Presentación de snapshots buscables
Estamos entusiasmados por lanzar en la versión 7.10 los snapshots buscables (en beta), esta característica transforma la manera en la que puedes usar tu almacén de objetos preferido (como AWS S3, Microsoft Azure Storage, Google Cloud Storage o equivalente) para compensar entre reducir drásticamente los costos de almacenamiento, ingestar y retener más datos en el Elastic Stack, y el rendimiento de búsqueda rápido al que estás acostumbrado con el Elastic Stack. Si bien hemos soportado hacer backups de datos en almacenes de objetos de bajo costo durante mucho tiempo, con los snapshots buscables ahora puedes usarlos como una parte activa del almacenamiento y la búsqueda de tus datos.
Usaremos snapshots buscables para impulsar dos nuevos niveles de datos de primera clase: nivel frío, también incluido en beta en la versión 7.10, y un futuro nivel congelado. Soportamos desde hace mucho tiempo varios niveles de datos para la gestión de ciclo de vida de los datos: caliente para alta velocidad y tibio para un menor costo y rendimiento. El nuevo nivel frío, impulsado por snapshots buscables, puede reducir tus costos de almacenamiento hasta en un 50%, aumentando la densidad de almacenamiento local de tus datos de solo lectura a través de la descarga de la copia redundante de los datos a un almacén de objetos de bajo costo. El nivel congelado, actualmente en desarrollo, irá un paso más allá y almacenará por completo los datos de forma exclusiva en el almacén de objetos de bajo costo al mismo tiempo que mantendrá la capacidad de realizar búsquedas en ellos, con la caché local para búsquedas rápidas en datos a los que se accede con frecuencia. Y, como todas las características que creamos, hay API que permiten controlar directamente cómo los snapshots buscables cargan, gestionan y buscan datos en tu almacén de objetos. Estas capacidades nuevas permitirán facilitar y abaratar la gestión de tus volúmenes crecientes de datos en Elastic, lo que te empoderará para cumplir con tus requisitos de retención de datos de manera económica y al mismo tiempo posibilitará nuevos casos de uso como brindar a tu equipo la capacidad de mirar retrospectivamente sin límites investigaciones de seguridad o comparaciones de rendimiento interanuales del Viernes Negro (Black Friday).
Un viaje que evoluciona
Los datos temporales están en todas partes. Son logs, métricas, rastreos, eventos de seguridad. Son el pilar de los casos de uso de seguridad y observabilidad, y muchos más. Hemos estado invirtiendo continuamente para facilitar, acelerar y mejorar la eficiencia de la gestión y el escalado de estos datos con el tiempo. Esto es fundamental debido a la rapidez con la que aumentan. Si recopilas un terabyte de datos por día, por ejemplo, son siete terabytes a la semana. A lo largo de varios años, fácilmente aumenta a petabytes de datos. Los usuarios necesitan una forma para gestionar este crecimiento exponencial del almacenamiento y mantener la capacidad de búsqueda en él.
Nuestro enfoque para resolver este problema ha sido observar el ciclo de vida de los datos. Cuando los datos se ingestan por primera vez, es probable que se realicen muchas búsquedas en ellos. Cuando investigas un incidente, por ejemplo, necesitas acceso rápido a todos los datos relevantes para identificar y resolver el problema. Cuando un atacante compromete un host o una aplicación, tu capacidad de responder con rapidez suele determinar el impacto de la vulneración. Pero los datos también se pueden categorizar en diferentes niveles de uso según la fuente o el tipo. Es posible que algunos datos solo sean necesarios por motivos legales o de cumplimiento, o para mirar retrospectivamente de forma ocasional para una comparación. Por lo tanto, los usuarios necesitan diferentes niveles de potencia de procesamiento y almacenamiento para estos distintos niveles de necesidades, ya sea que se basen en la antigüedad, la fuente de los datos u otros criterios.
Nuestra misión ha sido brindarte la capacidad de equilibrar el costo, el rendimiento y las capacidades para cumplir con tus necesidades. Esto involucra inversión en todos los niveles de nuestro stack, pero un pilar central en nuestro enfoque son los niveles de datos, que gestionan el ciclo de vida de los datos. Este concepto no es nuevo, ha estado desde las primeras versiones del Elasticsearch. La gestión de ciclo de vida del índice (ILM) proporciona algunas convenciones para facilitar la gestión de datos en nodos calientes (máquinas rápidas con SSD) y tibios/cálidos (máquinas de menor costo que pueden tener discos giratorios), y en Elastic Cloud hemos brindado soporte para ella durante años. La gestión de ciclo de vida de snapshots (SLM) facilita aún más el uso de almacenes de objetos de bajo costo de AWS, Google, Azure y proveedores de almacenamiento en las instalaciones para realizar y almacenar backups. Si bien estos snapshots son una pieza clave en muchos despliegues, no han sido una parte activa de la división en niveles de los datos. ¿Por qué? Porque no se podía buscar en los snapshots. Pero eso cambiará ahora con los snapshots buscables, gracias a los que podemos crear niveles de datos nuevos y más económicos que aprovechen estos almacenes de objetos de bajo costo y le den vida a tus backups.
