El esquema durante la escritura en comparación con el esquema durante la lectura
El Elastic Stack (o ELK Stack, como se conoce en general) es un lugar popular para almacenar logs.
Muchos usuarios comienzan almacenando logs sin estructura más allá de parsear la marca de tiempo y, quizás, agregar algunas etiquetas simples que permitan un filtrado sencillo. Filebeat hace exactamente eso de forma predeterminada: muestra el final de los logs y los envía a Elasticsearch lo más rápido posible sin extraer ninguna estructura adicional. La UI de Logs en Kibana no asume nada sobre la estructura de los logs; un simple esquema de “@timestamp” y “message” es suficiente. Llamamos a esto el enfoque de esquema mínimo para logging. Es menos exigente para el disco, pero no muy útil excepto para búsquedas de palabras clave simples y filtros basados en etiquetas.
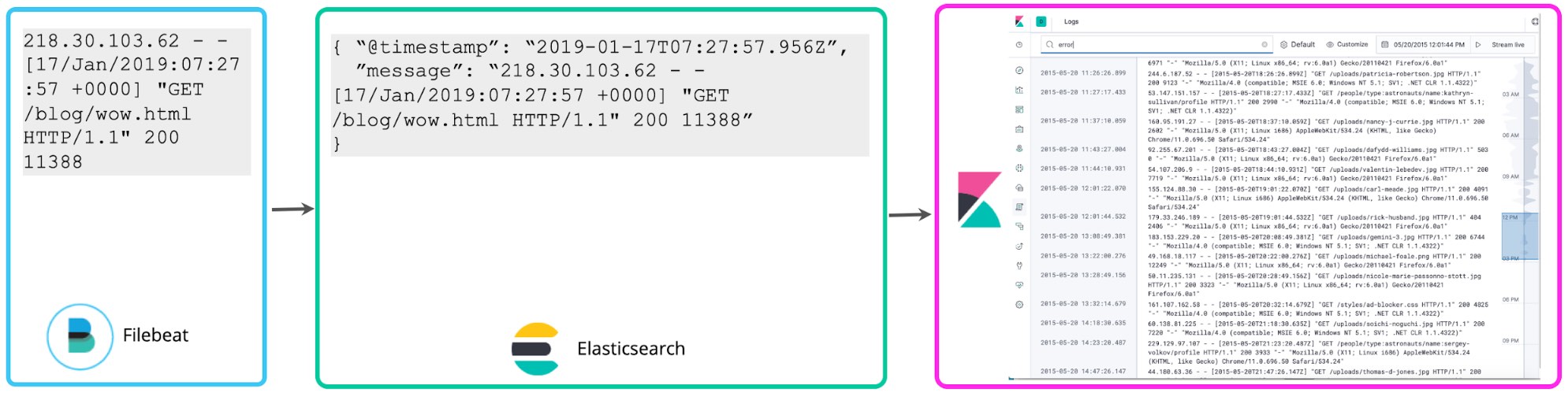
Una vez familiarizado con tus logs, por lo general querrás hacer más con ellos. Si observas una correlación entre los números de los logs y los códigos de estado, quizás quieras contarlos para saber cuántos códigos http 5xx tuviste en la última hora. Los campos con script de Kibana te permiten aplicar el esquema sobre los logs al momento de la búsqueda para extraer estos códigos de estado y realizar agregaciones, visualizaciones y otros tipos de acciones en ellos. Generalmente se hace referencia a este enfoque sobre logging como esquema durante la lectura.
