Elasticsearch Serverless
Payez uniquement pour ce que vous utilisez, sans souci d’infrastructure. Découvrez l’art du possible avec AI Search, des outils prêts pour la RAG et des fonctionnalités d’analyse des données.
Détails des tarifsIngestion*
À partir de 0,14 $
Par UC virtuelle par heure Search*
À partir de 0,09 $
Par UC virtuelle par heure Machine Learning
À partir de 0,07 $
Par UC virtuelle par heure Stockage et conservation
À partir de 0,047 $
Par Go conservé et par mois Egress
À partir de 0,05 $ par Go
Par Go transféré par mois *Les profils vectoriels bénéficient de 50 Go gratuits
Grand modèle de langage (LLM) géré par Elastic pour AI Playground et AI Assistant
4,50 $ par million de jetons d'entrée21 $ par million de jetons de sortie Service d’inférence Elastic
À partir de 0,08 $
Par million de tokens Le Service d'inférence Elastic prend en charge un catalogue de modèles en constante évolution. Consultez les tarifs détaillés par modèle ici et découvrez les modèles disponibles dès aujourd’hui, avec d’autres à venir.
Workflows
10 000 exécutions gratuites, puis à partir de 0,0108 $
Par exécution Agent Builder
1 000 exécutions gratuites, puis à partir de 0,025 $
Par exécution |
|
| Ingestion*Par heure d'UC virtuelle | À partir de 0,14 $ |
| Search*Par UC virtuelle par heure | À partir de 0,09 $ |
| Machine Learningpar UC virtuelle par heure | À partir de 0,07 $ |
| Stockage et conservationPar Go conservé et par mois | À partir de 0,047 $ |
| EgressPar Go transféré par mois *Les profils vectoriels bénéficient de 50 Go gratuits |
À partir de 0,05 $
|
| Grand modèle de langage (LLM) géré par Elastic pour AI Playground, Agent Builder et AI Assistant |
4,50 $
par million de jetons d'entrée
21 $
par million de jetons de sortie
|
| Service d'inférence ElasticPar million de jetons Le Service d'inférence Elastic prend en charge un catalogue de modèles en constante évolution. Consultez les tarifs détaillés par modèle ici et découvrez les modèles disponibles dès aujourd’hui, avec d’autres à venir. |
À partir de 0,08 $
|
| Workflows Par exécution |
10 000 exécutions gratuites, puis à partir de 0,0108 $
|
| Agent Builder par exécution |
1 000 exécutions gratuites, puis à partir de 0,025 $
|
*Ces prix prendront effet le 1er décembre 2024. Les tarifs des workflows et d'Agent Builder entrent en vigueur le 1er mai 2026. Consultez notre page dédiée à la tarification cloud pour en savoir plus.
La mesure de l'ingestion et de la conservation est basée sur le volume de données non compressées, normalisées et entièrement enrichies que vous ingérez dans votre projet serverless. Les volumes mesurés seront bien supérieurs à la taille des données « brutes » ou compressées « sur le réseau ».
