Sin estado: Tus nuevos aires de búsqueda con Elasticsearch
Evolución de la arquitectura de Elasticsearch para simplificar tu despliegue



Comparte en Twitter


Comparte en LinkedIn


Comparte en Facebook


Comparte por correo electrónico


Imprime
Punto de partida
La primera versión de Elasticsearch se lanzó en 2010 como un motor de búsqueda escalable distribuido que permitía a los usuarios buscar rápidamente y revelar información fundamental. Después de 12 años y más de 65 000 confirmaciones, Elasticsearch sigue brindando a los usuarios soluciones puestas a prueba para una gran variedad de problemas de búsqueda. Gracias al esfuerzo de más de 1500 colaboradores, incluidos cientos de empleados de tiempo completo de Elastic, Elasticsearch ha evolucionado constantemente para cumplir con los nuevos desafíos que surgen en el campo de la búsqueda.
En los comienzos de Elasticsearch, cuando surgieron inquietudes por la pérdida de datos, el equipo de Elastic realizó un esfuerzo de varios años para volver a escribir el sistema de coordinación de clusters a fin de garantizar que los datos reconocidos se almacenaran de forma segura. Cuando se hizo evidente que gestionar índices en grandes clusters presentaba inconvenientes, el equipo trabajó para implementar una solución de ILM amplia a fin de automatizar este trabajo permitiendo a los usuarios predefinir patrones de índice y acciones en el ciclo de vida. A medida que los usuarios fueron necesitando almacenar grandes cantidades de datos temporales y de métricas, se agregaron distintas características, como mejor compresión, para reducir el tamaño de los datos. Dado que el costo de buscar en grandes cantidades de datos fríos aumentaba, invertimos en crear snapshots buscables como una forma de buscar en los datos de los usuarios directamente en almacenes de objetos de bajo costo.
Estas inversiones sentaron las bases para la siguiente evolución de Elasticsearch. Con el crecimiento de los servicios nativos del cloud y nuevos sistemas de orquestación, decidimos que es momento de hacer avanzar Elasticsearch para mejorar la experiencia al trabajar con sistemas nativos del cloud. Creemos que estos cambios presentan oportunidades para mejoras operativas, de rendimiento y de costos mientras se ejecuta Elasticsearch en Elastic Cloud.
Hacia dónde nos dirigimos: El futuro es sin estado
Uno de los principales desafíos al operar u orquestar Elasticsearch es que depende de varias piezas de estado persistente; por lo tanto, es un sistema con estado. Las tres piezas principales son el log de transacciones, el almacén del índice y los metadatos del cluster. Este estado significa que el almacenamiento debe ser persistente y no puede perderse durante la sustitución o el reinicio de un nodo.
La arquitectura de Elasticsearch existente en Elastic Cloud debe duplicar la indexación en varias zonas de disponibilidad para proporcionar redundancia en caso de interrupciones. Nuestro objetivo es cambiar la persistencia de estos datos de los discos locales a un almacén de objetos, como AWS S3. Al depender de servicios externos para almacenar estos datos, eliminaremos la necesidad de la replicación de la indexación, lo cual reduce en gran medida el hardware asociado con la ingesta. Esta arquitectura también proporciona garantías de durabilidad muy altas gracias a la forma en que los almacenes de objetos en el cloud, como AWS S3, GCP Cloud Storage y Azure Blob Storage, replican los datos en las zonas de disponibilidad.
Descargar el almacenamiento del índice en un servicio externo también nos permitirá reestructurar Elasticsearch separando las responsabilidades de indexación y búsqueda. En lugar de tener instancias primarias y réplicas que se ocupan de ambas cargas de trabajo, nuestra intención es tener un nivel de indexación y uno de búsqueda. Separar estas cargas de trabajo permitirá escalarlas de forma independiente y que la selección de hardware esté más orientada a los casos de uso respectivos. También ayuda a resolver un desafío de larga data en el que la carga de indexación y búsqueda pueden afectarse entre sí.
