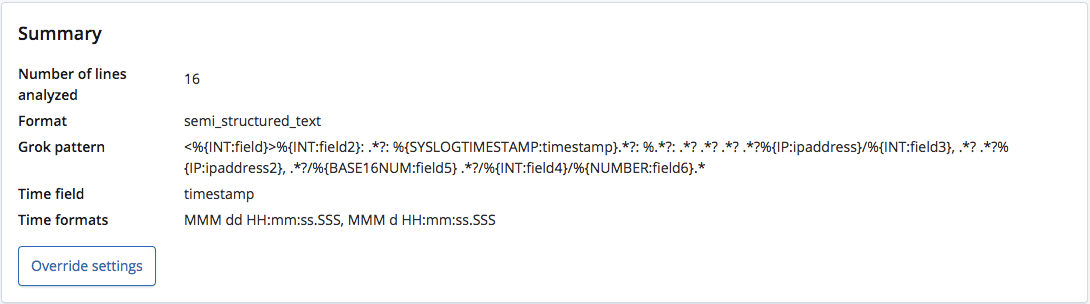
Lorsque le point de terminaison find_file_structure analyse ces données, il reconnaît que le format correspond à du texte semi-structuré et créer un modèle grok permettant d'extraire les champs et les types de champs de chaque ligne. Parmi ces champs, il reconnaît aussi le champ de date et son format.
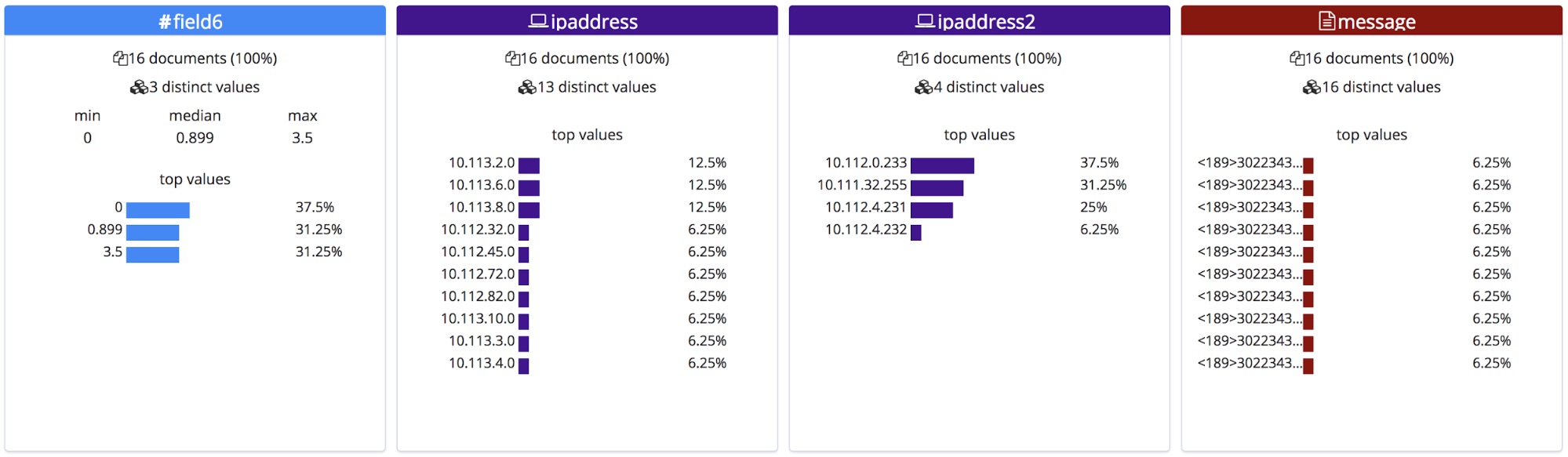
Contrairement à un fichier CSV avec en-tête ou à un fichier NDJSON, il n'existe aucun moyen de connaître les noms exacts de ces champs. Le point de terminaison leur donne donc des noms génériques en fonction de leur type.
Toutefois, le modèle grok étant modifiable via le menu Override settings (Remplacer les paramètres), nous avons la possibilité de rectifier les noms et les types de champs.
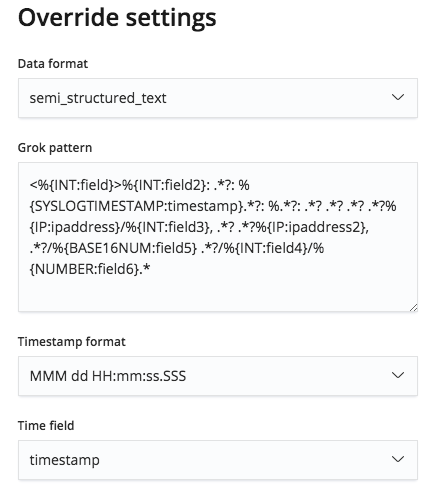
Une fois rectifiés, ces noms de champs s'affichent dans la section File stats (Statistiques du fichier). Remarque : Étant classés dans l'ordre alphabétique, ils apparaissent dans un ordre légèrement différent.
