Cómo importar archivos CSV y datos de logs a Elasticsearch con File Data Visualizer
Una novedad de la versión 6.5 del Elastic Stack es la nueva característica File Data Visualizer. Esta nueva característica le permite al usuario cargar un archivo que contiene texto delimitado (por ejemplo, CSV), NDJSON o texto semiestructurado (por ejemplo, archivos de logs) para que el nuevo punto final find_file_structure de Machine Learning de Elastic lo analice e informe sus hallazgos sobre los datos. Esto incluye un proceso de ingesta de pipelines sugerido y mapeos que pueden usarse para importar el archivo a Elasticsearch desde la UI.
El objetivo de esta característica es permitir que los usuarios que deseen explorar sus datos con Kibana o Machine Learning obtengan fácilmente pequeñas cantidades de datos en Elasticsearch sin tener que aprender las complejidades del proceso de ingesta.
Un buen ejemplo reciente es este blog, escrito por un miembro del equipo de marketing de Elastic, que no tiene experiencia en desarrollo. Mediante File Data Visualizer, pudo importar fácilmente datos de terremotos a Elasticsearch, lo cual lo ayudó a explorar y analizar las ubicaciones de los terremotos mediante visualizaciones geo_point en Kibana.
Ejemplo: importar un archivo CSV a Elasticsearch
La mejor manera de demostrar esta funcionalidad es con un ejemplo. En el siguiente ejemplo, se usan datos de un archivo CSV que contiene datos imaginarios de un sitio web de reservaciones de vuelos. Aquí mostramos solo las primeras cinco líneas del archivo para que tengas una idea de cómo se ven los datos:
time,airline,responsetime 2014-06-23 00:00:00Z,AAL,132.2046 2014-06-23 00:00:00Z,JZA,990.4628 2014-06-23 00:00:00Z,JBU,877.5927 2014-06-23 00:00:00Z,KLM,1355.4812
Configurar el archivo CSV importado dentro de File Data Visualizer
En Kibana, la característica File Data Visualizer se encuentra en la sección Machine Learning > Visualización de datos. Al usuario se le presenta una página que le permite seleccionar o arrastrar y soltar un archivo. A partir de la versión 6.5, limitamos el tamaño del archivo a un máximo de 100 MB.
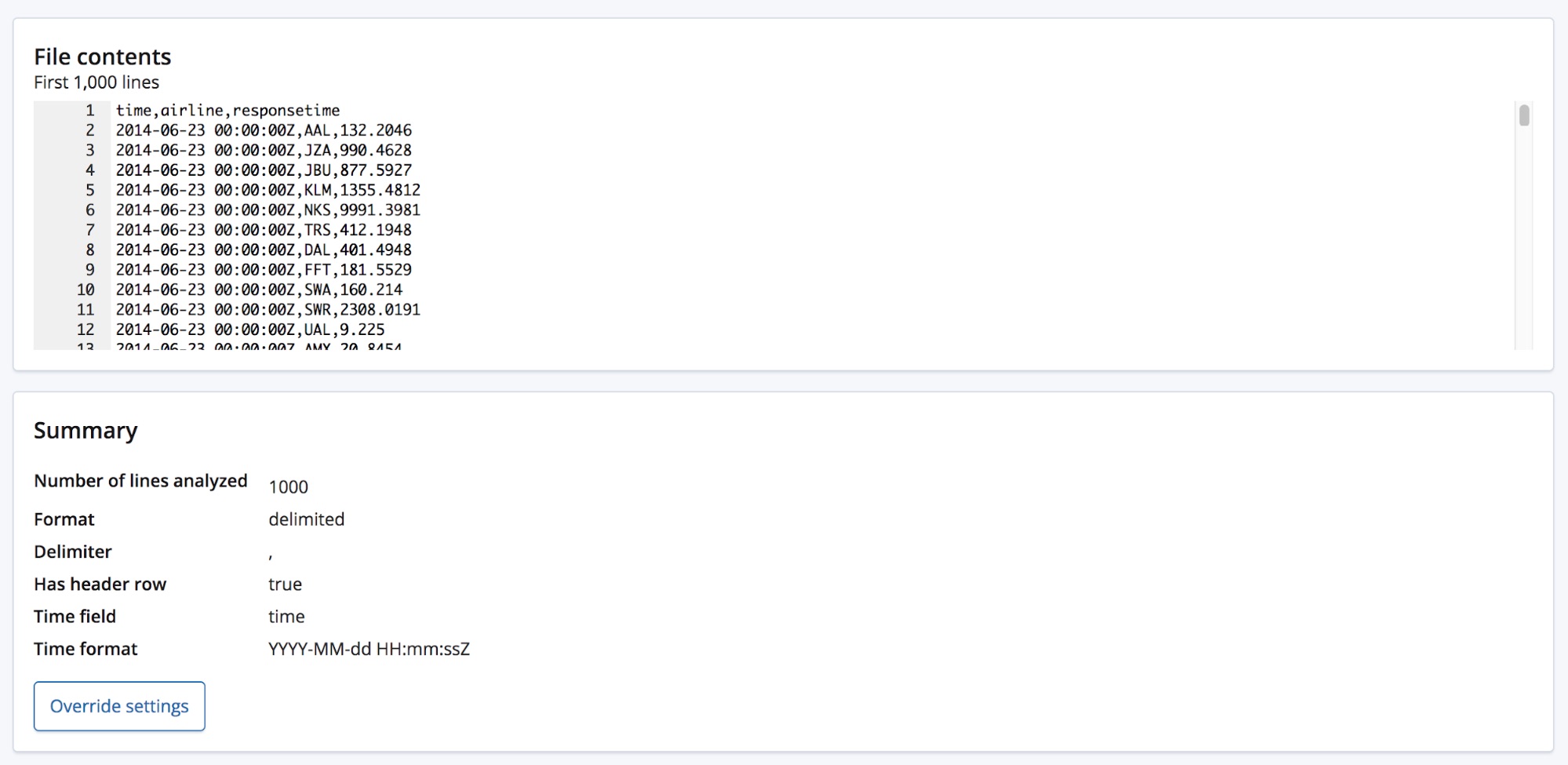
Cuando seleccionamos el archivo CSV, la página envía las primeras 1000 líneas del archivo al punto final find_file_structure, que ejecuta el análisis y devuelve los hallazgos. Si vemos la sección Resumen en la UI, podemos ver que detectó correctamente que los datos están en un formato delimitado y que el delimitador es un carácter de coma.