Pack de support technique
Un support technique limité est inclus dans l'abonnement standard ; tous les autres tarifs de support technique sont basés sur votre pourcentage de consommation. Pour en savoir plus sur les services inclus dans chaque niveau de support technique, veuillez consulter la page elastic.co/support.
| Niveau d'abonnement Elastic Cloud* | Standard | Or | Platinum | Entreprise |
|---|---|---|---|---|
| Support technique et facturation totale | ||||
| Niveau de support technique | Limité | Basique | Amélioré | Premium |
| % de charge | Compris | 5 % | 10 % | 15 % |
*Le niveau d'abonnement est choisi au moment de l'inscription
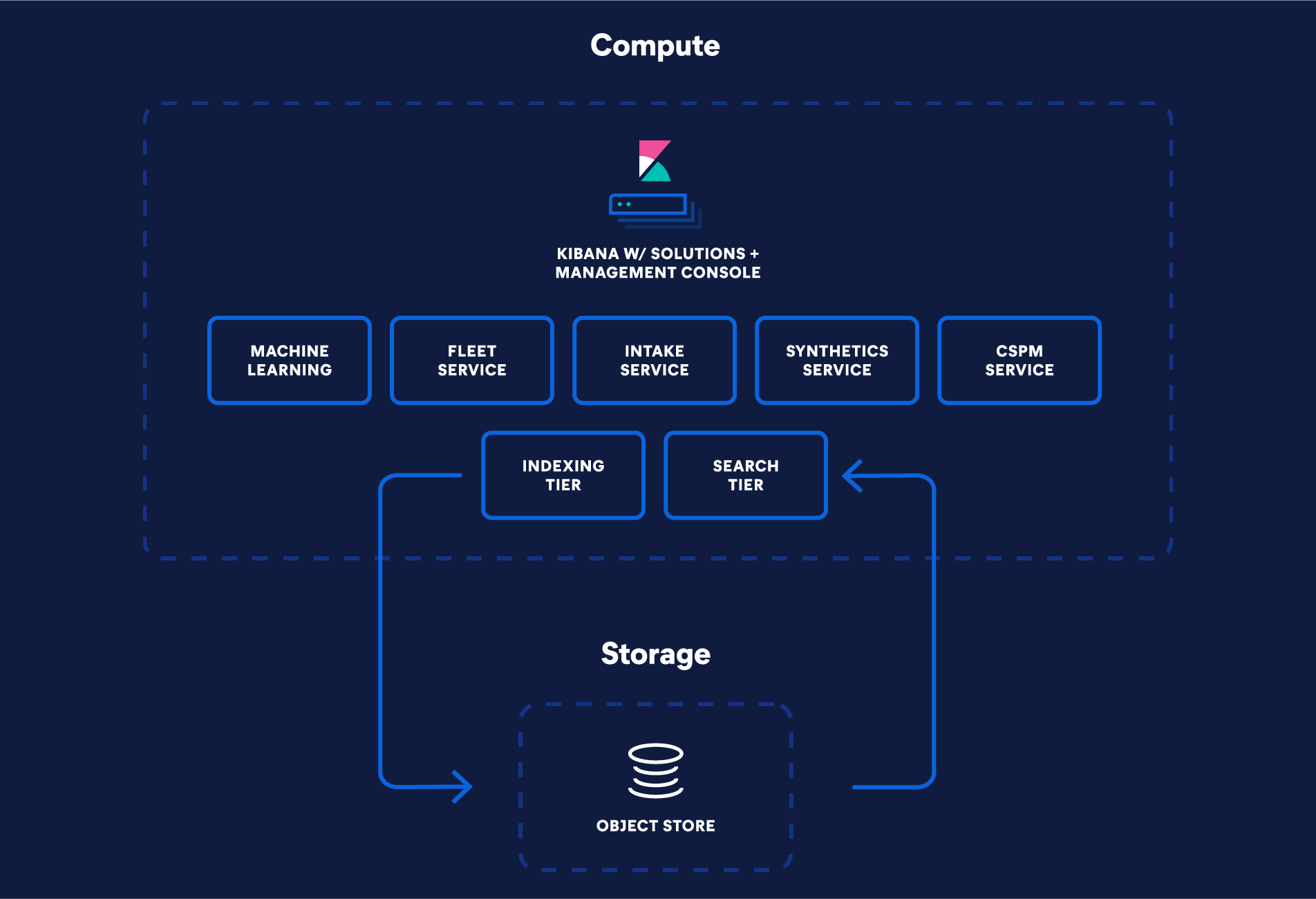
Composantes de la tarification d'Elasticsearch Serverless
Elasticsearch Serverless facture séparément le calcul (VCU avec 1 Go de RAM) et le stockage (en Go), offrant des tarifs modulables et axés sur les performances pour atteindre vos objectifs de latence et de débit.
Unité de calcul virtuelle (UC virtuelle)
Il existe trois types d'unités de contrôle de la vitesse (VCU) spécialisées, permettant d'effectuer des tâches spécifiques.
Ingestion des VCU : gérez l’indexation des données dans le lac d’IA de recherche.
Unités de recherche VCU : gérez les recherches pilotées par l’utilisateur, les règles d’alerting, les agrégations, les transformations et les requêtes géospatiales sur les données du lac d’IA de recherche.
Machine Learning VCUs : gérez l'inférence, les charges de travail ELSER et les tâches de Machine Learning.
Utilisation des jetons
Utilisation du modèle linguistique étendu par Elastic Managed par million de jetons d'entrée et de sortie : profitez des fonctionnalités d'IA prêtes à l'emploi sans déployer ni utiliser de grand modèle linguistique (LLM).
Utilisation des modèles Jina AI facturés par million de jetons : tirez parti des modèles Jina AI sur GPU pour des recherches sémantiques et des cas d'utilisation de reclassement.
Provisionnement adaptatif des ressources
Les ressources de calcul pour l'ingestion et le ML scalent automatiquement pour répondre aux exigences des charges de travail.
Les ressources de calcul de recherche s'adaptent dynamiquement à la charge de travail, garantissant des performances et une réactivité constantes. Grâce aux paramètres flexibles de Search Power, vous contrôlez l'allocation des ressources pour répondre à vos besoins de performance. Un minimum de ressources de recherche est toujours provisionné pour que vos données restent instantanément accessibles ; les périodes d'inactivité sont facturées à tarif réduit.
Stockage et conservation
Elasticsearch Serverless utilise des magasins d'objets pour le stockage persistant dans le Search AI Lake.