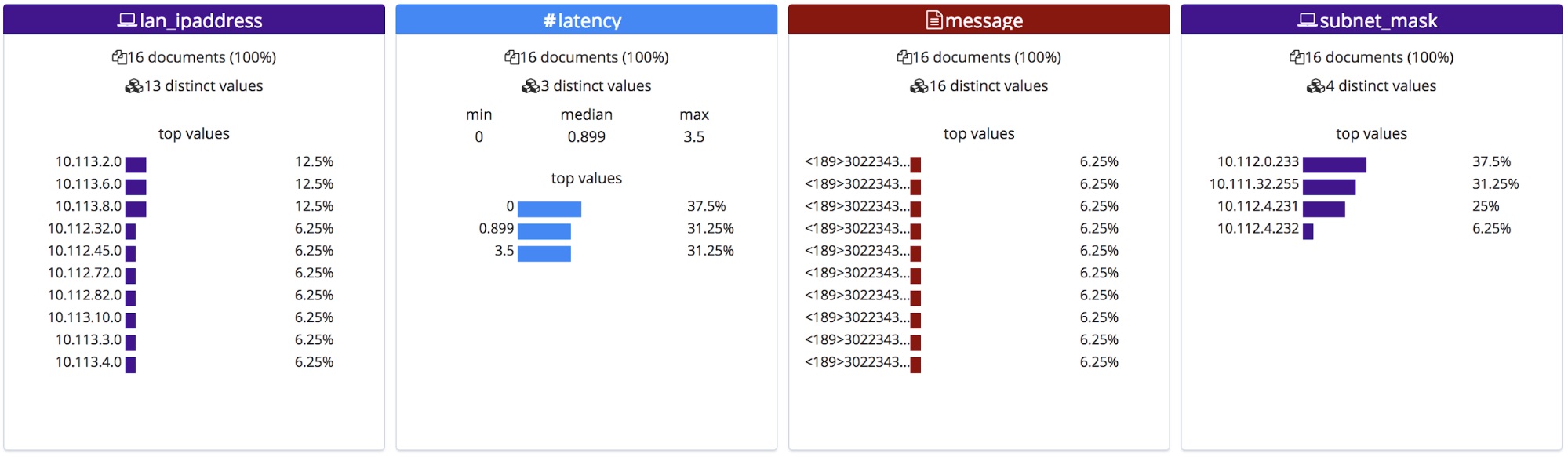
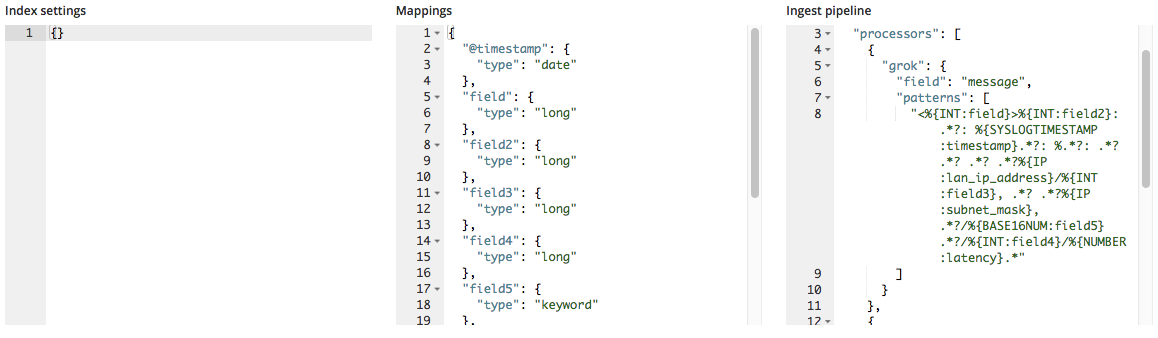
Une fois importés, ces nouveaux noms de champs sont ajoutés à l'objet mappings, et le modèle grok est ajouté à la liste des processeurs du pipeline d'ingestion.
Pour conclure
J'espère que ce petit aperçu vous a donné envie d'essayer la nouvelle fonctionnalité File Data Visualizer de la version 6.5. Pour le moment, il s'agit encore d'une fonctionnalité expérimentale. Il est donc possible que tous les formats de fichiers ne donnent pas les résultats escomptés, mais n'hésitez pas à l'essayer et à nous parler de votre expérience. Vos commentaires nous aideront à accélérer la disponibilité générale de cette nouvelle fonctionnalité.