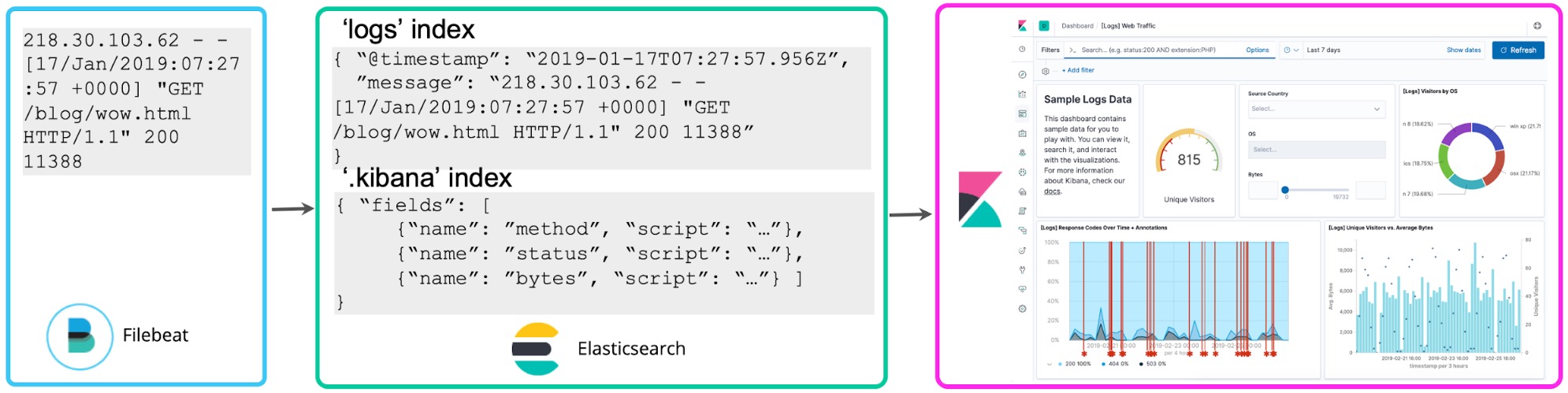
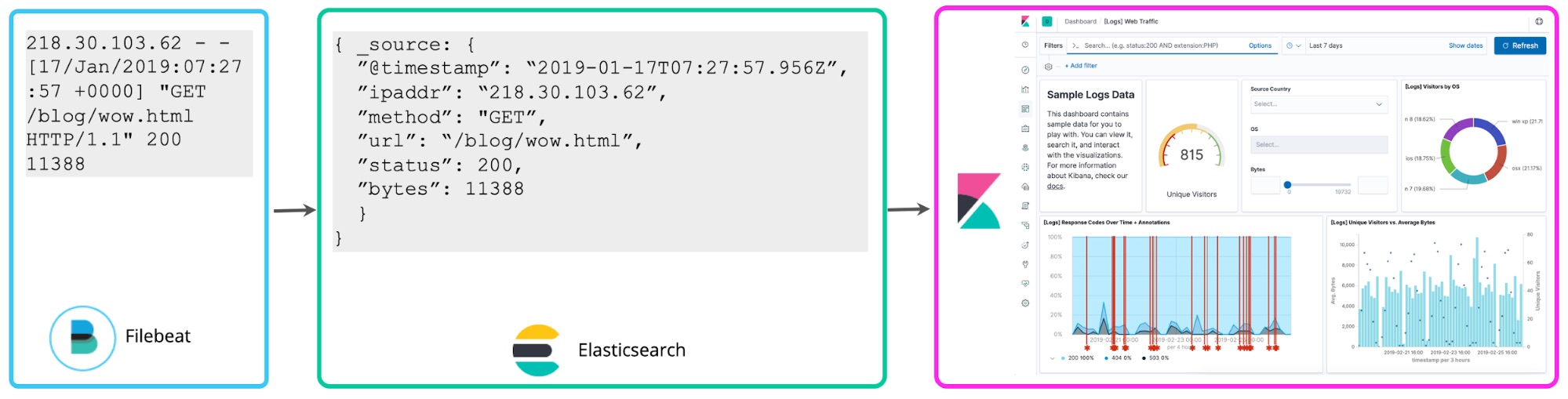
Si bien resulta conveniente para la exploración personalizada, la desventaja de este enfoque es que si lo adoptas para la creación continua de reportes y dashboards, volverás a ejecutar la extracción del campo cada vez que realices una búsqueda o vuelvas a representar la visualización. En cambio, una vez que hayas decidido qué campos estructurados deseas, se puede iniciar un proceso de reindexación en segundo plano para “hacer persistir” estos campos con script en los campos estructurados en un índice de Elasticsearch permanente. En cuanto a los datos que se transmiten a Elasticsearch, puedes configurar un pipeline de Logstash o pipeline de ingest node para extraer proactivamente estos campos usando los procesadores dissect o grok.
Lo cual nos lleva a un tercer enfoque: el parseo de logs al momento de la escritura para extraer proactivamente los campos antes mencionados. Estos logs estructurados aportan mucho valor adicional a los analistas, quienes ya no necesitan averiguar cómo extraer los campos con posterioridad, lo que acelera sus búsquedas y aumenta dramáticamente el valor que obtienen de los datos de logs. Muchos usuarios de ELK adoptaron este enfoque de “esquema durante la escritura” para la analítica de logs centralizada.
En este blog, analizaremos los pros y los contras de estos enfoques, y cómo abordarlos desde la perspectiva de planificación. Haremos una revisión de por qué estructurar los logs por adelantado tiene un valor intrínseco y por qué creemos que es la dirección natural de evolución, a medida que avanza el despliegue de logging centralizado, incluso si comienzas con poca estructura por adelantado.