También detectó que hay una fila de encabezado y usó estos nombres de campo para etiquetar los datos en cada columna. La primera columna coincidió con un formato de fecha conocido y, por lo tanto, se resalta como el campo Tiempo.
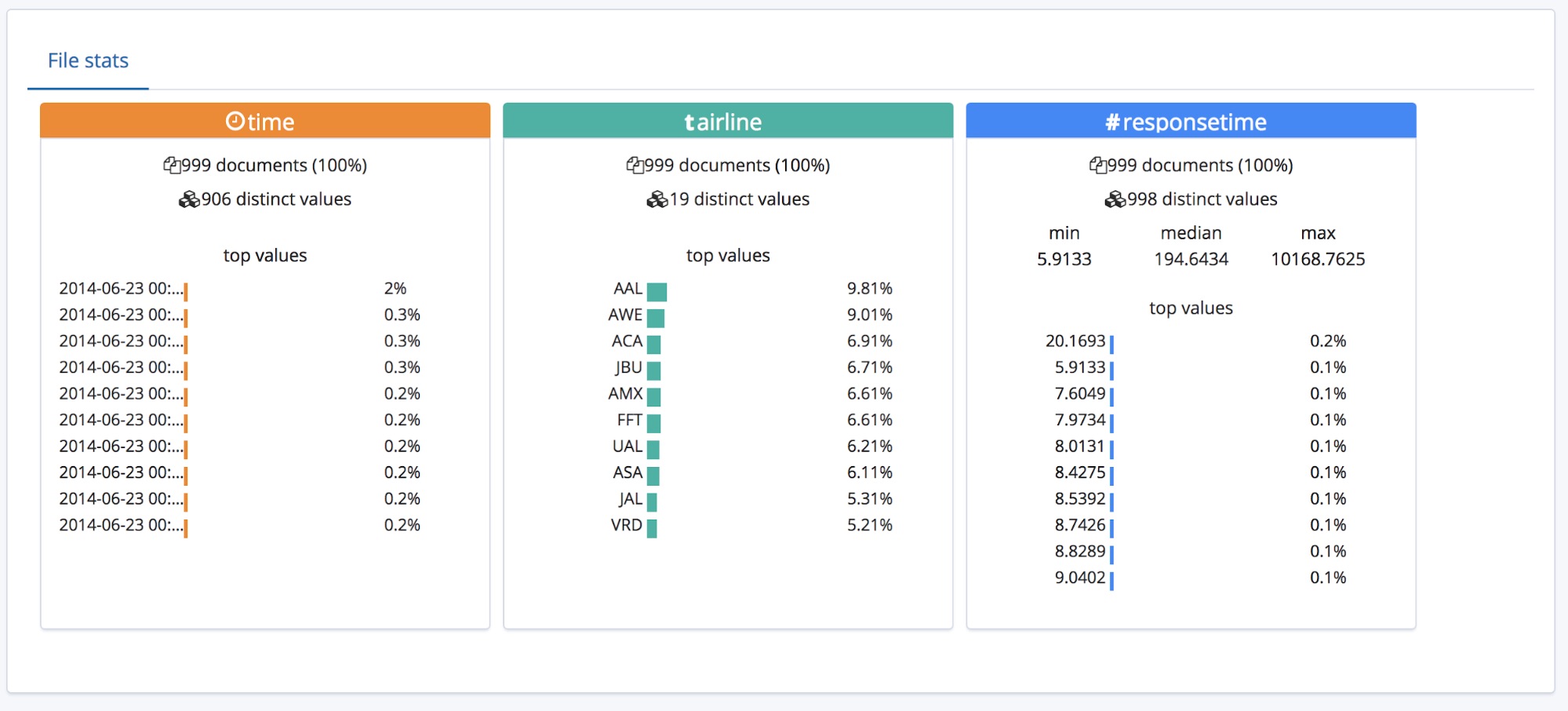
Debajo de la sección Resumen, se encuentra la sección de campos. Esto seguramente les resultará familiar a aquellos que hayan usado la característica original Data Visualizer.
Podemos ver que se identificaron correctamente los tipos de los tres campos y que para cada uno se enumeran algunas estadísticas de alto nivel. Se enumeran los 10 principales valores que aparecen para cada campo. Para tiempo de respuesta, que se identificó como un campo numérico, también se muestran los valores mínimo, promedio y máximo.