Presentación de snapshots buscables
Estamos muy entusiasmados por los snapshots buscables debido a que nos permiten usar S3 y otros almacenes de objetos de formas completamente nuevas. Aunque puedes continuar usando tu almacén de objetos para almacenar como snapshots los datos de los que hiciste backup, ahora puedes darle vida a ese almacén de objetos y mantenerlo siempre en línea y disponible haciendo que se pueda buscar directamente en los snapshots con Elasticsearch. Para crear esto y brindar una buena experiencia, hicimos cambios en todas las capas de nuestros productos: desde Kibana y Elasticsearch hasta Lucene. De hecho, usamos nuestra amplia experiencia en Lucene con el objetivo de optimizar el mecanismo de búsqueda para desplegar solo los subconjuntos del índice de snapshots realmente necesarios para responder a tu búsqueda o cargar tu dashboard. Los snapshots buscables aceleran y permiten realizar sin problemas el proceso de recuperar datos de tus índices respaldados con snapshots en S3 u otros almacenes de objetos, y también nos han permitido desarrollar niveles de datos nuevos que te ofrecen más valor a un costo más bajo.
El nivel frío
El nuevo nivel frío, disponible en beta en la versión 7.10, reduce tu almacenamiento en cluster hasta en un 50 % en comparación con el nivel tibio. Mantiene el mismo nivel de confiabilidad y redundancia que los niveles caliente y tibio, con soporte total de recuperación automática ante fallas de hardware en cualquiera de tus nodos. Esto hace que sea mucho más económico hacer preguntas sobre tus datos como "¿cómo se compara este pico con el mes pasado?" o "¿este usuario inició sesión en un sistema restringido en los últimos 6 meses?".
¿Cómo lo hicimos? Bueno, en los niveles caliente y tibio, la mitad de los discos se usan para almacenar shards de réplica. Estas copias redundantes aseguran un rendimiento de búsqueda rápido y constante, y te proporcionan resistencia en caso de que falle una máquina. Si sucede eso, una réplica ocupa el lugar primario sin problemas, y tu indexación y búsquedas continúan sin cesar.
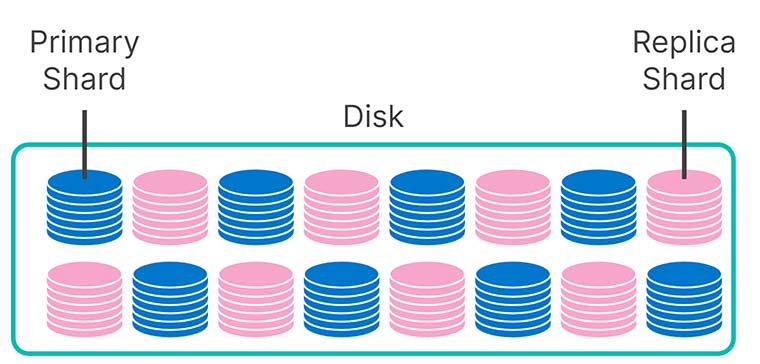
Pero una vez que tus datos se convierten en de solo lectura, la redundancia puede descargarse con facilidad. Tu repositorio de snapshots es perfecto para esto debido a que es mucho más económico almacenar datos en S3 que en discos giratorios o SSD locales. Entonces, en el nivel frío, tus shards de réplica se almacenan en S3 como snapshots. Como resultado, duplicamos la capacidad utilizable de tus nodos fríos por el mismo costo que antes, con un impacto modesto en el rendimiento de búsquedas.