Exploración de los beneficios del esquema durante la escritura (y destrucción de mitos)
Comencemos por el motivo por el cual querrías estructurar los logs cuando los escribes en un cluster de logging centralizado.
Mejor experiencia de búsqueda. Cuando buscas información valiosa en los logs, lo más natural es comenzar por buscar simplemente una palabra clave como “error”. Es posible devolver resultados de una búsqueda de ese tipo tratando cada línea de log como un documento en un índice invertido y realizando una búsqueda de texto completo. Sin embargo, ¿qué sucede cuando deseas hacer preguntas más complejas, como “Muéstrame todas las líneas de log en las que my_field sea igual a N”? Si no definiste el campo my_field, no puedes hacer esta pregunta directamente (sin autocompletar). E incluso si observas que tu log tiene esta información, ahora debes escribir la regla de parseo como parte de la búsqueda para extraer el campo y compararlo con el valor esperado. En el Elastic Stack, cuando estructuras los logs por adelantado, la característica de autocompletar de Kibana sugerirá automáticamente campos y valores para crear tus búsquedas. Esto incrementa enormemente la productividad de los analistas. Ahora, tú y tus colegas pueden realizar preguntas directamente, sin que cada uno deba averiguar cuáles son los campos y escribir reglas de parseo complejas al momento de la búsqueda para extraer los campos.
Búsquedas históricas y agregaciones más rápidas. Las búsquedas sobre campos estructurados en el Elastic Stack, incluso ejecutadas en grandes cantidades de datos históricos, devolverán la información en cuestión de milisegundos. Compara eso con los minutos u horas que se tarda en devolver una respuesta en los sistemas típicos de “esquema durante la lectura”. Esto se debe a que es mucho más rápido filtrar y ejecutar agregaciones estadísticas en campos estructurados extraídos e indexados por adelantado que ejecutar regex en cada línea de log para extraer el campo y actuar sobre este matemáticamente. Esto resulta especialmente importante para las búsquedas personalizadas, cuyos resultados no pueden acelerarse por adelantado, debido a que no sabes qué búsquedas ejecutarás durante la investigación.
Logs a métricas. En relación con lo anterior, el resultado de extraer valores numéricos de los logs estructurados tiene una semejanza sorprendente con las series temporales numéricas o las métricas. Ejecutar agregaciones rápidamente sobre estos puntos de datos valiosos tiene un valor enorme desde una perspectiva operativa. Los campos estructurados te permiten tratar los puntos de datos numéricos de los logs como métricas a escala.
Verdad a tiempo. Cuando necesitas resolver campos como una dirección IP a un nombre de host, debes hacerlo al momento de la indexación y no más adelante durante la búsqueda, debido a que es posible que las resoluciones ya no sean válidas para la transacción anterior: es posible que una semana después esa IP esté vinculada a un nombre de host totalmente diferente. Esto aplica a las búsquedas en cualquier fuente externa, que solo ofrece la snapshot más reciente del mapeo, como la resolución del nombre de usuario en sistemas de administración de identidades, la etiqueta de activo en CMDB, etc.
Detección de anomalías y alertas en tiempo real. De forma similar a las agregaciones, la detección de anomalías y las alertas en tiempo real funcionan de manera más eficiente al escalar con campos estructurados. De lo contrario, los requisitos de procesamiento continuo en su cluster son bastante costosos. Hablamos con muchos clientes que no pueden crear trabajos de detección de anomalías y alertas debido a que simplemente no es posible escalar la extracción de campos al momento de la búsqueda a la cantidad de alertas que necesitan. Esto significa que los datos de logs que recolectan solo son adecuados para los casos de uso de gran reactividad y limitan el retorno de la inversión en ese proyecto.
Logs en iniciativas de observabilidad. Si tienes en marcha una iniciativa de observabilidad, sabes que simplemente recolectar y buscar logs no es suficiente. Idealmente, los datos de logs deberían estar correlacionados con métricas (por ejemplo, uso de recursos) y rastros de aplicaciones para brindarle a un operador la historia completa sobre lo que sucede con el servicio, sin importar de dónde provengan los puntos de datos. Estas correlaciones funcionan mejor en campos estructurados; de lo contrario, las búsquedas son lentas y el análisis es poco utilizable en situaciones prácticas a escala.
Calidad de datos. Cuando tus eventos están sujetos al procesamiento por adelantado, tienes la oportunidad de comprobar que no haya datos no válidos, duplicados o faltantes, y de corregir estos problemas. Si dependes de un esquema durante la lectura, no sabes si los resultados que se devuelven son precisos, debido a que no se verificó por adelantado su validez e integridad. Esto puede llevar a resultados imprecisos y conclusiones incorrectas basadas en los datos devueltos.