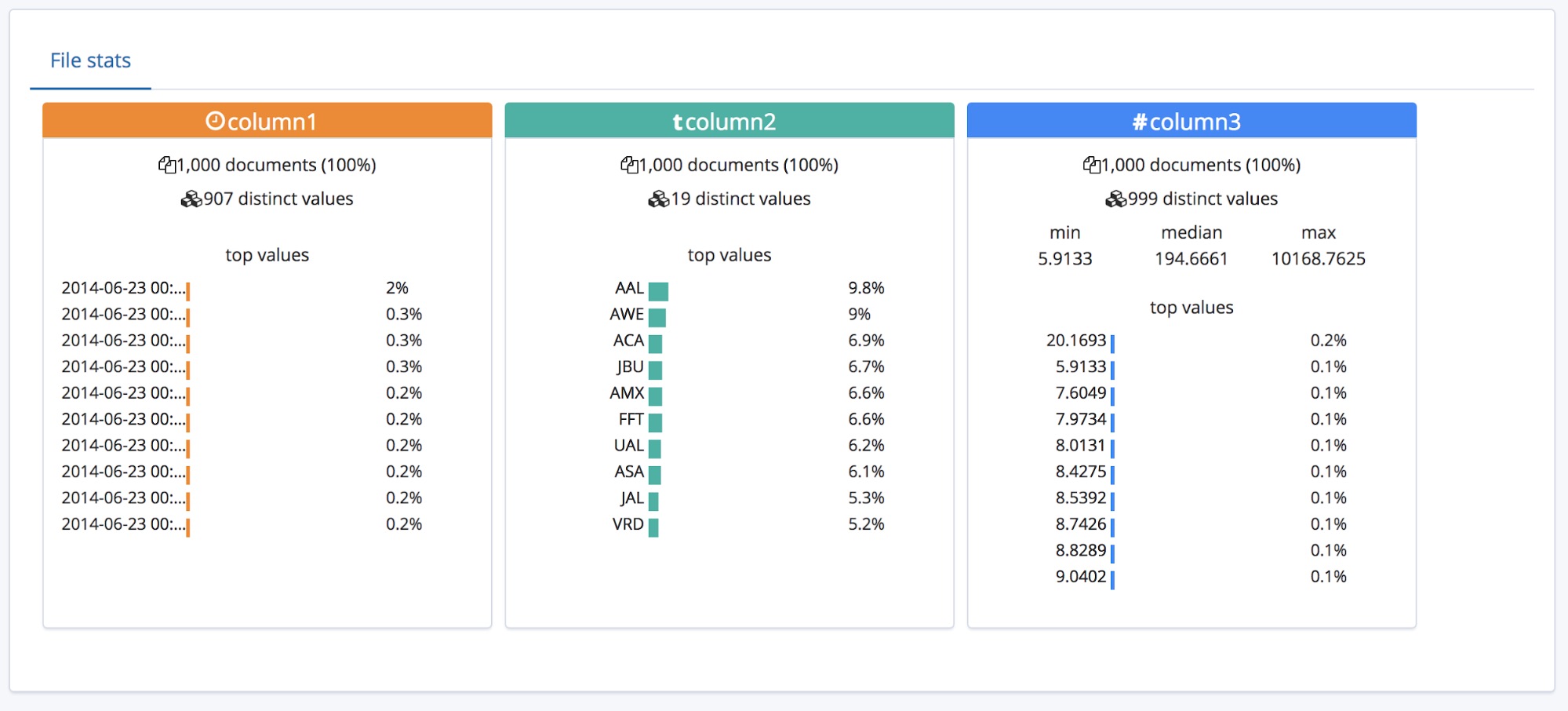
Todo esto está muy bien para un archivo CSV que tiene un encabezado, pero ¿qué pasa si los datos no tienen una fila de encabezado?
En ese caso, el punto final find_file_structure usará nombres de campo temporales. Para demostrar esto, eliminaremos la primera fila del archivo de ejemplo y lo volveremos a subir. Ahora, a los campos se les asignaron nombres generales: columna1, columna2 y columna3.
El usuario probablemente tendrá algún conocimiento del dominio y tal vez elija asignarles nombres más adecuados a estos campos. Para eso, pueden usar el botón Anular configuración.
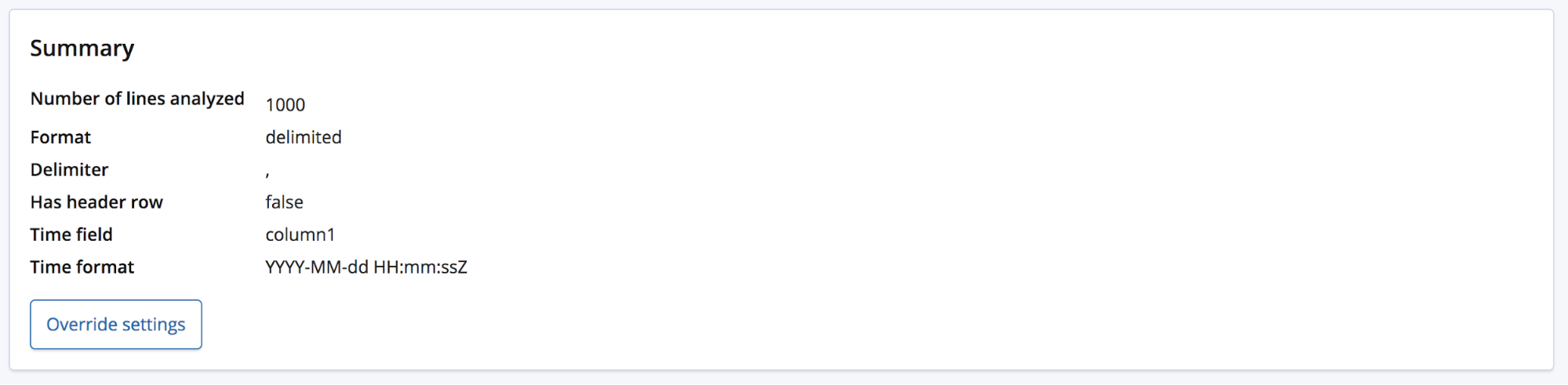
Además de cambiar el nombre de estos campos, el usuario puede ajustar otras configuraciones, como el formato de los datos, el delimitador y el carácter de la cita. Piensa en esta sección como una forma de corregir la predicción bien fundamentada que hizo el punto final find_file_structure con respecto a los datos. Es posible que tengas múltiples campos de datos, de los cuales eligió el primero. O quizás quieras simplemente cambiar por completo los nombres de los campos, aunque el archivo tenga una fila de encabezado.