Toutes les données, quels que soient leur type, leur récence et leur fréquence d'utilisation, sont accessibles à partir du Search AI Lake. La taille du Search AI Lake peut être contrôlée à l'aide de politiques de conservation des données manuelles ou gérées.
Le stockage est mesuré en Go.
Effectuez des recherches parmi les projets sans déplacer vos données
Que vos données soient séparées par locataire, unité commerciale ou région géographique, vous pouvez interroger instantanément les projets Elastic Cloud Serverless comme un seul.
Le nombre de VCU de recherche pourrait augmenter pour ce projet afin de prendre en charge les requêtes fédérées. Pendant la phase d'aperçu technique, le transfert de données CPS entre les projets n'est pas facturé.
Recherche et automatisation agentiques
Créez et interagissez avec des agents d'IA qui comprennent vos données pour améliorer la précision et la performance, et prenez des mesures à l'aide de flux de travail.
L'utilisation de l'agent d'IA est mesurée par les exécutions de l'Agent Builder et les exécutions du Workflow.
Elasticsearch, mais en plus facile
Questions fréquentes
Qu'est-ce qu'Elasticsearch Serverless ?
Qu'est-ce qu'Elasticsearch Serverless ?
Les projets sans serveur utilisent les composants de noyau de l'Elastic Stack, tels qu'Elasticsearch et Kibana, et sont basés sur l'architecture Search AI Lake d'Elastic qui dissocie le calcul et le stockage. Les opérations de recherche et d'indexation sont séparées, ce qui offre une grande flexibilité pour le scaling de vos workloads tout en garantissant des performances élevées.
Profitez des avantages suivants avec Elasticsearch Serverless :
- Sans gestion. Elastic gère le cluster Elastic sous-jacent, vous permettant de vous concentrer sur vos données. Avec les projets sans serveur, Elastic est responsable des mises à niveau automatiques, des sauvegardes de données et de la continuité des activités.
- Scaling automatique. Pour répondre à vos exigences en matière de performances, le système s'ajuste automatiquement à vos workloads.
- Stockage des données optimisé. Vos données sont stockées dans le Search Lake de votre projet, qui sert de stockage peu onéreux et performant. Une couche haute performance est disponible au-dessus du Search Lake pour vos données les plus interrogées.
- Payez pour les performances dont vous avez besoin. Payez pour l'ingestion, la recherche et les ressources ML séparément selon les besoins des workloads que vous exécutez.
En quoi Elastic Cloud Serverless est-il différent de l'offre Elastic Cloud Hosted ?
En quoi Elastic Cloud Serverless est-il différent de l'offre Elastic Cloud Hosted ?
Elastic Cloud est une plateforme puissante qui répond à de nombreux besoins informatiques. Les projets sans serveur sont spécialement conçus pour des cas d'utilisation, tout en offrant une expérience entièrement gérée et mise à l'échelle automatique. Cette spécialisation et ce modèle opérationnel sont ce qui distingue le modèle Serverless aujourd'hui.
Comment choisir entre Elasticsearch Serverless ou la Suite Elastic hébergée ?
Comment choisir entre Elasticsearch Serverless ou la Suite Elastic hébergée ?
Elasticsearch Serverless est actuellement disponible dans certaines régions de fournisseurs cloud, avec certaines fonctionnalités à venir. Nous sommes pleinement engagés dans l'expansion de notre offre sans serveur vers davantage de régions et de fournisseurs cloud. Nous vous recommandons de consulter la documentation pour vérifier la compatibilité technique telle que la sécurité, la conformité et la disponibilité.
Comment faire mes premiers pas avec Elasticsearch Serverless ?
Comment faire mes premiers pas avec Elasticsearch Serverless ?
Il est simple de commencer avec Elasticsearch Serverless :
- Créez des projets Elasticsearch Serverless dans la console cloud.
- Choisissez le type de projet optimisé pour votre cas d'utilisation qui correspond le mieux à vos besoins.
- Démarrez votre projet avec une expérience optimisée pour votre cas d'utilisation.
Puis-je migrer des données entre Elasticsearch Serverless et la Suite Elastic hébergée ?
Puis-je migrer des données entre Elasticsearch Serverless et la Suite Elastic hébergée ?
Nous recommandons d'envoyer les données directement à partir de votre application ou d'utiliser les clients Connector. Pour l'envoi de données dans une instance Elasticsearch existante, nous recommandons d'utiliser Logstash pour migrer d'importants volumes.
Quels sont les paramètres de Search Power ?
Quels sont les paramètres de Search Power ?