Control de acceso granular. Resulta desafiante aplicar reglas de seguridad granular, como restricciones a nivel del campo, sobre datos de logs no estructurados. Los filtros que restringen el acceso a los datos durante la búsqueda pueden ayudar, pero tienen limitaciones importantes, como la incapacidad de devolver resultados parciales que consistan en un subconjunto de los campos. En el Elastic Stack, la seguridad a nivel del campo permite a los usuarios con un conjunto de privilegios inferior ver algunos campos y no otros del set de datos completo. Entonces, proteger los datos PII en logs y permitir que un conjunto más amplio de usuarios opere sobre otra información se vuelve mucho más fácil y flexible.
Requisitos de hardware
Un mito común sobre el “esquema durante la escritura” es que automáticamente significa que tu cluster requerirá más recursos para parsear los logs y almacenar tanto los formatos no parseados como los parseados (o “indexados”). Veamos algunos pros y contras que debes considerar particularmente en tu caso de uso, porque la respuesta, de hecho, es “depende”.
Parseo por única vez en comparación con extracción de campos continua. Parsear y almacenar los logs en un formato estructurado sí consume capacidad de procesamiento del lado de la ingesta. Sin embargo, ejecutar búsquedas repetidas sobre logs no estructurados que ejecutan expresiones regex complejas para extraer campos consume muchos más recursos de RAM y CPU de forma continua. Si anticipas que el caso de uso común para tus logs será solamente participar en una búsqueda ocasional, quizás estructurarlos por adelantado resulte exagerado. Pero si anticipas una búsqueda activa en los logs y la ejecución de agregaciones sobre los datos de logs, el costo de la ingesta por única vez puede ser menor que el costo continuo de volver a ejecutar las mismas operaciones al momento de la búsqueda.
Requisitos de ingesta. Con el procesamiento adicional por adelantado, el rendimiento de la ingesta puede ser un poco menor en comparación con lo que sería si no hicieras nada. Puedes introducir una infraestructura de ingesta adicional para manejar esa carga, escalando independientemente tus ingest nodes de Elasticsearch o instancias de Logstash. Existen buenos recursos y blogs sobre cómo abordar esto, y si usas Elasticsearch Service en Elastic Cloud, escalar la ingesta es tan sencillo como agregar más nodos “con capacidad de ingesta”.
Requisitos de almacenamiento. La verdad, por ilógica que parezca, es que los requisitos de almacenamiento pueden de hecho ser menores cuando te esfuerzas por comprender la estructura de tus logs por adelantado. Los logs pueden ser detallados y desmedidos. Si los examinas por adelantado (incluso si no parseas cada campo), puedes decidir qué líneas de logs y campos extraídos mantener en línea para la búsqueda en tu cluster de logs centralizado y qué archivar de inmediato. Este enfoque puede reducir los requisitos generales del disco respecto al almacenamiento de logs detallados y desmedidos. Filebeat tiene procesadores dissect y drop ligeros precisamente con este fin.
Incluso si debes mantener todas las líneas de los logs debido a requisitos normativos, existen maneras de optimizar los costos de almacenamiento con el “esquema durante la escritura”. En primer lugar, tú tienes el control; no es necesario que estructures por completo los logs. Si resulta necesario en tu caso de uso, agrega solo algunos metadatos estructurados importantes y deja el resto de la línea de log sin parsear. Por otra parte, si estructuras por completo tus logs y cada dato importante termina en un almacenamiento estructurado, no es necesario mantener el campo “source” en el mismo cluster que los logs indexados, puedes archivarlo en un almacenamiento económico.
También existen muchas formas de optimizar los valores predeterminados de Elasticsearch si el almacenamiento sigue siendo una cuestión importante; puedes reducir las proporciones de compresión con unas simples correcciones. También puedes usar arquitecturas calientes-tibias e índices congelados para aprovechar al máximo el almacenamiento en lo que respecta a datos a los que se accede con menor frecuencia almacenados por períodos de retención mayores. Sin embargo, debes recordar que, en lo que respecta a datos calientes, el almacenamiento es relativamente económico en comparación con los minutos de espera para obtener una respuesta a una búsqueda cuando más la necesitas.
Definición de la estructura por adelantado
Otro mito que escuchamos es que es difícil estructurar los logs antes de almacenarlos. Derribemos este mito.
Logs estructurados. Muchos logs ya están generados en formatos estructurados. Las aplicaciones más comunes soportan el logging directamente en JSON. Esto significa que puedes comenzar a ingestar tus logs directamente en Elasticsearch y almacenarlos en formatos estructurados sin necesidad de parsearlos.