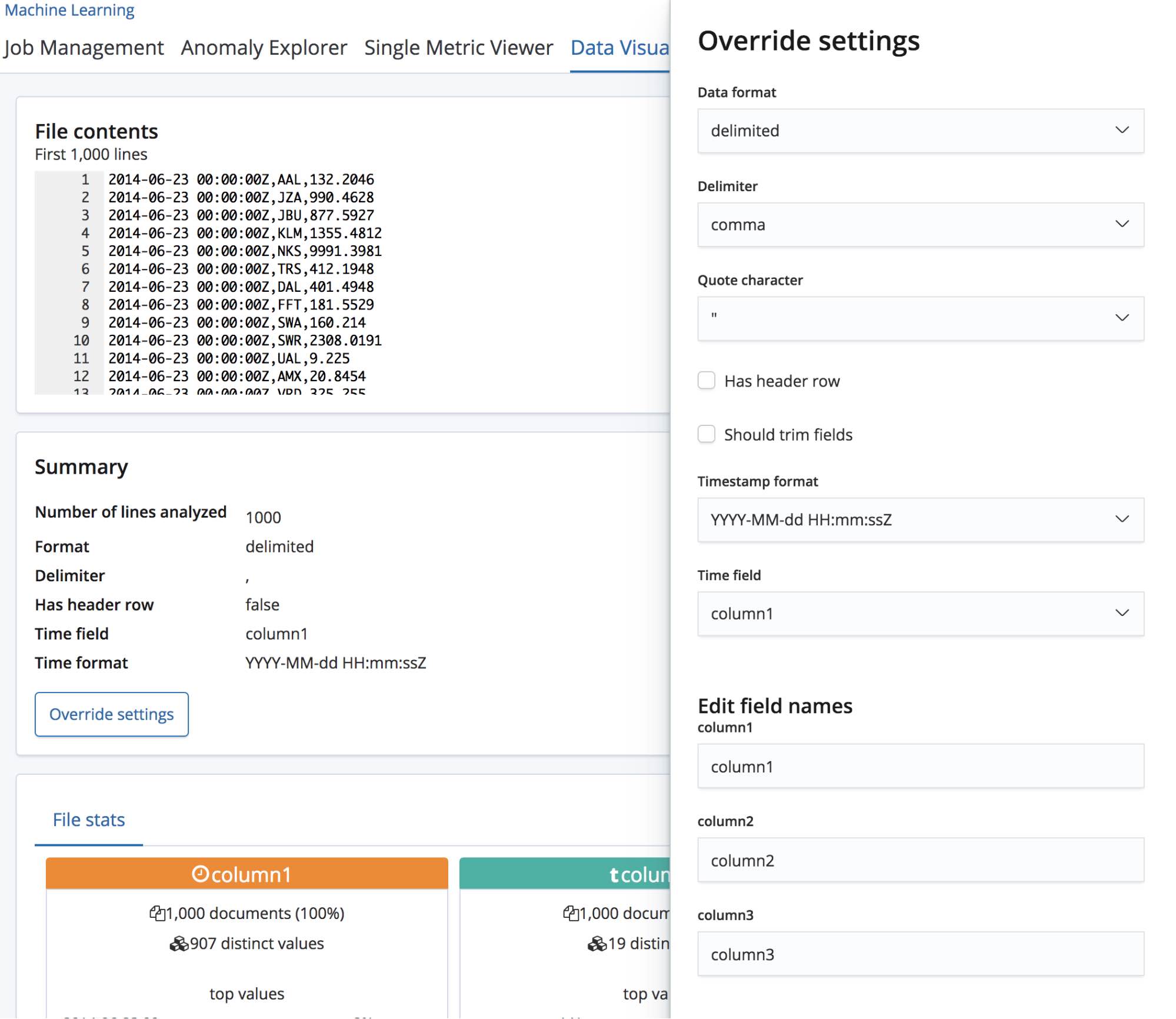
Una vez que estemos satisfechos con esta configuración, podemos presionar el botón Importar, ubicado en la parte inferior izquierda de la página.
Importar los datos del archivo CSV a Elasticsearch
Esto nos lleva a la página Importar, donde podemos importar los datos a Elasticsearch. Ten en cuenta que esta característica no está diseñada para usarse como parte de un proceso de producción repetido, sino para la exploración inicial de los datos. La razón principal es la falta de opciones de automatización, pero también el hecho de que actualmente esta característica es experimental.