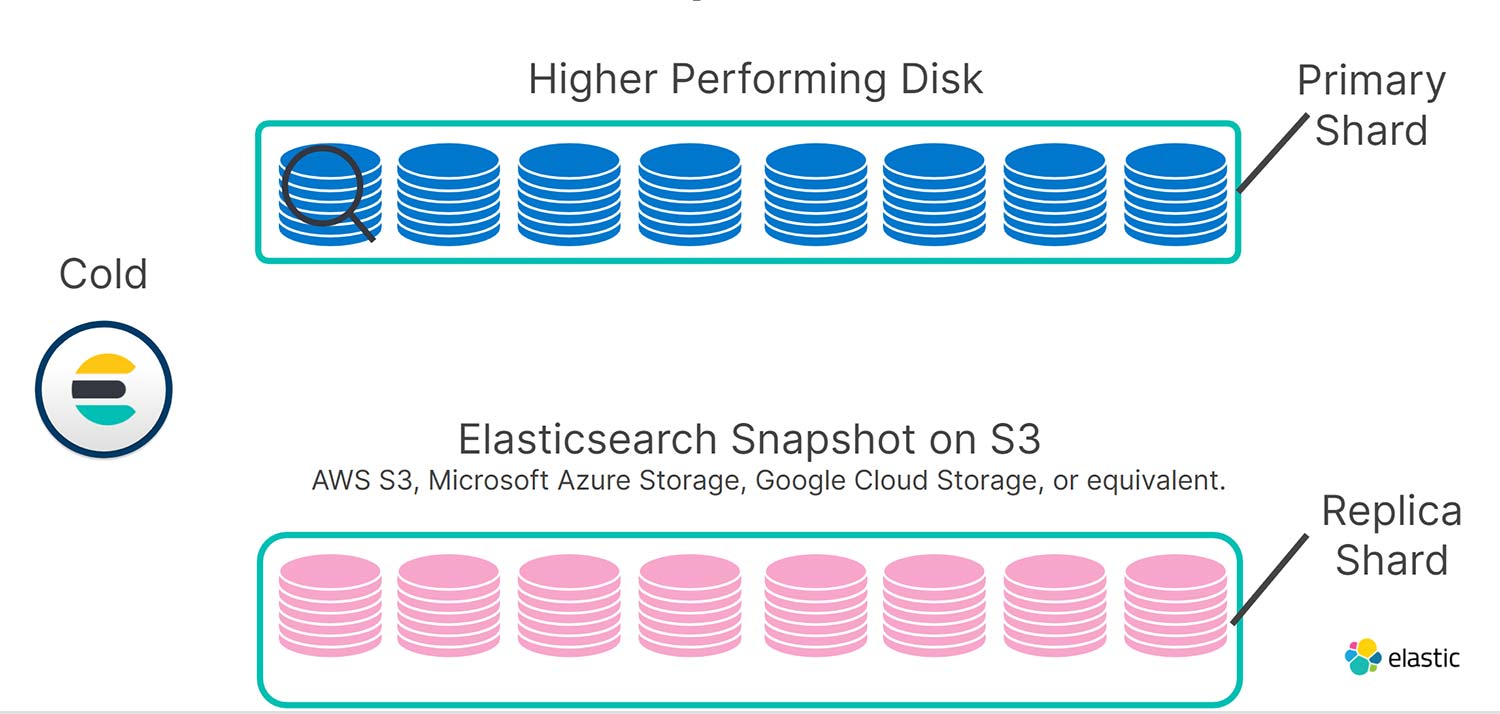
Si hay un fallo del disco o nodo local en el nivel frío, usamos snapshots que permiten búsqueda para la recuperación de forma automática con los índices de réplica almacenados como snapshots en S3, haciendo que estos índices estén disponibles para atender las solicitudes de búsqueda en una fracción del tiempo necesario para realizar una restauración desde snapshots habitual. Así es como todo se combina.
El nivel congelado
Imagina si pudieras mirar retrospectivamente sin límites tus investigaciones de seguridad o si pudieras explorar los datos sin procesar de APM para ver cómo cambió el comportamiento de tus clientes durante los últimos dos años. Es entonces que entra en juego el nivel congelado y abre paso a casos de uso completamente nuevos con tipos y volúmenes de datos para los que previamente no era económico usar Elasticsearch. Piensa en lo poderoso que puede ser el concepto de S3 que permite búsqueda para tus objetivos comerciales. Actualmente en desarrollo activo, el nivel congelado te permitirá buscar directamente en los datos almacenados en S3 o tu almacén de objetos preferido. Con el nivel congelado, no habrá necesidad en lo absoluto de almacenar ninguno de tus datos de forma local, todo puede estar simplemente almacenado como snapshots en S3. Lo bueno del nivel congelado: no es necesario extraer los datos congelados y rehidratarlos en el improbable caso de que necesites acceder a ellos para una auditoría o investigación de seguridad. Puedes simplemente usar los snapshots que permiten búsqueda para ejecutar tus búsquedas en ellos de forma directa.
Con el nivel congelado, lo que ofreceremos no tiene precedentes: la capacidad de buscar una cantidad casi ilimitada de datos, a demanda, con costos similares al de almacenar esos datos en S3. El ciclo de vida completamente automatizado de tus datos se completa: de caliente a tibio, frío y después congelado, y al mismo tiempo te aseguras tener el acceso y rendimiento de búsqueda que necesitas al menor costo de almacenamiento posible.
Optimización para la mejor experiencia del usuario
Lanzar nuevas capacidades innovadoras es una cosa, y siempre nos esforzaremos por hacerlo. Pero la otra pieza clave en esto es asegurarse de que todo lo demás funcione bien al unísono con estas características nuevas para ofrecerte la mejor experiencia del usuario posible.