Les paramètres de recherche Power vous permettent de gérer les ressources de calcul afin d’optimiser les performances de recherche (débit et latence) et de maîtriser les coûts. Il existe trois paramètres de recherche Power pour les projets Elasticsearch Serverless. Le paramètre Performant est activé par défaut et offre une expérience de recherche performante pour des données de toutes tailles. Il est possible de choisir l’un des paramètres suivants :
À la demande : s’adapte automatiquement en fonction des données et de la charge de recherche avec une base minimale plus faible pour l’utilisation des ressources. Cette flexibilité entraîne une latence de requête plus variable et un débit maximal réduit.
Performant : offre une latence constamment faible et s’adapte automatiquement pour gérer un débit de requêtes modérément élevé.
Haute disponibilité : optimisé pour les scénarios de haute disponibilité, il s’adapte automatiquement pour maintenir la latence des requêtes même à des volumes de requêtes très élevés.
Combien vais-je payer* ?
Combien vais-je payer* ?
Avec Elasticsearch Serverless, vous payez uniquement les ressources utilisées pour gérer vos charges de travail et vos besoins de performance. Voici quelques exemples pour vous donner une idée des coûts potentiels et vous aider à les appréhender.
Exemple 1 - Environnement de développement avec 2 Go de données consultables, 1 % d’utilisation d’ingestion (15 minutes par jour), 8 % d’utilisation de recherche (2 heures par jour)
- À la demande : 24 $/mois
- Performant : 27 $/mois
Exemple 2 - Environnement de production avec 20 Go de données consultables, 5 % d’utilisation de l’ingestion (1 heure par jour), 33 % d’utilisation de la recherche (8 heures par jour)
- À la demande : 190 $/mois
- Performant : 210 $/mois
Les estimations de prix fournies dans les exemples sont données à titre indicatif uniquement. Les coûts réels peuvent varier en fonction de facteurs tels que le type de données, la complexité des requêtes, les tendances de trafic, la durée d’utilisation et les configurations spécifiques. Ces estimations visent à vous aider à comprendre les scénarios de tarification possibles, mais ne doivent pas être considérées comme un coût définitif. Pour un calcul précis des coûts, nous vous recommandons de surveiller votre utilisation.
Pourquoi suis-je facturé pour les VCU de recherche même lorsque je ne lance pas de requêtes ?
Pourquoi suis-je facturé pour les VCU de recherche même lorsque je ne lance pas de requêtes ?
Elasticsearch Serverless maintient un niveau minimal de ressources de recherche allouées à votre projet afin que vos données restent consultables sans délai inutile lors de la première requête après une période d'inactivité. Pendant une recherche active, vous êtes facturé pour l'intégralité des ressources utilisées ; pendant les périodes d'inactivité, la facturation est réduite en fonction de la taille de votre ensemble de données prêt pour la recherche et de votre paramètre Search Power.
Pour réduire les coûts liés à l'inactivité, vous pouvez passer la puissance de recherche de "Performante" (par défaut) à "À la demande", ce qui abaisse le niveau de référence au prix d'une latence de requête plus variable. Les VCU d'ingestion, en revanche, sont réduites à zéro lorsqu'aucune activité d'ingestion n'est en cours
Comment le Service d'inférence Elastic est-il facturé ?
Comment le Service d'inférence Elastic est-il facturé ?
L'utilisation est facturée strictement en fonction du volume de données traitées, mesuré en millions de jetons. Ce modèle de facturation à l'usage vous permet de scaler vos coûts de manière linéaire en fonction de votre débit, vous assurant ainsi de ne payer que pour les jetons réellement traités, et non pour une infrastructure ou une capacité inutilisée.
Comment Agent Builder est-il facturé ?
Comment Agent Builder est-il facturé ?
Agent Builder est facturé en fonction des exécutions d’Agent Builder. Une exécution correspond à chaque interaction terminée avec un agent IA (par exemple, une entrée et une sortie dans un chat). Les interactions plus complexes, mesurées en fonction du nombre de jetons d’entrée utilisés, sont comptabilisées comme des exécutions supplémentaires (chaque tranche de 50 000 jetons d’entrée correspond à une exécution supplémentaire).
Exemple 1 : message envoyé à l’agent IA, et l’agent renvoie une réponse avec succès. L’interaction utilise 42 000 jetons d’entrée ; cela correspond à 1 exécution de l’agent.
Exemple 2 : message envoyé à l’agent IA, et l’agent renvoie une réponse avec succès. L’interaction utilise 325 000 jetons d’entrée ; cela correspond à 7 exécutions.
Exemple 3 : message envoyé à l’agent IA, et l’agent rencontre une erreur et ne renvoie pas de réponse. Aucune exécution n’est comptabilisée.
Découvrez toutes les possibilités offertes par la technologie Elastic Cloud Serverless

Démonstration interactive
Découvrez ce que la technologie sans serveur a à vous offrir.

Essai gratuit
Démarrez avec une tarification simple, orientée vers une solution et basée sur l'utilisation.