Hay dos formas de importar. La simple, donde lo único que necesita el usuario es elegir un nuevo nombre de índice único y si desea crear también un patrón de índice.
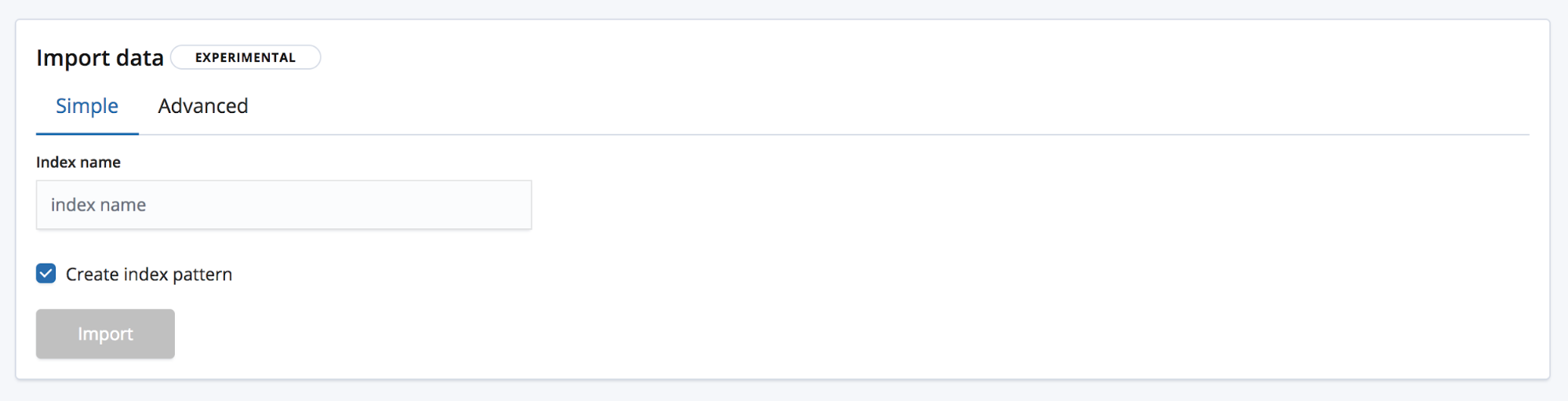
Y la avanzada, donde el usuario tiene un mayor control sobre la configuración que se usará para crear el índice.
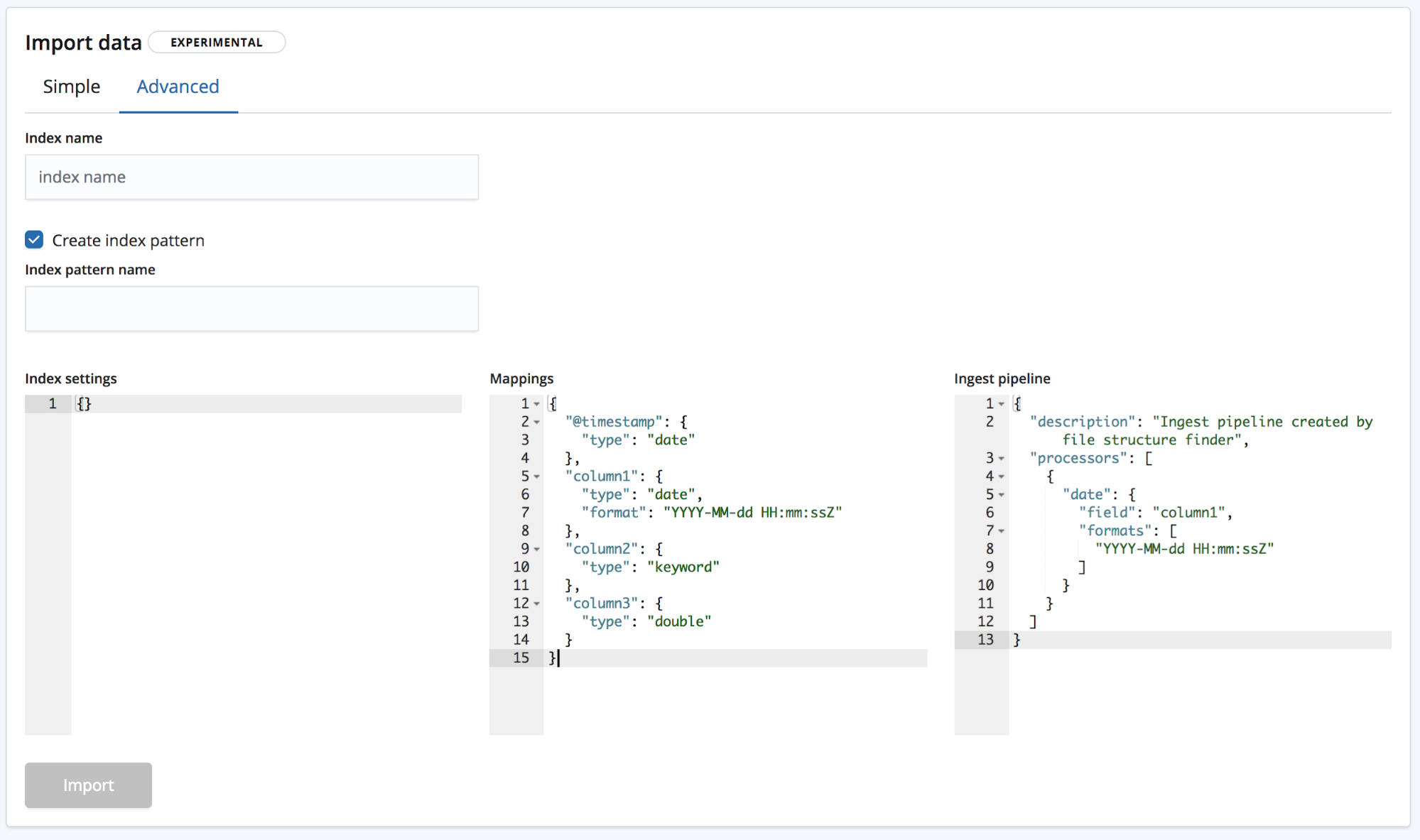
- Configuración de índice: de forma predeterminada, no se necesitan configuraciones adicionales para la creación del índice y la importación; de todos modos, está disponible la opción para personalizar la configuración del índice.