Tras realizar una prueba de concepto de varios meses y una fase experimental, estamos convencidos de que estos servicios de almacén de objetos cumplen con los requisitos que visualizamos para el almacenamiento de índices y los metadatos del cluster. Nuestras pruebas y evaluaciones comparativas indican que estos servicios de almacenamiento pueden cumplir con las exigentes necesidades de indexación de los clusters más grandes que hemos visto en Elastic Cloud. Además, hacer un backup de los datos en el almacén de objetos reduce los costos de indexación y permite un ajuste simple del rendimiento de la búsqueda. Con el objetivo de buscar en los datos, Elasticsearch usará el modelo de snapshots buscables puesto a prueba en el que los datos persisten de forma permanente en el almacén de objetos nativo del cloud y los discos locales se usan como memorias caché para los datos a los que se accede con frecuencia.
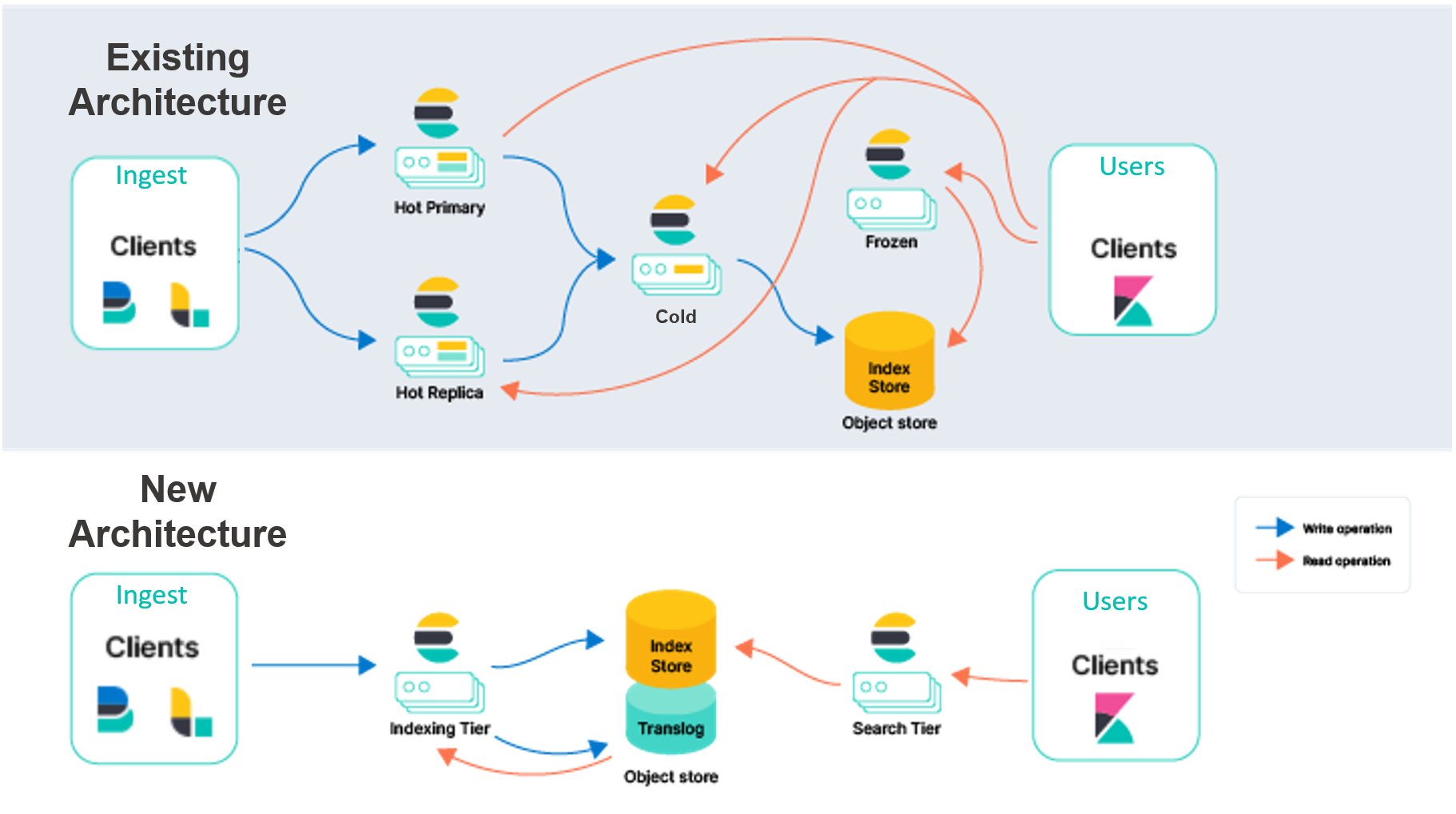
A los fines de la diferenciación, describimos nuestro modelo existente como replicación "nodo a nodo". En el nivel caliente de este modelo, los shards principal y réplica hacen el mismo trabajo duro para ocuparse de la ingesta y responder las solicitudes de búsqueda. Estos nodos son "con estado" en el sentido de que dependen de sus discos locales para persistir de forma segura los datos de los shards que hospedan. Además, los shards principal y réplica se comunican de forman constante para mantenerse en sincronía. Lo hacen replicando en el shard réplica las operaciones realizadas en el shard principal, lo que significa que el costo de esas operaciones (CPU, principalmente) se incurre para cada réplica especificada. Los mismos shards y nodos que realizan este trabajo para la ingesta también responden las solicitudes de búsqueda, por lo que el aprovisionamiento y el escalado deben hacerse teniendo en cuenta ambas cargas de trabajo.
Más allá de la búsqueda y la ingesta, los shards en el modelo de replicación de nodo a nodo se ocupan de otras responsabilidades intensivas, como la fusión de segmentos de Lucene. Si bien este diseño tiene sus méritos, vimos grandes oportunidades basadas en lo que aprendimos con los clientes a lo largo de los años y la evolución del ecosistema más amplio en el cloud.
La nueva arquitectura permite muchas mejoras inmediatas y futuras, entre ellas:
- Puedes aumentar de forma significativa el rendimiento de ingesta en el mismo hardware o, dicho de otra forma, mejorar en gran medida la eficiencia para la misma carga de trabajo de ingesta. Este aumento proviene de la eliminación de la duplicación de las operaciones de indexación de cada réplica. Las operaciones de indexación que requieren un uso intensivo de la CPU solo son necesarias una vez en el nivel de indexación, que luego envía los segmentos resultantes a un almacén de objetos. Desde allí, los datos están listos para que el nivel de búsqueda los consuma tal como se encuentran.
- Puedes separar el procesamiento del almacenamiento para simplificar la topología de tu cluster. En la actualidad, Elasticsearch tiene varios niveles de datos (contenido, caliente, tibio, frío y congelado) para emparejar los datos con el perfil de hardware. El nivel caliente es para la búsqueda casi en tiempo real, y el congelado es para los datos en los que se busca con menos frecuencia. Si bien estos niveles proporcionan valor, también aumentan la complejidad. En la nueva arquitectura, los niveles de datos ya no serán necesarios, lo que simplifica la configuración y el funcionamiento de Elasticsearch. También separamos la indexación de la búsqueda; esto reduce aún más la complejidad y nos permite escalar ambas cargas de trabajo de forma independiente.
- Puedes experimentar costos de almacenamiento mejorados en el nivel de indexación reduciendo la cantidad de datos que se deben almacenar en un disco local. En la actualidad, Elasticsearch debe almacenar una copia del shard completa en los nodos calientes (tanto el principal como el réplica) a los fines de la indexación. Con el enfoque sin estado de indexación directamente al almacén de objetos, solo se necesita una parte de esos datos locales. Solo en los casos de uso de anexado, únicamente ciertos metadatos tendrán que almacenarse para indexación. Esto reducirá en gran medida el almacenamiento local necesario para la indexación.
- Puedes bajar los costos de almacenamiento asociados con las consultas de búsqueda. Al hacer que el modelo de snapshots buscables sea el modo nativo de búsqueda de datos, el costo de almacenamiento asociado con las consultas de búsqueda se reducirá en gran medida. Según las necesidades de latencia de búsqueda para los usuarios, Elasticsearch permitirá ajustes para aumentar el almacenamiento en caché local en los datos solicitados con frecuencia.