- Configuración de niveles de datos simplificada: simplificamos y optimizamos en gran medida la forma en que configuras tus niveles de datos y políticas de ILM con roles nuevos que le asignas a tus nodos de datos, que después usa el Elastic Stack para asignar de forma automática tus datos al nivel adecuado cuando se usa la gestión de ciclo de vida del índice.
- Búsqueda asíncrona: aunque hicimos todo lo posible para que la búsqueda en S3 sea rápida, no somos magos. Las búsquedas en S3 simplemente tomarán más que milisegundos. Y cuando lo hacen, queremos proporcionar la mejor experiencia del usuario posible. Es por eso que desarrollamos un mecanismo de búsqueda asíncrono en Elasticsearch que mejora de forma significativa la experiencia en Kibana con las búsqueda que toman tiempo. Ahora puedes ejecutar una solicitud de búsqueda de forma asíncrona sin tener que esperar los resultados. En cambio, puedes monitorear el progreso de la solicitud y recuperar los resultados en una etapa posterior. Incluso puedes recuperar resultados parciales a medida que estén disponibles antes de que se haya completado la búsqueda.
- Eficiencia de la búsqueda: presentamos una serie de mejoras para omitir la búsqueda en índices que no coinciden o ni siquiera son necesarios cuando ejecutas una búsqueda. Por ejemplo, los índices que sabemos que no tendrán ninguna coincidencia se omiten de forma automática a través del filtrado previo basado en la hora u otras propiedades en los datos. También se hace una salida anticipada de las búsquedas cuando resulta posible, usando Block-Max WAND para la búsqueda de texto, búsquedas clasificadas que clasifican los shards en los que buscamos, deteniendo la búsqueda cuando tenemos suficientes coincidencias, etc.
Cada mejora ofrece valor en sí, pero el conjunto completo supera la suma de sus partes. Mantenemos constantemente el panorama completo en mente a medida que desarrollamos características y las vinculamos sin problemas con todas las capacidades ya disponibles en el Elastic Stack.
Cómo solucionar casos de uso y nuestras soluciones
Imagina el valor que podrías liberar si pudieras buscar de forma fácil y económica en años de logs, métricas y rastreos de APM con snapshots que permiten búsqueda en almacenes de objetos como S3. ¡Hasta la vista, rehidratación de datos! Con los snapshots que permiten búsqueda y Elastic Observability, podrás buscar directamente en años de datos archivados sin necesidad de pasar por el proceso lento y costoso de restaurar índices a partir de snapshots antes de hacer una búsqueda.
¿Y si pudieras equipar a los buscadores de amenazas y analistas con años de fuentes de datos de seguridad de gran volumen en almacenes de objetos como S3, accesibles con facilidad a través de snapshots que permiten búsqueda? Con los snapshots que permiten búsqueda y Elastic Security, puedes recopilar datos relacionados con la seguridad de gran volumen, como datos de IDS, NetFlow, DNS, PCAP o endpoint a mayor escala y mantenerlos accesibles durante más tiempo del que solía ser práctico en nuevos niveles de datos que reducen los costos y preservan la capacidad de búsqueda.
Por último, considera la capacidad de buscar en todo el contenido de las aplicaciones y registros históricos del lugar de trabajo sin gastar demasiado gracias a la búsqueda en almacenes de objetos con snapshots que permiten búsqueda. Elastic Enterprise Search también se beneficiará con las nuevas capacidades de snapshots que permiten búsqueda que se lanzarán en el Elastic Stack. Cuando das soporte a órdenes adicionales de magnitud de contenido de aplicaciones o buscas en registros históricos de la organización que pueden almacenarse de forma segura en almacenes de objetos como S3, puedes almacenar todo el contenido archivado e histórico de una forma que permita la búsqueda sin gastar demasiado.
El viaje continúa
Estamos entusiasmados por los grandes pasos que dimos con los lanzamientos en beta de los snapshots que permiten búsqueda y el nivel frío en la versión 7.10. Y también nos entusiasma lo que tenemos por delante: un nivel congelado próximamente y niveles frío y congelado gestionados con controles deslizantes simples en Elastic Cloud para simplificar en verdad el flujo de registro y suscripción para los usuarios. Como siempre, el viaje es continuo para nosotros, y lo que nos mantiene en marcha es el valor adicional constante que te seguimos proporcionando con cada lanzamiento.

Comienza hoy mismo
Para comenzar con los snapshots buscables y comenzar a almacenar datos en el nivel frío, activa un cluster en Elasticsearch Service o instala la versión más reciente del Elastic Stack. ¿Ya tienes Elasticsearch en ejecución? Solo actualiza los clusters a la versión 7.10 y pruébalo. Si deseas conocer más información, puedes leer la documentación sobre niveles de datos y snapshots buscables.