- Mapeos:
find_file_structureproporciona un objeto de mapeos basado en los campos y los tipos que ha identificado. Para obtener una lista de posibles mapeos, consulta nuestra documentación de mapeos de Elasticsearch. - Pipeline de ingesta:
find_file_structureproporciona un objeto de pipeline de ingesta predeterminado. Esto se usará al ingestar los datos y se puede usar para cargar cualquier información adicional.
En la versión 6.5, solo se permite crear nuevos índices, pero no se permite agregar datos a un índice existente para reducir el riesgo de dañar el índice.
Al hacer clic en el botón Importar, comienza el proceso de importación. Esto consta de varios pasos numerados:
- Procesamiento del archivo: convertir los datos en documentos NDJSON para que puedan ingestarse mediante la API de bulk
- Creación del índice: crear el índice mediante los objetos de configuración y mapeo
- Creación de pipeline de ingesta: crear la pipeline de ingesta mediante el objeto de pipeline de ingesta
- Carga de los datos: cargar los datos en el nuevo índice de Elasticsearch
- Creación del patrón de índice: crear un patrón de índice de Kibana (si el usuario seleccionó esta opción)

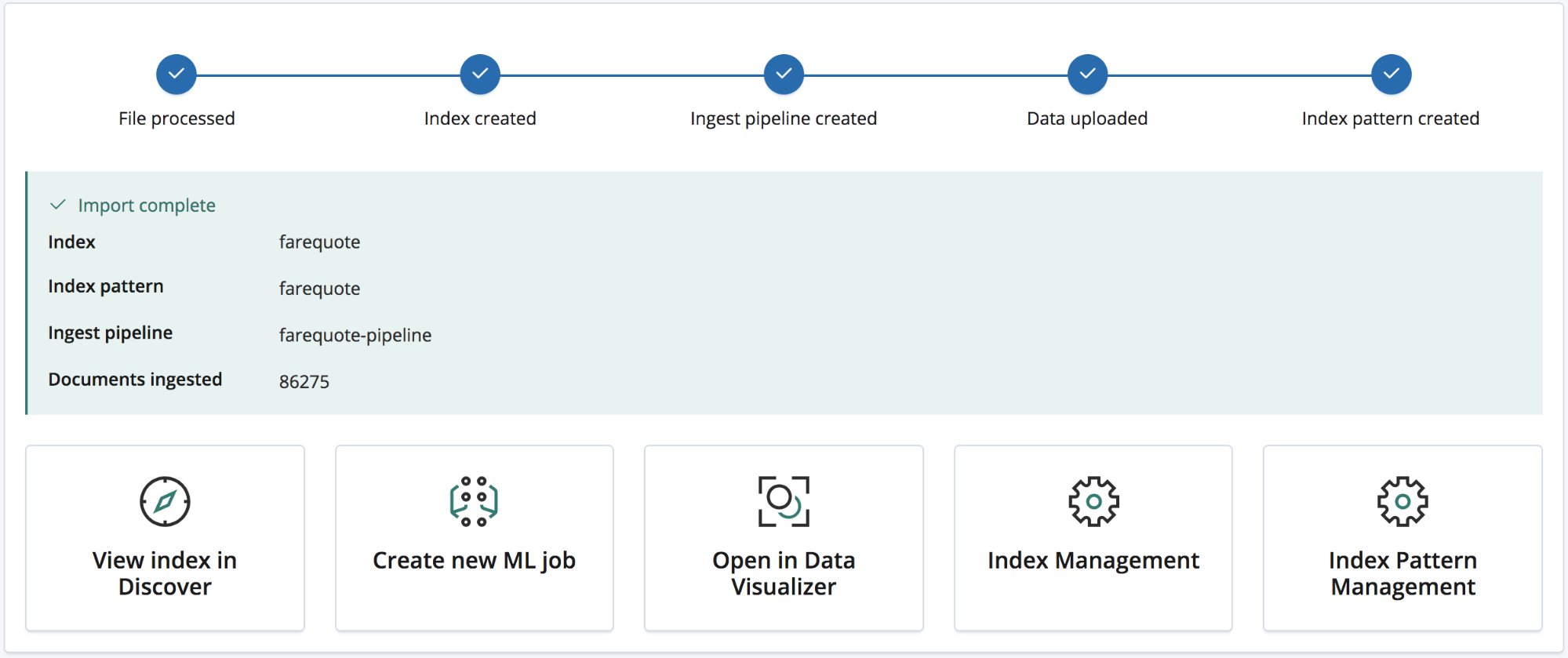
Una vez que se completa el proceso de importación, el usuario recibe un resumen con los nombres del índice, el patrón de índice y el canal de ingesta que se han creado, así como el número de documentos ingestados.