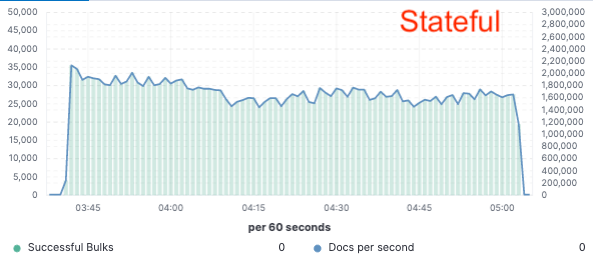
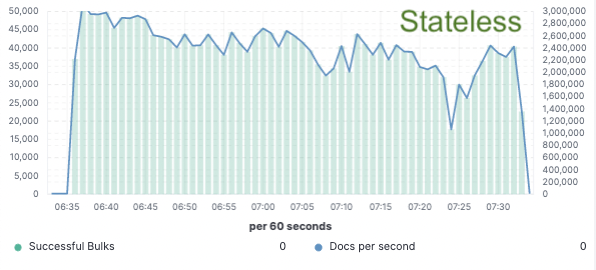
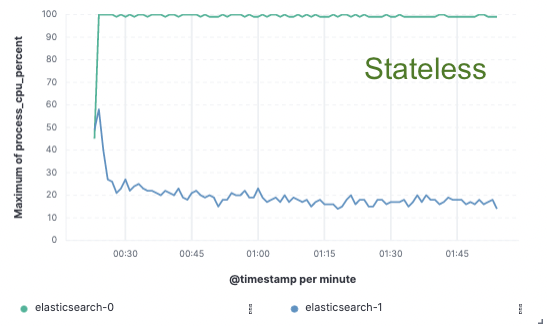
Evaluación comparativa: Mejora del 75 % del rendimiento de indexación
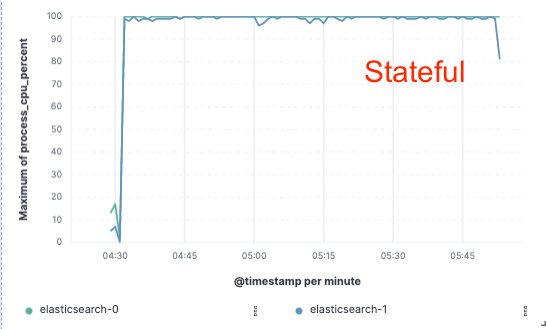
Para validar este enfoque, implementamos una prueba de concepto amplia en la que los datos solo se indexaban en un nodo y la replicación se lograba a través de los almacenes de objetos en el cloud. Descubrimos que podíamos lograr una mejora del 75 % del rendimiento de indexación eliminando la necesidad de dedicar hardware a la replicación de la indexación. Además, el costo de CPU asociado con simplemente extraer los datos del almacén de objetos era mucho menor que indexar los datos y escribirlos de forma local, lo cual es necesario para el nivel caliente en la actualidad. Esto significa que los nodos de búsqueda podrán dedicar por completo su CPU a la búsqueda.
Estas pruebas de rendimiento se realizaron en un cluster de dos nodos en los tres proveedores cloud públicos principales (AWS, GCP y Azure). Nuestra intención es seguir realizando evaluaciones comparativas más grandes en nuestra búsqueda de una implementación sin estado de producción.
Rendimiento de indexación
Uso de CPU
Sin estado para nosotros, ahorros para ti
La arquitectura sin estado en Elastic Cloud te permitirá reducir la sobrecarga de indexación, escalar independientemente la ingesta y la búsqueda, simplificar la gestión del nivel de datos y acelerar las operaciones, como escalado o actualización. Este es el primer hito hacia una modernización sustancial de la plataforma de Elastic Cloud.
Sé parte de nuestra visión sin estado
¿Te interesaría probar esta solución antes que todos? Puedes contactarnos para debatir o en nuestro canal de Slack de la comunidad. Nos encantaría recibir tus comentarios para que nos ayuden a encaminar nuestra nueva arquitectura.
Comparte
Comparte en Twitter
Comparte en LinkedIn
Comparte en Facebook
Comparte por correo electrónico
Imprime