Reglas de parseo prediseñadas. Existen docenas de reglas de parseo prediseñadas que Elastic soporta de manera oficial. Por ejemplo, los Filebeat modules estructuran por ti logs de proveedores conocidos, y Logstash contiene una amplia biblioteca de patrones grok. Hay muchas más reglas de parseo prediseñadas disponibles en la comunidad.
Reglas de parseo autogeneradas. Herramientas como Kibana Data Visualizer, que automáticamente sugieren cómo parsear los logs, ayudan a definir reglas para extraer campos de logs personalizados. Simplemente pega una muestra del log y obtén un patrón grok que puedes usar en el ingest node o Logstash.
Qué sucede cuando cambia el formato de log
El último mito es que el “esquema durante la escritura” dificulta el trabajo con formatos de log cambiantes. Esto sencillamente no es cierto. Alguien deberá ocuparse de los formatos de log cambiantes, independientemente del enfoque que tomes para extraer inteligencia de los logs, por adelantado o posteriormente, suponiendo que haces algo más que una búsqueda de texto completo. Ya sea que tengas un pipeline de ingest node que aplica el patrón grok al log a medida que se indexa o un campo con script de Kibana que hace lo mismo al momento de la búsqueda, cuando cambia el formato del log, será necesario modificar los campos de extracción de lógica. Ten en cuenta que para los Filebeat modules que mantenemos, hacemos un seguimiento de cuándo los proveedores de log anteriores en la cadena lanzan versiones nuevas y actualizamos la compatibilidad luego realizar pruebas.
Existen varios enfoques para trabajar con las estructuras de log cambiantes al momento de la escritura.
Modificar la lógica de parseo por adelantado. Si sabes que el formato de log cambiará, puedes crear un pipeline de procesamiento paralelo y dar soporte a ambas versiones del log durante un período de transición. Esto aplica, por lo general, a los formatos de los logs que controlas de forma interna.
Escribir un esquema mínimo cuando ocurre un error de parseo. No todos los cambios se conocen por anticipado y, en ocasiones, los logs que no están bajo tu control cambian sin previo aviso. Podrás dar cuenta de esta eventualidad en el pipeline de logs desde el comienzo. Cuando ocurra un error de parseo de grok, escribe un esquema mínimo de marca de tiempo y un mensaje no parseado, y envía una alerta al operador. En ese punto, es posible crear un campo con script para el formato de log nuevo (para evitar la interrupción en el flujo de trabajo del analista), modificar el pipeline en adelante y considerar reindexar los campos por la breve duración de la interrupción en la lógica de parseo.
Retrasar la escritura del evento cuando ocurre un error de parseo. Si escribir un esquema mínimo no es útil, puedes no escribir la línea de log (si la lógica de parseo falla), dejar el evento de lado en una “cola de mensajes fallidos” (Logstash ofrece esta funcionalidad de fábrica) y enviar la alerta al operador, que puede arreglar la lógica y volver a ejecutar los eventos desde la cola de mensajes fallidos a través de un pipeline de parseo nuevo. Esto crea una interrupción en el análisis, pero no tendrás que ocuparte de campos con script ni de reindexar.
Una analogía apropiada
Esto se está haciendo bastante extenso, te felicitamos por llegar hasta aquí. Hay algo que nos ayuda a interiorizar un concepto: una buena analogía. Y hablando con Neil Desai, Especialista en seguridad de Elastic, escuchamos una de las mejores analogías para “esquema durante la lectura” en comparación con “esquema durante la escritura”, y esperamos que también te resulte útil.

En conclusión: la decisión es tuya
Como mencionamos al comienzo, no hay necesariamente una respuesta única para todos los despliegues de logging centralizado en lo que respecta a “esquema durante la escritura” en comparación con “esquema durante la lectura”. De hecho, la mayoría de los despliegues que vemos se encuentran en un punto intermedio: estructuran algunos logs en gran medida y dejan otros en el esquema más básico (@timestamp y message). Todo depende de qué estés intentando hacer con los logs y de si valoras la velocidad y eficiencia de las búsquedas estructuradas en comparación con la escritura de datos en el disco tan pronto como sea posible sin complicaciones por adelantado. El Elastic Stack soporta ambas opciones.
Para comenzar con los logs en el Elastic Stack, activa un cluster en Elasticsearch Service o descárgalo localmente. Consulta la app nueva Logs en Kibana que optimiza tu flujo de trabajo para trabajar con logs en cualquier forma o estado, estructurados o no.