Además, obtiene una serie de enlaces de Kibana para explorar los datos recién importados. Los usuarios con suscripción Platino y De prueba también recibirán un enlace para crear rápidamente una tarea de Machine Learning a partir de los datos importados.
Ejemplo: importar archivos de log y otros archivos de texto semiestructurado a Elasticsearch
Hasta ahora, cubrimos los datos de archivos CSV; los de NDJSON son aún más sencillos, ya que la importación requiere poco procesamiento, pero ¿qué pasa con el texto semiestructurado? Veamos cómo el análisis de los datos de CSV difiere de los datos típicos del archivo de log, conocido también como texto semiestructurado.
A continuación, se muestran tres líneas de un archivo de log generado por un enrutador.
<190>38377: GOW45-AR002: Apr 18 08:44:02.434 GMT: %JHG_MS-6-ROUTE_EVENT_INFO: Route changed Prefix 10.156.26.0/23, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired <190>38378: GOW45-AR002: Apr 18 08:44:07.538 GMT: %JHG_MS-6-ROUTE_EVENT_INFO: Route changed Prefix 10.156.72.0/23, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired <190>38379: GOW45-AR002: Apr 18 08:44:08.818 GMT: %JHG_MS-6-ROUTE_EVENT_INFO: Route changed Prefix 10.156.55.0/24, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired
Cuando se analiza mediante el punto final find_file_structure, reconoce correctamente que el formato es texto semiestructurado y crea un patrón grok para extraer los campos y sus tipos de cada línea. Entre estos campos, también reconoce cuál es el campo Tiempo y su formato.
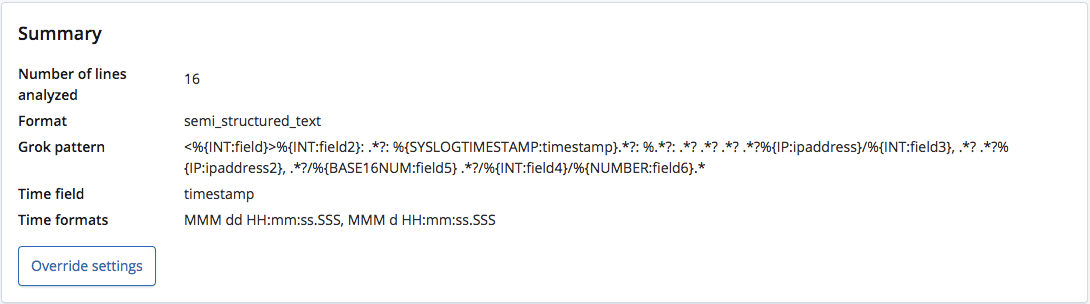
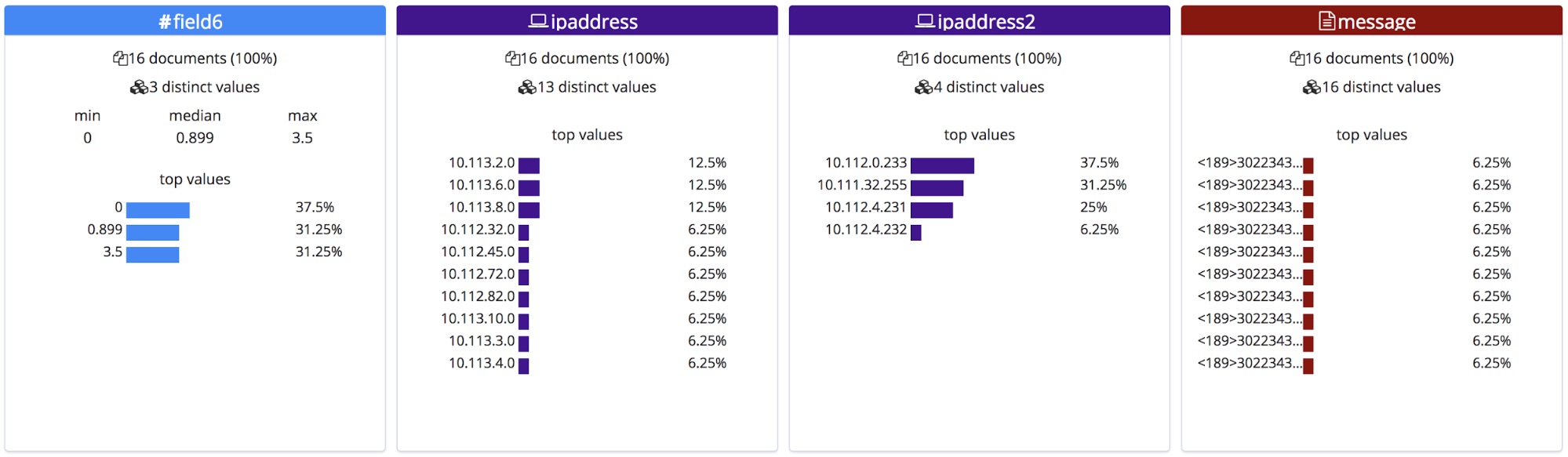
A diferencia de un archivo CSV con un encabezado o un archivo NDJSON, no hay forma de saber los nombres correctos para estos campos, por lo que el punto final les da nombres generales basados en sus tipos.
Sin embargo, este patrón grok puede editarse en el menú Anular configuración, así que podemos corregir los nombres de campo y sus tipos.
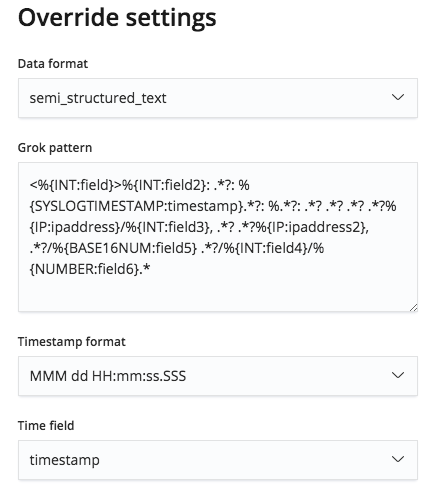
Estos nombres de campo corregidos se mostrarán en la sección Archivo de las estadísticas. Debe tenerse en cuenta que están ordenados alfabéticamente, por lo que el orden cambió ligeramente.
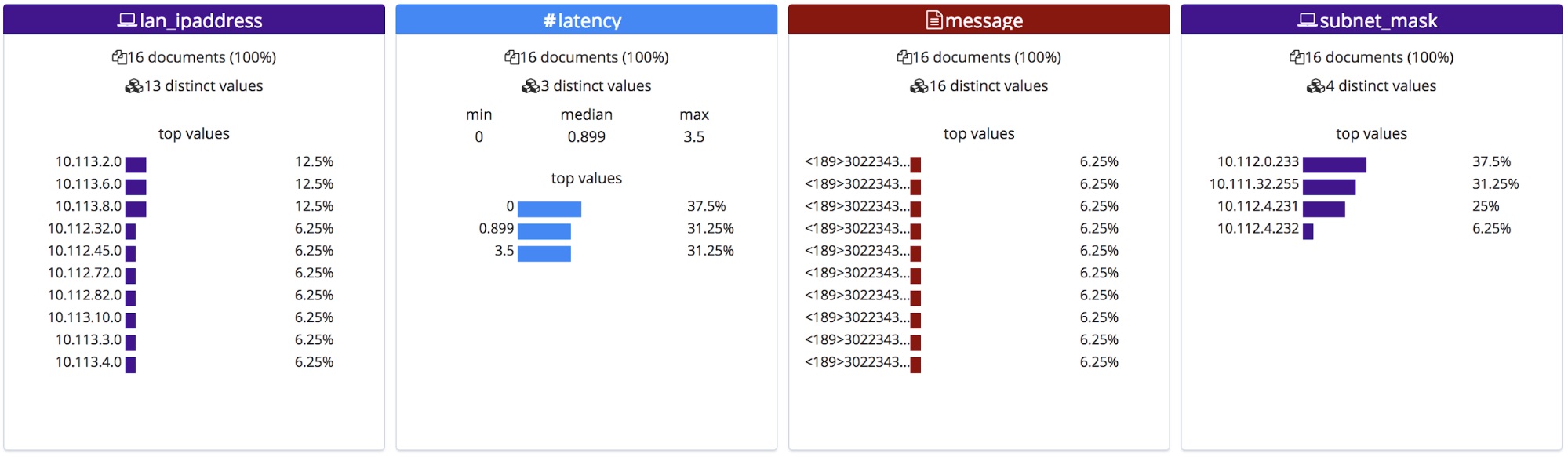
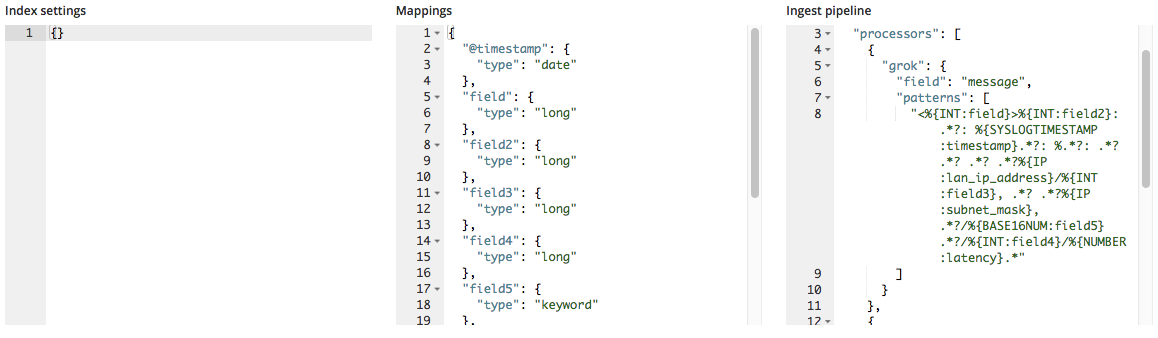
Al importarlos, estos nuevos nombres de campo se agregan al objeto de mapeos y el patrón grok se agrega a la lista de procesadores en la pipeline de ingesta.
Resumen
Esperamos que esto haya despertado tu apetito para probar la nueva característica File Data Visualizer en la versión 6.5. Esta sigue siendo una característica experimental en la versión 6.5, por lo que es posible que no todos los formatos de archivo coincidan correctamente, pero pruébala y cuéntanos cómo te va. Tus comentarios nos ayudarán a llevar esta característica a GA más rápido